最近正在下载关于ScanNet的数据集,希望做一个深度的调查,以供自己学习
背景
作者是Angela Dai 是斯坦福大学的一名博士生,她最初的想法是,推动数据匮乏的机器学习算法的发展,特别是在 3D 数据上。
Scannet数据采集框架
- 收集3D重建数据,用有效的方式对数据进行标注,来收集更多数据。团队通过收集RGB-D的视频序列,通过ipad应用加深传感器而收集的,然后视频会被上传到服务器,并被自动重建。然后,视频会被给到亚马逊 Mechanical Turk,将标注工作众包出去。就是下面的这个女人::

- 数据标注是在一个给定的3D场景中,绘制出物体,可以是椅子、桌子或者计算机,从而了解每个物体,以及对应的所在位置。每个图像通常需要5个人来标注。所得数据可以在做物体分类这样的训练任务。主要的任务就是给3D数据赋予语义解释,这样有利于机器人更好的理解世界。
ScanNet数据集
-
数据集介绍:一共1513个采集场景数据(每个场景中点云数量都不一样,如果要用到端到端可能需要采样,使每一个场景的点都相同),共21个类别的对象,其中,1201个场景用于训练,312个场景用于测试
- **2D数据:**由于2DRGB-D帧的数据量特别大,作者提供了下载较小子集的选项scannet_frames_25k(约25,000帧,从完整数据集中大约每100帧进行二次采样)通过ScanNet数据下载,有5.6G,还有基准评估scannet_frames_test这个,下图是下载scannet里面的
PREPROCESSED_FRAMES_FILE = ['scannet_frames_25k.zip', '5.6GB']
TEST_FRAMES_FILE = ['scannet_frames_test.zip', '610MB']

数据包括2D数据和3D数据
-
2D:包括每一个场景下的N个帧(为了避免帧之间的重叠信息一般取的时候隔50取一帧)2D标签和实例数据提供为.png图像文件。彩色图像以8位RGB的形式提供.jpg,深度图片为16位 .png(除以1000可获得以米为单位的深度)上面这张图代表第一场景第980帧,长宽分别为640*480

下面分别是提取出来的(按顺序为):color,depth,instance-label,label(包),and corresponding pose
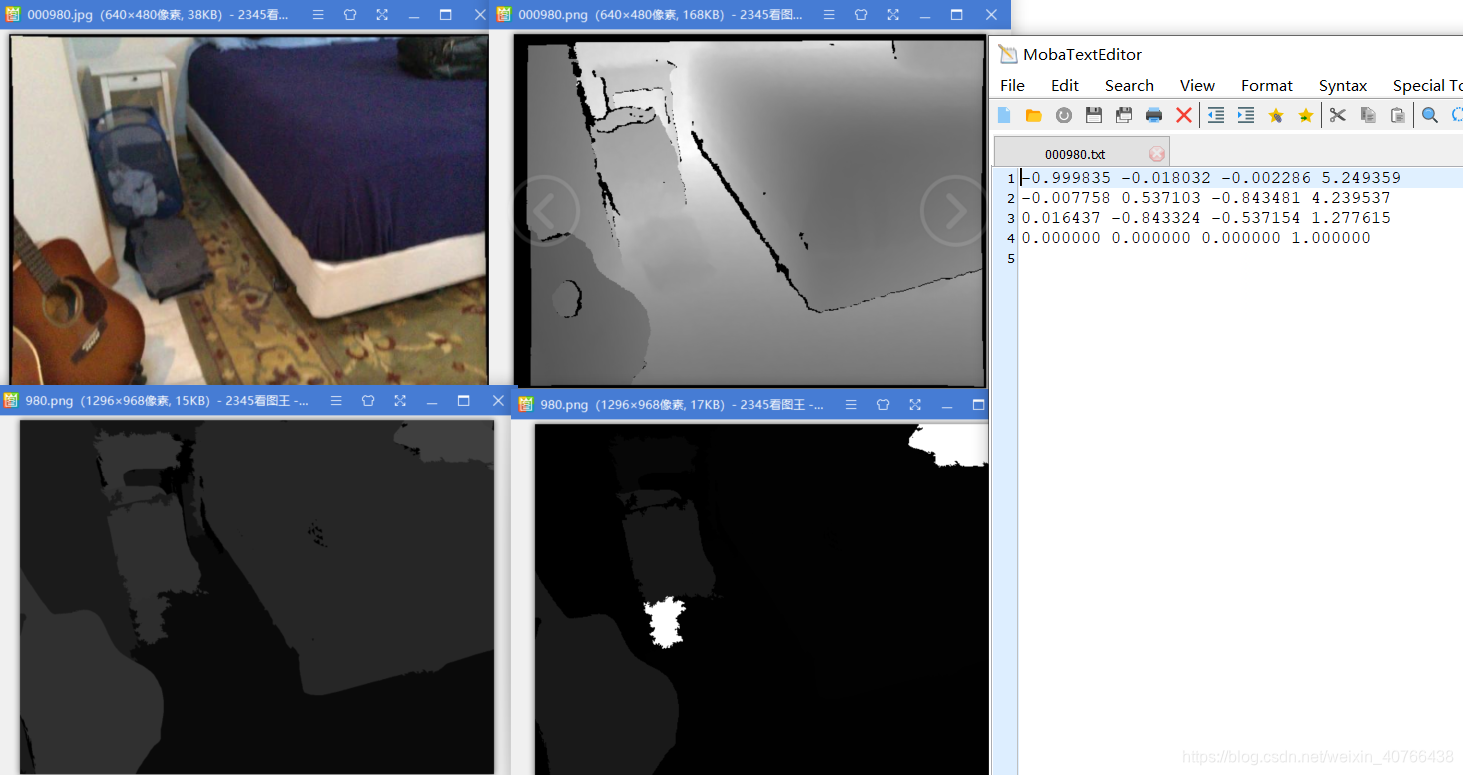
ScanNet版本随附的2D数据(* _2d-label.zip,* _ 2d-instance.zip,* _ 2d-label-filt.zip,* _ 2d-label-filt.zip)的格式如下:
- 标签图像: 16位.png 每个像素存储 ID 来自的值 scannetv2-labels.combined.tsv (0对应于未注释或没有深度)。比如7代表包,那么这个像素值存储的就是7
- 实例图片: 8位.png 其中每个像素为每个不同的实例存储一个整数值(0对应于未注释或没有深度)。
作者还提供了ScanNet帧的预处理子集, scannet_frames_25k。这些标签和实例图像已经过预处理,因此其格式与以前的格式不同,如下所示:
- 标签图像: 8位.png 每个像素存储 nyu40id 来自的值 scannetv2-labels.combined.tsv (0对应于未注释或没有深度)。如下id1代表wall

- 实例图片: 16位.png 其中每个像素为每个与之对应的实例存储一个整数值 标签* 1000 + ins,label代表nyu40id里面的label,而inst代表图片中各自label的第几个实例,用于计算图像中各个标签的实例。请注意,墙壁,地板和天花板不包含实例,并且0对应于未注释或没有深度。
- 3D data
- 3D数据随RGB-D视频序列以及重建的meshes一起以.ply的形式提供
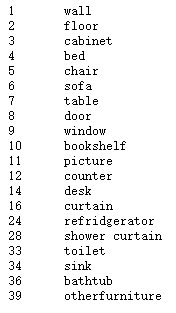
类的标签和对应的ids
-
2D/3D 语义标签以及实例预测:作者使用Nyuv2数据里的标签。并且在20类上进行评估。对于实例的评估是不把墙和地板算在内的。作者按照原样着色_vh_clean_2.labels.ply
-

-
场景类型分类 ScanNet数据集有21种不同的场景类型,作者只对13类子集进行评估


评估提交的东西
3D
- 语义标签预测的格式:每个顶点要有一个类,然后这个顶点要和_vh_clean_2.ply文件契合,同时每个预测文件每个顶点包含一行,每行包含预测类的整数标签ID。如下格式,每个txt应该是
10
10
2
2
2
⋮
39
然后每个场景应该是
unzip_root/
|-- scene0707_00.txt
|-- scene0708_00.txt
|-- scene0709_00.txt
⋮
|-- scene0806_00.txt
3D语义实例预测的格式:
对于每一个测试扫描的场景要提供一个text文件,在txt文件中,每一个实例要包含一行,其中包含该实例的二进制掩码的相对路径,预测的标签ID和预测的可信度,因此预测的文件提交格式是:
unzip_root/
|-- scene0707_00.txt
|-- scene0708_00.txt
|-- scene0709_00.txt
⋮
|-- scene0806_00.txt
|-- predicted_masks/
|-- scene0707_00_000.txt
|-- scene0707_00_001.txt
⋮
其中每个txt应该是:
predicted_masks/scene0707_00_000.txt 10 0.7234
predicted_masks/scene0707_00_001.txt 36 0.9038
⋮
而预测实例文件下的txt应该是
0
0
0
1
1
⋮
0
2D
2D语义标签预测格式
提交包含每个测试图像的结果图像,就是画画绿绿的那种图罗
场景类型分类的格式
结果必须作为单个文本文件提供,其中包含每次扫描的一行及其预测的场景类型,并用空格分隔。例如,示例提交example_scene_type_classificiation.txt 应该看起来像:
scene0707_00 1
scene0708_00 2
scene0709_00 3
⋮
scene0806_00 14
数据集处理