-
持久化存储,(数据不会丢失)
a) 数据源;操作数据来源称为数据源
b) 数据汇;通过程序进行对数据进行操作,保存到新的目的地称为数据汇
c) 文件来源(数据源)有两种(暂时的和永久的)
i. 永久保存;文件(称为文件,数据运行后不会丢失)
ii. 暂时保存;键盘、控制台、内存(数据运行后会丢失,不能重复使用)
-
IO(输入输出流,一般指在数据是文件(永久保存)的作用上进行数据的交互)
a) 站在程序的角度上看,分为读与写两种
b) 读为input(也就是输入,简写为I)
c) 写为output(也就是输出,简写为O)
-
文件(一些数据的集合)
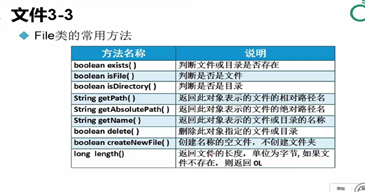
a) 文件保存在java.io包中(java .io.file)
b) 使用时用new来获得( File file=new File(String pathname) )是一个构造方法, String pathname 代表的是文件的路径名,是string类型(书写方法一般为;c:\text.txt或c:/text.txt,与在计算机中的书写有区别)
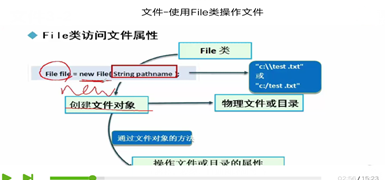
c) file可以是指文件,也可是指文件目录
-
路径
a) 相对路径;不是从盘符进行寻找的
b) 绝对路径;从盘符进行寻找的
-
获取file的长度返回的是字节(0L)(L是强制转换)(一个字符是两个字节)
-
使用的代码情况
//创建文件对象
File file=new File(“E:\JAVA文件输入输出案例实用\a.txt”);
//判断文件是否存在 System.out.println(file.exists());
//判读是否是文件夹
System.out.println(file.isDirectory());
//判断是否是文件
System.out.println(file.isFile());
//删除一个文件
file.delete();//删除之后再盘符中也会对应的删除,无法通过java进行恢复
-
使用创建文件时,会产生编译时的异常,必须通过捕获,否则无法通过编译(在使用数据库时也会常常出现编译时的异常)
//创建文件
if(!file.exists()){//判断文件是否存在,不存在进行新建
try {
//创建文件时会产生异常,必须进行捕获,它是编译时异常,不捕获无法通过编译
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
-
创建文件过后进行删除,文件的路径还是存在的,相当于在创建文件时,先建立的文件路径,在建立的文件,删除的是文件,路径不会删除(就是,先建立房子,有没有人住是另一回事,新建文件就是建立人,删除文件就是删除人)
-
流(相当于水管流水一般,读写文件一般用流来进行读写)
a) 流是一组有序的数据序列
b) 以先进先出方式发送信息的通道(先读到什么就先写什么)
-
流区分(他们的父类是抽象类)
a) 输入流;inputStream(输入字节流)和reader(输入字符流,一般用于处理文本内容)作为基类(也就是父类)
b) 输出流;outputstream(输入字节流)和writer(输入字符流,一般用于处理文本内容)作为基类(也就是父类)
c) 字节流是8位通用字节流,字符流是16位Unicode字符流
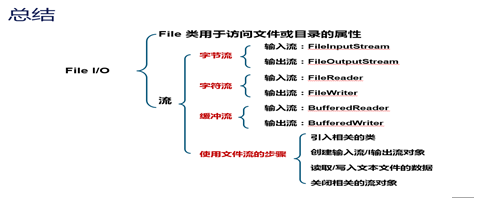
字节流
处理音频视频图片等内容必须使用字节流
-
使用io流进行获取内容
a) 先判断是输出还是输入,在根据实况进行使用字符或字节进行输入输出
b) 代码书写
//使用io时要判断是输入还是输出
try {
//创建输入流对象 可以传入文件名,也可是文件路径名
FileInputStream fis=new FileInputStream(“E:\JAVA文件输入输出案例实用\a.txt”);
byte[] b=new byte[1000];
//将读取到内容存放到数组中,他是有返回值的,返回的是内容的长度
int len=fis.read(b);
//关流fis.close();
//将数组内容转换成字符串
String s =new String(b, 0, len);
//输出获得的内容
System.out.println(s);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
c) 使用将数组中的内容转换为字符串时要注意string对象的构造方的参数数量(用三个参数的构造方法)
-
使用输入输出流后,需要进行关流,以便减少内存的占用
a) 代码书写
//关流
fis.close();
-
逐个输出字符(这只是另一种方法,输出只有一遍)
a) 代码
//逐个输入
int ads=0;
int i=0;
while ((ads=fis.read())!=-1) {
b[i++]=(byte)ads;
System.out.print(new String(b));
}
//关流
fis.close();
-
输出流
a) 输出流是将java文件写入到计算机中
b) 通过.getBytes( )方法将字符串转换为字节
c) 在输入输出流中要实现换行加\r\n
d) 要实现不覆盖原来得数据,在参数列表中加人true(默认是false,也就覆盖原来的数据)
e) 输出流的代码书写
try {
//创建输出对象 在参数中加上true为保存原来的数据,要实现换行加\r\n
FileOutputStream fis=new FileOutputStream(“E:\JAVA文件输入输出案例实用\a.txt”,true);
String s ="\r\nabcdefghijkmlnopqrstuvwsxyz";
//将字符串转换为字节
fis.write(s.getBytes());
//刷新,将内存中的数据刷新到文件中
fis.flush();
//关闭流
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
-
在输出流中必须要加上close,否则无法输出,但在输入流中可以不写,能输入(推荐读写)
a) 刷新,flush()与close的目的不一样,flush是刷新内容,将内存中的数据传输到计算机中
b) close()关流;关流是将输入输出流进行关闭,使数据无法再进行传输修改,从而减少内存的占用,同时也可以将内存中的数据传输到计算机中(调用close方法时也会掉用flush方法,当调用flush方法不会调用close方法,这也是他们的区别)
-
利用io流进行复制
a) 通过输入输出流的方法进行对换
b) 代码
try {
FileInputStream fos=new FileInputStream(“E:\JAVA文件输入输出案例实用\1.jpg”);
FileOutputStream foss=new FileOutputStream(“E:\JAVA文件输入输出案例实用\2.jpg”);
int i=0;
while ((i=fos.read())!=-1) {
foss.write(i);
}
System.out.println(“复制完成”);
fos.close();
foss.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
字符流
处理用户能看得懂的数据内容一般都使用字符流(文本内容)
输入流(reader类)
-
便于读取各种带编码的文件,比字节流获取数据效率更高
-
字符流
a) 字符输入流(reader读取数据方法)
i. read方法与字节流的read方法一样,但存放参数类型的是char类型,不再是byte类型的参数
ii. read方法的构造方法依旧存在

b) 字符输出流(writer)
i. 在利用writer进行遍历输出时通过 . readerline( )方法进行输出不会出现空方格,如果用 . reader()方法进行输出的话会出现空方格
c) 输出字符流代码
try {
//创建文件对象
FileReader fis=new FileReader(“E:/JAVA文件输入输出案例实用/d.txt”);
//建立字符流保存数组
char []ch=new char[100];
//将字符流保存到数组中,并返回长度
int len =fis.read(ch);
//关闭流
fis.close();
//将数组转换为字符串
String s =new String(ch, 0, len);
//输出字符流内容
System.out.println(s);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
-
inputStreamReader(字符输入流,是Reeder的子类,是fileReader的父类)

a) fileReader类是inputStreamReader类的子类
i. FileReader( File file )(可以传入文件)
ii. FileReader( String name)(可以传入文件地址)
iii. fileReader无法指定编码格式,读取文件时会按照文件默认的编码格式进行读取
-
fileReader方法
-
获取程序编码格式;
System. out. printIn ( System. getProperty (“ file. encding ”) )
-
中文乱码的原因;文件编码格式与程序的编码格式不一样(推荐编码格式是UTF-8国际通用格式,)
-
解决中文乱码的方法;字符流读取数据的时候进行指定编码格式,或者通过改变文件的编码格式进行解决(必须在可以改变文件的编码格式的情况下才可用,不推荐使用)
-
利用InputStreamReader字符输入流解决中文乱码方法(推荐使用)
a) InputStreamReader在new对象时可以指定编码格式也可以传入字节流(是字节流与字符流的过渡,是一个适配器)
i. 在使用InputStreamReader的时候要new一个字节流,然后将字节流传入到InputStreamReader中,才能进行指定编码格式的读取(字节流为需要转换成字符流的数据)
ii. InputStreamReader也可以将一个字节流的数据转换成字符流
iii. 代码
try {
FileInputStream fss=new FileInputStream(“E:/JAVA文件输入输出案例实用/d.txt”);
//将字节流转换为字符流,并指定编码格式
InputStreamReader fis=new InputStreamReader(fss,“gbk”);
char []ch=new char[100];
int i=fis.read(ch);
System.out.println(new String(ch, 0, i));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
b) 传入的编码格式与文件的编码格式一样才能进行指定的编码格式读取数据
-
为了更加快速的读取字符流的数据,出现了缓冲流(缓冲流也是字符流的一种)
a) BufferedReader类(缓冲流)

b) 缓冲流就是将字符流在包装异常
c) 缓冲区是有大小的
d) 缓冲流的readLind()方法(一次读取多个数据)
i. readLind()需要传入一个reader数据流()
e) readLind()在没有读出来的情况可能是;流没用关闭(后开的流先关)
-
缓冲区的代码
a) (一行读取)
//创建文件对象
FileReader fis=new FileReader(“E:/JAVA文件输入输出案例实用/d.txt”);
//创建缓冲区
BufferedReader buf=new BufferedReader(fis);
String sx ="";
//按行读取
while ((sx=buf.readLine())!=null) {
System.out.println(sx);
}
b) (整个读取)
//创建文件对象
FileReader fis=new FileReader(“E:/JAVA文件输入输出案例实用/d.txt”);
//创建缓冲区
BufferedReader buf=new BufferedReader(fis);
String sx ="";
//整个读取
StringBuilder str=new StringBuilder();
while ((sx=buf.readLine())!=null) {
str.append(sx+"\n");
}
fis.close();
buf.close();
System.out.println(str);
-
进程(正在运行的程序)
a) 应用程序的执行实例
b) 拥有独立的内存空间和系统资源
-
线程(一个进程中不同的执行路径)
a) 进程中执行元素的最小单位,可完成一个独立的顺序控制流程(独立的执行路径)
b) CPU调度和分派的基本单位
-
多线程
a) 如果在一个进程中同时运行啦多个线程,用来完成不同的工作,则称为“多线程”
b) 多个线程是交替占用cup资源的,并非真正的同时执行(只是运行速度快)
-
多线程的好处(单线程就只有一条执行路径(main方法),多线程有多条)
a) 充分的利用了cup的资源
b) 简化编程模型
c) 带来良好的用户体验
多线程的实现
-
thread类是线程的关键类,通过thread类进行线程的相关操作
-
主线程
a) main()方法时主线程的入口
b) 产生其他子线程的线程
c) 必须最好完成执行,因为它执行各种关闭动作
-
获取线程对象 . currentThread( )(通过该方法进行获取,是一个静态的方法)

a) 获取到的对象是Thread类型的,通过接收后调用. getname( )获取线程的名称
b) 在线程类中可以直接调用. currentThread( )方法
-
创建线程(必须重写run方法)

a) 创建线程继承Thread类,且一定要重写run方法(不去重写run方法不会出现编译时报错)
b) 启动线程;通过start方法进行启动(要实现启动多个线程就要new多个线程对象然后通过对象调用start方法)
c) 直接调用run方法存在的问题(相当于单线程)
i. 只有主线程的执行数据
ii. 依次调用了两次run方法
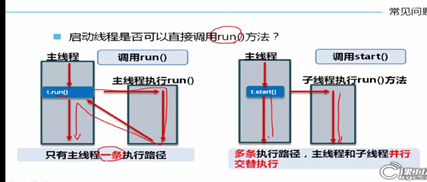
d) 创建新的线程必须重写run方法且在run方法中书写线程要执行的操作
e) 线程每次执行的时长是由cup进行分配的时长进行决定的
f) 线程类在测试类中要实例化对象才能进行启动线程
g) 获取当前线程名;
Thread.currentThread().getName()
h) 代码书写(继承thread类创建线程)
//建立线程对象
MyThread th=new MyThread();
th.start();//开启线程
//主线程的逻辑体
for (int i = 0; i <10; i++) {
System.out.println(Thread.currentThread().getName()+i);
}
-
实现Runnable接口创建线程(推荐使用)

a) 通过Runnable接口创建线程也要重写run方法(不去重写会出现编译时报错)
b) 通过Runnable接口创建线程时new线程对象时要传入一个Runnable接口实现类的对象(也可以传入两参数,一起修改线程名)
c) 代码详情
i. 主线程(代码)
MyThread2 t=new MyThread2();//实现接口类型
Thread Th2=new Thread(t);//转换接口类型
Th2.start();
for (int i = 0; i < 10; i++) {
try {
Th2.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+i);
}
d) 子线程代码与继承的代码一样书写(实现接口runnable)
-
thread与runnable创建线程的区别
a) thread类
i. 编写简单,可直接操作线程
ii. 适用于单继承
b) runnable接口(推荐使用)
i. 避免单继承的局限性
ii. 便于共享资源
-
创建线程的方法

-
线程状态与调度

a) 线程没有调用start方法时可以进行修改线程的名称
b) 线程的调度

c) sleep方法可以使线程处于休眠状态(也就是堵塞状态)
i. 在使用sleep时会出现异常需要捕捉
ii. 传入的参数为休眠的时间长度(单位为毫秒)
iii. 在主线程中要使线程休眠必须通过thread调用sleep才能进行休眠
d) 线程调度指的是特定机制为多个线程分配cup的使用权
e) 线程休眠代码书写
i. 主线程(代码)
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
ii. 子线程(代码)
try {
sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
-
线程的优先级(用数字1-10表示)
a) 线程的默认优先级是5,最低为1,最高为10
b) 线程的优先级高的线程获取的CPU资源的概率较大
i. . setPriorityThread_MAX_PRIORITY最高级
ii. . setPriorityThread_MIN_PRIORITY最低级
iii. . setPriority( (线程的优先级的数字))(通过线程的优先级数字的大小进行改变线程的优先级)

-
线程的强制执行(join)

a) 暂停当前线程,等待其他线程结束后再继续执行该线程
b) 代码书写
if (i==5) {
try {
//当前线程停止执行,加入的子线程执行完之后当前线程再执行
Th2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
i. }
c) 使用方法

-
线程的死亡有两种
a) 自然死亡(线程运行结束)
b) 强制死亡(强制停止线程,无法手动进行强制进行死亡)
-
线程的不安全
a) 当多个线程在同时操作同一个数据时就会出现线程不安全
b) 解决线程不安全的方法
i. 同步方法;在方法上加上synchroized(进行上锁)
-
方法上锁后,cup就进行锁定方法,只有当前线程执行完成后其余线程才能进行使用方法
ii. 同步代码块;在代码块上加上synchroized
-
代码块上锁后,cup就进行锁定代码块,只有当前线程执行完成后其余线程才能进行使用代码块
-
在使用该方法时要传入一个对象(该对象为无用的对象,没有用,只做参数进行使用),该对象一般为this或者object(this推荐使用)
-
线程的礼让(停止当前的线程,让其他线程先去执行)
a) 线程的礼让是概率性的事件,让当前线程处于就绪状态(不一定执行,也不一定不执行)
b) 礼让的几个方面
i. 当前线程处于阻塞状态
c) 代码书写(关键字yield)
if (i==6) {
Th2.yield();
}
-
线程的中断(中断休眠)
a) 代码书写
if (i==6) {
Th2.interrupt();
}
第九章;网络编程
网络编程
-
网络概述
a) 网络就是连接在一起的计算机(两台以上的计算机)
-
IP地址
a) 计算机在网络中地址的表示(每一台计算机的IP都不同)
b) IP地址有32位二进制表示的,由4个8位二进制数组成
-
IP地址的组成
a) IP=网络地址+主机地址
i. 网路地址;标识计算机或网路设备所在的网段
ii. 主机地址;标识特点主机或网络设备

iii. 一般的IP地址都为ABC三类中一类
-
查看自己的IP;使用ipconfig命令查看IP(在Dem命令管理中使用)
-
测试网络是否通畅;使用ping进行测试ping IP(IP为网络的地址,在Dem命令管理中使用)

DNS域名解析和网络服务器
-
访问网站时通过网址进行访问的原因;方便记忆
a) 通过DNS域名解析器将网址进行编译返回为IP地址(相当于将IP地址进行包装,然后通过)
-
网路服务器(通常指在网络环境下,具有较高计算能力,能够提供用户服务功能的计算机)
a) 邮件服务器
i. 邮件服务器一般进行邮件的传输
ii. 邮件服务器是对邮件进行收发管理的一个服务器
b) web服务器(对应的是java程序)
i. 网站的服务器
ii. 专门用来分析用户的请求,然后进行相对应的操作
iii. 常见的web服务器
-
B/S和C/S程序模式
a) B/S是服务器端应用程序(访问网站的,特点是方便进行升级)
b) C/S是客户端应用程序(需要下载的,特点是升级程序后用户是要重新进行下载的)
网络通信协议
-
网络通信协议是为了在网络中不同的计算机之间进行通信而建立的规则、标准或约定的集合

-
网络分层
a) 物理层;网络传输的东西
b) 数据链路层;将数据的传输,
c) 网络层;路由选择(选择传输的方式)
d) 传输层;点到点,可见的数据传输
Socket简介及分类
-
Socket(套接字,网路编程的关键字)
a) socket是提供给应用程序的接口
b) socket是通信的关键,相当于接口,双方通过socket才能准确的找到相应的服务器进行通信
(相当于快递点)
c) socket分类
i. 流式套接字;SOCK_STREAM,他是面向连接、可靠的数据传输服务(不会存在文件的丢失,遵守TCP协议)
ii. 报式套接字;SOCK_DGRAM,他是无连接服务,将数据分段的传输(会有数据的丢失,但效率更高遵守UDP协议)
iii. 原始式套接字;SOCK_RAM(不常使用)
-
socket通信原理

a) 使用流进行通信
b) 通信原理相当于打电话
c) 在使用socket后需要将其进行关闭
d) 要使用端口才能进行通信
-
端口;计算机上用一些整形的数字来表示端口(1024以下的都是系统的端口,一般使用1024以上的端口进行调用)
基于TCP协议的Socket编程(流式套接字)
-
网络编程使用java.net包
a) Socket客户端
i. 在客户端中建立socket时传入的端口名必须与服务器端的端口名一样,在传入id的时候要是服务器的id(本机用localhost(或者127.0.0.1)进行获取,他是一个字符串),否则无法进行通信
ii. 在客户端发送请求是用输出流
-
当请求是一个字符串就传字符串
-
当请求是对象时,方法如下
a) 确保对象可以序列化
b) 然后将对象进行序列化
iii. 要给服务器发送数据要将发送请求的输出流关闭,通过调用shutdownOutput()方法进行关闭(也称为socket半关闭)
iv. 通过输入流接受服务器的响应
b) ServerSocket服务器端
i. 在服务器端需要一个侦听客户端请求的一个方法,通过accept方法可以进行侦听请求(有返回值,返回值是socket类型)
-
如果传入的是一个对象的话,必须将对象进行反序列化之后才能进行准确的接受用户的请求
ii. accept方法在没有接受到用户端的数据请求是处于堵塞状态的,一旦数据请求发送过来就会到就绪状态
iii. 在服务器端响应客户端使用输出流
-
多线程网络编写
a) 通过线程类进行创建线程
i. 线程类中必须声明一个变量为socket类型的
ii. 用socket类型的变量值进行相对应客服端的线程开启
iii. 在线程类中只书写socket处理的代码(也就是逻辑处理输入输出等语句)
b) 建立服务端
i. 在服务端中书写服务端的监听方法(监听方法必须写在循环中,才能确保能重复监听客户端的请求)
ii. 在服务端中必须建立线程对象,否则无法进行线程的对应输出输入
c) 建立客户端
i. 客户端与单线程的客户端书写相同
ii. 客户端中也需要实现线程的类并将socket对象传入到线程类中
-
单线程的CTP协议代码编写
a) 服务器端
try {
//建立端口
ServerSocket serverSocket=new ServerSocket(5000);
//等待响应
Socket socket= serverSocket.accept();
//建立端口套接字的输入流
InputStream ins=socket.getInputStream();
//建立端口套接字输入流的缓冲区
BufferedReader is=new BufferedReader(new InputStreamReader(ins));
//定义空字符串
String info;
//循环输出
while((info=is.readLine())!=null){
System.out.println(info);
}
//定义新的字符串,给客户端回应
String hello=“服务器响应回;hello Dell!”;
//建立端口套接字的输出流
OutputStream si=socket.getOutputStream();
//将字符串进行字节化,并进行输出
si.write(hello.getBytes());
//关闭流和套接字
si.close();
is.close();
ins.close();
socket.close();
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
b) 客户端
try {
//建立对应IP地址和端口的套接字
Socket socket=new Socket(“localhost”, 5000);
//定义字符串
String info=“客户端说:holle word!”;
//建立套接字的输出流
OutputStream out=socket.getOutputStream();
//将字符串进行转换为字节流并进行输出
out.write(info.getBytes());
//关闭套接字的输出流
socket.shutdownOutput();
//建立套接字的输入流,用于读取服务器端的回复
InputStream showInFo= socket.getInputStream();
//建立套接字的缓冲区
BufferedReader sho=new BufferedReader(new InputStreamReader(showInFo));
//定义新的字符串
String in;
//利用while循环进行输出服务器端的回复
while ((in=sho.readLine())!=null) {
System.out.println(in);
}
//关闭流和套接字
showInFo.close();
sho.close();
out.close();
socket.close();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
-
CTP协议多线程的代码书写
a) 线程类
//定义套接字的变量
private Socket socket;
public SocketDemo02(Socket socket) {
super();
this.socket = socket;
}
public void run() {
//书写服务器的逻辑处理编码 与多线程的run方法同样进行数据的输出输入
try {
InputStream inp = socket.getInputStream();//接受数据
//定义空数组
byte[]b=new byte[1000];
int leb=inp.read(b);
System.out.println(new String(b, 0, leb));
inp.close();
} catch (IOException e) {
e.printStackTrace();
}
b) 客户端
try {
//建立套接字对象 参数是;IP地址、端口
Socket socket=new Socket(“localhost”,6666);
//建立输出流,将数据输出到服务器端
OutputStream out=socket.getOutputStream();
//输出的内容是字节流,通过getbyte进行转换
out.write(“你好”.getBytes());//输出数据内容
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
c) 服务器端
try {
//建立端口
ServerSocket sever=new ServerSocket(6666);
//通过while循环使accept能够重复使用
while(true){
Socket acc = sever.accept();
//响应成功输出提示
System.out.println(acc.getInetAddress()+“链接成功!”);
//建立线程对象
SocketDemo02 soc=new SocketDemo02(acc);
//将线程进行转换,并启动线程
Thread t=new Thread(soc);
t.start();
}
} catch (IOException e) {
e.printStackTrace();
}
UDP协议网络编程(报式编程)
-
udp 是将数据进行打包,然后通过数据包的形式进行发送到对方
-
udp协议的没有服务器端与客户端的说法,都是客户端之间的数据交互
-
udp的数据发送与接收
a) udp协议通过send方法进行数据的发送(有参数,参数是一个有内容数据的包)
b) udp通过received进行数据的接受(有参数,参数是一个接受内容的空包)
-
udp协议的运行是先运行接受端,在运行发送端
-
udp协议代码的书写
a) 发送端
try {
//发消息的一端
DatagramSocket socket=new DatagramSocket();
//发送数据的内容
String s=“你好”;
//将数据类型进行转换
byte[]b=s.getBytes();
//将数据保存到数据包中,参数是;数组、数组长度、IP地址、端口
DatagramPacket packet=new DatagramPacket(b, b.length, InetAddress.getLocalHost(), 8888);
//发送数据
socket.send(packet);
socket.close();
} catch (SocketException e) {
e.printStackTrace();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
b) 接受端
try {
//接受消息的一端
DatagramSocket socket=new DatagramSocket(8888);
//定义空包
byte b[]=new byte[100];
DatagramPacket packet=new DatagramPacket(b, b.length);
//接受到的数据保存进空包里
socket.receive(packet);
//将接受到的数据转换为字符串
String s=new String(packet.getData(),0,packet.getLength());
//输出数据内容
System.out.println(s);
socket.close();
} catch (SocketException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
第十章;XML
XML
-
XML(extensible markup language),可扩展标记语言
a) 标记;用< >包裹的称为标记(也叫元素)
b) 特点
i. XML与操作系统,编程语言的开发平台无关
ii. 实现不同系统之间的数据交换(数据交换的格式)
iii. 可以跨平台,跨语言
c) 作用
i. 数据交互
ii. 配置应用程序和网站
iii. Ajax基石
iv. 统一信息的结构,实现不同的系统之间的通信
-
XML文档结构
a) 与HTML的书写类似

c) XML的声明(写在第一行)
i. <?xml version=”1.0” encoding=”UTF-8”?>
-
version 文档符合的规范
-
encoding 文档的编码格式(不写也是UTF-8)
d) 文档元素描述信息(文档结构)
i. 每一个XML文档是以树形结构进行存储的
ii. 每一个XML只有一个根元素(相当于HTML中的HTML标签)
-
建立XML文档
a) 元素的书写(HTML中的标签书写一样),元素也能增加属性(与HTML中的id、class一样的书写)
b) 属性值不能包含(< ” &)(不推荐包含(‘ >))
c) 标签中可以随意定义标签(标签中可以在写标签)
d) XML的注释;
e) 书写代码<?xml version="1.0" encoding="UTF-8"?>
-
XML的属性注意事项

XML的标签命名一般与数据库中的标签名一样(方便进行映射)
-
转义符(关键字的转换)

a) 当出现多个特殊字符的时候通过cdata书就进行输出则不会将特殊字符当成标签使用
-
命名空间
a) 指定标签的特殊含义
b) 命名空间作用是解决在复杂,大型XML文件中出现名称相同,但含义不同的元素
c) xmlns是命名空间的关键字(例:xmlns:Nikon=“http//www.nikon.com”)
-
XML解析
a) 非验证解析器
i. 检查文档格式是否良好
b) 验证解析器
c) 使用DTD检查文档的有效性
-
解析方法(XML文件必须为与工程的目录下)
a) DOM解析(文档对象模型)
i. 基于XML文档树解析结构
b) 解析方法
i. 创建解析器工厂对象(关键字documentBuilderFactory . newInstance( ))
//解析器工厂对象
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
ii. 解析器工厂对象创建解析器对象( .newDocumentBuillder)
//解析对象
DocumentBuilder builder=factory.newDocumentBuilder();
iii. 解析器对象指定XML文件进行解析获得文档对象document . parse( )(要传入文件路径)
//解析文件获取文档对象
Document document=builder.parse(“XMLDemo02.xml”);
iv. 文档对象解析(未完成…)
c) 判断节点关键字(. getNodeType( )==Element. ELEMENT_NODE)(只解析节点)
i. 代码书写
for (int j = 0; j < node.getLength(); j++) {
//获取子元素
Node item2 = node.item(j);
//判断节点,让程序只解析节点
if (item2.getNodeType()==Element.ELEMENT_NODE) {
//数据类型转换
Element ele=(Element) item2;
//获取文本内容并进行输出
System.out.println(ele.getTextContent());
}
}
d) 代码书写
i. 内容保存的是元素,在同一个标签中(包要导w3c的)
//解析器工厂对象
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
try {
//解析对象
DocumentBuilder builder=factory.newDocumentBuilder();
//解析文件获取文档对象
Document document=builder.parse(“XMLDemo01.xml”);
//获得name元素集合
NodeList nodelist=document.getElementsByTagName(“name”);
//遍历每一个name集合
for (int i = 0; i <nodelist.getLength(); i++) {
//获取单个的name元素
Node phone= nodelist.item(i);
//转换为element类型
Element ele=(Element) phone;
//解析属性
String type=ele.getAttribute(“name”);
String pricet=ele.getAttribute(“money”);
String color=ele.getAttribute(“color”);
System.out.println(“品牌:”+type+“价格:”+pricet+“颜色:”+color);
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
ii. 内容保存的是多个元素保存在多个标签中(包要导w3c的)
//解析器工厂对象
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
try {
//解析对象
DocumentBuilder builder=factory.newDocumentBuilder();
//解析文件获取文档对象
Document document=builder.parse(“XMLDemo02.xml”);
//获得student元素集合
NodeList nodelist=document.getElementsByTagName(“student”);
//遍历每一个student集合
for (int i = 0; i < nodelist.getLength(); i++) {
//进行数据类型进行转换
Element item = (Element) nodelist.item(i);
//输出name的属性值
System.out.println(item.getAttribute(“name”));
//获得子元素的集合
NodeList node=item.getChildNodes();
//遍历输出每一个值元素
for (int j = 0; j < node.getLength(); j++) {
//获取子元素
Node item2 = node.item(j);
//判断节点,让程序只解析节点
if (item2.getNodeType()==Element.ELEMENT_NODE) {
//数据类型转换
Element ele=(Element) item2;
//获取文本内容并进行输出
System.out.println(ele.getTextContent());
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
-
为XML添加元素
a) 要创立转换器工厂,通过转换器工厂建立转换器对象,对象创建XML文件,通过文件进行建立属性
i. 创建子元素
ii. 为子元素创建子子元素并添加
iii. 为根元素添加子元素
b) 转换完成后要进行保存到文件(要获取数据源和输出流)
XML方法使用二(XML4J)
-
使用DOM4J进行解析(DOM4J提供的是一些接口和类)
a) document;定义XML文档
b) element;定义XML元素
c) text;定义XML文本节点
d) attribute;定义XML的属性
-
导入jar包
a) 在工程中新建一个空的文件夹
b) 在文件夹中访日jar包(文件夹命名为lib(资源的缩写))
c) 在工程中加入相应的文件包
-
DOM4J的使用
a) 关键字document(是导入jar包中的,非w3c中的)
b) 获取对象
i. 解析器的对象通过SAXReader进行new获取对象
ii. 转换工厂的对象通过OutputFormat . createPrettyPrint( )进行获取一个对象(默认格式,不需要添加格式)
iii. 转换工厂通过XMLWrite write=newXMLWrite(参数)进行获取
iv. 代码
-
解析器获取代码
//建立解析器工厂
SAXReader reaorder=new SAXReader();
try {
//读取XML的信息
document=reaorder.read(new File(“XML4JDemo01.xml”));
} catch (DocumentException e) {
e.printStackTrace();
}
-
转换工厂代码
//获取转换工厂对象
OutputFormat format=OutputFormat.createPrettyPrint();//以一个格式输出
//指定代码格式 format.setEncoding(“gbk”);
try {
//创建输出流,指定以format格式输出
XMLWriter writer=new XMLWriter(new OutputStreamWriter(new FileOutputStream(src)),format);
//输出document
writer.write(document);
//关闭流
writer.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
c) 获取节点
i. 获取根节点通过 . getRooElement ( )的方法进行获取
ii. 获取子节点通过 . emelentIterator( )的方法进行获取所有的字节点(根节点的下一级节点,可以通过反复循环调用获取子子节点)
iii. 获取节点代码
-
获取根节点
//获取根节点
Element element=document.getRootElement();
-
获取子节点(子子节点)
//获取所有的子节点
Iterator<?> sel= element.elementIterator();
d) 添加节点
i. 添加子节点 . addElement( “ “ )(括号中添加子节点的标签名)
ii. 添加子子节点也是用 . addElment( “ “ )进行添加
iii. 曾加后的内容要通过转换器进行保存到XML文档中
iv. 添加节点代码
//获取XML的根节点
Element root=document.getRootElement();
//创建student
Element add= root.addElement(“student”);
add.addAttribute(“name”, “战神”);
//创建student子节点
Element foot=add.addElement(“score”);
//添加子节点的内容
foot.addAttribute(“score”, “1000”);
//将子节点的数据保存到XML文件中
seavxml(“XML4JDemo02.xml”);
e) 删除节点
i. 删除节点通过 . getParent( ) . remove( “ 要删除对象 ”)(删除后的内容要保存到XML文件中,通过转换器进行保存)
ii. 代码
//获取根节点
Element root=document.getRootElement();
//获取student子节点
Iterator<?> iterator = root.elementIterator();
//遍历子节点
while (iterator.hasNext()) {
//数据类型转换
Element next = (Element) iterator.next();
//判断是否是指定的节点
if(next.attributeValue(“name”).equals(“张三”)){
//获取根节点删除子节点
next.getParent().remove(next);
}
}
f) 修改节点
i. 修改节点通过 . addAttribute( “元素名 ” , “ 元素值”)进行修改(修改过后的XML内容要保存到XML文件中,通过转换工厂进行保存. addAttribute方法为有对应属性的修改,没有为添加,getName为对没有属性的标签进行修改 . setText是修改内容不是修改属性)
ii. 代码
//获取根节点
Element root=document.getRootElement();
//获取所有的student子节点
Iterator<?> iterator = root.elementIterator();
int id=0;
//遍历子节点
while (iterator.hasNext()) {
id++;
//数据类型转换
Element next = (Element) iterator.next();
//添加内容和属性
next.addAttribute(“id”, id+"");
}
//将数据保存到XML文件中
seavxml(“XML4JDemo02.xml”);
g) 输出XML文件内容
i. 通过迭代器进行遍历输出
ii. 代码书写
//获取根节点
Element element=document.getRootElement();
//或取所有的子节点
Iterator<?> sel= element.elementIterator();
//遍历子节点
while (sel.hasNext()) {
Element si=(Element) sel.next();
//输出字节的name属性
System.out.println(si.attributeValue(“name”));
//获取子子节点
Iterator<?> eles=si.elementIterator();
//循环子子节点
while (eles.hasNext()) {
Element sis=(Element) eles.next();
//输出子子节点的yuScore属性
System.out.println(sis.attributeValue(“yuScore”));
}
}
iii. 代码
-









