CNN模型
CNN卷积神经网络,包含卷积层(卷积运算提取输入的不同特征,更多层的网络能从低级特征中迭代提取等复杂的特征),线性整流层(RELU),池化层(卷积后会得到维度很大的特征,将特征切成几个区域,取最大值或平均值,得到新的较小维度特征),全连接层(局部特征结合变成全局特征,计算最后得分)
卷积:使用卷积核对图像进行扫描,得到特征图

池化:池化即下采样,目的减少特征图

详细内容参见:https://blog.csdn.net/liangchunjiang/article/details/79030681
实验内容
加深对卷积神经网络模型的理解,能够使用卷积神经网络模型解决简单问题
根据卷积神经网络模型的相关知识,使用Python语言实现一个简单卷积神经网络模型,该模型能够实现手写数字识别。
代码详解
jupyter notebook
Python 3.7
TensorFlow 1.13
Keras 2.3.1
数据处理
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
def plot_images(images, idx, num=10):
fig = plt.gcf()
for i in range(num):
ax = plt.subplot(5, 2, 1+i)
ax.imshow(images[idx+i], cmap='binary')
plt.show()
plot_images(x_train, 0, 10)
x_train_nom = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')/255
x_test_nom = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32')/255
y_train1hot = np_utils.to_categorical(y_train)
print(y_train1hot[:3])
加载mnist数据集,并进行提取,plot_images函数用于展示图片
然后将图片数据reshape成四维,便于之后输入,然后除以255进行标准化处理
标签数据to_categorical转化为独热编码

构建模型
model = Sequential()
model.add(Conv2D(filters = 16,
kernel_size=(3, 3),
padding='same',
activation='relu',
input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Conv2D(filters=36,
kernel_size = (3, 3),
padding = 'same',
activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(10, activation = 'softmax'))
Sequential 建立线性堆叠模型,建立卷积层,filters卷积核个数16,kernel_size卷积核大小,input_shape输入图像大小,padding填充,activation激活函数
池化层池化窗口2
建立第一个卷积层,第一个池化层,再建立第二个卷积层,第二个池化层
加入 dropout防止过拟合
Flatten平坦层,将多维向量转化为一维向量
Dense隐藏层
最后加入输出层,一共10个神经元,表示十个类别,softmax来分类
模型训练
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
train_history = model.fit(x = x_train_nom,
y = y_train1hot,
epochs=10,
batch_size=64,
verbose=2,
validation_split=0.2)
进行模型编译和训练,epoch为10,batchsize为64,将训练数据的0.2作为验证集
结果分析
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc = 'upper left')
plt.savefig(train)
plt.show()
show_train_history(train_history, 'loss', 'val_loss')
show_train_history(train_history, 'accuracy', 'val_accuracy')
y_test1hot = np_utils.to_categorical(y_test)
scores = model.evaluate(x_test_nom, y_test1hot)
print(scores)
绘制准确率和loss的图像
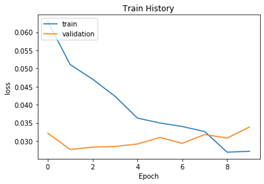
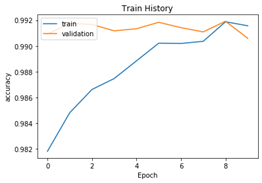
输出得到测试准确率为 0.9912
from keras.utils import plot_model
plot_model(model, to_file = 'model1.png', show_shapes=True)
Keras可视化输出模型图
