如果没有数据的时候,那只能通过正则或者规则来解决问题 但是有些基于概率的方法,必须有一定的数据 首先我们要对句子进行切分,使用分词 接着进行预处理:拼写纠错、stemming(将不同的单词转换到原型)、停用词过滤(a, an)、单词顾虑() 同义词等 之后进行文本表示:将文本转换成向量,这样可以使用各种公式去处理。tfidf,word2vec,seq2seq 接着计算相似度,给定两个向量计算相似度 根据相似度进行排序,排序后返回结果
分词工具 最常用的还是jieba,中文分词工具 分词一定得有一个词典库,
贪心算法:选择当前最好的解,不能保证全局最优 DP动态规划算法:可以降低复杂度,能保证全局最优
算法具备的能力, 当分词工具没达到需要的效果,要会去修改算法, 弥补不足 但是这种分词工具是没有开源的
最大匹配算法是一种贪心算法 最大匹配缺点:细分不能做到更好,局部最优、效率低(依赖max_len),歧义(不能考虑语义)
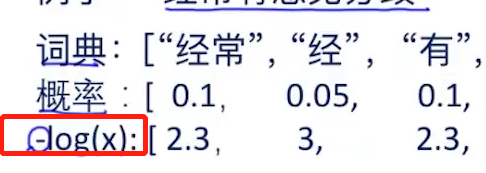
将生成的所有分词结果输入到语义工具,然后返回一个分割最好的结果 这种工具最经典的是语言模型 LM 先对一篇文章的单词出现概率进行统计,比如有简单的unique gram LM 那么每次单词当作独立事件考虑,计算一个句子的概率就是单词概率的乘积。 然后分出的哪个句子概率高就输出哪句 但是这种考虑单词概率的方式存在问题:如果这个单词出现概率很低,那相乘的结果就会很小, 进而导致计算机underflow\overflow 处理的方式就是在概率前加log,因为log函数是单调递增的(默认以10为底),概率只关心比较大小, 所以完全可以使用log,这样就把乘法变成了加法,加法是不容易出现overflow的
这种分两步:1、生成所有的可能分词情况,2、取出每个单词的出现概率,通过语言模型然后选出最好的。 但是这样复杂度太高 将两步合成一步,然后经过viterb算法,将整个流程优化,
log前加负号,是因为统计中偏向于找最小的,加负号可以让原来最大的变为最小项。同时x小于1,对数函数y是负数,加负号将其变为正数结果 下面将两步合并一步,把分词所有情况和计算句子概率合并一步 找那个最小的概率和,就是最好的结果 这时需要使用viterb算法来找最小概率,也就是一个最短路径 我的理解就是从最后一个结点每次找他的前驱结点的最短路径,最后找到开始结点,就组合成最短路径
拼写纠错是所有电商网站、搜索引擎的核心,搜索相关岗位都会用到 最短编辑距离:通过多少操作才能把候选单词,转换成目标单词 编辑距离三个操作:insert、delete、replace,三个操作没有次序,需要哪个操作使用哪个 编辑距离也是DP算法 比如上边用户输入 : three候选词thesis 要计算编辑距离,首先e后插入s,然后r替换为i,第二个r替换为s,所以这个编辑距离就是3 计算出这些候选词的编辑距离,最小的为there\their 返回哪一个呢?这时候要根据上下文或候选词的词频来判断
了解DP算法:https://people.cs.clemson.edu/~bcdean/dp_practice/ 从候选词中计算最小编辑距离的方法,要遍历整个的词典,这显然是不合适的,时间复杂度特别高
替代方法:用户输入后,通过三种操作add\delete\replace,生成编辑距离为1或者2的字符串,在这个范围当中进行拼写纠错 之所以选编辑距离1和2,因为可以覆盖绝大多数的字符串情况 如何选择出最有可能字符串c? 也就是计算p(c|s)概率的最大值,通过贝叶斯定理,得p(c|s) = p(s|c)*p©/p(s), p(s)是固定的,常量,可以不考虑,所以最终就是计算p(s|c)*p© p(s|c)表示的是在正确字符串为c的条件下,是s的概率,比如正确字符串是apple的情况下,用户输入是apple的概率p(s|c) 这个概率可以通过前期统计文章获得