1.选择合适的字段属性
- mysql中表越小,查询速度越快,所以,我们在创建表时,字段尽可能的设置最小,如果可以的话,可以用MEDIUMINT而不是BIGIN来定义整型字段。
- 应该尽量把字段设置为NOTNULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
- 对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。
2、使用连接(JOIN)来代替子查询(Sub-Queries)
用union all代替union
使用union关键字后,可以获取排重后的数据。而如果使用union all关键字,可以获取所有数据,包含重复的数据。
排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。所以如果能用union all的时候,尽量不用union。
SELECT*
FROM customerinfo
WHERE CustomerID
NOT in(
SELECT CustomerID
FROM salesinfo)
如果使用连接(JOIN)..来完成这个查询工作,速度将会快很多。尤其是当salesinfo表中对CustomerID建有索引的话,性能将会更好,查询如下:
SELECT *
FROM customerinfo
LEFT JOIN salesinfo
ON customerinfo.CustomerID=salesinfo.CustomerID
WHERE salesinfo.CustomerID
IS NULL
连接(JOIN)..之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
3、使用联合(UNION)来代替手动创建的临时表
临时表会被自动删除,从而保证数据库整齐、高效,使用union来创建查询的时候,我们只需要用UNION作为关键字把多个select语句连接起来就可以了
4.事务
事物以BEGIN关键字开始,COMMIT关键字结束
5.锁表
6.使用外键
7.使用索引
8.优化sql语句
- 在建有索引的字段上尽量不要使用函数进行操作
- 尽量不要使用like和通配符,以牺牲系统性能为代价
- 查询中尽量不要让mysql自动进行类型转换,这样也会使索引失效
- 只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
- 使用短索引,如果一个char(255)前面10-20数字都是唯一的,那么应创建指定长度的短索引
- mysql只会使用一个索引,如果where已经使用了索引,那么orderBy索引就不会生效,在数据库默认排序符合需求的时候,尽量不要使用排序,尽量不要给多个列进行排序,如果需要,应该给这些列建立复合索引
- like语句因使用‘%name’,而不是'%name%'导致索引失效
- 不要在列上进行运算操作,这样会导致扫全表,索引失效
- 不使用NOT IN和<>操作(都会导致索引失效),用not exist和>3 or<3代替!=和<>
.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10
union all
select id from t where Name = 'admin'
- in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
- 不要使用select * from t:select不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。此外,多查出来的数据,通过网络IO传输的过程中,也会增加数据传输的时间。
- 小表驱动大表:这个需求中,order表有10000条数据,而user表有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。
select * from order
where user_id in (select id from user where status=1)
循环插入io消耗过大,也不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
select id, create_date
from order
where user_id=123
order by create_date asc
limit 1;
使用limit 1,只返回该用户下单时间最小的那一条数据即可。
update order set status=0,edit_time=now(3)
where id>=100 and id<200 limit 100;
这样即使误操作,比如把id搞错了,也不会对太多的数据造成影响。
select id,name from category
where id in (1,2,3...100)
limit 500;
可以在sql中对数据用limit做限制。
- 增量查询,按条件分批查询
- 控制索引的数量(不超过五个)
-
提升group by的效率,先筛选,再分组
- 索引优化
索引优化的第一步是:检查sql语句有没有走索引。
那么,如何查看sql走了索引没?
可以使用explain命令,查看mysql的执行计划。
explain select * from `order` where code='002';

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:
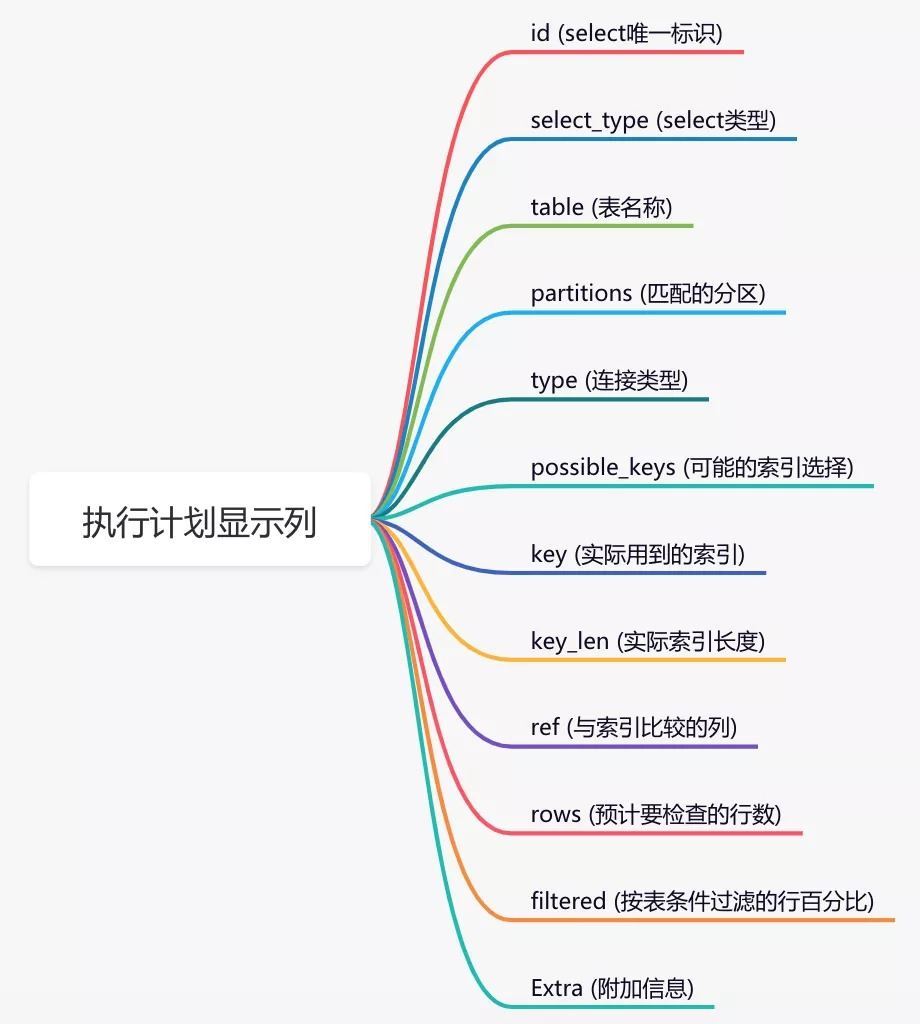
如果没有走索引,排除没有创建,那么就是失效了,检查sql原因改就行
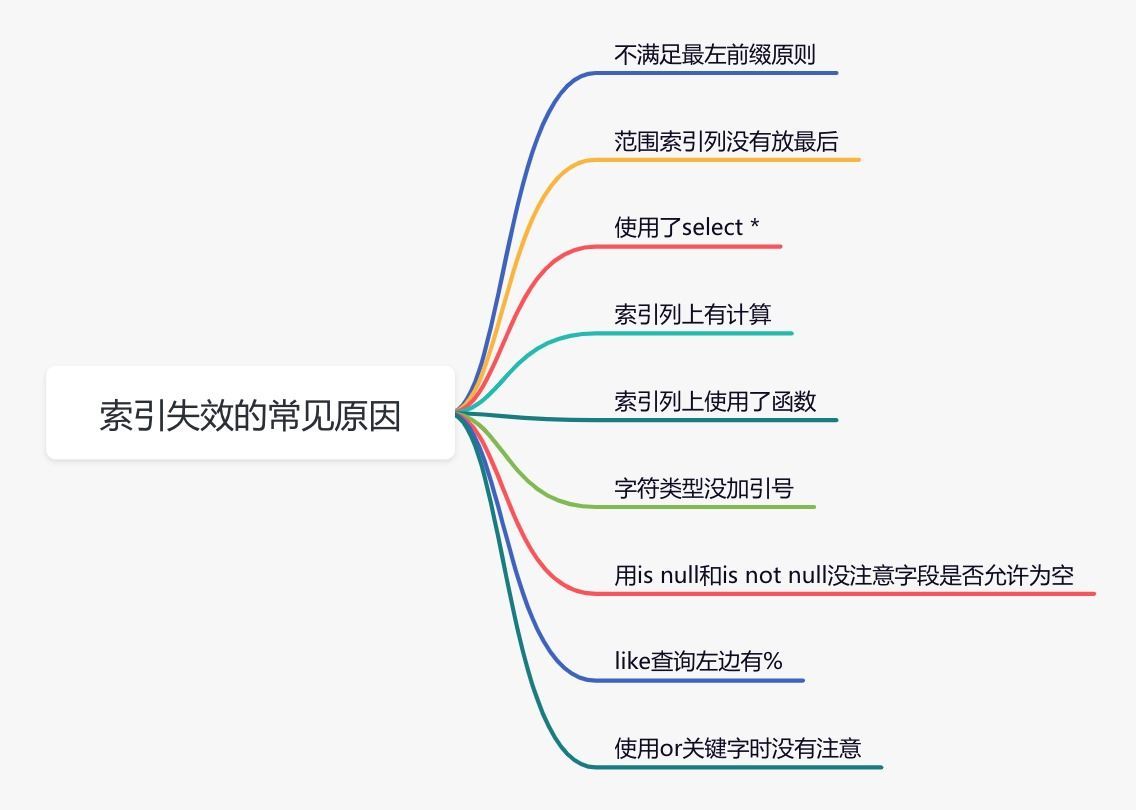
有时候mysql会选错索引。
必要时可以使用force index来强制查询sql走某个索引
- 查看详细信息:show PROFILE cpu,block io for QUERY id;
-
Show Profile 是 MySQL 提供的可以用来分析当前查询 SQL 语句执行的资源消耗情况的工具,可用于 SQL 调优的测量。默认情况下处于关闭状态,开启会消耗一定的性能,一般在 SQL 分析和优化的时候使用,只保存最近15次的运行结果。