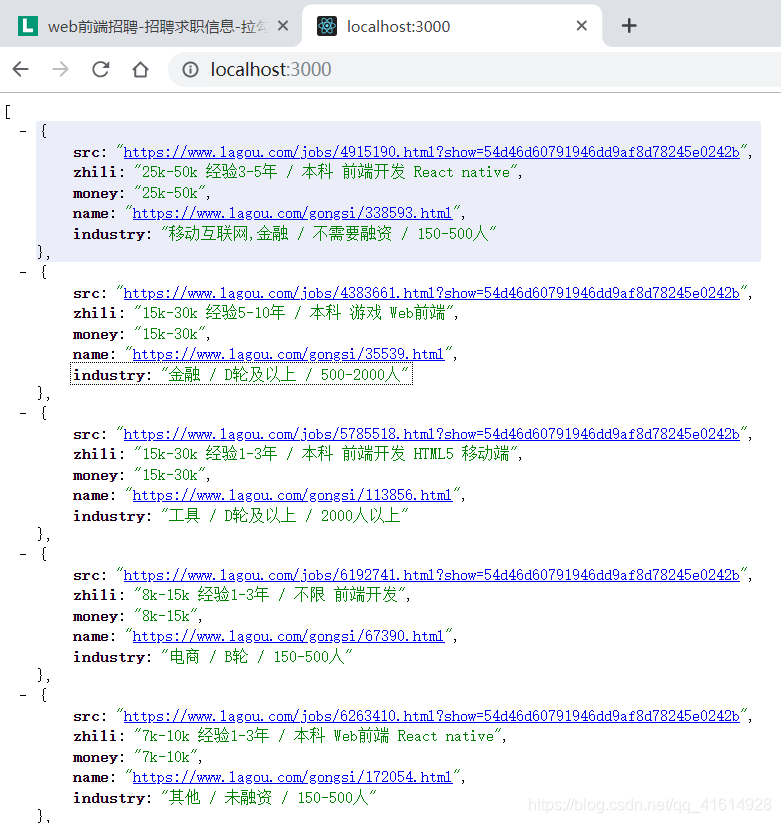
效果图如下:
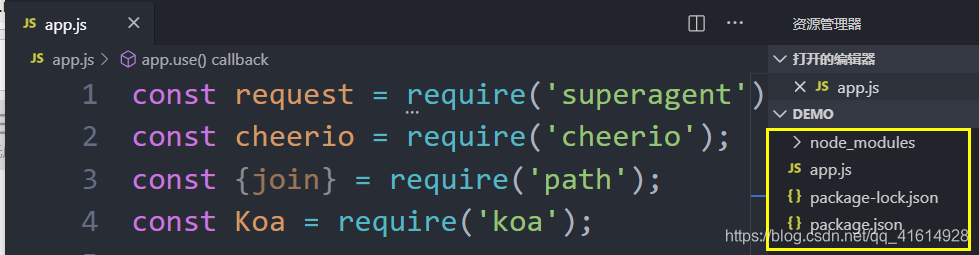
首先我们新建文件夹→进入终端:
初始化node项目:npm init -y
安装koa搭建服务模块:npm install koa
安装superagent发送请求模块:npm install superagent
安装cheerio文档转对象模块:npm install sheerio
app.js
const request = require('superagent'); //发送请求模块
const cheerio = require('cheerio'); //转对象模块
const Koa = require('koa'); //搭建服务模块
const app = new Koa; //开启服务
//需要爬取的网站
const url = 'https://www.lagou.com/zhaopin/webqianduan/?labelWords=label';
app.use(async ctx =>{
const arr = []; //存放爬取到的数据
const data = await new Promise(resolve =>{
request
.post(url) //爬取数据请求的地址
.end((err, res)=>{
const data = res.text; //请求到的html文档
const $ = cheerio.load(data); //html转对象
//去分析原网页的dom结构 li的class为.con_list_item
$('.con_list_item').each((i,v)=>{
const $v = $(v);
const obj = { //爬取class=position_link的a标签的href
src: $v.find('a.position_link').prop("href"),
zhili: $v.find('.li_b_l').text().trim(),
money: $v.find('.money').text().trim(),
name: $v.find('.company_name a').prop("href"),
industry: $v.find('.industry').text().trim(),
}
arr.push(obj);
})
resolve(arr)
})
})
ctx.body = arr; //将爬取的数据返回给前端
})
app.listen(3000);
项目文件展示如下: