利用搜索关键字爬取今日头条新闻评论信息案例
爬虫4步骤:
1.分析网页
2.对网页发送请求,获取响应
3.提取解析数据
4.保存数据
本案例所用到的模块
import requests
import time
import csv
案例网址:https://www.toutiao.com/
一、分析网页
如果我们想通过关键字来搜索爬取新闻的评论信息,就需要找到它们的接口,但是这个接口应该如何找呢,其实也不难找,我们在首页中的搜索栏中,输入想搜索的关键字,点击搜索:
 然后网址会给我们跳转到一个搜索出来该关键字的新闻页面:
然后网址会给我们跳转到一个搜索出来该关键字的新闻页面:
 找到这个页面,我们就可以按F12进入到开发者模式。经过分析,因为是动态加载页面,我们很简单的就可以找到包含新闻数据的网址接口:
找到这个页面,我们就可以按F12进入到开发者模式。经过分析,因为是动态加载页面,我们很简单的就可以找到包含新闻数据的网址接口:
 有了网址接口,就需要分析这个网址的信息,可以看出这个网址非常的长,里面有很多必须要加载的参数,该参数也就是我们常说的params参数了:
有了网址接口,就需要分析这个网址的信息,可以看出这个网址非常的长,里面有很多必须要加载的参数,该参数也就是我们常说的params参数了:
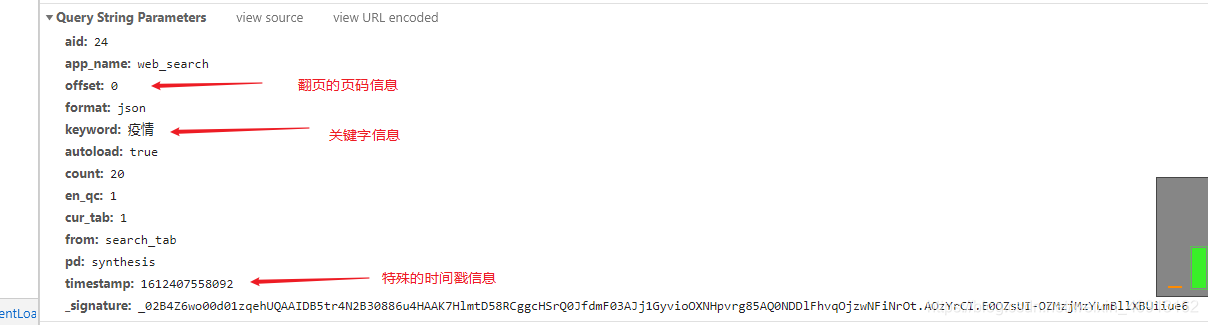 图中标识的这3个参数信息就是我们必须要用到的信息,offset是页码的信息,用它我们可以实现翻页的爬取数据,keyword是关键字信息,这个一般都懂的,timestamp就是一个时间戳,只不过这个时间戳做了些变化,我在之前的博文中也讲到过,这里就不在赘述了,感兴趣的可以看我之前的那篇博文:Python爬取基金数据案例
图中标识的这3个参数信息就是我们必须要用到的信息,offset是页码的信息,用它我们可以实现翻页的爬取数据,keyword是关键字信息,这个一般都懂的,timestamp就是一个时间戳,只不过这个时间戳做了些变化,我在之前的博文中也讲到过,这里就不在赘述了,感兴趣的可以看我之前的那篇博文:Python爬取基金数据案例
现在我们看看这个接口网址里面的信息是什么样的,如图:
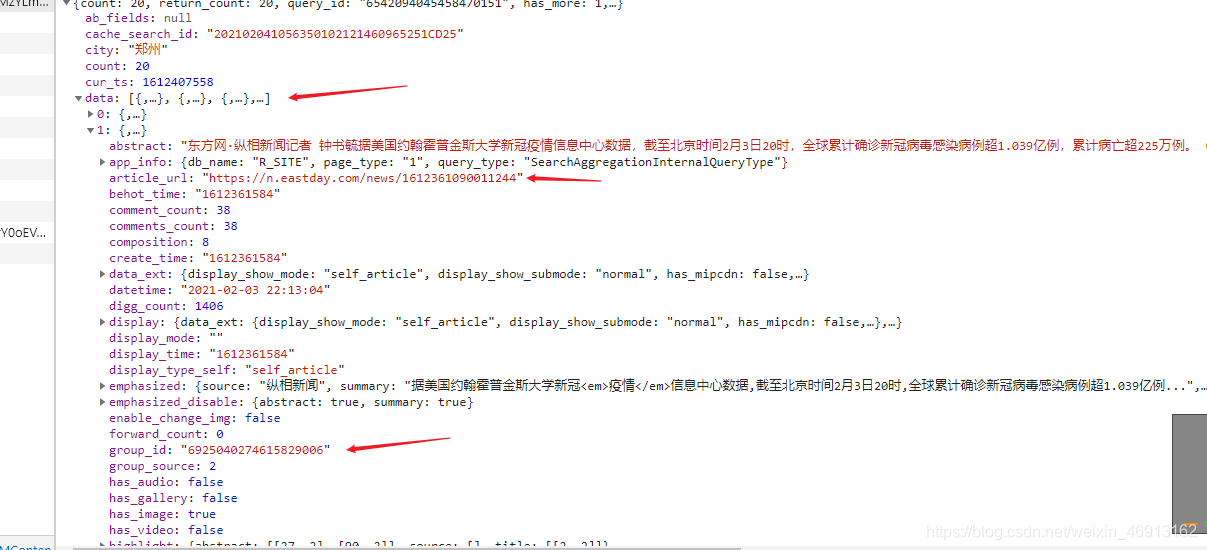
可以看出,这个接口里面的信息就是一个json数据格式的信息,所有新闻数据的信息都在data这个列表中,每一个列表里面就是一条新闻数据信息,我们需要提取出来每条信息数据的链接地址和该新闻所属的ID信息,这个ID信息很有用,在提提取评论信息的时候需要用到:

上图这个是包含评论信息的params参数,可以看到该参数里面有两个关键参数,group_id和item_id,这个group_id正好对应上面那个接口信息里面的group_id,至于item_id那就是和group_id一样,到这里我们能就算分析完成了。现在说一下大体思路,通过搜索我们获取到所有包含该新闻数据的接口网址,然后对该网址发送请求,提取需要的数据,然后,在把需要的数据构建给包含每条信息数据评论的接口,对这个接口再次发送请求,最后提取出每条新闻数据的信息并保存。
二、构建params参数,并发送请求,获取响应数据
代码如下:
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.page),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
三、提取需要的数据
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {}
# 提取新闻的url
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
四、再次构建params参数,并再次请求提取出的URL
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2
五、提取评论数据
def get_pinglun_data(self, resp):
"""
提取需要的评论信息的方法
:param resp:
:return:
"""
json_str = resp.json()
for json in json_str.get('data'):
create_time = time.localtime(json.get('comment').get('create_time'))
Time = time.strftime("%Y-%m-%d %H:%M:%S", create_time)
yield {
# 提取评论者id
'user_id': json.get('comment').get('user_id'),
# 提取评论者名字
'user_name': json.get('comment').get('user_name'),
# 提取评论内容
'pl_content': json.get('comment').get('text'),
# 提取评论时间
'pl_time': Time
}
完成后效果:

六、完整代码:
# 导入需要的模块
import requests
import time
import csv
class JrttSpider:
"""爬取今日头条新闻评论"""
def __init__(self, search_name, page):
self.API_URL = 'https://www.toutiao.com/api/search/content/'
self.PINGLUN_URL = 'https://www.toutiao.com/article/v2/tab_comments/'
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
self.search_name = search_name
self.PAGE = page
self.TIMESTRF = int(time.time()) * 1000
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.PAGE),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {}
# 提取新闻的链接
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2
def get_pinglun_data(self, resp):
"""
提取需要的评论信息的方法
:param resp:
:return:
"""
json_str = resp.json()
for json in json_str.get('data'):
create_time = time.localtime(json.get('comment').get('create_time'))
Time = time.strftime("%Y-%m-%d %H:%M:%S", create_time)
yield {
# 提取评论者id
'user_id': json.get('comment').get('user_id'),
# 提取评论者名字
'user_name': json.get('comment').get('user_name'),
# 提取评论内容
'pl_content': json.get('comment').get('text'),
# 提取评论时间
'pl_time': Time
}
def run(self):
"""
# 实现主要逻辑思路
:return:
"""
with open('./news_pl.csv', 'a', encoding='utf-8-sig', newline="") as csvfile:
fieldnames = ['news_title', 'user_id', 'user_name', 'pl_content', "pl_time"]
write_dict = csv.DictWriter(csvfile, fieldnames=fieldnames)
write_dict.writeheader()
# 1.构建params数据
params = self.paramsData()
# 2.发送请求,获取响应
response = self.parse_url(self.API_URL, params)
# 3.提取需要的数据
for json_str in response.json().get('data'):
# 4.把提取出的数据放入到字典里面
news_dict = self.get_news_data(json_str)
# 5.再次构建params数据
params2 = self.paramsData2(news_dict)
# 6.再次发送请求,获取响应
resp = self.parse_url(self.PINGLUN_URL, params2)
# 7.提取需要的数据
pinglun_list = self.get_pinglun_data(resp)
news_pl_dict = {'news_title': news_dict.get('news_title')}
for pinglun_dict in pinglun_list:
news_pl_dict.update(pinglun_dict)
print(news_pl_dict)
# 8.保存数据
write_dict.writerow(news_pl_dict)
if __name__ == '__main__':
serch_name = input('请输入你需要搜索的新闻关键字:')
for page in range(0, 201, 20):
jrtt_data = JrttSpider(serch_name, page)
jrtt_data.run()