CPU每次访问虚拟内存,虚拟地址都必须转换为对应的物理地址。从概念上说,这个转换需要遍历页表,页表是三级页表,就需要3次内存访问。就是说,每次虚拟内存访问都会导致4次物理内存访问。简单点说,如果一次虚拟内存访问对应了4次物理内存访问,肯定比1次物理访问慢,这样虚拟内存肯定不会发展起来。幸运的是,有一个聪明的做法解决了大部分问题:现代CPU使用一小块关联内存,用来缓存最近访问的虚拟页的PTE。这块内存称为translation lookaside buffer(TLB)。
TLB的工作机制如下。对于一次虚拟内存访问,CPU搜索TLB中要访问的内存页的页号(page number),称为TLB查找(TLB lookup)。如果可以找到与虚拟页号匹配的TLB条目,称为发生TLB命中(TLB hit),CPU就会使用TLB条目中存储的PTE来计算目标物理地址。现在,TLB使虚拟内存成为现实的原因是它很小——一般几十个——可以直接在CPU中构建并且使CPU全速执行。这意味着只要TLB中能找到转换条目,访问虚拟内存就跟访问物理内存一样快。实际上,现代CPU在虚拟内存中运行的更快,因为TLB记录还包含了访问特定内存是否安全的信息(例如,预取指令)。
如果没有找到与虚拟页号匹配的TLB记录会发生什么?会触发一个TLB未命中(TLB miss)事件,这与CPU架构相关,处理方式有两种:
- 硬件处理TLB未命中:在这个方案中,CPU会遍历页表,找到正确的PTE。如果能够找到PTE并且标记是存在的(present),CPU就会把新的转换信息放到TLB中。否则,CPU会发起一个页错误并将控制权限交给操作系统。
- 软件处理TLB未命中:在这个方案中,CPU就简单的发起一个TLB未命中错误。由操作系统来处理这个错误,调用TLB未命中处理方法。未命中处理程序通过软件的方式遍历页表,如果能够找到标记为present的PTE,就会在TLB中插入新的转换信息。如果PTE找不到,由页错误处理程序来接管。
不论TLB未命中是由软件还是硬件处理,底层都会导致遍历页表,如果能找到标记为present的PTE,就会在TLB中更新新的转换信息。大部分CISC架构(比如IA-32)平台,TLB未命中使用硬件方式处理,大部分RISC架构(比如Alpha)使用软件方式处理。硬件的解决方案通常比较快,但是缺乏灵活性。实际上,如果硬件不太能满足操作系统需求的时候,性能优势会少很多。像后面提到的,IA-64提供了一个混合的解决方案,能够保留软件处理方式的灵活性,同时不会牺牲硬件处理方式的处理速度。
TLB替换策略
看一下TLB满(所有的TLB条目都在使用)的时候,CPU或者TLB未命中处理程序需要插入新的转换信息时会发生什么。现在的问题是,要删除或者重写哪条,让新的数据插入进来。这个由TLB替换策略(TLB replacement policy)来选择。通常会使用一些类似LRU的算法来。根据LRU算法,最长时间未使用的数据会被替换掉。替换策略的精确选择通常依赖于这个策略是通过硬件还是软件实现的。硬件的解决方案倾向于简单的策略,比如最近未使用(not recently used, NRU),然而软件解决方案可以使用完全的LRU甚至更复杂的方法都不会有什么问题。
注意,如果TLB未命中处理程序是由硬件实现的,很明显替换策略也必须由硬件实现。然而,对于软件实现的TLB未命中处理程序,替换策略可以用硬件实现,也可以用软件实现。一些架构(例如MIPS)采用软件替换策略,但是很多新的架构,包括IA-64,提供了一个硬件替换策略。
删除TLB中旧记录
最后一个挑战是怎么使TLB保持与基础的页表同步(synchronized) (或一致 coherent)。与其它缓存一样,必须考虑到避免TLB包含了一些失效的脏记录。很多场景都会导致脏记录。例如,当一个虚拟页换出到磁盘,页表上对应的PTE会标记为不存在(not present)。如果这个页还包含一个TLB记录,那就是脏记录(因为TLB中仅存在标记为present的PTE记录)。类似的,一个进程可能把文件映射(map)到内存,在映射区域访问了访问了几页,然后释放文件映射(unmap)。这个时候,TLB中可能仍然包含访问过的映射区域对应的记录,但是因为这个映射已经不存在了,所以这些记录都是脏的。目前,创建最多的脏记录的情况是从一个进程切换到另一个进程的时候。因为每个进程都有自己的地址空间,上下文切换的时候整个TLB都是脏的。
考虑到导致脏记录的数目和复杂性,这应该由操作系统来保证这些脏记录造成破坏之前来刷新掉它们。不同的CPU架构提供了不同的TLB刷新指令。典型的指令包括刷新整个TLB、指定虚拟页或者一个指定地址范围内的所有TLB记录。
注意到上下文切换通常要求刷新整个TLB。然而,因为这是一个普遍的操作并且TLB错误处理比较慢,CPU架构师经过多年的努力找到了多种策略来避免这个问题。这些策略也有很多种名字,像address-space nmbers, context numbers, 还有region IDs,但是它们的基本想法是一样的:扩展匹配TLB记录的标记,不仅包含虚拟页号,还包含这个地址空间的唯一标识,判断这些转换信息属于哪个进程(地址空间)。CPU也扩展出来包含一个新的寄存器asn,标识当前执行进程的地址空间。这样,当搜索TLB时,CPU会忽略唯一标识不符合asn寄存器的记录。有了这个方法,上下文切换仅仅更新asn寄存器就可以了,不用再刷新TLB。事实上,这个策略让多个进程共享TLB成为现实。
IA-64 TLB架构
IA-64架构使用了一种有趣的方法来提升虚拟地址到物理地址的转换效率。与普通的TLB不同,还有另外3个硬件结构,两个region寄存器,一个protection key寄存器,用来提升LTB的效率。第三个是虚拟哈希表遍历(virtual hash page table walker VHPT walker),用来减少TLB未命中的损失。
图4.29描述了IA-64 CPU怎么将虚拟地址转换到物理地址。先从图的右上角开始。这里有一个虚拟地址,分成三个字段:虚拟域号 vrn(virtual region number),虚拟页号vpn(virtual page number)和页偏移量字段。
通常,页偏移量不会参与到转换中,而是直接复制偏移量字到物理地址,如图中右下角所示。相反,3bit的域号(region number) vrn首先放到域(region)寄存器中,图中左上角。域寄存器通过vrn检索出来,将region ID的值发送给TLB。在TLB中,region ID与虚拟页号vpn关联起来组成region ID/vpn 键值,用来搜索TLB。如果某条记录与搜索的键值匹配,记录中剩下的字段提供一些必要信息来完成这个地址转换。具体的就是pfn字段提供页帧号(page frame number)与虚拟页号关联。这个字段也可以复制到物理地址中对应的字段。内存属性字段ma指示这个内存访问是否可以缓存。如果可以,物理地址中的uc字段(bit 63)被清零;否则,设置为1。最后两个字段,+rights(正权值)和键值,用来检测内存访问的权限。字段提供了一系列权值(positive rights)用来控制在什么权限级别(用户层或内核层)下可以做什么访问(读、写或执行)。键值(key)字段放到保护键值寄存器(protection key registers)中。这里,与寄存器匹配的键值对读取出来,它的 –rights(负权值)字段提供了禁止权限(negative rights)来完成权限检测。具体点说就是-rights指定的任何访问都是禁止的,即使+rights字段是允许的。如果没有寄存器与键值对匹配,会发出一个键值未命中错误(KEY MISS FAULT)。操作系统可以解释这个错误并且决定是否安装这个未命中的键值,或者采取一些其它的动作(比如终止进程)。从这个角度来讲,CPU已经拿到了物理地址,并且还有内存访问权限的信息,因此转换完成。
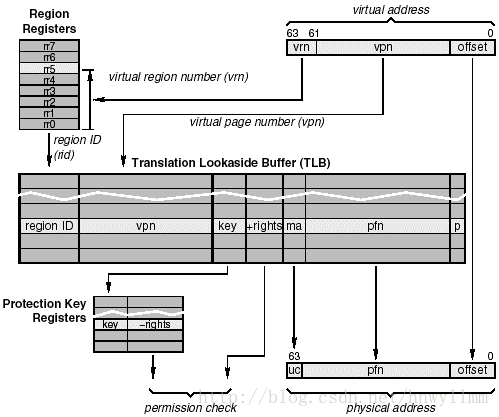
图4.29 IA-64 虚拟地址转换硬件
TLB记录中还有一个不常用的字段present。Linux内核从来不会将不存在的页转换信息插入进去,但是VHPT walker可能会这么做。
TLB结构和管理策略
图4.30描述的是, IA-64逻辑上分成了4个独立单元。左边的是指令TLB(instruction TLB, ITLB),转换指令地址;右边的是数据TLB(data TLB, DTLB), 转换数据地址。ITLB和DTLB又被分成转换寄存器(translation registers, ITR和DTR)和转换缓存(translation caches,ITC和DTC)。这两者之间的区别是实现的替换策略:对于转换缓存来说,硬件(CPU)实现了替换策略,然而对于转换寄存器,替换策略由软件实现。换句话说,当在转换寄存器中插入一个TLB记录时,必须同时制定TLB记录和转换寄存器的名称(比如itr1)。相反,在转换缓存中插入记录只需要制定TLB记录——硬件会找到一个已经存在的记录并且用新的替换。

图4.30 IA-64 TLB构造
这个架构保证了ITC和DTC最少有一个记录。当然,一个真正的CPU一般都会在每个缓存中实现几十个记录。例如,安腾(Itanium)实现了96个ITC记录和128个DTC记录。即使这样,为了保障正确运行,操作系统在任何时间都不应该假设缓存中可以存放超过一个记录。否则,当连续插入两条记录,硬件的替换策略可能在插入第二条记录的时候替换掉第一条记录。因此,操作系统必须通过某种方式保证程序正常运行,即使仅仅有第二个条目存在。
ITR和DTR都保证至少支持8个转换寄存器。然而,IA-64架构给硬件设计师留下了一个选项,标记一下转换缓存记录中的转换寄存器,就不会被硬件替换掉了。有了这个选项,用的转换寄存器越多,转换缓存中的记录就会越少。由于这个原因,通常会分配与真实需要一样多的转换寄存器,而且分配这些是为了增加寄存器索引。
Linux/ia64使用转换寄存器保存特定标准代码区域和数据结构。例如,内核中使用一个ITR记录来保存TLB错误处理程序,另一个用来映射不能产生TLB未命中错误的固件代码。与此类似,内核使用一个DTR保存当前运行进程的内核栈。
VHPT walker和线性表虚拟映射
还有一个目前为止没有讨论的,当找不到与region ID/vpn对匹配的TLB记录会发生什么,比如TLB未命中。在IA-64上,可以使用二者之一来解决:如果开启,VHPT walker就会激活并且尝试填充未命中的TLB记录。如果VHPT walker被禁用,CPU会发起一个TLB未命中错误,这个错误由Linux内核解释。4.5节详细描述了软件如何处理TLB未命中。现在将重心放到VHPT walker如何处理TLB未命中。
首先注意使用VHPT walker是完全可选的。如果操作系统不使用它,IA-64让操作系统完全控制页表结构和PTE格式。为了使用VHPT,操作系统需要限制一些多样性。详细点说,VHPT walker可以支持两种模式之一:哈希模式和线性页表模式。对哈希模式,操作系统需要使用一个哈希表作为页表,PTE的格式是长格式(long format)。长模式下,每个PTE都是32字节大小。在线性页表模式下,操作系统需要支持一个虚拟映射线性页表,PTE的格式是短模式(short format)。短模式是Linux使用的。如图4.25所示,这种类型的PTE是8字节大小。
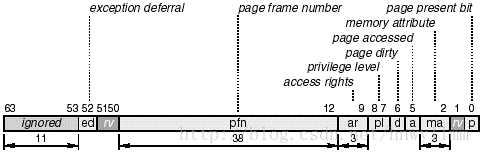
图4.25 IA-64的PTE格式(present设置为1)
通过页表地址(page table address)控制寄存器pta来配置VHPT walker。图4.31描述了这个寄存器。ve位控制是否开启VHPT walker。每个域寄存器(region register)中有一个控制位会进一步指明VHPT walker的操作。一个区域的TLB未命中发生的时候,只有这个控制位和pta.ve都是1才会激活VHPT walker。pta中第二个控制位是vf;它确定walker使用哈希(长格式 long-format)还是虚拟映射线性页表(短格式 short-format)模式。1表示哈希模式。假设ve是1(开启),vf是0(虚拟映射线性页表模式)。在这个配置下,base和size字段定义了线性页表在每个域中占用的地址范围。base字段包含了最重要的从表开始的域相关偏移量的49个位,size字段包含了表区间地址位的数量(比如表是2pta.size字节长)。

图4.31 IA-64 页表地址寄存器pta的组成
注意尽管VHPT walker可以每个域单独停用(通过域寄存器的一个位),对这些开启的域来说,线性页表映射到了每个域的相同相对地址范围。考虑到这个约束,放置线性页表的位置需要慎重选择。
图4.32描述了Linux/ia64使用的方案。有两个因素影响线性页表的替换。首先,为了不浪费虚拟地址空间,页表与普通的页表映射空间不能重合。图中区域底部的矩形描述了后者的空间。通常,在8KB页大小的三级页表中,跟在后面的地址都是有效的(valid)。其次,如果CPU不使用所有地址位的话(由IMPL_VA_MSB参数决定),域中间部分的地址会有空洞,页表可能不会和这部分空洞有重叠部分。图中中间部分区域的黑色阴影矩形描述了这个空洞。IMPL_VA_MSB = 50的情况下,它后面的地址是有效的(valid)。综合这两个因素,Linux/ia64将pta寄存器设置成一个值,这个值会使线性页表映射到域的顶部,如亮阴影矩形部分描述。注意对特定页大小和IMPL_VA_MSB的组合,页表映射空间可能交叉覆盖到未实现空间,也可能覆盖虚拟映射线性页表(当IMPL_VA_MSB = 60的时候)。Linux内核会在开机时间(boot time)检查,如果检测到有覆盖的情况,会打印错误信息并且挂起。
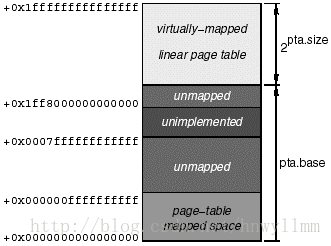
图4.32 Linux/ia64域下虚拟映射线性页表
现在看一下VHPT walker是如何运转的。当一个va虚拟地址发生了TLB未命中,walker会计算与va对应的Pte的虚拟地址va3。根据虚拟映射线性页表,这个地址这样计算:
va´ = Îva/261 ˚ ·261 + pta.base ·215+8 · (Îva/PAGE_SIZE˚ mod 2pta.size)
这就是说va3 就是域基址(base address)、线性页表中域偏移量与线性页表中PTE的偏移量的和。最后一个加数,乘上一个8,因为每个PTE都有8个字节大小,而且取模运算去掉了不会被页表映射的最重要的地址位。接着VHPT walker尝试读取这个地址的PTE。因为这还是一个虚拟地址,CPU会继续正常的虚拟地址到物理地址的转换。如果存在va3的TLB记录,这个转换就成功了,walker就可以从物理内存中读取PTE然后安装va的PTE。然而,如果va3的TLB记录不存在,walker就会结束,然后通过发起VHPT转换错误(VHPT TRANSLATION FAULT)来请求协助。
需要强调一下VHPT永远不会遍历Linux页表。不可能这么做的原因是它不知道Linux使用的页表结构。例如,它不知道页表树有多少层级,也不知道每一层级有多大。但是为什么仅仅当线性页表对应的TLB记录已经存在时,使用VHPT walker可以处理TLB未命中? 原因就是引用的空间局限性。想一下一个TLB记录映射到一个特定的PTE,其实就是映射了PTE的一整页。这样的话,一个页表的TLB记录安装后,所有相同页中的PTE对应的TLB未命中都可以使用VHPT walker处理,避免了TLB未命中错误的消耗。例如,一个大小为8KB的页,每个页表的TLB记录映射8KB/8=1024个PTE,就是1024 * 8KB = 8MB的内存。换句话说,当顺序访问内存的时候,从一次一页到一次1024页,VHPT walker会减少TLB未命中的错误!考虑到现代的CPU处理一个错误的消耗,VHPT walker是非常有潜力来大大提高性能的。
另一方面,如果以一种极端的零散随机方式访问内存,线性表会失去优势,因为这个页表的TLB记录占据的空间没有这么大的优势。例如,再次假设一个页大小8KB,最极端的场景是每隔8MB访问一个字节。这种情况下,每次内存访问都会有两次TLB记录:一次是访问页的时候,另一次是对应的页表。这样的话,TLB的效率会有两倍的降低!幸运的是,极少有应用程序会用这种极端的访问模式,因此这通常不会有什么问题。
最后一个提醒值得指出,Linux/ia64使用的虚拟映射线性页表不是自映射(self-mapped)虚拟页表(请看4.3.2)。二者性质很相近,但是IA-64页表全局目录中没有自映射(self-mapped)记录。因为根本不需要。自映射记录只有在虚拟页表访问全局和中间目录记录时才会访问。因为Linux/ia64不会这样做,所以不需要自映射记录。另一种找到这种情况的方法就是,将虚拟页表看做只会在TLB中存在:如果虚拟页表中的页已经在TLB中映射,就可以通过PTE目录访问,如果没有映射,就需要一个典型的页表遍历。
Linux/ia64 区域和保护键寄存器(the region and protection key registers)
现在返回图4.29,进一步查看区域和保护寄存器的工作方式以及Linux是如何使用它们的。两个寄存器文件都完全由操作系统控制,IA-64架构没有指定如何使用它们。然而,已经很清晰的设计了特殊的用途。具体的说,区域寄存器(the region register)提供了多进程间(地址空间)共享TLB的方法。例如,如果一个唯一的域ID赋值到每个地址空间,对于不同地址空间的相同虚拟页号vpn记录,可以在同一个时间保留在TLB中,因为域ID不同,它们仍然是不同的。通过域ID的这种使用方法,上下文切换不再需要刷新整个TLB。相反,只需要简单的加载新进程的域ID到对应的域寄存器即可。这样减少TLB刷新可以让某些应用显著的提升性能。还有,因为每个域有自己的域寄存器,在相同的时间甚至可能有部分不同的地址空间是有效的。Linux内核是这样使用的:将内核的域ID固定的安装在rr5-rr7,将当前运行的进程的域ID安装在rr0-rr4。通过这个步骤,内核的TLB记录和会变化的用户层进程TLB记录就可以共存,不会有任何困难和浪费。
域寄存器使不同进程间共享整个TLB成为可能,保护键寄存器(protection key register)使进程间共享“私有”TLB记录成为可能,即使进程中TLB记录映射的页必须使用不同的访问权限。对应的页的TLB记录要根据拥有者的需要安装对应的访问权限(+right)。键字段要设置成共享对象的唯一标识值。通过使用一个保护键寄存器,将对象的唯一标识映射到对应的负权限(-rights)集合,操作系统可以设置一个进程的严格访问权限。这种细粒度的TLB共享,有可能极大的提高TLB利用率,比如共享链接库。然而,短格式模式的VHPT walker不能利用保护键寄存器的优势,而且由于这个原因,Linux清掉处理器状态寄存器的pk位禁用了这个功能(看第2章,IA-64架构)。
TLB一致性维护
为了保证Linux内核的正常运行,TLB必须保持与页表一致。为了做到这点,Linux定义了一些接口,从不同平台中抽象出来,指定如何刷新TLB。这些接口在图4.33中描述,称为TLB刷新接口(文件 include/asm/pgalloc.h)。
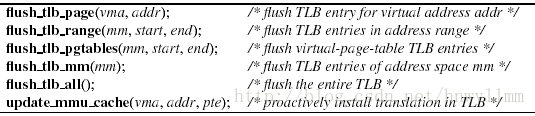
图4.33 维护TLB一致性的内核接口
第一个函数是flush_tlb_page()。刷新一个特定页的TLB记录。这个函数需要两个参数,一个vm-area指针vma,一个虚地址addr。后面那个参数是要刷新的TLB记录的页的地址,前面那个指针指向包含这个页的vm-area结构体。因为vm-area结构体有一个指向包含了这个vm-area的mm结构体的指针,vma参数间接的标明要刷新的TLB记录的地址空间。
第二个函数,flush_tlb_range(),刷新与任意地址范围虚拟页对应的TLB记录。需要三个参数:一个mm结构体指针mm,一个起始地址start,和一个结束地址end。mm参数指定了要刷新的TLB记录的地址空间,start和end指明了要刷新的TLB记录的第一个和最后一个虚拟页。
第三个函数flush_tlb_pgtables,刷新与虚拟映射线性页表对应的TLB记录。不适用虚拟页表的平台什么都不做。对其它平台,mm参数表示要刷新的TLB地址空间,start和end指定要刷新的虚拟页表TLB记录对应的地址范围。
第四个函数flush_tlb_mm(),刷新指定地址空间的所有TLB记录。这个地址空间用参数mm指定,mm是一个指向mm结构体的指针。平台不同,这个函数可以真正的刷新相关的TLB记录,也可能仅仅简单的赋值给mm一个新的地址空间号。
注意,这四个函数可能刷新的TLB记录比请求的要多。比如,如果某个平台上没有刷新特定TLB记录的指令,实现flush_tlb_page()的时候,刷新整个TLB也是正确的。
下一个函数,flush_tlb_all()刷新整个TLB。如果前面几个细粒度的函数都没有合适的,这就是最后一个选择。根据定义,这个函数会刷新包含内核页的TLB记录。因为这是唯一一个能这样做的函数,任何与页表映射内核段或者kmap段相关的地址转换变化,都必须调用这个函数。由于这个原因,调用vmalloc和vfree会消耗很多。
最后一个函数是update_mmu_cache()。与刷新一个TLB记录不同,这个可以主动建立一个新的转换。这个函数需要三个参数:一个vm-area指针vma,一个虚拟地址addr和一个页表入口pte。Linux内核使用这个函数通知特定平台,addr指定的虚拟页现在映射到了pte指定的页帧。vma参数指定包含了虚拟页的vm-area结构体。这个函数在页表改变的时候,给特定平台一个提示信息。因为这只是给一个提示信息,所以不会要求平台做任何事情。平台可以使用这个函数做平台特定的动作,或者第一时间在新的地址转换前集中更新TLB记录。然而,需要时刻注意的是,安装一个新的转换记录,一般就会替换掉一个已经存在的TLB记录,因此这种做法是不是好的,取决于正在使用的应用程序,还有平台的性能特征。
IA-64实现
在Linux/ia64上,flush_tlb_mm()的实现是通过参数mm强制分配一个新的地址空间号(域ID)给地址空间标识。逻辑上与清除指定地址空间上所有的TLB记录相同,但是相对于要求执行TLB清除指令来说是有优势的。
flush_tlb_all()基于ptc.e(清除转换缓存记录 purge translation cache entry)指令实现的,这个指令会清除TLB中一大块区域的数据。至于多大会被清除,依赖于CPU模式。刷新整个TLB的结构化指令是这样的:
-
long flags, i, j, addr = BASE_ADDR;
-
local irq_save( flags); /* 禁用中断 */
-
for ( i = 0; i < COUNT0; ++ i, addr += STRIDE0) {
-
for ( j = 0; j < COUNT1; ++ j, addr += STRIDE1)
-
ptc e( addr);
-
}
-
local irq restore( flags); /* 开启中断 */
其中BASE_ADDR, COUNTO, STRIDEO, COUNT1和STRIDE1都是CPU特定模式的值,可以从PAL固件中获取(请看第10章,Booting)。使用这样一个结构化的循环,而不是一条指令是为了保证刷新整个TLB,因为对于多级CPU上和不同类型的TLB,ptc.e更容易实现。例如,一个特殊的CPU模式可能有两级不同的指令和数据TLB,这就给使用单条指令自动清除所有TLB造成困难。然而,对安腾(Itanium)来说有个特例,COUNTO和COUNT1的值都是1,这就意味着一个单独的ptc.e指令就会刷新整个TLB。
其它的刷新函数都是基于ptc.l(清除局部转换缓存 purge local translation cache)或ptc.ga(清除全局转换缓存和ALAT purge global translation cache and ALAT)指令实现的。前面一个用于UP机器,后面一个用于MP机器。两个指令都有两个操作数——其实地址和大小——指定了需要清除TLB记录的虚拟地址范围。ptc.l指令仅仅影响局部TLB,因此通常会比ptc.ga快,ptc.ga会影响整个机器(请看架构手册中的精确定义[26])。在同一个时间只能有一个CPU执行ptc.ga。为了保证这点,Linux/ia64内核使用一个spinlock序列化指令的执行。
Linux/ia64使用update_mmu_cache()实现了缓存刷新功能,这个在4.6节会有更详细的解释。这个函数也可以用来主动在TLB中安装一个新的转换信息。不过Linux没有说明这个转换信息是用于指令执行的还是数据访问的,所以不能确切地知道这个转换应该安装在指令还是数据TLB(或者都是)。因为这个不确定性,还有安装一条新的转换信息常常会替换掉另一个,甚至更有用的一个TLB记录,所以最好避免主动安装TLB记录。
惰性(Lazy)TLB刷新
为了避免每次上下文切换时刷新TLB,Linux定义了一组接口,抽象了特定平台上地址空间号(address-space numbers ASNs)的不同工作方式。这组接口称为ASN接口(文件include/asm/mmu_context.h),如图4.34。是否支持这个接口是可选的,在不支持ASN的平台上定义一些空函数就可以了,flush_tlb_mm的替换实现是刷新整个TLB。

图4.34 管理地址空间号的内核接口
每个mm结构体都包含一个mm context的组件,包含一个特定平台类型的成员mm context type(mm_context_t,在include/asm/mmu.h中)。通常这个类型就是一个单字(signal word)数据,保存了地址空间的ASN。然而,一些平台会使用CPU本地的方式分配ASN。对这些方式,这个类型一般是一些字(word)的数组,第i个元素存储在CPU i上地址空间的ASN。
图4.34定义了4个函数。第一个函数init_new_contex()初始化新创建的地址空间的mm context。这个函数包含两个参数:一个task指针task和一个mm结构体指针mm。后面的参数是一个指向新地址空间的指针,前面的指针是创建它的task。通常,这个函数仅仅设置mm context为一个特殊的值(比如0),表示还没有分配ASN。成功时返回0。
剩下的函数都只有一个参数,一个mm结构体指针mm表示地址空间,在这里操作ASN。get_mmu_context()函数保证mm context包含一个正确的ASN。如果mm context已经是正确的,什么都不需要做。否则就会分配一个新的(未使用的)ASN,然后放在mm context上。它会临时使用进程号(pid)作为ASN。然而,因为execve()系统调用创建新地址空间时不会改变进程号,所以这样不行。
reload_context()函数负责激活当前CPU上的代表mm context的ASN。逻辑上讲,这个激活动作需要将ASN写入到CPU的asn寄存器,但是实际上这个动作具体怎么做,是依赖于平台的。调用这个函数时,需要保证mm context包含了一个正确的ASN。
最后,ASN不再使用时,Linux调用destroy_context()释放它。这个调用会标记用mm context表示的ASN可以被其它地址空间再次使用,并且释放在get_mmu_context()中申请的内存。即使调用这个函数之后ASN就可以重用了,TLB仍然可能包含这个ASN的旧转换信息。为了保证正常运行,特定平台代码需要在激活可重用ASN之前清除这些旧的转换信息。通常使用轮转的方式实现,并且在转一圈到第一个可用ASN时,刷新整个TLB。
IA-64实现
Linux/ia64使用域ID来实现ASN接口。mm结构体中的mm context包含了一个单字(single word)存储地址空间的域ID。0表示未分配ASN。因此init_new_context()函数简单的将mm context清为0。
IA-64架构定义域ID 24位宽,不过这取决于CPU模式,最少可以支持18位。例如,安腾(Itanium)架构上支持最小的18位宽。在Linux/ia64上,域ID 0是内核保留的,其余的ID可以供get_mmu_context()以轮转的方式使用。最后一个可用的域ID用掉后,会刷新整个TLB,然后计算一个新范围的可用域ID,并使当前正在使用的域ID都在这个范围之外。一旦找到了这个范围,get_mmu_context()就可以以轮转的方式继续分配新的域ID,直到这个范围再次用光,然后再次重复刷新TLB和查找域ID的可用范围。
域ID有18到24位宽,但是只有15到21位在Linux上是可用的。原因是IA-64要求TLB必须匹配域ID和虚拟页号(请看图4.29),但是不需要与虚拟域号(vrn)匹配。因此TLB可能区分不了,除非rr1和rr2中的域ID是不同的,比如0x2000000000000000到0x4000000000000000的地址。为了确保这单,Linux/ia64将vrn编码到域ID的三个最低位上。
注意,get_mmu_context返回的域ID是所有CPU共享的。这种全局域ID分配策略对UP来说是完美的,但是对一般的大型MP机器来说有点不足。有一个全局策略对MP机器是有利的,因为它使ptc.ga指令清除机器中所有的TLB转换信息成为可能。缺点是,全局域ID分配是一个潜在的竞争点,而且可能更差的是,机器上越多的CPU就会导致域ID空间更快的消耗。为了证明这一点,假设有8个不同的域ID,一个CPU平均一秒钟创建一个地址空间。对于一个单独的CPU,因为域ID空间耗尽的原因,TLB必须每8秒钟刷新一次。对于一个有8颗CPU的机器,每秒钟创建一个地址空间,全局分配策略就会导致TLB每秒钟刷新一次。相反的,本地策略会在UP上好一点,比如8秒钟刷新一次。但是必须使用处理器间中断(IPI,interprocessor interrupt)而不是ptc.ga来执行全局TLB刷新(因为每个CPU都使用它自己的域ID)。换句话说,局部和全局策略的选择,牵涉到典型的少量固定开销(ptc.ga对比IPI)与更好的灵活性(域ID空间的消耗速度和总量与每个CPU创建新地址空间的速度的比值相关)。
在IA-64上,reload_context()具有根据mm 上下文的值加载rr0到rr4域寄存器的作用。就像前面章节介绍的,真正在域寄存器中存放的值是mm上下文的值左移三位再放到编码域的vrn值最后面。
IA-64版本的destroy_context()什么都不用做。get_mmu_context()不会分配内存,所以这里也不需要释放。类似的,可用域ID范围仅仅在现存范围用光的时候才重新计算,因此这里不需要刷新TLB中旧的转换信息。
原文地址:
Translation Lookaside Buffer (TLB) | Virtual Memory in the IA-64 Linux Kernel | InformIT