值域为正负1之间,用来筛查单变量与预测结果之间的相关关系,一般来讲:
- 绝对值在0-0.1之间:无关
- 绝对值在0.1-0.3之间:弱相关关系
- 绝对值在0.3-0.6之间:存在相关关系
- 绝对值在0.6-0.9之间:强相关关系
- 绝对值大于0.9:几乎线性相关
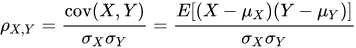
主要的功能函数:
def pearsonr_selection(x_data, y_data): # 皮尔逊pearsonr相关系数
from scipy.stats import pearsonr
para_dict3 = []
for col_name, c_data in x_data.iteritems():
sp = pearsonr(c_data, y_data)[0]
para_dict3.append([col_name, abs(sp)])
# 对特征进行排序
feature_df = pd.DataFrame(para_dict3)
feature_df.sort_values(by=1, ascending=False, inplace=True)
return feature_df
示例
import pandas as pd
from sklearn.datasets import make_regression, make_classification
def pearsonr_selection(x_data, y_data): # 皮尔逊pearsonr相关系数
from scipy.stats import pearsonr
para_dict3 = []
for col_name, c_data in x_data.iteritems():
sp = pearsonr(c_data, y_data)[0]
para_dict3.append([col_name, abs(sp)])
# 对特征进行排序
feature_df = pd.DataFrame(para_dict3)
feature_df.sort_values(by=1, ascending=False, inplace=True)
return feature_df
if __name__ == '__main__':
value_x, value_y = make_classification(n_samples=1000, n_classes=4, n_features=10, n_informative=8)
df_x = pd.DataFrame(value_x, columns=['f_1', 'f_2', 'f_3', 'f_4', 'f_5', 'f_6', "f_7", "f_8", "f_9", "f_10"])
df_y = pd.Series(value_y)
# value_x, value_y = load_data(samples=10000, classification=True)
# 下面是筛选单变量特征
feature_df = pearsonr_selection(df_x, df_y) # 皮尔逊
for col_index, value in feature_df.iterrows():
print(value[0], ":", value[1])