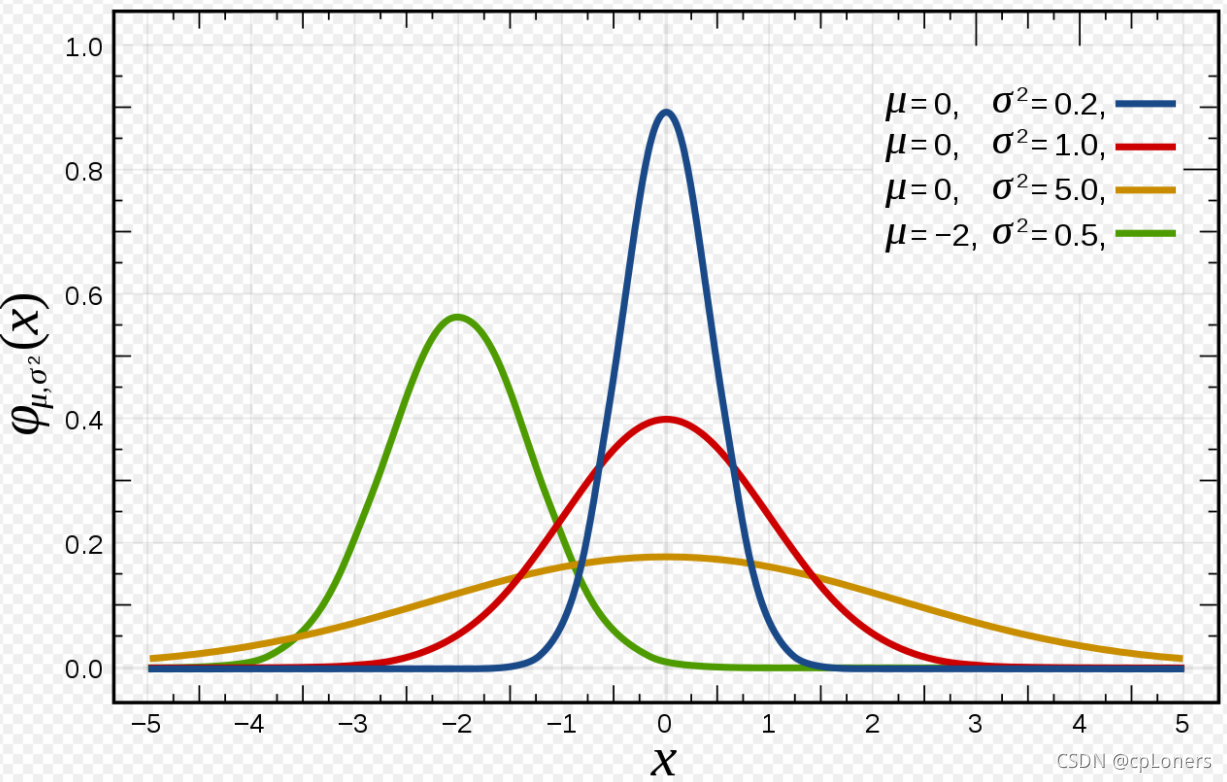
n 元高斯分布描述 n 个随机变量的联合概率分布,由均值向量(μ,
μ
2
\mu_2
μ2…
μ
n
\mu_n
μn)和协方差短阵工唯一确定。其中上是一个 nXn 的矩阵,每个矩阵元素描述 n 个随机变量两两之间的协方差。
和与差
设有任意两个独立的高斯分布 U 和 V,那么它们的和 U+V 一定是高斯分布,它们的差 U-V 也一定是高斯分布
部分与整体
多元高斯分布的条件分布仍然是多元高斯分布,也可理解为多元高斯分布的子集也是多元高斯分布
核函数
根据上面的知识已经知道可以将高斯过程看成无限维的多元高斯分布,那么机器学习的训练过程目标就是学习该无限维高斯分布的子集——也是一个多元高斯分布的参数:均值向量<μ,
μ
2
\mu_2
μ2…
μ
n
\mu_n
μn>和协方差矩阵上。协方差矩阵工中的元素用于表征两两样本之间的协方差,这个“描述两两样本之间关系”的概念似曾相识。对,就是 SVM 中用于计算高维空间两两样本向量内积的核函数。此处核方法也应用在了协方差矩阵上,使得多元高斯分布也具有了表征高维空间样本之间关系的能力,也就是具备了表征非线性数据的能力。此时的协方差矩阵可以表示为:
Σ
=
K
x
x
=
[
k
(
x
1
,
x
2
)
.
.
.
k
(
x
1
,
x
n
)
:
.
.
.
:
k
(
x
n
,
x
1
)
.
.
.
k
(
x
n
,
x
n
)
]
\Sigma = Kxx = \begin{bmatrix}k(x_1, x_2) & ...&k(x_1, x_n) \\ : & ...&:\\k(x_n,x_1)&...&k(x_n,x_n)\\ \end{bmatrix}
Σ=Kxx=⎣⎡k(x1,x2):k(xn,x1).........k(x1,xn):k(xn,xn)⎦⎤ 其中符号Kxx表示样本数据特征集 X 的核函数矩阵,用 k()表示所选取的核函数,
x
1
,
x
2
.
.
.
x
n
x_1,x_2...x_n
x1,x2...xn等是单个样本特征向量。和 SVM 一样,此处的核函数也需要开发者指定其形式。常用的仍然有径向基核、多项式核、线性核等。在训练过程中可以定义算法自动寻找核的最佳超参数。
白噪声处理
在建模中已经知道随机过程需要考虑采样数据存在噪声的情况。用高斯分布的观点来看,就是在计算训练数据协方差矩阵 Kxx 的对角元素上增加噪声分量。因此协方差矩阵变为如下形式:
Σ
=
K
x
x
=
[
k
(
x
1
,
x
2
)
…
k
(
x
1
,
x
n
)
⋮
⋱
⋮
k
(
x
n
,
x
1
)
…
k
(
x
n
,
x
n
)
]
+
α
(
1
…
0
⋮
⋮
0
…
1
)
\Sigma = Kxx = \begin{bmatrix}k(x_1, x_2) & \dots&k(x_1, x_n) \\ \vdots& \ddots&\vdots\\k(x_n,x_1)&\dots&k(x_n,x_n)\\ \end{bmatrix}+\alpha\begin{pmatrix} 1&\dots&0\\ \vdots&&\vdots\\ 0&\dots&1\\ \end{pmatrix}
Σ=Kxx=⎣⎢⎡k(x1,x2)⋮k(xn,x1)…⋱…k(x1,xn)⋮k(xn,xn)⎦⎥⎤+α⎝⎜⎛1⋮0……0⋮1⎠⎟⎞ 其中α 是模型训练者需要定义的噪声估计参数,该值越大模型抗噪声能力越强,但容易产生拟合不足。