一、简介
强化学习是一类解决马尔可夫决策过程的方法,其中,动态规划、蒙特卡洛以及时序差分是强化学习算法的三大基础算法。本文就其实际效果来对比三种方法以及其子方法的不同与优缺点。本文就动态规划方法进行简单介绍。
二、动态规划(DP,Dynamic Planning)方法
动态规划是一类优化方法,在给定一个马尔可夫决策过程(MDP)描述的完备环境模型的情况下,其可以计算最优的策略。其中心思想是通过将一个系列性的复杂问题进行分解来简化问题的求解。对于强化学习问题,传统的DP算法,作用比较有限:一是完备的环境模型只是一种假设;二是它的计算复杂度极高。但是,它仍然是一个非常重要的理论。对于之后的方法而言,DP提供了一个必要的基础。
(一)策略评估
策略评估即对于任意一个策略
π
\pi
π,计算其状态价值函数
v
π
v_{\pi}
vπ.在这里直接给出迭代策略评估算法,用于估计
V
≈
v
π
V≈v_{\pi}
V≈vπ
- 输入待评估的策略
π
\pi
π
- 算法参数:小阈值
θ
\theta
θ>0,用于确定估计量的精度
- 对于任意状态
s
∈
S
+
s\in S^{+}
s∈S+,任意初始化
V
(
s
)
V(s)
V(s),其中
V
(
终止状态
)
=
0
V(终止状态)=0
V(终止状态)=0
- 循环:
Δ
←
0
\Delta \leftarrow 0
Δ←0
对每一个
s
∈
S
+
s\in S^{+}
s∈S+循环:
v
←
V
(
s
)
v \leftarrow V(s)
v←V(s)
V
(
s
)
←
∑
a
π
(
a
∣
s
)
∑
s
′
,
a
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
V
(
s
′
)
]
V(s) \leftarrow \sum_{a}{\pi(a|s)\sum_{s^{'},a}{p(s^{'},r|s,a)[r+\gamma V(s^{'})]}}
V(s)←∑aπ(a∣s)∑s′,ap(s′,r∣s,a)[r+γV(s′)]
Δ
←
m
a
x
(
Δ
,
∣
v
−
V
(
s
)
∣
)
\Delta \leftarrow max(\Delta,|v-V(s)|)
Δ←max(Δ,∣v−V(s)∣)
till
Δ
<
0
\Delta<0
Δ<0
我们从上述算法中也可以看到,所谓完备环境的含义即是,对于任意的
(
s
,
a
)
(s,a)
(s,a)二元组都能够得到确定的
p
(
s
′
,
r
∣
s
,
a
)
p(s^{'},r|s,a)
p(s′,r∣s,a)以及对于任意状态
s
s
s,我们都可以得到
p
(
s
∣
a
)
p(s|a)
p(s∣a)。因此,如果没有这种比较完备的环境,就不适合使用动态规划方法。
(二)策略迭代
1.策略改进
对于一个策略
π
\pi
π,如果我们想要改进它,那么一个直观的方法是针对于某一个状态
s
s
s,我们可以采用一个动作
a
≠
π
(
s
)
a \neq \pi(s)
a=π(s),而当处于其他状态时,依旧按照策略
π
\pi
π来采取动作。如果采取新动作
a
a
a之后的动作价值
q
(
s
,
a
)
≥
v
π
(
s
)
q(s,a) \ge v_{\pi}(s)
q(s,a)≥vπ(s),那么我们就可以认定采取新动作的策略
π
′
\pi ^{'}
π′比之前的策略
π
\pi
π更好。所以我们在策略改进的过程中的目标就是采用一个不同于原策略
π
\pi
π的新动作
a
a
a,从而使得a的动作价值大于原策略价值。
即
π
′
(
s
)
=
a
r
g
m
a
x
a
∑
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
v
π
(
s
′
)
]
\pi^{'}(s)=argmax_{a}\sum{p(s^{'},r|s,a)[r+\gamma v_{\pi}(s^{'})]}
π′(s)=argmaxa∑p(s′,r∣s,a)[r+γvπ(s′)]
2.策略迭代
一旦一个策略
π
\pi
π根据
v
π
v_{\pi}
vπ产生了一个更好的策略
π
′
\pi^{'}
π′,我们就可以通过计算
v
π
′
v_{\pi^{'}}
vπ′来得到一个更好的策略
π
′
′
\pi^{''}
π′′。通过这样的一个链式的方法就可以得到一个不断改进的策略和价值函数的序列:
π
0
→
v
π
0
→
π
1
→
v
π
1
→
.
.
.
→
π
∗
→
v
π
∗
\pi_{0} \rightarrow v_{\pi_{0}} \rightarrow \pi_{1} \rightarrow v_{\pi_{1}} \rightarrow ... \rightarrow \pi* \rightarrow v_{\pi*}
π0→vπ0→π1→vπ1→...→π∗→vπ∗
3.迭代算法
- 初始化
对于
s
∈
S
s \in S
s∈S,任意设定
V
(
s
)
∈
R
V(s) \in R
V(s)∈R以及
π
(
s
)
∈
A
(
s
)
\pi(s) \in A(s)
π(s)∈A(s)
- 策略评估
输入待评估的策略
π
\pi
π
算法参数:小阈值
θ
\theta
θ>0,用于确定估计量的精度
对于任意状态
s
∈
S
+
s\in S^{+}
s∈S+,任意初始化
V
(
s
)
V(s)
V(s),其中
V
(
终止状态
)
=
0
V(终止状态)=0
V(终止状态)=0
循环:
Δ
←
0
\Delta \leftarrow 0
Δ←0
对每一个
s
∈
S
+
s\in S^{+}
s∈S+循环:
v
←
V
(
s
)
v \leftarrow V(s)
v←V(s)
V
(
s
)
←
∑
a
π
(
a
∣
s
)
∑
s
′
,
a
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
V
(
s
′
)
]
V(s) \leftarrow \sum_{a}{\pi(a|s)\sum_{s^{'},a}{p(s^{'},r|s,a)[r+\gamma V(s^{'})]}}
V(s)←∑aπ(a∣s)∑s′,ap(s′,r∣s,a)[r+γV(s′)]
Δ
←
m
a
x
(
Δ
,
∣
v
−
V
(
s
)
∣
)
\Delta \leftarrow max(\Delta,|v-V(s)|)
Δ←max(Δ,∣v−V(s)∣)
till
Δ
<
0
\Delta<0
Δ<0
- 策略改进
p
o
l
i
c
y
−
s
t
a
b
l
e
←
t
r
u
e
policy-stable \leftarrow true
policy−stable←true
对于每一个
s
∈
S
s \in S
s∈S:
o
l
d
−
a
c
t
i
o
n
old-action
old−action
←
π
(
s
)
\leftarrow \pi(s)
←π(s)
π
(
s
)
←
a
r
g
m
a
x
a
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
V
(
s
′
)
]
\pi(s) \leftarrow argmax_{a}\sum_{s',r}{p(s',r|s,a)[r+\gamma V(s')]}
π(s)←argmaxa∑s′,rp(s′,r∣s,a)[r+γV(s′)]
如果
o
l
d
−
a
c
t
i
o
n
≠
π
(
s
)
old-action \neq \pi(s)
old−action=π(s),那么
p
o
l
i
c
y
−
s
t
a
b
l
e
←
f
a
l
s
e
policy-stable \leftarrow false
policy−stable←false
如果
p
o
l
i
c
y
−
s
t
a
b
l
e
policy-stable
policy−stable为
t
r
u
e
true
true,那么停止并返回
V
≈
v
∗
V≈v*
V≈v∗以及
π
≈
π
∗
\pi ≈ \pi*
π≈π∗
三、编程实践
本文的小实验基于这里完成。自定义的环境基本上是把Gym官网的例子简单改了一下。大致描述就是:
在一个5*5的方格中,有一个蓝色的小球,其初始化位置在方格正中央,也就是[2,2]的位置上。在方格的四个角[0,0],[4,0],[0,4],[4,4]分别有4块奖励区域,分别对应着-1,-2,2,1。本案例使用类动态规划方法(近乎于蒙特卡洛方法)找到使小球能够以最短路径找到奖励最大的路径,我找到了一个其他大佬用冰湖(FrozenLake)环境写的一个动态规划,由于其创作时间为2020年,故将其代码进行稍事修改,放在文章末端。其图示如下:

(一)环境介绍
环境大致如上所述,需要补充的是小球每次只能上下左右移动一个方格,当小球的运动超出方格时,这里作取模运算,即如果小球走到如图所示的最右边[1,4],那么如果小球继续向右的话,它就会移动到同行最左侧的[1,0],其他方向同理。四角不同颜色的红色代表不同奖励值的区域。环境编辑代码如下:
(本文以个人学习记录为主,需要学习交流的大佬请在评论区留言~)
import gym
from gym import spaces
import pygame
import numpy as np
class GridWorldEnv(gym.Env):
metadata = {"render_modes":["human","rgb_array"],"render_fps":4}
def __init__(self,render_mode=None,size=5):
self.size=size #The size of the square grid
self.window_size=512 #The size of the PyGame window
#Obervations are dictionaries with the agent's and the target's loaction
#Each location is encoded as an element of {0,...,'size'}^2,i.e. MultiDiscrete([size,size])
self.observation_space=spaces.Dict(
{
"agent":spaces.Box(0,size-1,shape=(2,),dtype=int),
"target": spaces.Box(0, size - 1, shape=(2,), dtype=int)
}
)
#We have 4 actions,corresponding to "right,left,up,down"
self.action_space=spaces.Discrete(4)
self._action_to_direction={
0:np.array([1,0]),
1:np.array([0,1]),
2:np.array([-1,0]),
3:np.array([0,-1])
}
#We set the four rewars at the four corners for -1,-2,1,2
self.reward_range = (-2, 2)
self._reward = {
(0,0):-1,
(4,0):-2,
(0,4):2,
(4,4):1
}
assert render_mode is None or render_mode in self.metadata['render_modes']
self.render_mode=render_mode
"""
If human-rendering is used, `self.window` will be a reference
to the window that we draw to. `self.clock` will be a clock that is used
to ensure that the environment is rendered at the correct framerate in
human-mode. They will remain `None` until human-mode is used for the
first time.
"""
self.window=None
self.clock=None
#Used to save the steps process under the some policy
self.policy_steps=[]
#用来保存当前的动作序列
self.action_list=[]
def _get_obs(self):
return {"agent":self._agent_location,"target":self._target_location}
# def _get_info(self):
# return {"distance":np.linalg.norm(self._agent_location-self._target_location,ord=1)}
def _get_info(self):
return {"actions":self.action_list}
def reset(self,seed=None,options= None,location=None) :
#We need to following line to seed self.np_random
super(GridWorldEnv, self).reset(seed=seed)
#Choose the agent's location uniformly at random
# self._agent_location=self.np_random.integers(0,self.size,size=2,dtype=int)
# Agent initial location is always at [1,1]
self._agent_location=location if np.array(location).any() else np.array([(self.size-1)/2,(self.size-1)/2],dtype=int)
#We will sample the target's location randomly until it does not coincide with the agents's location
# self._target_location=self._agent_location
# while np.array_equal(self._agent_location,self._target_location):
# self._target_location=self.np_random.integers(0,self.size,size=2,dtype=int)
self.action_list=[]
self._target_location=[
np.array([0,0],dtype=int),
np.array([self.size-1,0],dtype=int),
np.array([0,self.size-1],dtype=int),
np.array([self.size-1,self.size-1],dtype=int)]
observation=self._get_obs()
info=self._get_info()
if self.render_mode=="human":
self._render_frame()
return observation,info
def step(self, action):
#Add the action to the action_list
self.action_list.append(action)
#Map the action to the direction we walk in
direction=self._action_to_direction[action]
#We use np.clip to make sure we don't leave the grid
# self._agent_location=np.clip(self._agent_location+direction,0,self.size-1)
# terminated=np.array_equal(self._agent_location,self._target_location)
self._agent_location=(self._agent_location+direction)%self.size
terminated=False
terminated_loaction=None
for target_location in self._target_location:
if np.array_equal(self._agent_location,target_location):
terminated=True
terminated_loaction=target_location
#reward well be decided by the terminated location
reward=self._reward[tuple(terminated_loaction)] if terminated else 0
observation=self._get_obs()
info=self._get_info()
if self.render_mode=="human":
self._render_frame()
return observation,reward,terminated,False,info
def render(self):
if self.render_mode=="rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode=="human":
pygame.init()
pygame.display.init()
self.window=pygame.display.set_mode((self.window_size,self.window_size))
if self.clock is None and self.render_mode=="human":
self.clock=pygame.time.Clock()
canvas=pygame.Surface((self.window_size,self.window_size))
canvas.fill((255,255,255))
pix_square_size=(self.window_size/self.size) #Size of single grid square in pixels
#First we draw the target
i=50
for target in self._target_location:
pygame.draw.rect(canvas,(i,0,0),pygame.Rect(pix_square_size*target,(pix_square_size,pix_square_size)))
i+=50
#Then draw the agent
pygame.draw.circle(canvas,(0,0,255),(self._agent_location+0.5)*pix_square_size,pix_square_size/3)
#Finally,add some gridlines
for x in range(self.size+1):
pygame.draw.line(
canvas,0,(0,pix_square_size*x),(self.window_size,pix_square_size*x),width=3
)
pygame.draw.line(
canvas,
0,(pix_square_size*x,0),(pix_square_size*x,self.window_size),width=3
)
if self.render_mode=="human":
#The following line copies our drawing from 'canvas' to the visible window
self.window.blit(canvas,canvas.get_rect())
pygame.event.pump()
pygame.display.update()
#We need to ensure that human-rendering occurs at the predefined framerate.
#The following line will automatically add a delay to keep the framerate stable
self.clock.tick(self.metadata["render_fps"])
else:#rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)),axes=(1,0,2)
)
def close(self):
if self.window is not None:
pygame.display.quit()
pygame.quit()
(二)策略编写
1. 初始化
先初始化一条策略,无需理会其最终奖励值大小以及走过的步数。在以下代码中,我将初始化策略所走过的轨迹用数组保存起来,即policy_steps。并返回轨迹和奖励reward
对于
s
∈
S
s \in S
s∈S,任意设定
V
(
s
)
∈
R
V(s) \in R
V(s)∈R以及
π
(
s
)
∈
A
(
s
)
\pi(s) \in A(s)
π(s)∈A(s)
import random
import gym
from gym.envs.registration import register
import numpy as np
register(id="GridWorld",
entry_point="grid_mdp_modi:GridWorldEnv",
max_episode_steps=200)
env=gym.make(id="GridWorld",render_mode="human")
env.reset()
def initial_policy():
policy_steps = []
policy_steps.append(np.array([2,2]))
while True:
# action=np.random.randint(0,4,1)
action = random.randint(0, 3)
observation,reward,terminated,truncated,info= env.step(action)
policy_steps.append(observation["agent"])
if terminated:
break
print("Initial policy finished.")
return policy_steps,reward
2.价值评估
我在第三节开头写道,由于环境限制,我采用的办法并非是纯动态规划的方法,其原因就在于动态规划中的价值评估是需要对每个状态的策略价值
V
(
s
)
V(s)
V(s)进行评估,即
V
(
s
)
←
∑
a
π
(
a
∣
s
)
∑
s
′
,
a
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
V
(
s
′
)
]
V(s) \leftarrow \sum_{a}{\pi(a|s)\sum_{s^{'},a}{p(s^{'},r|s,a)[r+\gamma V(s^{'})]}}
V(s)←∑aπ(a∣s)∑s′,ap(s′,r∣s,a)[r+γV(s′)],这就需要确定的环境,即上式中的
p
(
s
′
,
r
∣
s
,
a
)
{p(s^{'},r|s,a)}
p(s′,r∣s,a)和
π
(
a
∣
s
)
\pi(a|s)
π(a∣s)已知。(但是我用的这个gym官方的自定义环境它做不到这一点(悲,当然,也是我自己懒得去构造一个这样的理想环境。
所以,最终我的做法是用走到四个角落里所获得的奖励reward/小球运动的步数来评估这个价值value。代码如下:
def value_estimate(policy_steps,reward):
length = len(policy_steps)
# Let the reward/length=reward
reward = reward / float(length)
return reward
3.策略改进
策略改进也和上述算法
p
o
l
i
c
y
−
s
t
a
b
l
e
←
t
r
u
e
policy-stable \leftarrow true
policy−stable←true
对于每一个
s
∈
S
s \in S
s∈S:
o
l
d
−
a
c
t
i
o
n
old-action
old−action
←
π
(
s
)
\leftarrow \pi(s)
←π(s)
π
(
s
)
←
a
r
g
m
a
x
a
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
V
(
s
′
)
]
\pi(s) \leftarrow argmax_{a}\sum_{s',r}{p(s',r|s,a)[r+\gamma V(s')]}
π(s)←argmaxa∑s′,rp(s′,r∣s,a)[r+γV(s′)]
如果
o
l
d
−
a
c
t
i
o
n
≠
π
(
s
)
old-action \neq \pi(s)
old−action=π(s),那么
p
o
l
i
c
y
−
s
t
a
b
l
e
←
f
a
l
s
e
policy-stable \leftarrow false
policy−stable←false
如果
p
o
l
i
c
y
−
s
t
a
b
l
e
policy-stable
policy−stable为
t
r
u
e
true
true,那么停止并返回
V
≈
v
∗
V≈v*
V≈v∗以及
π
≈
π
∗
\pi ≈ \pi*
π≈π∗
有所不同。因为如果不走到最后的话,就无法确认某一动作价值的优劣性。因此,在这里我做的办法就是对于上一个策略
π
\pi
π所产生的轨迹中的每一步作评判,如果我改变了该步下一个动作,并且最终取得了更好的价值,那么我就认定新生成的策略比之前的策略要好,并用新策略覆盖旧策略。代码如下:
def policy_update( policy_steps,old_reward):
for step_num in range(len(policy_steps)):
action_temp = random.randint(0, 3) #随机生成一个动作
if len(policy_steps)>step_num+1:
update=policy_steps[step_num+1]
else:
break
while np.array_equal(update,policy_steps[step_num + 1]): # 如果该动作生成的位移和原策略的位置相同,那么就继续产生随机动作,直至产生不同的位置
env.reset(location=policy_steps[step_num])
action_temp = random.randint(0,3)
observation = env.step(action_temp)
update=observation[0]["agent"]
temp_policy_steps = []
temp_policy_steps.append(update)
while True:
action_temp=random.randint(0,3)
observation,reward,terminated,truncated,info = env.step(action_temp)
temp_policy_steps.append(observation["agent"])
if terminated:
temp_reward=reward
break
value = value_estimate(temp_policy_steps,temp_reward)
value = value * len(temp_policy_steps) / (step_num+1+len(temp_policy_steps))
if value > old_reward:
new_policy_steps = policy_steps[:step_num+1]
new_policy_steps.extend(temp_policy_steps)
return new_policy_steps,value
# break
# if policy_steps!=new_policy_steps:
# return new_policy_steps, value
print("Can't find the better policy")
return policy_steps,old_reward
最后就是主函数,首先随机生成一个策略,随后进行策略迭代,只有当价值达到最大时(毕竟就一5*5的方格,肉眼可以计算出最大价值=0.4),停止更新.
initial_policy,initial_reward=initial_policy()
initial_reward=value_estimate(initial_policy,initial_reward)
print("The initial reward has been produced which is {}".format(initial_reward))
print("The initial policy is {}".format(initial_policy))
old_reward=initial_reward
policy=initial_policy
episode_num=0
while True:
policy,new_reward=policy_update(policy,old_reward)
print("This episode the reward is {}".format(new_reward))
print("This episode the policy steps is {}".format(len(policy)))
print("The policy steps is {}".format(policy))
episode_num+=1
print("The episode number is {}".format(episode_num))
if abs(new_reward-old_reward)<old_reward/10 and new_reward>=0.4:
print("The policy has converged to the condition")
break
old_reward=new_reward
由于每一步的动作都是随机生成的,因此,每次运行程序的结果都会不一样,但最后都会收敛到最优路径。截取某次运行的结果。
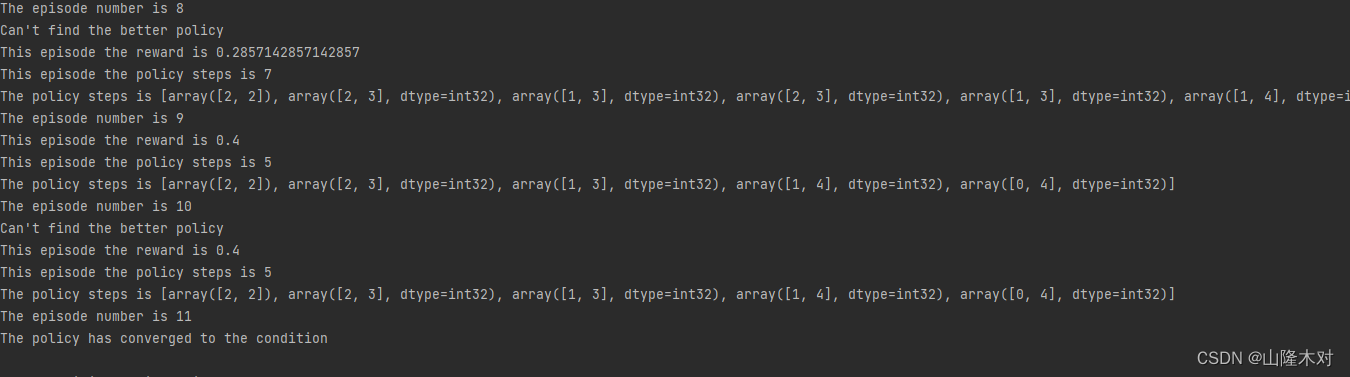
4.其他大佬的冰湖环境动态规划
运行前注意,你的gym里要有冰湖环境(FrozenLake8x8-v1),没有的记得pip一下。
在这里插入图片描述
import gym
import time
import numpy as np
def value_iteration(env, threshold=1e-4, gamma=0.9):
env.reset()
start = time.time()
# 初始化策略
policy = np.zeros(64, dtype=int) # 默认为float类型
# 初始化value表 (初始化0)
value_table = np.zeros(64)
new_value_table = np.zeros(64)
delta = 2 * threshold
while delta > threshold:
for state in range(64):
action_value = np.zeros(4)
for action in range(4):
for prob, next_state, reward, done in env.P[state][action]:
action_value[action] += prob * (reward + gamma*value_table[next_state])
# 1.利用max操作更新V(s),区别与Policy Iteration
new_value_table[state] = max(action_value)
# 2.Policy Improvement
policy[state] = np.argmax(action_value)
delta = sum( np.fabs(new_value_table - value_table) )
value_table = np.copy(new_value_table) # 注:需用copy拷贝副本,否则两个变量指向同一位置,则赋值时同时改变
print('===== Value Iteration ======\nTime Consumption: {}s\nIteration: {} steps\nOptimal Policy(gamma={}): {}'.format(time.time()-start, 1, gamma, policy))
return value_table, policy
def play_game(env, policy, episodes=5, timesteps=150):
for episode in range(episodes):
env.reset()
state=0
for t in range(timesteps):
action = policy[state]
state, reward, done, truncated,info = env.step(action)
if done:
print("===== Episode {} finished ====== \n[Reward]: {} [Iteration]: {} steps".format(episode+1, reward, t+1))
env.render()
break
env = gym.make('FrozenLake8x8-v1',render_mode="human")
# 价值迭代
value_table, policy = value_iteration(env, gamma=0.9)
# 使用迭代计算得到的策略打游戏
play_game(env, policy, episodes=3)
env.close()