前言
缓存一致性常见的更新策略也比较多,如先更新数据库再更新缓存,先删缓存再更新数据库等等,我在理解的时候有些混乱,所以这个文章提供了一些理解上的技巧去理解缓存一致性。
为什么会有缓存一致性的问题
- 缓存与数据库是两套中间件,存在网络抖动之类的原因导致没有更新任一方的可能
- 数据库大多都是事务型的中间件,支持错误回滚,缓存大多是非事务型的中间件,这里缓存更新失败了没办法回滚
所以根因是缓存大部分不支持事务无法回滚。
怎么尽量解决缓存一致性的问题
操作二者必定有先后顺序,存在以下两个情况:
- 先操作缓存,再操作数据库。操作缓存成功,数据库更新失败,缓存无法回滚,数据不一致
- 先操作数据库,再操作缓存。操作数据库成功,缓存操作失败,可触发异常回滚数据库,数据一致
根据上述所列,只能先操作数据库,再操作缓存了。
操作缓存也分两种:
- 更新缓存数据,可能并发请求,后一请求更新缓存的数据被前一请求的更新覆盖了,导致数据不一致
- 删除缓存数据,并发请求,二者都使缓存失效,查询请求将数据库数据加载到缓存中,数据一致
根据上述所列,只能使缓存失效,查询请求加载数据到缓存中了。
所以,如果在不加任何重试措施的情况下,先操作数据库,再删除缓存是一个容错较好的方法。
缓存一致性的分类 & 存在的问题
Client 维护缓存 & 数据库的一致性
-
更新缓存 -> 更新数据库
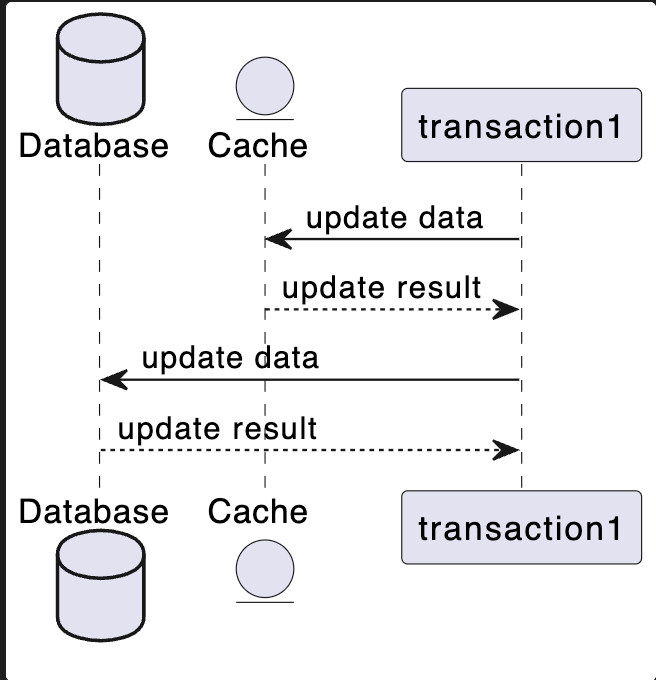
@startuml
Database Database as DB
entity Cache as Cache
transaction1 -> Cache: update data
transaction1 <-- Cache: update result
transaction1 -> DB: update data
transaction1 <-- DB: update result
@enduml
数据不一致:更新缓存成功了,更新数据库失败了,有数据不一致的问题,直到缓存超时失效或又一更新请求操作成功都会不一致
- 更新数据库 -> 更新缓存
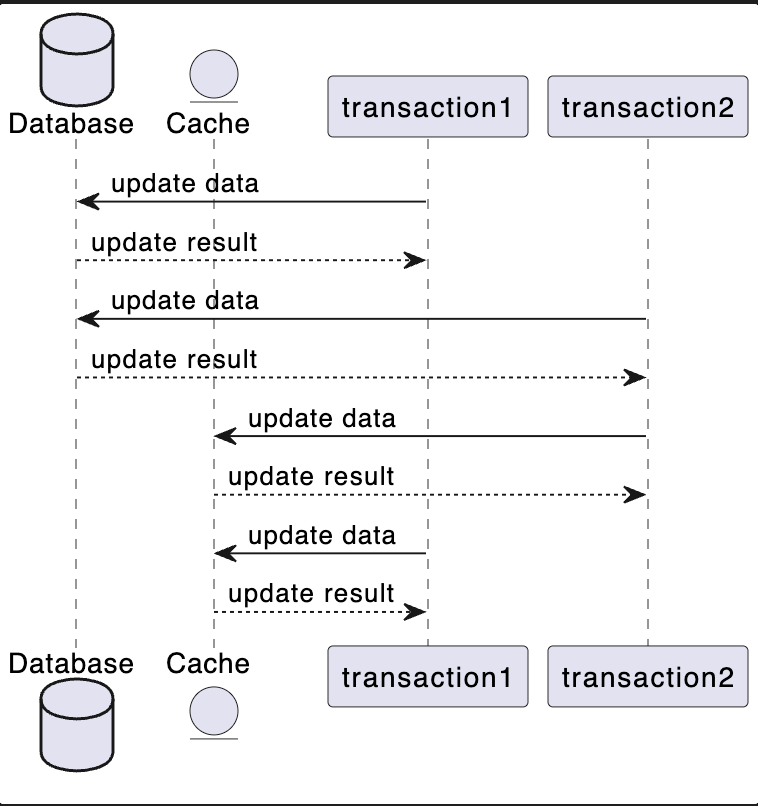
@startuml
Database Database as DB
entity Cache as Cache
transaction1 -> DB: update data
transaction1 <-- DB: update result
transaction2 -> DB: update data
transaction2 <-- DB: update result
transaction2 -> Cache: update data
transaction2 <-- Cache: update result
transaction1 -> Cache: update data
transaction1 <-- Cache: update result
@enduml
数据不一致:如 t1 先更新数据库,t2 在 t1 更新缓存前把数据库缓存都更新完了,t1 再更新缓存,这时候缓存上是 t1 的数据,数据库是 t2 的数据
-
删除缓存 -> 更新数据库

@startuml
Database Database as DB
entity Cache as Cache
transaction1 -> Cache: delete data
query1 -> DB: select data
query1 -> Cache: insert data
transaction1 -> DB: update result
@enduml
-
可能出现的数据不一致
- 如图所示,更新请求先删除缓存,查询请求从缓存获取不到数据从数据库获取数据(老数据)加载到缓存中,更新请求更新数据库
- 这样的流程会导致查询请求加载老数据到缓存中,后续更新请求更新新数据到数据库中,导致数据不一致
-
改进方式
暂无。
- 更新数据库 -> 删除缓存
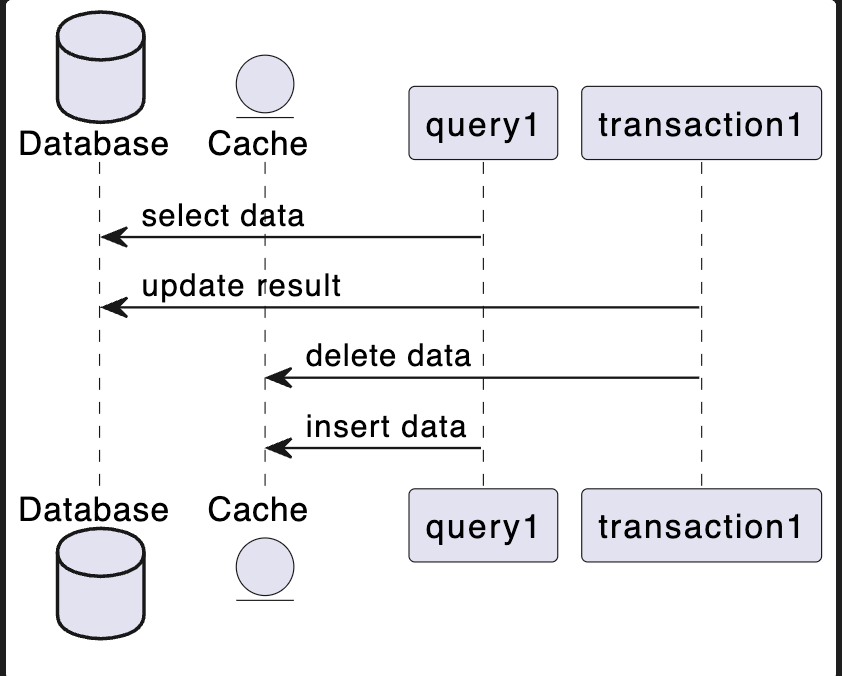
@startuml
Database Database as DB
entity Cache as Cache
query1 -> DB: select data
transaction1 -> DB: update result
transaction1 -> Cache: delete data
query1 -> Cache: insert data
@enduml
Server 维护缓存 & 数据库的一致性
-
Read though/Write though

@startuml
Database Database as DB
entity Cache as Cache
query -> repository: select data
repository -> cache: get data
repository -> DB: get data
DB -> repository: return data
repository -> cache: update data
repository -> query: return data
@enduml

@startuml
Database Database as DB
entity Cache as Cache
transcation -> repository: update data
repository -> cache: update data
repository -> DB: update data
DB -> repository: return result
repository -> transcation: return result
@enduml
- 可能出现的数据不一致
- 程序没有优雅关闭,更新请求先更新了缓存,但还没更新数据库,数据丢失
- 更新缓存成功,更新数据库失败导致的数据不一致
- 适用场景
- 改进方式
- Write Behind

@startuml
Database Database as DB
entity Cache as Cache
query -> repository: query data
repository -> cache: query data
repository -> DB: query data
DB -> repository: return data
repository -> cache: update data
repository -> query: return data
@enduml
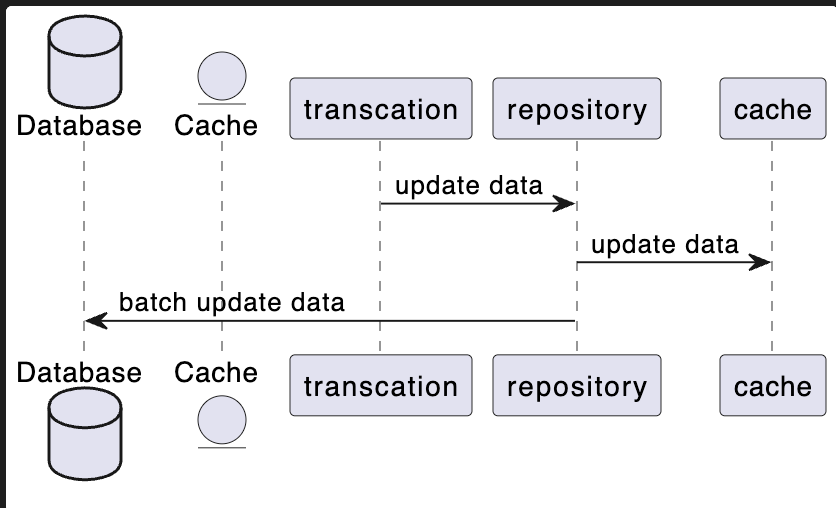
@startuml
Database Database as DB
entity Cache as Cache
transcation -> repository: update data
repository -> cache: update data
repository -> DB: batch update data
@enduml
- 可能出现的数据不一致
- 程序没有优雅关闭,更新请求先更新了缓存,但还没更新数据库,数据丢失
- 批量更新数据库失败导致的数据不一致
- 适用场景
- 改进方式
参考
https://coolshell.cn/articles/17416.html
本文首发于cartoon的博客
转载请注明出处:https://cartoonyu.github.io