目录
MySql的高级查询语句
数据准备
查询中常用的DISTINCT、IN、BETWEEN,OR、DESC/ASC、COUNT、MAX、LIMIT等关键字
SQL中关于日期的函数
SQL的分组查询和多表查询
sql的子查询以及UNION和以及UNION ALL、NOTIN的使用
SQL语句中的条件查询
SQL语句中的连接查询
MySql的常见的增删改查语句:
查:SELECT * from pet;
增:INSERT INTO pet VALUES(‘**’,‘**’,‘**’);
改:UPDATE pet SET **=‘**’ where **=‘**’;
删:DELETE from pet where **=‘**’
MySql的高级查询语句
数据准备
首先我们先准备数据和表,下面创建的是学生表,由no、name、sex、brithday、class五个字段组成。
CREATE TABLE student (
no VARCHAR(20) PRIMARY KEY,
name VARCHAR(20) NOT NULL,
sex VARCHAR(10) NOT NULL,
birthday DATE, -- 生日
class VARCHAR(20) -- 所在班级
);
然后我们创建教师表,教师表由no、name、sex、brithday、profession、department六个字段组成。
CREATE TABLE teacher (
no VARCHAR(20) PRIMARY KEY,
name VARCHAR(20) NOT NULL,
sex VARCHAR(10) NOT NULL,
birthday DATE,
profession VARCHAR(20) NOT NULL, -- 职称
department VARCHAR(20) NOT NULL -- 部门
);
接下来是课程表,课程表由no、name、t_no组成,其中t_no代表的是教师表中的no字段。其中t_no是一个外键约束。
CREATE TABLE course (
no VARCHAR(20) PRIMARY KEY,
name VARCHAR(20) NOT NULL,
t_no VARCHAR(20) NOT NULL, -- 教师编号
-- 表示该 tno 来自于 teacher 表中的 no 字段值
FOREIGN KEY(t_no) REFERENCES teacher(no)
);
接下来创建的是成绩表,成绩表由s_no,c_no,degree三个字段组成。其中s_no和c_no都是外键约束,并且设置s_no和c_no为联合主键。
CREATE TABLE score (
s_no VARCHAR(20) NOT NULL, -- 学生编号
c_no VARCHAR(20) NOT NULL, -- 课程号
degree DECIMAL, -- 成绩
-- 表示该 s_no, c_no 分别来自于 student, course 表中的 no 字段值
FOREIGN KEY(s_no) REFERENCES student(no),
FOREIGN KEY(c_no) REFERENCES course(no),
-- 设置 s_no, c_no 为联合主键
PRIMARY KEY(s_no, c_no)
);
接下来我们使用sql语句为创建的这四个表加入数据。
-- 添加学生表数据
INSERT INTO student VALUES('101', '曾华', '男', '1977-09-01', '95033');
INSERT INTO student VALUES('102', '匡明', '男', '1975-10-02', '95031');
INSERT INTO student VALUES('103', '王丽', '女', '1976-01-23', '95033');
INSERT INTO student VALUES('104', '李军', '男', '1976-02-20', '95033');
INSERT INTO student VALUES('105', '王芳', '女', '1975-02-10', '95031');
INSERT INTO student VALUES('106', '陆军', '男', '1974-06-03', '95031');
INSERT INTO student VALUES('107', '王尼玛', '男', '1976-02-20', '95033');
INSERT INTO student VALUES('108', '张全蛋', '男', '1975-02-10', '95031');
INSERT INTO student VALUES('109', '赵铁柱', '男', '1974-06-03', '95031');
-- 添加教师表数据
INSERT INTO teacher VALUES('804', '李诚', '男', '1958-12-02', '副教授', '计算机系');
INSERT INTO teacher VALUES('856', '张旭', '男', '1969-03-12', '讲师', '电子工程系');
INSERT INTO teacher VALUES('825', '王萍', '女', '1972-05-05', '助教', '计算机系');
INSERT INTO teacher VALUES('831', '刘冰', '女', '1977-08-14', '助教', '电子工程系');
-- 添加课程表数据
INSERT INTO course VALUES('3-105', '计算机导论', '825');
INSERT INTO course VALUES('3-245', '操作系统', '804');
INSERT INTO course VALUES('6-166', '数字电路', '856');
INSERT INTO course VALUES('9-888', '高等数学', '831');
-- 添加添加成绩表数据
INSERT INTO score VALUES('103', '3-105', '92');
INSERT INTO score VALUES('103', '3-245', '86');
INSERT INTO score VALUES('103', '6-166', '85');
INSERT INTO score VALUES('105', '3-105', '88');
INSERT INTO score VALUES('105', '3-245', '75');
INSERT INTO score VALUES('105', '6-166', '79');
INSERT INTO score VALUES('109', '3-105', '76');
INSERT INTO score VALUES('109', '3-245', '68');
INSERT INTO score VALUES('109', '6-166', '81');
查询中常用的DISTINCT、IN、BETWEEN,OR、DESC/ASC、COUNT、MAX、LIMIT等关键字
DISTINCT关键字用来去重,可以查询到表中不重复的列。如下图所示,我们可以查询到teacher表中的所有的不重复的部门。而不是返回很多重复的查询结果


使用in可以一次查询规定中的多个值,具体的查询语句格式如下所示,可以一次性查询degree为85或86或88的所有行:
select * from score where degree in (85,86,88);
使用or表示关系,与in的区别在于,in只能是一个字段的选择,而or可以是两个字段的判断。下面这个查询语句可以查询到班级号为95301或者性别为女的所有的学生。
select * from student where class=‘95031’ or sex=‘女’;
使用DESC或者ASC可以将查询到的数据按照升序或者降序排列。SQL语句格式如下所示,可以将查询到的数据按照class的升序或者降序排列:
select * from student order by class desc;
select * from student order by class asc;
也可以联合使用升序和降序,下面这个语句是将查询到的数据按照c_no的升序排序,如果c_no相同,就按照degree的降序排序。
select * from score order by c_no asc,degree desc;
我们还可以使用count计算表中某一字段有多少个,如下所示这个sql语句可以查询class为95301的学生有多少个:
select count(*) from student where class='95301';
我们还可以使用MAX、MIN查询某个字段的最大值或者最小值对应的行,具体的查询格式如下所示,该sql语句可以查询degree最大的行的s_no和c_no:
select s_no,c_no from score where degree=(select MAX(degree) from score);
对于一些数据量较大的查询结果,我们也可以使用limit取前几行数据,数据格式如下所示,下面这行语句的意思是将查询的数据按照degree的降序排序,并去、从0开始取前1行数据。
select s_no,c_no,degree from score order by degree desc limit 0,1;
使用BETWEEN可以实现某个字段在某个范围的查询。如下所示的语句可以查询degree的范围在60到80之间的数据。
select * from score where degree between 60 and 80;
SQL中关于日期的函数
now()返回当前日期时间,使用的sql语句为select now(),查询出的格式为2021-03-17 14:44:06;
curdate()返回当前日期,使用的sql语句为select curdate();查询的格式为2021-03-17。
curtime()返回当前时间,使用的sql语句为select curtime();返回的格式为14:46:00。
date(date)提取时间的日期部分,使用的sql语句为select date(now());,返回的格式为2021-03-17。
DATEDIFF(date1,date2)计算两个日期之间间隔的天数,(时分秒不参与计算)。
SELECT TIMESTAMPDIFF(DAY,'2012-10-01','2013-01-13');这里的TIMESTAMPDIFF是计算两个日期的天数差
SELECT TIMESTAMPDIFF(MONTH,'2012-10-01','2013-01-13');这里是计算两个日期的月差
SELECT TIMESTAMPDIFF(second,'2012-10-01 11:00:00','2013-01-13 12:00:00');这里是计算两个日期之间的秒差
DATE_FORMAT(date,"日期格式"),SQL语句为select DATE_FORMAT(now(),"%Y-%m-%d")。按照自定义格式输出日期,将now()换成具体的字段。
SQL的分组查询和多表查询
对于分组查询,我们通常是将查询的某个分组里面的所有数据的平均数,或者是总数等等。常见的分组查询语句如下所示。该查询语句是以c_no为分组查询score表中的c_no,以及每个分组的平均值和总数。其中c_no是模糊查询,查询的是以3开头的c_no。
其中HAVING表示条件判断,通常与group by联合使用,用以对分组后的组别进行判断。
SELECT c_no, AVG(degree), COUNT(*) FROM score GROUP BY c_no HAVING COUNT(c_no) >= 2 AND c_no LIKE '3%';
对于多表查询,是指将两个表或者多个表通过外键约束将两个表或者多个表的某些行连接在一起,并将两个表中的字段组合在一起返回。具体的示例如下所示。其中name是student表中的字段,而c_no和degree是score表中的字段,两个表通过student.no=score.s_no作为条件判断。
select name,c_no,degree from student,score where student.no=score.s_no;
sql的子查询以及UNION和以及UNION ALL、NOTIN的使用
sql的子查询是指在一个查询的select语句中有两个查询的语句,其中的一个的查询作为另外一个查询的条件,就被称为子查询。具体的sql语句的格式如下所示。该sql语句先使用SELECT no FROM student WHERE class = '95031'查询到了class为95031的所有no,然后再查询到的no作为条件,查询score表中的s_no,c_no,degree。
SELECT s_no, c_no, degree FROM score
WHERE s_no IN (SELECT no FROM student WHERE class = '95031');
UNION用来连接查询出来的两个不同的数据,查询的语句和效果如下所示。该查询语句的意义是查询计算机系和电子工程系中不同职称的教师。
SELECT * FROM teacher WHERE department = '计算机系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '电子工程系'
) UNION SELECT * FROM teacher WHERE department = '电子工程系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '计算机系'
);

UNION操作会对查询出来的两组结果进行去重处理且排序,而UNION ALL是将查询出来的结果联合在一起,并没有去重和排序的处理,具体的区别如下所示:




SQL语句中的条件查询
条件查询是指在查询的时候用到 > 、< 等作为值的判断,具体的sql语句的格式如下所示,该语句的意思是查询比s_no为105的最大的degree要小的数据。
SELECT * FROM score WHERE degree < (
(SELECT MAX(degree) from score where s_no='105')
);
条件查询还可以与分组查询结合起来,具体的格式如下所示,该查询语句可以查询以class为分组条件,且组内数据大于1的组。
SELECT class FROM student WHERE sex = '男' GROUP BY class HAVING COUNT(*) > 1;
条件查询也可以和all和any联合使用,any表示符合sql语句中的任意条件,具体的sql语句的格式如下所示。该sql语句的含义是在 3-105 成绩中,只要有一个大于从 3-245 筛选出来的任意行就符合条件。该sql语句的意思是在 3-105 每一行成绩中,都要大于从 3-245 筛选出来全部行才算符合条件。
SELECT * FROM score WHERE c_no = '3-105' AND degree > ANY(
SELECT degree FROM score WHERE c_no = '3-245'
) ORDER BY degree DESC;
条件查询和all联合使用的格式如下所示:
SELECT * FROM score WHERE c_no = '3-105' AND degree > ALL(
SELECT degree FROM score WHERE c_no = '3-245'
);
SQL语句中的连接查询
连接查询是将两个表的通过某个字段查询合在一起,虽然从效果上来说连接查询和多表查询的结果一样,但是连接查询时先做hash再匹配,查询效率是O(logN),效率较高。对于多表查询的话,先查询再筛选,效果是O(n^2),效率较慢。连接查询又被分为内连接,左外连接,右外连接和全外连接。
对于连接查询的测试,我们需要先准备一些数据,数据准备的sql语句的代码如下所示,我们创建了两个表,分别是person表和card表。对于person表来说,有三个字段,分别为id、name、cardID。card表有两个字段,分别是id和name。
CREATE TABLE person (
id INT,
name VARCHAR(20),
cardId INT
);
CREATE TABLE card (
id INT,
name VARCHAR(20)
);
INSERT INTO card VALUES (1, '饭卡'), (2, '建行卡'), (3, '农行卡'), (4, '工商卡'), (5, '邮政卡');
INSERT INTO person VALUES (1, '张三', 1), (2, '李四', 3), (3, '王五', 6);
对于内连接的话,可以使用INNER JOIN将两个表连接在一起,具体的查询语句如下所示,其中on表示要执行某个条件,查询结果如下所示:
SELECT * FROM person INNER JOIN card on person.cardId = card.id;

内连接是将符合要求的两个表的字段拼接在一起。
左外连接是指完整显示左边的表,右边的表如何符合条件就显示,不符合条件就补充null,左外连接的语句为 LEFT JOIN。查询语句和查询结果如下所示:
SELECT * FROM person LEFT JOIN card on person.cardId = card.id;
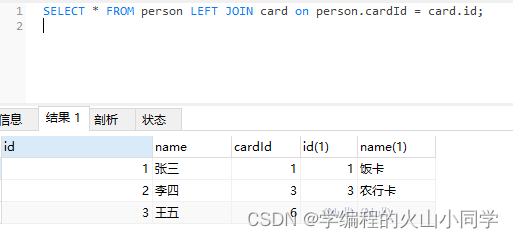
右外连接是指完整显示右边的表,左边的表如果符合条件就显示,不符合条件就补null。
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;

全外连接时指完整显示两张表的全部数据。全外连接是通过UNION实现的,sql语句和效果如下所示。
SELECT * FROM person LEFT JOIN card on person.cardId = card.id
UNION
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;
