一、Mask R-CNN网络介绍
Mask R-CNN是何凯明2017年提出的一个实例分割(Instance segmentation)算法,可以用来做“目标检测”、“目标实例分割”、“目标关键点检测”。,是ICCV2017的best paper。
Mask R-CNN网络的设计比较简单,①在Faster R-CNN的基础上,在原本的两个分支上(分类+坐标回归)增加一个简单的完全卷积网络(FCN)输出object mask 作为第三个分支,②同时用RoIAlign代替了Faster R-CNN的RoIPooling,如下图所示:

二、Mask R-CNN网络
1、为什么要用ROIAlign代替ROIPooling?它们有什么区别?
关于它们的区别及作用,我已经另外写了一篇文章。这里简单介绍下。
Faster R-CNN方法中,在进行Roi-Pooling之前需要进行两次量化操作(第一次是原图像中的目标到conv5之前的缩放,比如缩放32倍,目标大小是600,结果不是整数,需要进行量化舍弃,第二次量化是比如特征图目标是5*5,ROI-pooling后是2*2,这里由于5不是2的倍数,需要再一次进行量化,这样对于Roi Pooling之后的结果就与原来的图像位置相差比较大了)。这样操作的问题就是会造成像素偏差以至会对后层的回归定位产生影响,而实例分割需要比较准确的像素位置,因此ROI Pooling的这种操作无法应用在分割支路,因为输入和输出的ROI像素点的位置对应关系不能保证一致,因此为了解决这个问题,作者采用了ROIAlign,用于替代原来Faster R-CNN中的ROIPooling层,如图所示。
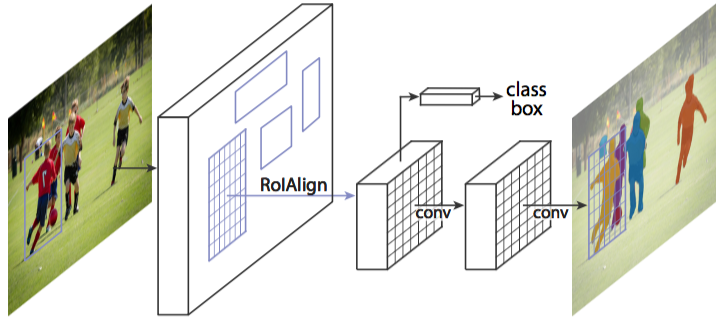
2、Mask R-CNN的网络结构如下
下图所示是两种典型的Mask R-CNN网络结构,作者借鉴了 FPN 的思想,分别设计了两种网络结构,左边的是采用ResNet作为网络的backbone提取特征,右边的网络采用FPN网络作为backbone进行特征提取,并且作者指明,使用FPN作为基础网络的效果其实是最好的。

3、Mask R-CNN的损失函数
Mask R-CNN的损失函数为
其中L_cls和L_box和Faster RCNN中定义的分类和回归损失一致,这里主要介绍下L_mask,
L_mask是对每个像素进行分类,其含有 K * m * m维度的输出,K代表类别的数量,m*m是提取的ROI图像的大小。L_mask被定义为 average binary cross-entropy loss(平均二值交叉熵损失函数)。这里解释一下是如何计算的,首先分割层会输出channel为K的Mask,每个Mask对应一个类别,利用sigmoid函数进行二分类,判断是否是这个类别,然后在计算loss的时候,假如ROI对应的ground-truth的类别是 ,则计算第
,则计算第 个mask对应的loss,其他的mask对这个loss没有贡献计算二值交叉熵搞的公式如下图中的函数接口。这里不同于FCN的是,FCN是对每个像素进行softmax分类,分为K个类别,然后计算softmax loss,作者根据分类分支的预测结果进行判断。
个mask对应的loss,其他的mask对这个loss没有贡献计算二值交叉熵搞的公式如下图中的函数接口。这里不同于FCN的是,FCN是对每个像素进行softmax分类,分为K个类别,然后计算softmax loss,作者根据分类分支的预测结果进行判断。
这里有个推断的细节:采用ResNet作为backbone的Mask R-CNN产生300个候选区域进行分类回归,采用FPN方法的生成1000个候选区域进行分类回归,然后进行非极大值抑制操作, 最后检测分数前100的区域进行mask检测,这里没有使用跟训练一样的并行操作,作者解释说是可以提高精度和效率,然后mask分支可以预测k个类别的mask,但是这里根据分类的结果,选取对应的第k个类别,得到对应的mask后,再resize到ROI的大小, 然后利用阈值0.5进行二值化即可。(这里由于resize需要插值操作,所以需要再次进行二值化,mask最后并不是ROI大小,而是一个相对较小的图, 所以需要进行resize操作。)
4、网络训练
训练时的一些实现细节:输入图像的处理是将短边resize到800大小;单GPU的batch size设置为2;每张图像提取N个ROI(对于Faster RCNN架构采用N=64,对于FPN架构采用N=512,之所以数量差别这么大,主要原因在于FPN是基于多个融合层分别预测),其中positive和negative的比例是1:3;RPN网络采取5种scale和3种aspect retio。
验证时的一些细节:proposal的数量对于Faster RCNN架构采用300,对于FPN架构采用1000。mask支路都是基于最后score最高的100个预测结果进行的,这样增加的计算量就非常少。
三、实验结果
1、首先是Mask R-CNN算法在COCO数据集上的实例分割结果:

2、Table1是Mask RCNN算法和其他实例分割算法的结果对比(MNC和FCIS分别是COCO 2015和2016的分割比赛冠军),优势还是比较明显的:

3、Table2是一些细节对比:
①表(a),显示了网络越深,效果越好。并且FPN效果要好一些。
②表(b),sigmoid要比softmax效果好一些。
③表(c),是在ResNet-50-C4上进行的ROI Pool、ROIWarp和ROIAlign的对比,可以看出ROIAlign效果有提升,另外pooling的类型对ROIAlign的效果影响不大。
④表(d),是在ResNet-50-C5上进行的ROI Pool和ROIAlign的对比,可以看出此时ROI Pool的效果要比从C4提取特征来得差,毕竟越高层的特征量化带来的误差就越大。另外基于C5提取特征的ROIAlign的效果要比基于C4提取特征好一点,这就说明ROIAlign所带来的误差非常小,这个实验还是比较重要的,因为很大程度上解决了长期以来大感受野带来的检测和分割效果差的问题。
⑤表(e),mask banch采用FCN效果较好(因为FCN没有破坏空间关系)
⑥另外作者实验,mask分支采用不同的方法,方法一:对每个类别预测一个mask ,方法二:所有的都预测一个mask,实验结果每个类预测一个mask别会好一些 30.3 vs 29.7

4、Table3是对于目标检测的结果:
对比下表,可见,在预测的时候即使不使用mask分支,结果精度也是很高的,下图中’Faster R-CNN, ROIAlign’ 是使用ROI Align,而不使用ROI Pooling的结果,较ROI Pooling的结果高了约0.9个点,但是比MaskR-CNN还是低了0.9个点,这个提升,作者将其归结为多任务训练的提升,由于加入了mask分支,带来的loss改变,间接影响了主干网络的效果。

5、Figure6是人体关键点检测:
与Mask R-CNN进行Mask检测有什么不同呢?
①人体关键点检测,作者对最后m*m的mask进行one-hot编码,并且,mask中只有一个像素点是foreground其他的都是background。
②人体关键点检测,最后的输出是m^2-way 的softmax, 不再是Sigmoid,作者解释说,这有利于单独一个点的检测。
③人体关键点检测, 最后的mask分辨率是56*56,不再是28*28,作者解释,较高的分辨率有利于人体关键点的检测。

官方代码链接:https://github.com/facebookresearch/Detectron