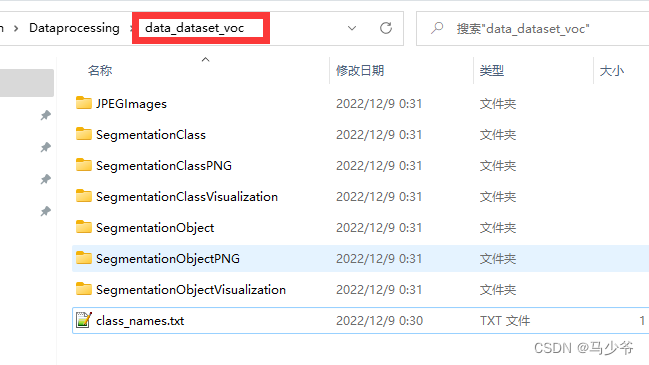
1、数据集介绍
COCO数据集有80个类别,VOC数据集有20个类别。当这些数据集类别中没有自己需要的时候,就需要自己动手做自己的数据集了。
我自己在做数据集的时候主要使用到了labelme和labelImg两个工具。labelme主要是制作语义分割数据集(ImageSets,JPEGImages,SegmentationClass,SegmentationObject几个文件夹),labelImg主要是制作目标检测数据集(主要是Annoations中的xml文件),最后把两个合在一起就可以使用maskR-CNN来训练了。文件结构如下图所示:
2、安装labelme
参考:Windows下使用labelme标注图像
3、开始数据集制作
点击OpenDir打开要制作数据集图片的文件夹。点击CreatePolygons标记图片就可以了,最后每张图片标记好之后,别忘记点击save保存。此时的会保存问json格式的文件,如图所示:
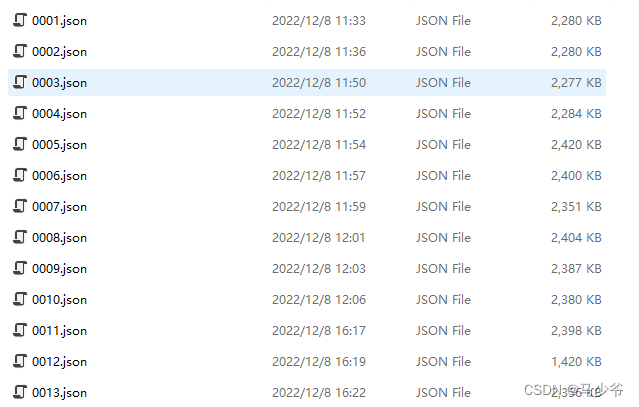
接下来就要转换这些json格式为轮廓图片。
将图片和json文件放在同一个文件夹,命名为data_annotated
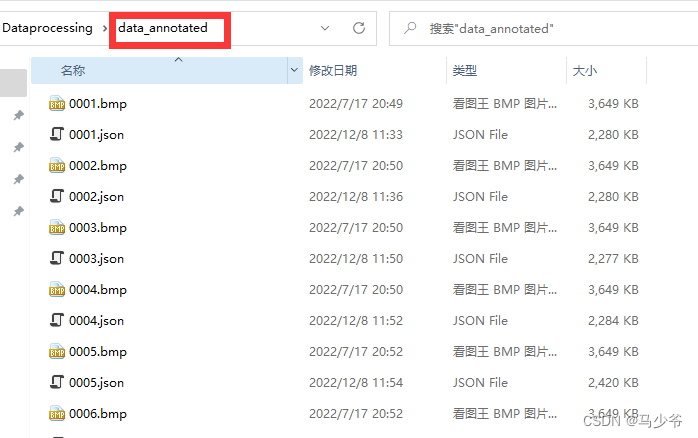
在data_annotated文件的目录下启动cmd,命令conda activate labelme切换至labelme环境下。
编辑labelme2voc.py文件
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
os.makedirs(osp.join(args.output_dir, "SegmentationObject"))
os.makedirs(osp.join(args.output_dir, "SegmentationObjectPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationObjectVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_cls_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_clsp_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_clsv_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
out_ins_file = osp.join(
args.output_dir, "SegmentationObject", base + ".npy"
)
out_insp_file = osp.join(
args.output_dir, "SegmentationObjectPNG", base + ".png"
)
if not args.noviz:
out_insv_file = osp.join(
args.output_dir,
"SegmentationObjectVisualization",
base + ".jpg",
)
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
cls, ins = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
ins[cls == -1] = 0 # ignore it.
# class label
labelme.utils.lblsave(out_clsp_file, cls)
np.save(out_cls_file, cls)
if not args.noviz:
clsv = imgviz.label2rgb(
cls,
imgviz.rgb2gray(img),
label_names=class_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_clsv_file, clsv)
# instance label
labelme.utils.lblsave(out_insp_file, ins)
np.save(out_ins_file, ins)
if not args.noviz:
instance_ids = np.unique(ins)
instance_names = [str(i) for i in range(max(instance_ids) + 1)]
insv = imgviz.label2rgb(
ins,
imgviz.rgb2gray(img),
label_names=instance_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_insv_file, insv)
if __name__ == "__main__":
main()
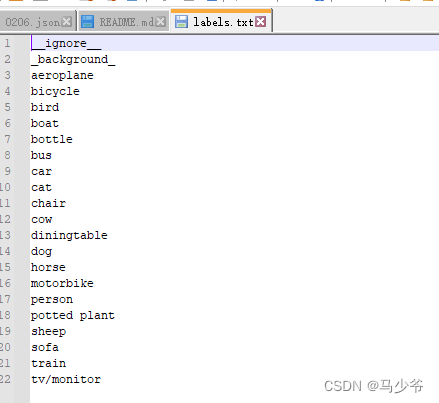
编辑labels.txt文件
内容是数据集的各个类别
运行指令:
python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
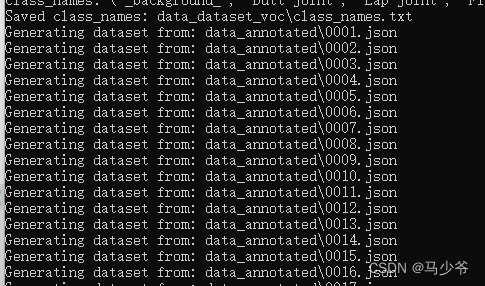
即生成如下文件夹