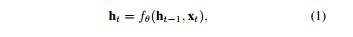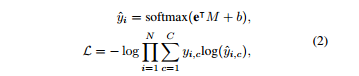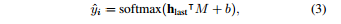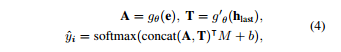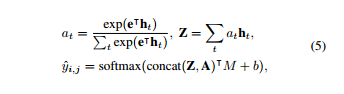基于音频和文本的多模态语音情感识别 语音情感识别是一项具有挑战性的任务,在构建性能良好的分类器时,广泛依赖于使用音频功能的模型。本文提出了一种新的深度双循环编码器模型,该模型同时利用文本数据和音频信号来更好地理解语音数据。由于情感对话是由声音和口语内容组成的,因此我们的模型使用双循环神经网络(RNN)对音频和文本序列中的信息进行编码,然后结合这些信息源中的信息来预测情感类。该体系结构从信号级到语言级对语音数据进行分析,从而比关注音频特性的模型更全面地利用数据中的信息。为了研究该模型的有效性和性能,进行了大量的实验。当模型应用于IEMOcap数据集时,我们提出的模型在将数据分配给四种情绪类别(即愤怒、快乐、悲伤和中性)中的一种方面优于以前的最先进方法,精度从68.8%到71.8%不等。 关键词:语音情感识别、计算辅助语言学、深度学习、自然语言处理 1.介绍
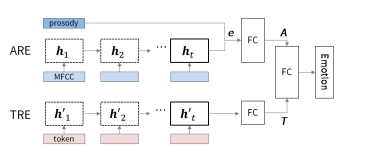
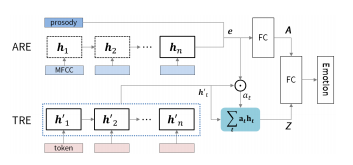
最近,深度学习算法已经成功地解决了各种领域的问题,如图像分类、机器翻译、语音识别、文本语音生成和其他机器学习相关领域[1、2、3]。同样,当深度学习算法应用于统计语音处理时,性能也得到了实质性的提高[4]。这些基本的改进使研究人员研究了与人类本性有关的其他课题,这些课题长期以来都是研究对象。其中一个主题涉及理解人类情感并通过机器智能(如情感对话模型)反映出来[5,6]。 在开发情感感知智能的过程中,第一步是建立强大的情感分类器,无论应用程序如何,都能显示出良好的性能;这个结果出现在过程中。 希腊Athens被认为是情感计算的基本研究目标之一[7]。尤其是语音情感识别任务是副语言学领域中最重要的问题之一。这一领域最近扩大了其应用范围,因为它是优化人机交互(包括对话系统)的关键因素。语音情感识别的目标是预测语音的情感内容,并根据几个标签(即快乐、悲伤、中性和愤怒)中的一个对语音进行分类。为了提高情绪分类器的性能,人们采用了各种类型的深度学习方法,但由于多种原因,这项任务仍然具有挑战性。首先,由于与人类参与相关的成本,没有足够的数据来训练复杂的基于神经网络的模型。第二,情感特征必须从低级语言信号中学习。基于特征的模型在应用于此问题时显示的技能有限。 为了克服这些局限性,我们提出了一种使用高级文本转录和低级音频信号的模型,以便在更大程度上利用低资源数据集中包含的信息。鉴于自动语音识别(ASR)技术(8、3、9、10)的最新改进,语音转录可以使用具有相当技能的音频信号进行。句子[11]所包含的情感词,如“可爱”和“棒极了”,与一般(非情感)词(如“人”和“天”)相比,具有强烈的情感性,因此,我们假设语音情感识别模型将从高级文本输入的结合中受益。 在本文中,我们提出了一种新的深度双循环编码器模型,该模型同时利用音频和文本数据识别语音中的情绪。为了研究该模型的有效性和性能,进行了大量的实验。我们提出的模型在应用于IEMOcap数据集(研究最为充分的数据集之一)时,比以前的最先进方法有68.8%到71.8%的优势。在对模型进行误差分析的基础上,证明了所提出的模型能够准确识别情绪类。此外,以前的模型中经常出现的中性类错误分类偏差,主要集中在音频特性上,在我们的模型中不太明显。 2.相关工作 经典的机器学习算法,如隐马尔可夫模型(HMMS)、支持向量机(SVMS)和基于决策树的方法,已经被用于语音情感识别问题[12、13、14]。近年来,为了提高语音情感识别的性能,研究者提出了各种基于神经网络的结构。一项初步研究利用深度神经网络(dnns)从原始音频数据中提取高级特征,并证明其在语音情感识别中的有效性[15]。随着深度学习方法的进步,人们提出了更复杂的神经网络体系结构。基于卷积神经网络(CNN)的模型已经通过频谱图或音频特征(如mel频率倒谱系数(mfcs)和低级描述符(llds))来训练原始音频信号的信息。这些基于神经网络的模型结合在一起,产生更高的复杂度模型[19,20],这些模型在应用于IEMOcap数据集时获得了最好的记录性能。 另一个研究方向是采用变机器学习技术与基于神经网络的模型相结合。一位研究人员利用多目标学习方法,并将性别和自然性作为辅助任务,以便基于神经网络的模型从给定的数据集学习更多的特征[21]。另一位研究人员利用相关领域的外部数据研究了转移学习方法[22]。 由于情感对话是由声音和口语内容组成的,研究人员还研究了声音特征和语言信息的结合,建立了基于信仰网络的识别情感关键短语的方法,并评估了来自音位序列和单词的言语线索的情感显著性[23,24]。然而,这些研究都没有在一个基于端到端学习神经网络的模型中同时利用来自语音信号和文本序列的信息来对情绪进行分类。 3.模型 本节介绍应用于语音情感识别任务的方法。我们首先分别介绍音频和文本模式的重复编码器模型。然后,我们提出了一种多模式方法,通过一个双循环编码器同时对音频和文本信息进行编码。 3.1 音频循环编码器(ARE) 受[25,26]中使用的体系结构的激励,我们构建了一个音频循环编码器(ARE)来预测给定音频信号的类别。一旦从音频信号中提取了mfcc特性,序列特性的一个子集就被送入ASR技术[8]。 图1:编码器的多模双循环。上半部分显示的是ARE,什么是音频信号编码,和下半部分显示Tre,什么是编码器文本信息。 RNN(IU,门控单元(Grus)复发),这导致在形成的网络的内部模型的隐状态HT到时间序列模式。这是一个内部的隐状态更新在每个时间步上的输入数据和以前的时间步长的隐状态ht−1为如下: 其中fθ为带权参数θ的RNN函数,ht表示t时间步的隐藏状态,xt表示x=x1:ta_中的t-th mfcc特征。在用RNN编码音频信号x后,RNN的最后一个隐藏状态hta被认为是包含所有顺序音频数据的代表向量。然后将该向量与另一个韵律特征向量p连接,以生成信号的更信息化的向量表示,e=concat hta,p。利用openshill工具箱[27]分别提取音频信号的mfcc和韵律特征,分别取xt∈r 39和p∈r 35。最后,将SoftMax函数应用于向量e来预测情绪类。对于给定的音频样本i,我们假设y i是真标签向量,它包含所有零,但在正确的类中包含一个零,y_i是从SoftMax层预测的概率分布。培训目标的形式如下: 式中,e是计算出的具有维数e∈r d的音频信号的代表向量。m∈r d×c和偏差b是已知的模型参数。c是课程总数,n是培训中使用的样本总数。图1的上部显示了ARE模型的体系结构。 3.2文本循环编码器(TRE) 我们假设语音记录可以从音频信号中高精度地提取出来,鉴于ASR技术的进步。我们试图用处理过的文本信息作为另一种形式来预测给定信号的情绪类别。为了使用文本信息,使用自然语言工具包(NLTK)[28]将语音转录本标记化并编入标记序列中。然后,每个标记都通过一个嵌入字的层传递,该层将字索引转换为相应的300维向量,该向量包含单词之间的附加上下文意义。嵌入令牌的序列被送入文本循环编码器(TRE),这样,音频mfcc功能就可以用公式1表示。在这种情况下,xt是来自文本输入的第t个嵌入标记。最后,使用SoftMax函数从文本RNN的最后一个隐藏状态预测出情绪类。 我们使用与ARE模型相同的训练目标,目标类的预测概率分布如下: 其中,hlast是文本rnn的最后一个隐藏状态,hlast∈r d,m∈r d×c和bias b是学习的模型参数。图1的下半部分显示了TRE模型的体系结构。 3.3.多式联运双上诉裁定书 为了克服现有方法的局限性,我们提出了一种新的多模式双循环编码器(MDRE)结构。在本研究中,我们分别考虑了包含连续音频信息、统计音频信息和文本信息的多种形式,如mfcc特征、韵律特征和转录。这些数据类型与ARE和TRE案例中使用的数据类型相同。MDRE模型使用两个RNN分别对来自音频信号和文本输入的数据进行编码。音频RNN使用公式1对音频信号中的MFCC功能进行编码。音频RNN的最后一个隐藏状态与韵律特征相连接,形成最终的矢量表示形式E,然后将该矢量通过完全连接的神经网络层,形成音频编码矢量A,另一方面,文本RNN使用公式1对转录词序列进行编码。文本RNN的最终隐藏状态也通过另一个完全连接的神经网络层,形成文本编码向量t,最后将SoftMax函数应用于向量a和t的串联,对情感类进行预测,使用与ARE模型相同的训练目标,预测概率。目标类的ty分布如下: 其中gθ,g0θ是带有权参数θ的前馈神经网络。 图2:MDREA模型架构文本RNN HT隐态序列的加权总和是以注意力加权为依据的,并被计算为音频RNN E和HT的最后编码矢量的点产物。 音频-RNN and text-RNN,respectively.M8712;R×C和BIAS B是学习模型参数。 3.4 多模双循环注意编码器(MDREA) 受神经机器翻译中注意力机制概念的启发(29),我们提出了一种新颖的多模态注意方法来聚焦包含强情绪信息的转录本的特定部分,调节音频信息。图2显示了MDREA模型的体系结构。首先,音频数据和文本数据用音频RNN和文本RNN进行编码,使用公式1。然后我们将最终的音频编码向量e作为上下文向量。如等式5所示,在每个时间步骤t中,对上下文向量e与文本rnn在每个t-th序列ht处的隐藏状态之间的点积进行评估,以计算在处的相似性得分。将该分数a t作为权重参数,计算文本rnn,ht隐藏状态序列的加权和,生成一个注意应用向量z。该注意应用向量与audiornn a(方程式4)的最终编码向量相连,该向量将通过softmax函数t传递。o预测情绪等级。我们使用与ARE模型相同的训练目标,目标类的预测概率分布如下: 其中m∈r d×c和偏差b是已知的模型参数。 4 实验装置和数据集 4.1 数据集 我们使用交互式情绪二元运动捕捉(IEMOcap)[19]数据集评估我们的模型。该数据集是根据戏剧理论收集的,以模拟演员之间的自然二元互动。我们使用分类评估,多数同意。我们只使用了四种情绪类别:快乐、悲伤、愤怒和中性,来比较我们的模型与使用相同类别的其他研究的表现。IEMOcap数据集包括五个会话,每个会话包含两个演讲者(一个男性和一个女性)的发言。这个数据收集过程产生了10个独特的演讲者。为了与以前的工作进行一致的比较,我们将兴奋数据集与幸福数据集合并。最后一个数据集总共包含5531个话语(1636个快乐,1084个悲伤,1103个愤怒,1708个中性)。 4.2 特征提取 为了从音频信号中提取语音信息,我们使用了广泛用于分析音频信号的mfcc值。mfcc功能集共包含39个功能,其中包括26个MelFrequency波段和对数能量参数中的12个mfcc参数(1-12)、13个delta和13个加速度系数。帧大小通过Hamming功能以10 ms的速率设置为25 ms。根据每个波形文件的长度,MFCC特征的顺序步骤是不同的。为了从数据中提取更多的信息,我们还使用韵律特征,这些特征显示了情感计算的有效性。韵律特征由35个特征组成,包括f0频率、发声概率和响度轮廓。所有这些mfcc和韵律特征都是使用OpenSmile工具包[27]从数据中提取的。 4.3 实施细节 在RNN函数的变体中,我们使用GRU,因为它们产生与LSTM类似的性能,并且包含较少数量的权重参数[30]。我们对音频输入使用750的最大编码器步骤,这是基于[31]中提供的实现选择,对文本输入使用128,因为它覆盖了文本的最大长度。数据集的词汇大小为3747,包括表示未知单词的“unk”标记和用于指示准备小批量数据时添加的填充信息的“pad”标记。每个模型(ARE、TRE、MDRE和MDREA)的RNN中的隐藏单元数和层数是根据大量超参数搜索实验选择的。使用正交法初始化隐藏单元的权重。 Table 1.模型性能比较在博尔德标记了前2个最好的模型(根据未加权平均回归)。“-ASR”模型使用来自Google云语音API的已处理文本进行培训。 权重[32]],文本嵌入层由预训练的字嵌入向量初始化[33]。 在准备文本数据集时,为了简单起见,我们首先使用iemocap数据集的已发布副本。为了研究实际性能,我们随后使用ASR系统(Google Cloud Speech API)处理所有IEMOcap音频数据,并检索文本。google asr系统的误字率(wer)为5.53%,反映了系统的性能。 5 经验结果 5.1 性能评价
由于数据集没有预先明确划分为培训、开发和测试集,因此我们执行5倍的交叉验证来确定模型的整体性能。每个折叠中的数据分为培训、开发和测试数据集(分别为8:0.5:1.5)。在对模型进行训练后,我们测量了5倍数据集上的加权平均精度(wap)。我们对模型进行了10次培训和评估,并根据平均分和标准差评估模型性能。 我们检查了wap值,如表1所示。首先,我们的ARE模型显示了基线性能,因为我们使用了最小的音频特性,例如mfcc和具有简单架构的韵律特性。另一方面,与ARE相比,TRE模型显示出更高的性能增益。从这个结果中,我们注意到文本数据在情绪预测任务中是信息丰富的,而重复编码器模型对于理解这些类型的顺序数据是有效的。第二,新提出的模型MDRE显示出显著的性能提升。因此,它以0.718的WAP值实现了最先进的性能。结果表明,多模信息是影响情感计算的关键因素。 最后,注意力模型mdrea也优于现有的最佳研究结果(wap 0.690到0.688)[20]。然而,MDREA模型与MDRE模型的性能不匹配,即使它使用了更复杂的体系结构。我们认为这一结果的产生是因为没有足够的数据来正确确定MDREA模型中的复杂模型参数。此外,我们假设在应用注意机制的同时,当音频信号与文本序列对齐时,该模型将显示出更好的性能。我们将这一点的实现作为未来的研究方向。 为了研究所提出的模型的实际性能,我们对ASR处理的转录数据进行了进一步的实验(见表1中的“-ASR”模型)。处理后的转录本的标签准确率为5.53%。与tre、mdre和mdrea模型相比,tre-asr、mdre-asr和mdrea-asr模型反映出性能的下降。然而,这些模型的性能仍然具有竞争力;特别是,MDreasr模型优于先前的最佳性能模型3cnn-lstm10h(wap 0.691至0.688)。 5.2 误差分析 我们分析了ARE、TRE和MDRE模型的预测。图3显示了每个模型的混淆矩阵。ARE模型(图3(a))错误地将大多数快乐的实例分类为中性(43.51%),因此,它显示预测快乐类的准确性降低(35.15%)。总的来说,大多数情绪课经常与中性课混淆。这一观察结果与[31]的发现一致,后者指出中性类位于活化价空间的中心,使其与其他类的区别更加复杂。有趣的是,与ARE模型相比,TRE模型(图3(b))在预测快乐班级方面显示出更大的预测收益(35.15%至75.73%)。这一结果似乎是合理的,因为模型可以从快乐和中性表达中的单词分布差异中获益,这给模型提供了比音频信号数据更多的情感信息。另一方面,令人吃惊的是,Tre模型错误地预测了悲伤阶级的实例,认为快乐阶级占16.20%,尽管这些情绪状态是彼此对立的。
MDRE模型(图3(c))弥补了前两个模型(ARE和TRE)的缺点,并从其优点中获得了令人惊讶的好处。沿对角线排列的数值表明,正确预测类的所有精度都提高了。此外,TRE模型中不正确的“悲伤到快乐”案例的发生率从16.20%降至9.15%。 六 结论 在本文中,我们提出了一种新的多模双循环编码器模型,它同时利用文本数据和音频信号,以便更好地理解语音数据。我们的模型使用双RNN对音频和文本序列中的信息进行编码,然后使用前馈神经模型将来自这些源的信息结合起来预测情绪类。大量实验表明,我们提出的模型在对四种情绪类别进行分类方面优于其他最先进的方法,当模型应用于IEMOcap数据集时,其准确度在68.8%到71.8%之间。特别是,它解决了预测经常错误地产生中性类的问题,就像以前的关注音频特性的模型一样。 在未来的工作中,我们的目标是将模式扩展到音频、文本和视频输入。此外,我们计划研究注意力机制在多种模式数据中的应用。这种方法似乎可以发现增强型学习方案,这将提高语音情感识别和其他多模态分类任务的性能。