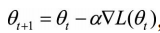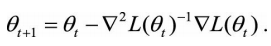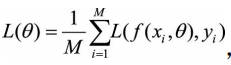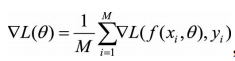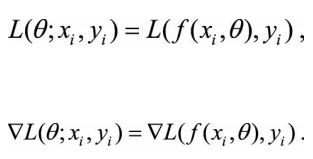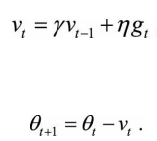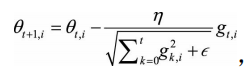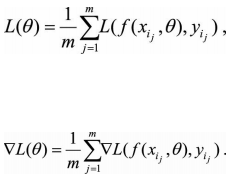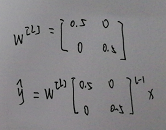(1)一阶迭代法(又称梯度下降法): (2)二阶迭代法(牛顿法): 一般在神经网络里面,L()函数就是代价函数。
随机梯度下降法可以解决经典梯度下降法数据量大,计算量大,耗时长的问题。 但是对于SGD来说,局部最小还不是最可怕的,在陷入鞍点(鞍点的形状像是一个马 鞍,一个方向上两头翘,另一个方向上两头垂,而中心区域是一片近乎水平的平 地)才是最可怕的,就像在山谷中一样,在两石壁上来回反弹振荡,故称plateau。 解决办法: a、动量方法: 具体来说,前进步伐−vt由两部分组成。一是学习速率η乘以当前估计的梯度gt;二 是带衰减的前一次步伐vt−1。这里,惯性就体现在对前一次步伐信息的重利用上。 类比中学物理知识,当前梯度就好比当前时刻受力产生的加速度,前一次步伐好 比前一时刻的速度,当前步伐好比当前时刻的速度。为了计算当前时刻的速度, 应当考虑前一时刻速度和当前加速度共同作用的结果,因此vt直接依赖于vt−1和gt, 而不仅仅是gt。另外,衰减系数γ扮演了阻力的作用。 由图可知:动量梯度下降法的收敛熟读更快。 b、环境感知—AdaGrad方法 惯性的获得是基于历史信息的,除了从过去的步伐中获取得一股子向前 冲的劲儿,还能获得什么呢?我们还期待获得对周围环境的感知,即使蒙上双眼,依靠前几次迈步的感觉,也应该能判断出一些信息,比如这个方向总是坑坑 洼洼的,那个方向可能很平。 随机梯度下降法对环境的感知是指在参数空间中,根据不同参数的一些经验性判断,自适应地确定参数的学习速率,不同参数的更新步幅是不同的。在应用中,我们希望更新频率低的参数可以拥有较大的更新步幅,而更新频率高的参数的步幅可以减少。AdaGrad方法采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性,取值越小表明越稀疏,具体的更新公式如下: AdaDelta和RMSProp两个方法非常类似,是对AdaGrad方法的改进。 c、Adam方法 Adam方法将惯性保持和环境感知这两个优点集于一身。一方面,Adam记录梯度的一阶矩阵,即过往梯度与当前梯度的平均,这体现了惯性保持 ;另一方面,Adam还记录梯度的二阶矩,即过往梯度平方与当前梯度平方的平均,体现了环境感知能力,为不同参数产生自适应的学习速率
注意: a、m一般选取2的幂次,如32、64、128等; b、为了避免数据的特定顺序给算法收敛带来的影响,在每次遍历训练数据之前,先对所有的数据进行随机排序,然后在每次迭代时按顺序挑选m个训练数据直至遍历完所有的数据; c、学习速率α要选择合适。
假设激活函数是tanh,当lambda增大时,导致w减少,z=w*a+b也会减少,由上图可知,在z较少的区域内,tanh(z)函数近似线性,所以每层的函数就接近线性函数,整个网络就成为了一个简单的线性网络,从未不会发生过拟合。
Dropout正则项为每个神经元设置一个随机消除的概率,对于保留下来的神经元,我们将得到一个节点较少,规模较大的网络进行训练。 对于Dropout的理解,以单个神经元入手,单个神经元工作就是接受输入,并产生一些有意义的输出,但是假如Dropout以后,输入的特征就是有可能会被随机清楚(概率是K的值),所以该神经元不会再特别依赖于任何一个输入特征,也就是不会给任何一个输入设置太大的权重。
从输入到输出有很多层结构,y=w(l) * w(l-1) * w(l-2) *** w(1) * x a、w(l)>1时: 激活函数的值将以指数级递增,在梯度函数上出现以指数级递增,成为梯度爆炸; b、w(l)<1时: 激活函数的值将以指数级递减,在梯度函数上出现以指数级递减,成为梯度消失。 解决办法:
以一个简单的神经网络为例: 注意:没有写出偏置参数b,是因为z=w * a+b,而b=Batch norm要做的就是将z归一化,结果为均值为0,标准差为1的分布,再由B和r进行重新的分布缩放,那就意味着,无论b的值为多少,在这个过程中都会减去,不再起作用。所以如果在神经网络中应用Batch norm的话,直接将偏置参数b去掉。 Batch norm起作用的原因: 1)可以加速神经网络训练的原因和输入层的输入特征进行归一化,从而改变Cost function的形状,只是Batch norm不是单纯的将输入的特征进行归一化,而将各个隐含层的激活值进行归一化,并调整到另外的分布; 2)使权重比网络更滞后或者更深层。 covariate shift问题 通俗上说,covariate shift问题就是训练集上分布较好的点,它所对应的参数,在测试集上是否好呢? 在神经网络中,第二个隐含层的输出值a[2]作为输入特征时,通过前向传播得到最终的预测输出y,但是由于我们的网络还有前面两层,由于训练过程,参数w[1]、w[2]是不断变化,那么也就对于后面的网络,a[2]的值也处于不断变化中,就有了covariate shift问题。 对于Z使用了Batch norm,那么即使其值不断的变化,但是其均值和方差却会保持。Batch norm的作用就是限制前两层的参数更新导致对后面网络数值分布程度的影响,使得后 层的数值变得更加稳定。另外一个角度就是,Batch norm削弱了前两层与后层之间的联系,使得网络的每一层都可以自己学习,相对其他层有一定的独立性,有助于加速整个网络的学习。 由于不是在整个训练集上训练,是在mini-batch中训练,计算均值和偏差,会带来小误差,起到了正则化的效果。