使用可分离卷积LSTM进行暴力检测的高效两流网络
本文亮点为作者对视频进行了预处理,1.取帧差作为输入;2.进行背景抑制,突出运动对象。在模型方面,作者选择了一种轻量级的CNN进行特征提取(MobileNet)。模型分为双流,一个流的输入为帧差,另一个流的输入为背景抑制后的结果,最后两个流都放入MobileNet进行特征提取,之后将输出放入Seperable Convolutional LSTM中,提取时空特征,之后串联两个流的输出。
作者提出了一种有效的双流深度学习架构,可分离卷积LSTM(SepConvLSTM)和与训练的MobileNet,其中一个流将背景抑制作为输入,而另一个流则处理相邻帧的差异。作者尝试了三种融合方法来融合双流的输出。作者提出的CNN-LSTM网络可以产生时空特征,同时需要的参数更少。
MobileNet
MobileNet是一种轻量级的2D CNN,它使用深度可分离的卷积和明智的设计选择来开发针对移动和嵌入式视觉应用的快速而有效的模型。
我们还采用了可分离卷积LSTM(SepConvLSTM),该结构是通过将LSTM门中的卷积运算替换为深度可分离卷积来构造的。
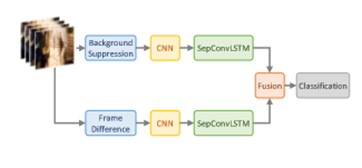
拟议中的管道有两个流,分别由CNN和SepConvLSTM模块组成。 背景抑制和帧差异是预处理模块。 将两个流的输出融合在一起,以产生鲁棒的时空特征。
Seperable Convolutional LSTM
深度可分离卷积是对标准卷积运算的一种有效修改,其中每个输入通道分别与一个滤波器进行卷积,以产生具有相同数量通道的输出。 然后,应用1×1卷积来重组通道中的信息。 这导致计算量减少了。用深度可分离的卷积替换了ConvLSTM单元中的卷积运算,这大大减少了参数计数,并使单元更小巧轻便。
Pre-processin
1.作者将相邻的帧差作为输入,增强了运动信息的捕获能力,帧差可以替代计算量大的光流。
2.作者首先计算所有帧的平均值,平均帧主要包含背景信息,通过抑制背景信息从每帧中减去该平均值,从而加重了该帧中的移动对象。
网络体系结构

从图中可以看出双流通道,一个通道输入的是帧差的信息,一个通道输入原始帧,并进行了背景抑制。每个流都包含MobileNet模块(蓝白块),该模块从输入的每个时间步生产空间特征,这些功能将传递到每个流中的SepConvLSTM单元,以产生时空编码。每个流的输出都使用Fusion层(灰色方块)进行融合,然后传递到分类器网络。两种流的输出特征相结合,产生了强大的时空特征图,能够区分暴力和非暴力视频。
使用在ImageNet数据集上预训练的MobileNetV2作为CNN来提取空间特征,使用SepConvLSTM从CNN的输出特征图中生产局部时空特征。
融合策略
SepConvLSTM-M:在该模型中,帧流的输出通过LeakyRelu激活层传递。 另一方面,来自帧差异流的特征图将通过Sigmoid激活层。 然后,我们执行逐元素乘法以生成最终的输出特征图。
SepConvLSTM-C:在此变体中,简单地串联了两个流的两个输出特征,并将其传递到分类层。
SepConvLSTM-A:在融合层的最后一个变体中,将两个流的输出特征图逐元素添加以生成最终的视频表示形式。
实验
作者在实验中发现,SepConvLSTM-C变体表现最好。并且通过消融实验证明作者提出的SepConvLSTM模型性能比ConvLSTM模型更好。
