kubernetes 简称k8s, 因为k和s 中间有'ubernete' 8个单词,所以简称k8s。是一个开源的,用于管理云平台中多个主机上的容器化的应用, k8s 的目标是让部署容器化的应用简单并且高效,k8s 提供了应用部署、规划、更新、维护的一种机制。是google 开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。
它有三个关键的组件:kubelet, kubeadm, kubectl
其中:
kubeadm : 是用来搞集群的,比如初始化 master 节点,添加 work 节
kubelet : 简单说就是master 派到node 节点的代表,管理本机容器的相关操作。负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
kubectl : 是执行各种查询和控制类操作的
这里再写几个其他的概念:
etcd:存储系统,用于保存集群相关的数据,比如说状态数据、pod数据等,注意pod可以分为2类,一种是普通的pod,这种pod会将自己的相关信息存储到etcd,这样管理节点就可以知道有哪些pod,还有一种是静态pod它们会将自己的信息存储到自己所在的节点的存储文件里,这样一来管理节点就不知道它们的存在,所以他们的启动停止等操作,就只能靠人工去相应的节点上去手动操作了。
apiserver:资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制,以restful 方式,交给etcd 存储
scheduler:节点调度,选择node 节点应用部署;按照预定的调度策略将Pod调度到相应的机器上
controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等,一个资源对应一个控制器
kube-proxy:网络上的代理,包括负载均衡等操作。负责为Service提供cluster内部的服务发现和负载均衡
pod:k8s部署的最小单元,一个pod 可以包含多个容器,也就是一组容器的集合;容器内部共享网络;pod 的生命周期是短暂的,重新部署之后是一个新的pod,pod是K8s集群中所有业务类型的基础,可以看作运行在K8s集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前K8s中的业务主要可以分为长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application);分别对应的小机器人控制器为Deployment、Job、DaemonSet和PetSet
Replication Controller :RC是K8s集群中最早的保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动运行新的Pod副本;多于指定数目,RC就会杀死多余的Pod
Service:定义一组pod 的访问规则。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。
ok,接下来,看下k8s部署集群的公共操作(不管是部署master节点,还是work节点,都需要先完成这些操作)
1、关闭selinux
vi /etc/selinux/config # 永久关闭
将参数 SELINUX 改为 disabled 即可

2、注释掉交换分区
vi /etc/fstab
将交换分区那一行注掉 
执行swapoff -a 暂时关闭这个文件
3、修改网卡配置(由于集群中肯定存在流量转发的问题,所以需要修改网卡)
vi /etc/sysctl.conf
将如下三行搞进去:
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1

保存退出后,执行 sysctl -p 来应用它

4、启用内核模块
vi /etc/sysconfig/modules/ipvs.modules
添加如下内容:
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
完成后,其并不会立刻生效,需要执行一下命令,让其临时生效:
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
5、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
6、配置 hosts
编辑源的配置文件
vi /etc/yum.repos.d/kubernetes.repo
将如下代码添加进去:
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg

安装 kubelet, kubeadm, kubectl:
yum install -y kubelet kubeadm kubectl
启动 kubelet 服务:
systemctl enable kubelet
systemctl start kubelet
systemctl status kubelet # 这里会有255的错,这个错属于正常,后面会解决

执行命令 journalctl -xe 可以查看具体报错信息

后续会创建这个配置文件,所以暂时不管。
安装 docker,可以去官网上看下流程:
https://docs.docker.com/engine/install/
这里以cetos为例:
1、先卸载以前的版本,如果之前没安过,直接跳过
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2、Set up the repository
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
3、下载docker
sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
4、启动docker
sudo systemctl start docker
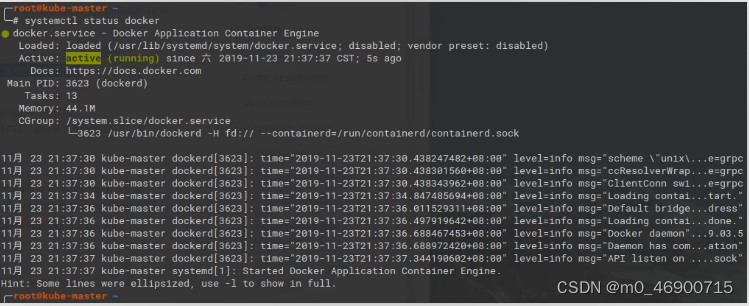
5、查看状态
systemctl status docker
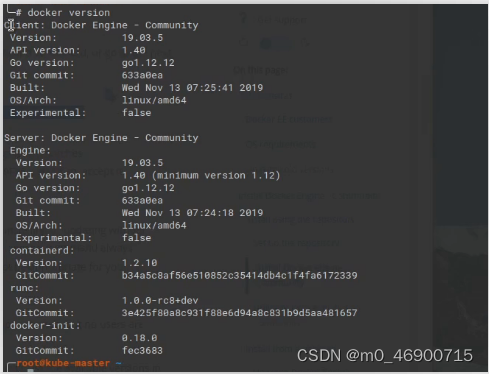
docker version
接下来修改docker配置:
1、查看docker驱动
docker info | grep -i cgroup

k8s默认的docker驱动为systemd,所以需要修改驱动
2、修改驱动
vi /etc/docker/daemon.json
将下面的东西添加进去:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
完成以后重启docker服务:
systemctl restart docker
再看驱动: docker info | grep -i cgroup

接下来需要下载k8s所需要的一些镜像文件:
1、查看需要下载哪些镜像:
kubeadm config images list

2、下载这些镜像,由于网络原因,我们需要用docker去找docker hub中等效的镜像,将其下载下来,完成后使用docker tag 命令将docker下载下的镜像名称换成上面所需要的k8s的镜像名称,然后再删除docker名称的那些原始镜像。
https://hub.docker.com/
在上面搜索所需同名镜像:
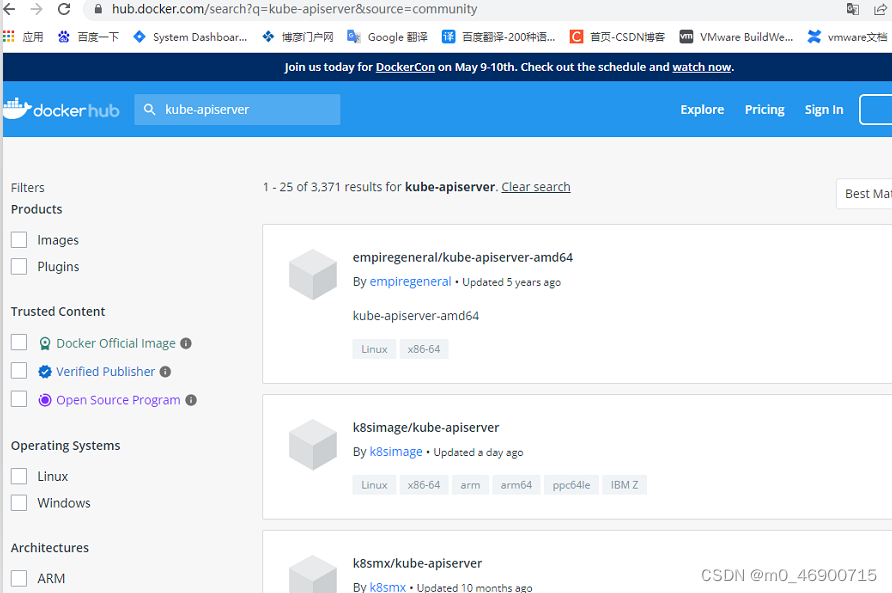

执行命令: docker pull kubeimage/kube-apiserver-amd64

完成后,查看镜像: docker images
 然后修改tag: docker tag xxx xxx 再次查看: docker images
然后修改tag: docker tag xxx xxx 再次查看: docker images

删除多余镜像,并查看结果:

然后,这就可以了,剩下的镜像,按照流程替换即可。
以上就是所有集群化配置的公共内容了。
Master 节点的配置:
假如是做测试,在pc上搞三个虚拟机做为节点的话,上面的操作可以在一个虚拟机上进行,完成后复制2份即可,但是会有一个问题,复制的虚拟机的 ip 地址也是完全相同的,所以需要将后面的复制品的 IP 进行更改。
这里分享一个改虚拟机 ip 的 方法:
首先:
ip addr # 查看 ip

所以这里就需要改2个地方的 ip
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8

换掉这个值就行,同一个机子,这个值应该是统一的。
注意,完事后记着重启网络服务:systemctl restart network
另外,对于后面的2个虚拟机还需要设定其主机名称,方法为:
cat /etc/hostname # 查看主机名
hostnamectl set-hostname xxx # 修改主机名
这里再提一嘴,往往可以 ping 主机名 就可以找到具体的 ip,那是因为在配置文件里已经有了相应的映射配置,所以才可以ping通,这里添加一个修改这个映射的方法:
vi /etc/hosts # 在这修改,将新的 ip 与 主机名映射添加进去即可

master节点初始化之前还需要对 pod-network-cidr 这个参数做一些准备工作,就是选择合适的插件。
https://kubernetes.io/zh/docs/concepts/cluster-administration/addons/
可以在这个网站上查看,都有哪些网络插件可用。
然后,选择你想用的插件,点中去查看,例如:

进去一后往下拉,看这里:

将这个url在浏览器中打开,搜 network,就可以找到网络取值范围:

然后将这个值给到,master节点的 pod-network-cidr 这个参数。所以说这个参数不是随便给的,也是精挑细选,选出来的。
然后就可以执行master节点的创建工作了。
kubeadm init --apiserver-advertise-address=192.168.13.103 --kubernetes-version v1.18.0 --pod-network-cidr=10.244.0.0/16
其中参数:
--pod-network-cidr 指pod的网络范围,不同的插件对应的范围不同,所以在给值的时候要注意
--kubernetes-version 就是k8s的版本默认是最新版,当然如果用的不是最新版,就最好指定一下
--apiserver-advertise-address 这是master机子所在节点的 ip 地址
如果在初始化过程中,失败了,那么肯定先找失败的原因,解决掉以后,需要重新还原配置,命令为:kubeadm reset

执行完命令后,这里会有个这个文件,在这里可以修改这个文件,因为我们有将主机名和ip绑定,所以,可以将这个文件中的 ip 地址换成主机名,然后,就可以通过主机名访问各个服务了。
编辑这个文件:

将它换掉:

然后,按照执行完初始化master的命令中的提示,继续即可。
然后查看下命名空间:kubectl get pods --all-namespaces

这里会发现有2个pod处于等待态。这是由于初始化参数 pod-network-cidr 我们给了参数,但是并没有进行相应的配置。还记着上面截图中,我们圈出来的命令么,这里,我们执行一下,将插件的配置文件使用起来。
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
执行完成之后,会发现这里多了一个pod

然后也可以通过命令去查看这个pod到底什么情况:
kubectl describe pods xxx(pod-name) -n xxx(namespece)
现在再看,它就好了

然后,master节点就ok了,接下来,我们需要生成一个将work节点添加到master节点的命令。
kubectl token create --print-join-command

work 节点的配置:
基础的相关配置和上面差不多,都需要改 ip,改主机名,改 hosts 映射,完成后,就只需要执行,在master节点上创建的 join-command 命令即可,就是上面那个,复制粘贴到work节点就完事了。
在master节点看下结果,一切ok

服务部署:
其实,服务的部署,只有一个命令就可以了,重点是得有部署服务的 yml 文件,这属于k8s的yml文件。
类似于这样的:


然后,基于这个配置文件,就可以直接使用命令部署了。
kubectl apply -f xxx.yml
直接就可以完成部署了。
接下来,分析下k8s.yml文件。

apiVersion:是当下构建内容的版本
kind:是指,你想干啥,比如,Namespace就是创建命名空间,Deployment就是部署服务
Namespace:命名空间,它的作用就是资源的隔离。
资源对象的隔离:Service,Deployment,Pod
资源配额的隔离:Cpu,Memory
这里注意,namespace的资源隔离只是在名称方面的隔离,它并不会隔离 service_ip, pod_ip,这有些像 /etc/hosts里的设定,它的隔离相当于更改了这里映射的名称,但并不能改ip本身,所以它只是隔离了类似主机名称,却不会产生物理隔离。

metadata:元数据,就是对当下kind的整体的说明,其中的 name 参数是指给这个 kind 起的名称,namespace 是指这个pod属于哪个命名空间。注意,如果这里没给namespace,那么就是用的默认的default命名空间。比如,当下这个name对应的kind是deployment,那么它的变动,就会引起deploy的变化,简单来说就是建立了新的deploy。

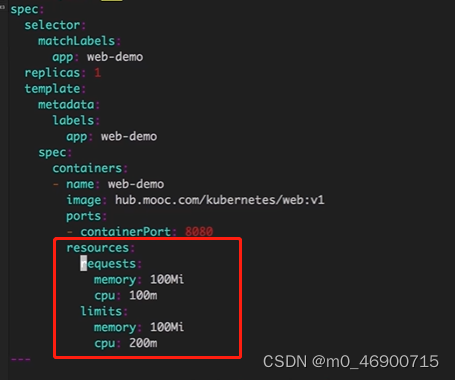
resources:资源管理。节点上kubelet会收集资源信息(内存大小,多少核等信息)然后上报给apiService,然后,apiService就会根据容器这里的资源需求将其分配到相应的节点上。就比如有个节点内存只有1G,但是有一个pod运行的容器需要10G内存,那么,这个时候,显然apiServer就是不可能将这个pod部署到这个节点上的。这里注意,resources,下有2个参数,requests,limits,前者是说,这个容器希望被分配多少资源,后者是说,这个容器最多消耗多少资源。memory,是内存,单位 Mi (就是传统的M),Gi (传统的G),cpu就是内核,如果不给单位,默认就是核,比如 cpu:1,就是cpu 1核,单位 m,1核 = 1000m。上面的配置解读的意思就是:运行这个容器,必须得有100M内存,0.1核的资源,同时这个容器最多占用资源100M,0.2核。这里需要注意,requests == limits 是最合理的安排,也是最稳定的。requests < limits, 这种设定意义不大,比如,设定 request.memory = 1G,而 limit.memory = 100G,那么就会产生一个问题,这个容器的运行过程占用内存波动太大了,到底它占多少内容,没人知道,这样的东西,就风险太大了。同时 resource 这个参数最好是给上,否则,在node上资源不够用的时候,第一个干掉的就是这种没任何设定的。另外,这里的值最好不要乱设置,资源不足时,cpu会按比例将资源分给各个容器,但是内存不会,资源不足时,占内存大的进程会被干掉,当然容器是不会被停掉的,但是容器内运行的占内存大的服务就会被停掉了。

当然也可以不在deploy这里定义容器的resource,转而通过一个专门的配置文件去控制这些资源。根据命令:
kubectl create -f xxx.yml -n xxx_namespace # 这里注意 limit.yml 必须依赖命名空间创建,这样以来就相当于命名空间本身有了相关的限制,所以,最后部署于这个命名空间之中的pod也就同样需要遵守这些限制
kubectl describe limits -n xxx_namespace # 查看 xx 命名空间的限制



这也是一种资源配额的设定。
只不过,这两种限定资源的启动方式和之前的不同:
kubectl apply -f xxx.yml -n xxx_namespace # 一样需要依赖命名空间
注意这种配置,属于配置的是总额,比如左侧截图的配置,就是说pods最多运行4个,需求cpu总量占用最多2核,需求内存总量占用最多4G,容器占用cup总量最多波动到4核,内存波动到8G。
扯一个机制:
pod驱逐-eviction :通常情况,kubelet会监控node的情况,并将相关信息返回给apiService,那么apiService就会根据一些策略将一些pod给干掉。
--eviction-soft=memory.available<1.5Gi # 当可用内存小于1.5G时,准备执行pod驱逐策略,这时候不是立刻执行pod驱逐策略
--eviction-soft-grace-period=memory.available=1m30s # 当可用内存小于1.5G这样的情况持续存在了1分30秒的时候,执行pod驱逐策略
--eviction-hard=memory.available<100Mi,nodefs.available<1Gi,nidefs.inodesFree<5% # 当内存小于100M或者磁盘小于1G或者磁盘i节点小于5%的时候,立刻执行pod驱逐策略。
对于磁盘紧缺的情况:
1、删除死掉的pod,容器
2、删除没用的镜像
3、按优先级,资源占用的情况驱逐pod
内存紧缺的情况:
1、驱逐不可靠的pod # 就是没有设置 resource参数的pod
2、驱除基本可靠的pod # 通常就是resource参数中 limit > request 的那些pod
3、驱除可靠的pod # 通常就是resource参数中 limit == request 的那些pod
label :
它可以贴到 pod,Deployment,Service,Node,Resource 等等上
而且同一个对象,可以有多个标签,不同的对象,可以有同样的标签。

selector:选择器
matchLabels:匹配 pod 的标签,app就是一个标签的key,对应的就是标签的值。
这里注意,当matchLabels 和 matchExpressions 同时存在的时候是且的关系,就是都要满足。
另外,还有一点,selector一旦创建就不可以更改,如果要改,那就得把原先的删掉,重新构建。
kubectl delete -f xxx.yml # 先删
kubectl create -f xxx.yml # 再建
同时对于标签的用法,也可以用作过滤:
kubectl get pods -l xx_key=xx_value -n xx_namespace # 这就是根据标签来过滤pod
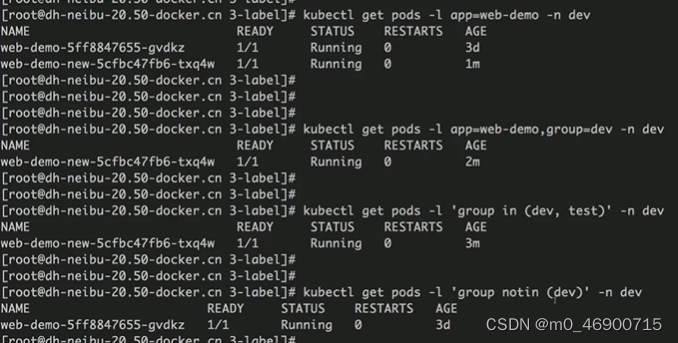
上述命令中 -l 参数中用逗号分隔是‘且’的意思。
kubectl label node xxx_node xx_key=xx_value # 直接给节点打标签

在template中可以添加节点选择器nodeSelector,这东西下面给的还是 label,只是这个 label 是属于node的label,意思就是说,这个创建pod的模板要求,只有拥有 disktype=ssd 标签的node,才能去承载当下所创建的pod。
replicas:副本数,就是部署多少个这样的pod
template:模板,就是根据这个模板的配置,将这个pod创建出来。
注意这里也有个metadata,它下面就必须有个labels标签项,且标签的内容,必须有上面selector里的标签。上面已经说了,选择器selector会选择出具有标签 app=web-demo的pod,最后将之创建在命名空间为dev的空间里,所以模板这里在构建创建pod的规则里,就需要体现这一点,就是创建的pod必须有标签app=web-demo。
spec:规范,它描述了你对这个对象所期望的状态,也就是目标。
containers:容器,name就是定义容器的名称,image就是定义容器的镜像从哪里获取,ports就是容器内部的端口,往往docker-compose.yml都会设置,容器的端口和主机端口的映射关系的。

这里的原理是这样的,上面的配置里不是创建pod的么,同时牵扯将这些pod部署到node上,完事后,就可以访问pod上面的服务了,那么这里的Service的配置里就设定了端口的映射关系,当访问80端口的时候,就会映射到容器8080的端口,那么假如现在有多个pod,每一个pod都部署了8080端口的容器服务,那么问题来了,当从浏览器访问服务的时候,具体访问的是哪个呢?这里的selector参数就很有用了,它会去过滤出有labels有app=web-demo的pod,然后去访问,那么加入有多个pod都有这个标签呢?那就轮询访问,浏览器每刷新一次就换一个pod访问。

ingress它是一种插件,也是一种模式,添加这个插件以后,在集群里,不管这个节点有没有部署你要访问的服务,它偶可以访问,如果你访问的节点刚好没部署相关服务,那么它会将你的请求转发给有相关服务的节点,然后就可以正常访问了。而且也指定了服务的名称,所以,这三个配置在一起也真是环环相扣了。

健康检查,首先,健康检查是针对容器服务的一种检查,所以它的存在是在容器项之下,和容器的其他配置平级。这种是搞shell脚本的方式检查。
livenessProbe:存活探针,该参数用于配置健康检查。
exec:执行命令,command
initialDelaySeconds:初始延迟时间,由于健康检查是针对于容器服务的检查,所以起码得等容器先起来以后,才需要进行检查,那么这个参数设定的时间就是给起容器的时间。
periodSeconds:每隔多长时间检查一次,显然健康检查不是个一次性操作。
failureThreshold:失败的门槛,当健康检查,连续检查2次,都是失败的,那么就认定健康检查失败
successThreshold:只要有一次成功,就任务健康检查成功
timeoutSeconds:执行健康检查命令的超时时间。
健康检查失败后,容器会被杀掉,然后重建。

这是第二种配置健康检查的方式,这种是属于访问http的方式:
path:就是健康检查时,所访问的http路径
port:是容器的真实端口
scheme:类型就是HTTP
注意,这个路径的检查,它只认200,比如返回个301重定向之类的,它会认定失败的。

这是第三种健康检查的方式,根据端口有没有被监听来检查。

这里还有一种参数,readinessProbe,检查程序是否准备就绪,可以访问了,如果可以正常访问了,就可以将其挂到负载均衡上去了。其他参数的意思同上,只是换了个领头的。

对于web服务,这样的配置就比较友好了,以检查端口是否被监听,来确定服务是否正常,如果不正常,就面临容器被杀,重新建容器的结果,然后再通过检查服务的http界面是否可以访问,如果可以访问,那就说明服务准备就绪,可以挂到负载均衡上,让用户访问了。

affinity:亲和性,它和容器时平级的
nodeAffinity:节点亲和性
requiredDuring....Execution:必须满足如下条件才可以被调度
nodeSelectorTerms:节点的选择策略
matchExpressions:匹配 label 的表达式,key就是 label 的key,value 就是 label 对应的值
这里注意,如果有多个匹配表达式,同时关系是‘且’的关系,那么就可matchExpressions,保持同级就可以。如果是‘或’的关系,就定义多个nodeSelectorTerms,每个 nodeSelectorTerms 都是平级写就可以。
perferreDuring....Execution:最好满足下面的条件
weight:权重
perference:最好满足
如果有多个条件,可以做多个 weight 标签,每个 weight 都是平级关系。

还是亲和性,不过这次是 pod 的亲和性。就是说,必须和具有哪些标签的pod在一起运行,更想跟具有哪些标签的pod在一起运行,运行在 topologyKey 对应的节点的标签的节点上。
topologyKey :它限定了节点的范围,就是该节点必须具备 label = topologyKey对应的值。

podAntiAffinity:不想跟具备哪些标签的pod运行在具备xx标签的node上

将label的值改为当下pod的label,这样设定以后,就相当于不愿意和自己运行在具有xx标签的节点上。通常这时候的replicas的值一般是不等于1的。通常这样的做法就是不希望同一个服务运行在一起。

反之,把 pod 亲和性从 podAntiAffinity 改成 podAffinity ,就成了希望同一个服务运行在一起。
下一个概念,污点(taint),污点是设定在node上的,然后就是需要在pod上明确设定容忍,如果没有设定容忍,那么,pod 就肯定不会去这些有污点的 node 上的。应用场景就是,通常有一些特殊的节点,他不希望有不相干的pod到他这运行,只有特殊的pod才被允许在这些节点上运行,那么这时候,就可以在这些节点上添加污点,然后给特殊pod上添加容忍,这样就可以规避其他不相干的pod调度到这些特殊node上了。
kubectl taint nodes xxx_node xx_key=xx_value:NoSchedule # 给节点xx打污点 key=value,效果是NoSchedule(不允许pod调度到这)

这个yml中和容器平级的 tolerations 就是容忍。
key就是node上污点的key,value就是污点key对应的值,effect,就是与污点对应的效果。
注意,这里的容忍,只是说对pod添加了容忍,就是说,node有污点pod可以接受,但是并不说pod就必须只能去有污点的node。如果副本数比较多的话,pod也是有可能部署到没有污点的node上的。

strategy:部署策略,type为Recreate


这个部署策略是说,当deploy文件发生变化以后,我们重新执行命令:
kubectl apply -f xx.yml
之后,会重新部署服务,这时部署服务的策略就是 Recreate,它的特点就是,停止原实例,然后创建新的实例。不管有几个副本,都是一样的。

同样是部署策略 strategy,只是这次是滚动升级。
maxSurge:每次多启动的实例的百分比个数,比如:共4个实例,每次多启动 4*25% 个实例
maxUnavailable:启动实例后,不可用个数。比如:共4个实例,升级完成后,最多可以有 4*25% 个实例是有问题的。
注意,这两个参数可以直接给int,不带%号。另外,对于滚动升级的模式,如果不配,其实默认也是这个策略,且默认的值,和上面截图一致。
kubectl rollout pause deploy xx_pod_name -n xx_namespace # 暂停xx_pod的滚动升级
kubectl rollout resume deploy xx_pod_name -n xx_namespace # 恢复
kubectl rollout undo deploy xx_pod_name -n xx_namespace # 回滚升级


蓝绿部署,就是比如之前是按照之前的部署方式,然后新建一个部署,然后等所有新的部署都ok以后,在通过切换service的selector,让其将流量转到新部署的pod上。

这是新搞的deploy.yml文件,这个文件不含service和ingress的内容。
然后启动它:
kubectl apply -f xx.yml
完成后,就会有新的pod被创建。创建完成后,去改之前的 service

这里 selector 的标签切换成新的 pod 就可以实现导流了。
注意,这时候,新的 pod,和老的 pod 都是在的,如果新的pod运行有问题,那么就可以通过改 service的selector,迅速的将流量切回老的 pod。


跟蓝绿部署不同的是,如果将版本号删掉,那么就成了金丝雀部署。
金丝雀部署的特点就是,所有的版本都是存在的,访问的过程就是轮询的状态,这就造成了有些人访问的时候,访问的是老版本,有些人就访问的新版本。