Multi-head Selection和Deep Biaffine Attention在关系抽取中的应用
前言
最近在磕一人之力,刷爆三路榜单!信息抽取竞赛夺冠经验分享这篇文章,文章对关系抽取任务的解码方式做了简单的概述,在之前的文章中本人已经实现了指针标注网络,并对其进了优化(详情见改良后的层叠式指针网络,让我的模型F1提升近4%),因此这次把文中提到的多头选择和Biaffine关系矩阵构建的原论文拿出来研究了一下,并根据实际的关系抽取任务做了复现和改良。
本文主要涉及以下论文:
多头选择与关系抽取:
Joint entity recognition and relation extraction as a multi-head selection problem
Bert版多头选择:
BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction
双仿射注意力机制:
Deep Biaffine Attention for Neural Dependency Parsing(基于深层双仿射注意力的神经网络依存解析)
新论文,采取Biaffine机制构造Span矩阵:
Named Entity Recognition as Dependency Parsing
本文只是记录自己的思考和实现,只对每篇论文核心部分做简单理解,可能有错误,感兴趣的同学建议直接看原文。
Multi-head Selection
一、Joint entity recognition and relation extraction as a multi-head selection problem
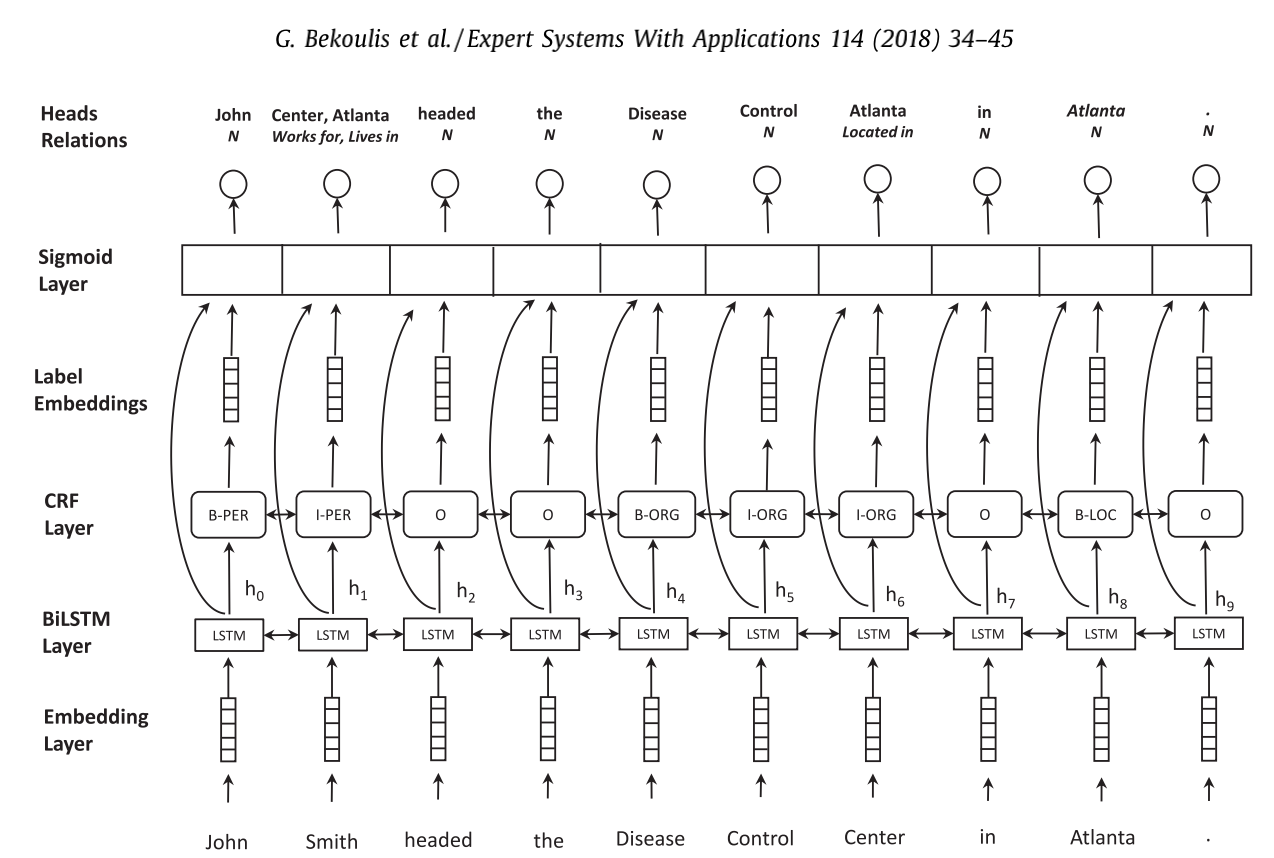
该网络结构将实体识别和关系抽取 joint 在一起,先通过在隐藏层上连接CRF,来抽取实体标签,并将实体标签信息embedding后与隐藏层一起传递给sigmoid_layer,来与其他实体特征进行交互抽取关系。
实体抽取部分比较好理解,对于多头选择部分,以下原文的几条核心公式:

理解如下:
当Token(j)为Subject的End 且 Token(i)为Object的End的概率分数为

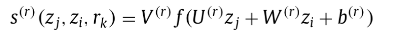
非常简明的意思是:将Token(j)和Token(i)的Z(隐藏层➕label embedding)分别经过U,W线性变换后相加再加上偏置b,最后再进行一次整体线性变换V,得到的值经过sigmoid函数后即转换为对应的概率分数。
别急!后文会讨论多类别关系时,各个矩阵的维度关系。
二、BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction
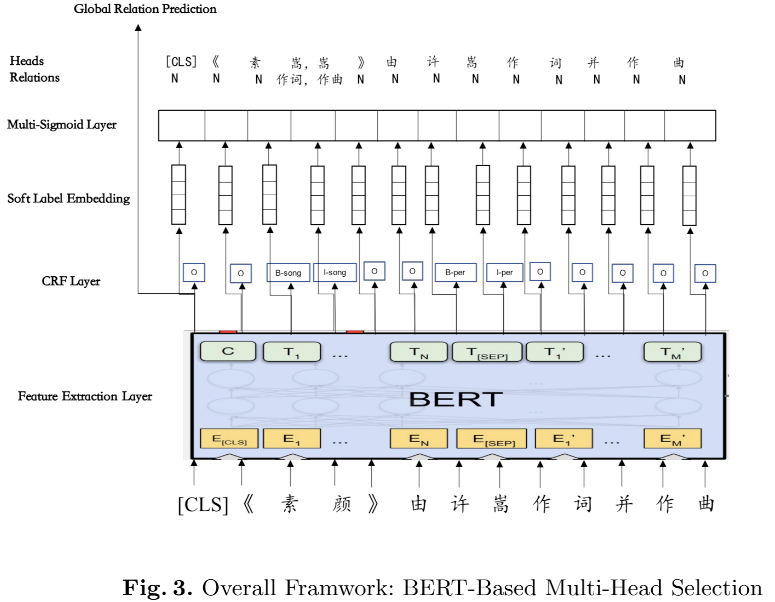
Bert + Multi-head Selection,除了引入了Bert作为编码层外,其他创新点如下:
- 考虑在训练时我们可以通过传入真实的实体标签的embedding给Multi-head Selection层,但在模型推理时,为了利用CRF的softmax在各个标签上产生的分值信息和考虑到推理时可能产生的错误标签结果,作者将softmax结果与各个标签的embedding进行加权后传给Multi-head Selection层。
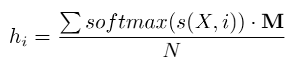
- 引入句子级关系分类任务来指导特征学习,如图中的用CLS来获得稳定的维度特征。(关于这一改进我并没有进行尝试,还不是因为没有数据!因此持有怀疑态度,原本就将两个任务的解码压力放在一组encoder上,现在又增加了句子分类任务。这不会加大模型压力吗?文中给出的实验结果表明,单独增加Global predicate Prediction并没有带来明显的提升,而组合各种策略能带来的较高提升不一定是该方法的贡献。)

- Soft label embedding of the ith token hi is feed into two separate fully connected layers to get the subject representation hsi and object representation hoi. where f(·) means neural network, ri,j is the relation when the ith token is subject and the jth token is object, rj,i is the relation when the jth token is subject and the ith token is object.(论文原文,多头选择方法与上文相同,将构建好的token特征通过两个不同的全连接层后经过一个F网络输出两者的关系分值)
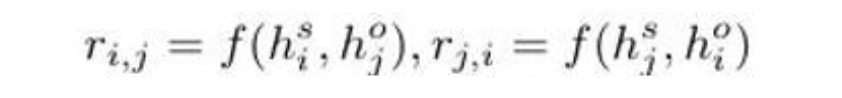
三、实现方法和模型代码展示
以三元关系抽取任务为例,我们多头选择该如何更好的理解和应用?功夫不负有心人我找大了夕大姐文章里一张图虽然和多头选择没多少关系,但能比较形象的展示Multi-head Selection的流程:
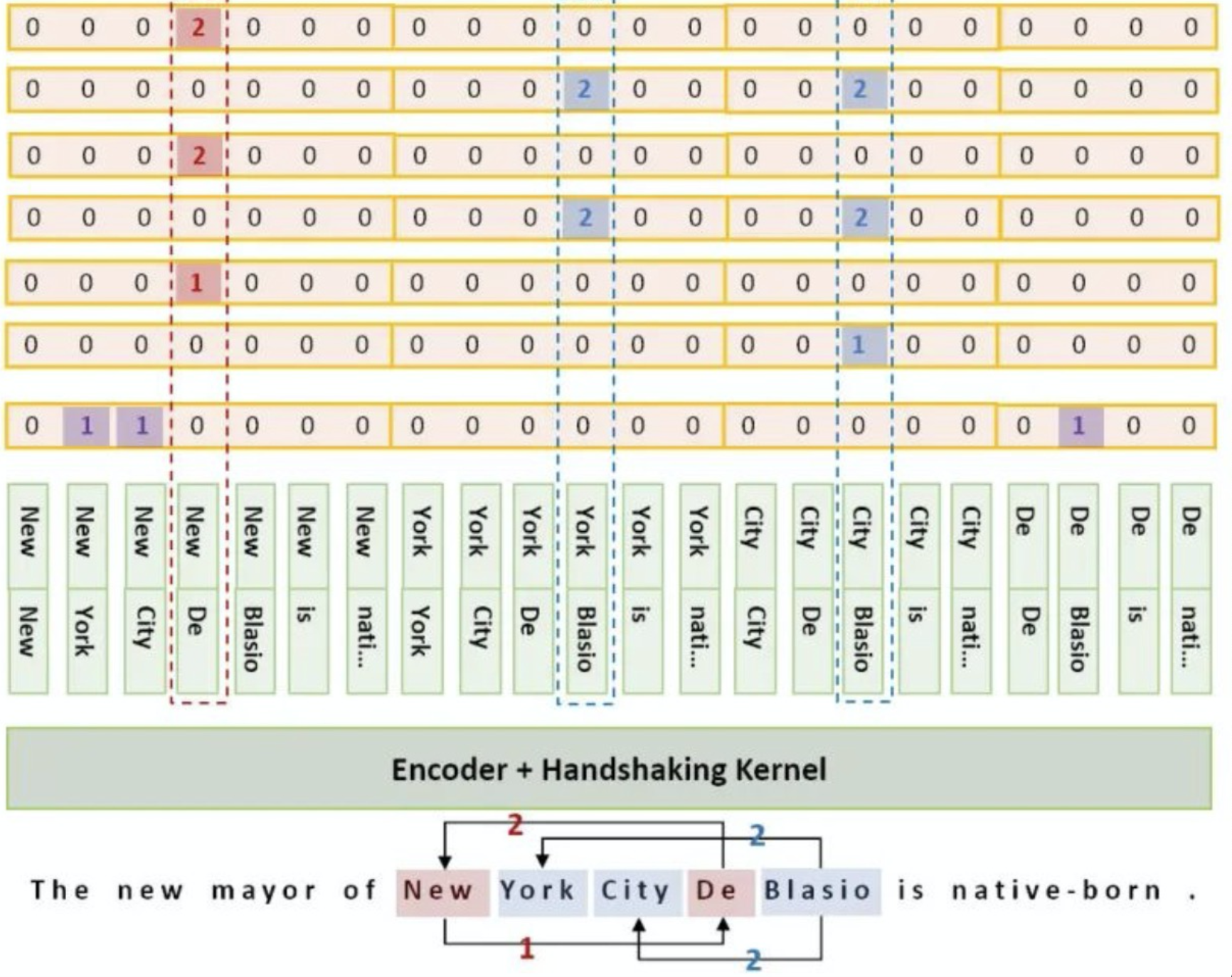
对于一个句子中的所有的token形成的SO组合,一共有N2种。假设我们的Token都已经经过了线性变化或者全连接层的洗礼,如图中对于每一个City,我们将其作为S,我们应该考虑其他所有token是否能和它形成SO关系,所以我们要计算每一个token和city经过V变换后的分数。
具体实现上也非常简单,我们可以构建一个NNHidden_size的token组合矩阵,经过一个P_num(关系类别总数)的Dense层后即可得到各个token之间在各个关系上的分值。
Subject = tf.keras.layers.Dense(hidden_size)(Encode)
Object = tf.keras.layers.Dense(hidden_size)(Encode)
'''
将原token的encode经过两个不同的全连接层后,得到Subject,Object两个token序列
对应公式中的 U*zj 和 W*zi
'''
Subject = tf.expand_dims(Subject,1)
#TensorShape([batch_size, 1, MAX_LEN, hidden_size])
Object = tf.expand_dims(Object,2)
#TensorShape([batch_size, MAX_LEN, 1, hidden_size])
Subject = tf.tile(Subject,multiples=(1,MAX_LEN,1,1))
#TensorShape([batch_size, MAX_LEN, MAX_LEN, hidden_size])
Object = tf.tile(Object,multiples=(1,1,MAX_LEN,1))
#TensorShape([batch_size, MAX_LEN, MAX_LEN, hidden_size])
concat_SO = tf.keras.layers.Concatenate(axis=-1)([Subject,Object])
#TensorShape([batch_size, MAX_LEN, MAX_LEN, 2*hidden_size])
output_logist = tf.keras.layers.Dense(P_num,activation='sigmoid')(concat_SO)
#TensorShape([batch_size, MAX_LEN, MAX_LEN, P_num])
'''
将组合后的 U*zj 与 W*zi 经过一个V全连接层,V.shape = (2*hidden_size,P_num)
对应公式中的 V*U*zj + V*W*zi = V(U*zj + W*zj + b)
'''
样本构建部分: 我们需要将一个标注好的[ MAX_LEN, MAX_LEN, P_num ]的矩阵作为Multi-Head Selection 结果的 Y值。
关于样本标注问题:
-
一个实体包含多个字符且可能存在实体嵌套的问题,如“我是歌手的主演是阿瓜”,需要抽取的关系为“我是歌手的主演是阿瓜”、“阿瓜是歌手”。
-
我们并不需要将“我是歌手”的四个token和“阿瓜”的两个token在P=主演的得分上全都标注为1,因为在实体抽取部分我们对实体的头和尾进行了识别,我们仅需要将 S“手”和O“瓜”所对应的P=主演的分值标注为1即可。本例中即 [3,9,indenx of 主演] = 1即可。如果阿瓜还是个歌手,则 [9,3,indenx of 职业] = 1即可,因为对于不同类型的嵌套的实体,可能存在尾字符相同的情况极少,因此我们标注尾字符而不是首字符。
以上就是Multi-head Selection Model部分的核心思路和代码。
完整模型代码如下:
- 用bert代替了原文的LSTM编码层。
- 这里将CRF替换为指针标注,并引入了实体的类别信息。
- 将实体的硬标签与实体的end_token拼接后传入Multi-head Selection层,这也是本人灵光一闪的部分,既然在Multi-head Selection层我们希望model能识别S的end_token和O的end_token, 我们就只给这两个token传入有效的实体标签信息,其余token类别都编码为0即可,实验正面这确实比你对所有的SOtoken都传入对应的实体类别embedding效果更好。
- 没有使用上文的软标签,软标签的具体实现可以通过自定义 layer 实现。
def build_model(pretrained_path,config,MAX_LEN,Cs_num,cs_em_size,R_num):
ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
cs = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
config.output_hidden_states = True
bert_model = TFBertModel.from_pretrained(pretrained_path,config=config,from_pt=True)
x, _, hidden_states = bert_model(ids,attention_mask=att)
layer_1 = hidden_states[-1]
start_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(layer_1)
start_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_start')(start_logits)
end_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(layer_1)
end_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_end')(end_logits)
cs_emb = tf.keras.layers.Embedding(Cs_num,cs_em_size)(cs)
concat_cs = tf.keras.layers.Concatenate(axis=-1)([layer_1,cs_emb])
f1 = tf.keras.layers.Dense(128)(concat_cs)
f2 = tf.keras.layers.Dense(128)(concat_cs)
f1 = tf.expand_dims(f1,1)
f2 = tf.expand_dims(f2,2)
f1 = tf.tile(f1,multiples=(1,MAX_LEN,1,1))
f2 = tf.tile(f2,multiples=(1,1,MAX_LEN,1))
concat_f = tf.keras.layers.Concatenate(axis=-1)([f1,f2])
output_logist = tf.keras.layers.Dense(128,activation='relu')(concat_f)
output_logist = tf.keras.layers.Dense(R_num,activation='sigmoid')(output_logist)
output_logist = tf.keras.layers.Lambda(lambda x: x**4,name='relation')(output_logist)
model = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[start_logits,end_logits,output_logist])
model_2 = tf.keras.models.Model(inputs=[ids,att], outputs=[start_logits,end_logits])
model_3 = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[output_logist])
return model,model_2,model_3
模型示意图之丑陋手稿:看个乐哈~:

模型效果:
没有做其他任何的处理,在2019百度三元抽取数据集上F1就达到了 79.157,而且模型结构相比于层叠序列标注简单了许多,理解起来也更加到胃~
Deep Biaffine Attention
一、Deep Biaffine Attention for Neural Dependency Parsing
这篇文章主要通过Biaffine来应用于依存关系分析上,但这也正好和关系抽取共通,只是依存关系中的关系类别只有一种,而在关系抽取中存在多种关系分类。
文章使用了双仿射注意力机制,而不是使用传统基于MLP注意力机制的单仿射分类器,或双线性分类器;上文提到的Multi-Head Selection正是由多个线性分类器构成的关系分类器。而现在我们希望能通过构建一个Biaffine Attention矩阵直接计算各个token之间在某个关系分类上的attention。


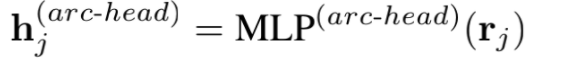
(这里直接将关系依存中的head 和 dep 称为 关系抽取中的S和O
- 将BiLSTM编码的token hidden 经过两个MLP 得到 S 和 O的特征表示;
- 对于这一步文章中特地提到:“Applying smaller MLPs to the recurrent output states before the biaffine classifier has the advantage of stripping away information not relevant to the current decision. That is, every top recurrent state ri will need to carry enough information to identify word i’s head, find all its dependents, exclude all its non-dependents, assign itself the correct label, and assign all its dependents their correct labels, as well as transfer any relevant information to the recurrent states of words before and after it. Thus ri necessarily contains significantly more information than is needed to compute any individual score, and training on this superfluous information needlessly reduces parsing speed and increases the risk of overfitting. Reducing dimensionality and applying a nonlinearity addresses both of these problems.”
- LSTM层的输出状态需要携带足够的信息,如识别其头结点,找到其依赖项,排除非依赖项,分配自身及其所有依赖的依存标签,而且还需要把其它任何相关信息传递至前或后单元。对这些不必要的信息进行训练会降低训练速度,而且还有过拟合的风险。使用MLP对LSTM输出降维,并使用双仿射变换,可解决这一问题!
- 简单来说我们希望能通过将原本高维度富含丰富信息的 hidden state 通过MLP降为至只能容下关系依赖信息的低纬度的特征,一方面加速训练,另一方面可以抑制过拟合。
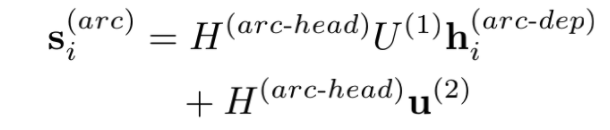
- 最终我通过构建一个U(Biaffine)矩阵来计算各个token之间依存的分值,并引入u矩阵来计算head的先验概率并产生偏置b。我们设token的长度为d,经过MLP压缩后的hidden_size为k,以下是我丑陋手稿来解释矩阵的乘法维度变化。

Biaffine实现代码:
class Biaffine(tf.keras.layers.Layer):
def __init__(self, in_size, out_size, bias_x=False, bias_y=False):
super(Biaffine, self).__init__()
self.bias_x = bias_x
self.bias_y = bias_y
self.U = self.add_weight(
name='weight1', shape=(in_size + int(bias_x),
out_size, in_size + int(bias_y)),trainable=True)
#U.shape = [in_size,out_size,in_size]
def call(self, input1, input2):
if self.bias_x:
input1 = tf.concat((input1, tf.ones_like(input1[..., :1])), axis=-1)
if self.bias_y:
input2 = tf.concat((input2, tf.ones_like(input2[..., :1])), axis=-1)
# bxi,oij,byj->boxy
logits_1 = tf.einsum('bxi,ioj,byj->bxyo', input1, self.U, input2)
return logits_1
完整模型代码:
def build_model(pretrained_path,config,MAX_LEN,Cs_num,cs_em_size,R_num):
ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
cs = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
config.output_hidden_states = True
bert_model = TFBertModel.from_pretrained(pretrained_path,config=config,from_pt=True)
x, _, hidden_states = bert_model(ids,attention_mask=att)
layer_1 = hidden_states[-1]
start_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(layer_1)
start_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_start')(start_logits)
end_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(layer_1)
end_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_end')(end_logits)
cs_emb = tf.keras.layers.Embedding(Cs_num,cs_em_size)(cs)
concat_cs = tf.keras.layers.Concatenate(axis=-1)([layer_1,cs_emb])
f1 = tf.keras.layers.Dense(128,activation='relu')(concat_cs)
f2 = tf.keras.layers.Dense(128,activation='relu')(concat_cs)
Biaffine_layer = Biaffine(128,R_num,bias_y=True)
output_logist = Biaffine_layer(f1,f2)
output_logist = tf.keras.layers.Activation('sigmoid')(output_logist)
output_logist = tf.keras.layers.Lambda(lambda x: x**4,name='relation')(output_logist)
model = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[start_logits,end_logits,output_logist])
model_2 = tf.keras.models.Model(inputs=[ids,att], outputs=[start_logits,end_logits])
model_3 = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[output_logist])
return model,model_2,model_3
模型效果:
F1 = 0.7964 相比Multi-head Selection F1提高了0.05左右
二、Named Entity Recognition as Dependency Parsing
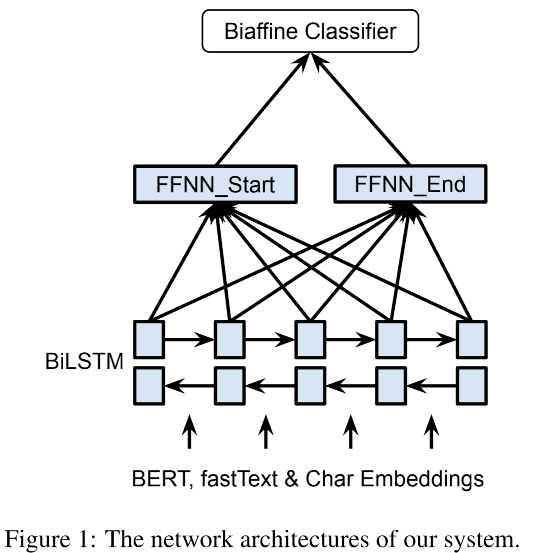
- After obtaining the word representations from the BiLSTM, we apply two separate FFNNs to create different representations (hs/he) for the start/end of the spans. Using different representations for the start/end of the spans allow the system to learn to identify the start/end of the spans separately. This improves accuracy compared to the model which directly uses the outputs of the LSTM since the context of the start and end of the entity are different. Finally, we employ a biaffine model over the sentence to create a l×l×c scoring tensor(rm), where l is the length of the sentence and c is the number of NER categories + 1(for non-entity). We compute the score for a span i by:

where si and ei are the start and end indices of the span i, Um is a d × c × d tensor, Wm is a 2d × c matrix and bm is the bias.
- 原文在BERT、fastText & Char Embeddings提取特征的基础上,通过BiLSTM捕获word representations后,同样使用两组全连接层来表示实体的头和尾,这比直接使用encode结果后直接输出实体的头和尾来说更加准确,毕竟两者所表示的信息是不同的。
- 之后将这两组特征丢入我们的主角:Biaffine矩阵。这个任务中我们不仅要识别实体的头和尾,还要识别出实体的类别C,因此我们目标是得到一个LLC的结果矩阵(其中L为序列长度,C为实体类别数目)
- 重点关注公式,其中Um、Wm、bm的shape及其表示意义如下:
- Um:tensor shape of dcd: 对hs(i)为头he(i)为尾的实体类别后验概率建模
- Wm:tensor shape of 2d*c: 对hs(i) 或 he(i)为尾的实体类别的后验概率分别建模
- bm:tensor shape of c: 对实体类别c的先验概率建模
- 对于头为hs(i),尾为he(i),类别为C的实体其概率分值为
- P(头为hs(i)&尾为he(i),C) + P(头为hs(i),C) + P(尾为he(i),C) + P( C )
- 根据公式我们可以构建新的Biaffine矩阵代码:
class Biaffine_2(tf.keras.layers.Layer):
def __init__(self, in_size, out_size,MAX_LEN):
super(Biaffine_2, self).__init__()
self.w1 = self.add_weight(
name='weight1',
shape=(in_size, out_size, in_size),trainable=True)
self.w2 = self.add_weight(
name='weight2',
shape=(2*in_size + 1, out_size),trainable=True)
self.MAX_LEN = MAX_LEN
def call(self, input1, input2):
f1 = tf.expand_dims(input1,2)
f2 = tf.expand_dims(input2,1)
f1 = tf.tile(f1,multiples=(1,1,self.MAX_LEN,1))
f2 = tf.tile(f2,multiples=(1,self.MAX_LEN,1,1))
concat_f1f2 = tf.concat((f1,f2),axis=-1)
concat_f1f2 = tf.concat((concat_f1f2,tf.ones_like(concat_f1f2[..., :1])), axis=-1)
logits_1 = tf.einsum('bxi,ioj,byj->bxyo', input1, self.w1, input2)
logits_2 = tf.einsum('bijy,yo->bijo',concat_f1f2,self.w2)
return logits_1+logits_2
尝试1
目前尝试中能拿到最好效果的模型方案(持续更新中):
- 实体标签作为比较强的特征,取得S和O的实体标签基本可以判断两者的关系,因此将标签直接引入Biaffine矩阵。
- 将BERT最后两层编码进⾏Biaffine计算,得到关系矩阵。
- 给实体抽取层增加了一层全连接,对实体抽取和关系抽取两个任务做适当的分离。
def build_model_3(pretrained_path,config,MAX_LEN,Cs_num,cs_em_size,R_num):
ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
cs = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
config.output_hidden_states = True
bert_model = TFBertModel.from_pretrained(pretrained_path,config=config,from_pt=True)
x, _, hidden_states = bert_model(ids,attention_mask=att)
layer_1 = hidden_states[-1]
layer_2 = hidden_states[-2]
start_logits = tf.keras.layers.Dense(256,activation = 'relu')(layer_1)
start_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(start_logits)
start_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_start')(start_logits)
end_logits = tf.keras.layers.Dense(256,activation = 'relu')(layer_1)
end_logits = tf.keras.layers.Dense(Cs_num,activation = 'sigmoid')(end_logits)
end_logits = tf.keras.layers.Lambda(lambda x: x**2,name='s_end')(end_logits)
cs_emb = tf.keras.layers.Embedding(Cs_num,cs_em_size)(cs)
concat_cs = tf.keras.layers.Concatenate(axis=-1)([layer_1,layer_2])
f1 = tf.keras.layers.Dropout(0.2)(concat_cs)
f1 = tf.keras.layers.Dense(256,activation='relu')(f1)
f1 = tf.keras.layers.Dense(128,activation='relu')(f1)
f1 = tf.keras.layers.Concatenate(axis=-1)([f1,cs_emb])
f2 = tf.keras.layers.Dropout(0.2)(concat_cs)
f2 = tf.keras.layers.Dense(256,activation='relu')(f2)
f2 = tf.keras.layers.Dense(128,activation='relu')(f2)
f2 = tf.keras.layers.Concatenate(axis=-1)([f2,cs_emb])
Biaffine_layer = Biaffine_2(128+cs_em_size,R_num,MAX_LEN)
output_logist = Biaffine_layer(f1,f2)
output_logist = tf.keras.layers.Activation('sigmoid')(output_logist)
output_logist = tf.keras.layers.Lambda(lambda x: x**4,name='relation')(output_logist)
model = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[start_logits,end_logits,output_logist])
model_2 = tf.keras.models.Model(inputs=[ids,att], outputs=[start_logits,end_logits])
model_3 = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[output_logist])
return model,model_2,model_3
F1 = 0.7986 比baseline提高了 0.022
尝试2
- 实体抽取部分用Biaffine矩阵代替序列标注,softmax激活后输出
- 并用bert后两层隐藏层同时编码实体和关系矩阵
def build_model(pretrained_path,config,MAX_LEN,Cs_num,cs_em_size,R_num):
ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
cs = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
config.output_hidden_states = True
bert_model = TFBertModel.from_pretrained(pretrained_path,config=config,from_pt=True)
x, pooling, hidden_states = bert_model(ids,attention_mask=att)
layer_1 = hidden_states[-1]
layer_2 = hidden_states[-2]
concat_cs = tf.keras.layers.Concatenate(axis=-1)([layer_1,layer_2])
start_logits = tf.keras.layers.Dense(128,activation = 'relu')(concat_cs)
end_logits = tf.keras.layers.Dense(128,activation = 'relu')(concat_cs)
S_Biaffine_layer = Biaffine_2(128,Cs_num,MAX_LEN)
S_logits = S_Biaffine_layer(start_logits,end_logits)
S_output_logist = tf.keras.layers.Activation('softmax',name='s_token')(S_logits)
S_logits = tf.keras.layers.Dense(256,activation = 'relu')(concat_cs)
S_logits = tf.keras.layers.Dropout(0.2)(S_logits)
S_logits = tf.keras.layers.Dense(128,activation = 'relu')(S_logits)
O_logits = tf.keras.layers.Dense(256,activation = 'relu')(concat_cs)
O_logits = tf.keras.layers.Dropout(0.2)(O_logits)
O_logits = tf.keras.layers.Dense(128,activation = 'relu')(O_logits)
cs_emb = tf.keras.layers.Embedding(Cs_num,cs_em_size)(cs)
f1 = tf.keras.layers.Concatenate(axis=-1)([S_logits,cs_emb])
f2 = tf.keras.layers.Concatenate(axis=-1)([O_logits,cs_emb])
Biaffine_layer = Biaffine_2(128+cs_em_size,R_num,MAX_LEN)
output_logist = Biaffine_layer(f1,f2)
output_logist = tf.keras.layers.Activation('sigmoid')(output_logist)
output_logist = tf.keras.layers.Lambda(lambda x: x**4,name='relation')(output_logist)
model = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[S_output_logist,output_logist])
model_2 = tf.keras.models.Model(inputs=[ids,att], outputs=[S_output_logist])
model_3 = tf.keras.models.Model(inputs=[ids,att,cs], outputs=[output_logist])
return model,model_2,model_3
F1值:0.8016
Biaffine 和 Multi-head对比
- 同样的计算开销:N^2
- 更多的参数:Baffine attention 矩阵拥有更多的参数,且相比于Muti-head Selection 能捕捉到S和O特征之间的交叉关系,而Muti-head Selection则是通过简单的MLP线性变化进行组合。丑陋手稿如下:

- 加入了start和end单独的先验概率
- 各模型结果对比

biaffine + biaffine 8 0.8016
总结
-
在关系抽取的任务中,baseline选择 Biaffine 会优于 基本的Multi-head,在这个基础上模型还有很多可以优化的地方。比如 如何更好的构造Biaffine矩阵,如何产生更有效的信息,但不至于过拟合。在我的实验过程中,Biaffine方法一直无法超越之前改良后的层叠式指针网络,这让我非常郁闷(主要是和别人实验结果不同),排除batch_size太小,模型收敛性较差的原因之外,根据模型的训练情况判断可能原因是在抽取实体时要求模型辨别实体的类别,导致该任务收敛性较差,试了多种网络较难拟合,也可能和数据集相关。使用上还存在一定的问题,会持续关注。
-
其实学术界已经对这种共享编码的效果提出了质疑,也有不少实验证明,实体抽取和关系抽取这两个任务在独立编码的情况下效果要好于共享编码。Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders
-
本文并没有尝试用CRF来抽取实体,而是直接使用了指针标注的方法,只是收到了大部分实体抽取文章的影响(默认指针标注优于CRF)之后会对这两种方法进行对比。
-
关系抽取的系列文章可能要到此告一段落,之后看到这方面重要的论文也会第一时间和大家分享~