
来自AAAI2021
文章链接:https://www.cbsr.ia.ac.cn/users/xiaobowang/papers/TNAS_AAAI2021.pdf
摘要
现有的知识蒸馏方法都是手工的启发式方法,这些方法旨在预先定义好目标学生网络,由于需要花费大量精力去找到一个合适的学生网络,这样的做法可能会导致出现次优解。
因此,这篇文章提出了一种教师网络指导的神经网络搜索方法,可以直接通过通道数和层数对学生网络进行搜索。
通俗的来说就是将搜索空间定义成通道数/层数(通过概率分布进行采样),然后将loss最小化进行学习。最终将每个分布中概率最大的值作为学生网络的深度和宽度。
一、介绍
这里作者列举了现有的一些方法,比较特别的有:
- Wang团队2019年提出的:教师网络使用原有的训练集,学生网络使用LR图像训练集
- Peng团队2019年提出的:使用概率一致性知识,不仅传递实际层级之间的参数信息,而且传递实例间的相关性。
但现有的这些方法都需要预先定义学生网络,而本文提出的方法是基于概率优化提出的。
主要贡献:
- 特征信息灵活且有效,因此对于人脸识别模型的蒸馏提取来说十分适合。为此本文利用特征拟合作为搜索目标以搜索合适的学生网络。
- 提出了TNAS框架,将搜索空间定义为学生网络的宽度和深度,并以可学习的概率不断的附加不同的候选层/通道。(?)
- 算法性能验证
二、相关工作
-
人脸识别: 人脸识别通常使用的是基于margin的softmax loss(关于人脸识别中的margin损失函数总结可以看这篇文章:点我点我~)、度量学习的损失函数或者两者共同使用。
-
知识蒸馏: 2015年有团队首次提出了基于软化概率一致性(?)的知识蒸馏算法。
-
神经网络架构搜索: 神经网络架构搜索可以将预定义的架构转换成一个需要学习的过程。本文通过经验观察到,相对于网络的拓扑结构(具体某层的设计)来说,网络的规模对于人脸识别蒸馏来说更加关键。通过改善现有方法的规模,它们大多数都获得了性能方面的提升。Dong的团队在2019年提出了一种基于概率的可微分方法,用于缩小CNNs的规模。(?)本文提出的方法就是将神经网络架构搜索与人脸识别相结合实现的。
三、研究方法
神经网架构搜索包括两个重点概念:搜索目标、搜索空间。
3.1 知识蒸馏
对于人脸识别问题上的知识蒸馏来说,一般情况下我们有一个训练好的教师网络,并且需要根据它蒸馏出学生网络,但问题是我们往往并不知道这个教师网络是怎么训练的(包括训练集,loss函数以及训练策略等),这时一般有以下几种情况:
-
One-hot标签: 如果学生网络的训练集有很完备的标签时,可以直接用one-hot标签进行训练,且在保证通用性的前提下可以使用AM-softmax损失进行监督。但这种方法并没有利用教师网络。
-
概率知识蒸馏(PKD): 令最终的softmax输出为
z
z
z,教师网络的soft标签可以表示为
P
T
τ
=
(
z
T
/
τ
)
P_T^\tau =(z_T/\tau)
PTτ=(zT/τ),这里
τ
\tau
τ是温度参数;学生网络的soft标签可以表示为
P
S
τ
=
(
z
S
/
τ
)
P_S^\tau =(z_S/\tau)
PSτ=(zS/τ)。现有的知识蒸馏方法往往利用了概率知识蒸馏方法:
L
P
K
D
=
L
(
P
T
τ
,
P
S
τ
)
=
L
(
(
z
T
/
τ
)
,
(
z
S
/
τ
)
)
L_{PKD}=L(P_T^\tau,P_S^\tau)=L((z_T/\tau),(z_S/\tau))
LPKD=L(PTτ,PSτ)=L((zT/τ),(zS/τ))其中
L
L
L表示的是交叉熵损失。但PKD的缺憾在于其受限于基于softmax的损失,且要求教师网络和学生网络的训练类别是一样的。
-
特征知识蒸馏: 在人脸识别中还有一种将特征层作为隐藏层去训练学生网络的方法:
L
F
K
D
=
H
(
F
S
,
F
T
)
=
∣
∣
F
S
−
F
T
∣
∣
L_{FKD}=H(F_S,F_T)=||F_S-F_T||
LFKD=H(FS,FT)=∣∣FS−FT∣∣
其中
H
H
H为
L
2
L_2
L2损失,
F
S
F_S
FS及
F
T
F_T
FT分别为学生网络和教师网络的特征。鉴于FKD的简单性与灵活性,我们将采用FKD作为评价搜索到的学生网络的标准。
3.2 教师网络指导下的神经网络架构搜索
预定义的学生网络往往不是最优的网络结构,其原因在于需要花费大量精力去找到一个合适的学生网络。本文的旨在通过搜索,找到一个合适的架构用于学生网络。
因此,本文将学生网络的深度和宽度的候选空间作为搜索空间。
3.2.1 搜索宽度
文章中用
α
∈
R
∣
C
∣
\alpha\in R^{|C|}
α∈R∣C∣表示一层中可能的通道数的分布。选择第j个候选通道的概率可以表示为:
p
j
=
e
x
p
(
α
j
)
∑
k
=
1
∣
C
∣
e
x
p
(
α
k
)
,
1
≤
j
≤
∣
C
∣
p_j=\frac{exp(\alpha_{j})}{\sum\nolimits_{k=1}^{|C|}exp(\alpha_k)} ,\quad 1\leq j \leq |C|
pj=∑k=1∣C∣exp(αk)exp(αj),1≤j≤∣C∣
但上述的采样操作是不可微的,因此需要采用Gumbel-Softmax的软化采样过程(?记得看)去优化
α
\alpha
α:
p
j
^
=
e
x
p
(
(
l
o
g
(
p
j
)
+
o
j
)
/
τ
)
∑
k
=
1
∣
C
∣
e
x
p
(
(
l
o
g
(
p
k
)
+
o
k
)
/
τ
)
\hat{p_j}=\frac{exp((log(p_j)+o_j)/\tau)}{\sum\nolimits_{k=1}^{|C|}exp((log(p_k)+o_k)/\tau)}
pj^=∑k=1∣C∣exp((log(pk)+ok)/τ)exp((log(pj)+oj)/τ)
3.2.2 搜索深度
3.2.3 搜索目标
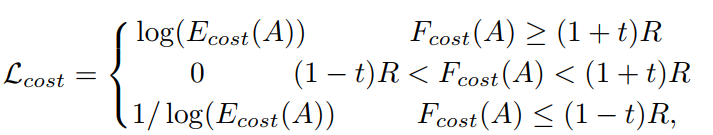
根据深度和宽度构建了相关loss函数,并且最终进行优化找到最大的size

四、实验
4.1 数据集
实验使用的训练集为ASIA-WebFace (Yi et al. 2014)和MS-Celeb-1M
测试集为LFW、SLLFW、 CALFW、 AgeDB、 CFP、RFW、 MegaFace和TrillionPairs