一、python库camelot安装及使用中的一些注意事项
1)camelot方法有两种解析模式:流解析(stream)、格子解析(lattice),其中格子解析能够保留表格完整的样式,对于复杂表格来说要优于流解析模式。同时,camelot方法默认格子解析(lattice),而采用这种解析方式,需要安装ghostscript。因此,仅通过pip命令安装的camelot,代码运行时通常会报错。需要下载ghostscript.exe并安装。安装后,经测试,并不需要在代码中import ghostscript。
2)camelot输出格式如果选择csv格式,可能存在中文乱码问题,需要用文本编辑器将导出的csv文件编码改为ansi格式。
如果想直接保存为excel格式,需要xlwt模块支持,pip安装xlwt后tables.export(‘文件名.xls’,f = ‘excel’)即可输出为excel格式。
3)后来在另外一台电脑上安装camelot库时出现了一个奇葩的问题,程序运行报错。反复检查才发现原因。首先是在这台电脑上,我是按照印象输入pip install camelot,也安装成功。但代码运行错误。经查阅,正确命令(或者说版本)是pip install camelot-py[cv]。
所以我先uninstall前面安装的camelot,又重新按照正确的命令安装camelot-py[cv],但代码运行时又提示import xlwt有问题,在python库中检查了下,xlwt文件是正常的,找了半天没找到原因。后来单独卸载xlwt,然后重新pip安装xlwt,发现xlwt的版本号由0.7变为1.3,然后一切就正常了。估计是之前错误安装了camelot的版本,导致顺带安装的xlwt版本过低,无法兼容python3.6.5。
4)camelot开始时一切正常,但处理一个pdf文件时突然报错:pdfminer.psparser.SyntaxError: Invalid dictionary construct: [/‘Type’, /‘Font’, /‘Subtype’, /‘Type0’, /‘BaseFont’, /b"b’", /“ABCDEE+\xcb\xce\xcc\xe5’”, /‘Encoding’, /‘Identity-H’, /‘DescendantFonts’, PDFObjRef:11, /‘ToUnicode’, PDFObjRef:19]
经百度,找到解决方案,修改了pandas和PyPDF2模块的三处源码,恢复正常。具体修改内容见python爬虫处理在线预览的pdf文档https://link.csdn.net/?target=https%3A%2F%2Fwww.cnblogs.com%2FEeyhan%2Farchive%2F2019%2F12%2F30%2F12111371.html
二 、 python库Camelot从pdf抽取表格数据
原文链接:https://blog.csdn.net/xc_zhou/article/details/99242995
Camelot: 一个友好的PDF表格数据抽取工具
一个python命令行工具,使任何人都能很轻松的从PDF文件中抽取表格数据。
安装 Camelot
安装非常简单! 在安装相关的依赖后,可以直接使用pip安装。
$ pip install camelot-py
怎样使用Camelot
使用Camelot从PDF文档提取数据非常简单
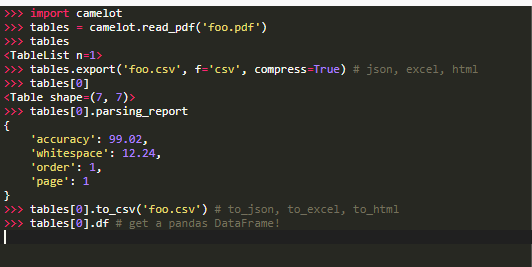
为什么使用Camelot
- Camelot允许你通过调整设置项来精确控制数据的提取过程
- 可以根据空白和精度指标来判断坏的表格,并丢弃,而不必手动检查
- 每一个表格数据是一个panda的dataframe,从而可以很方便的集成到ETL和数据分析工作流中
- 可以把数据导出为各种不同的格式比如 CSV、JSON、EXCEL、HTML
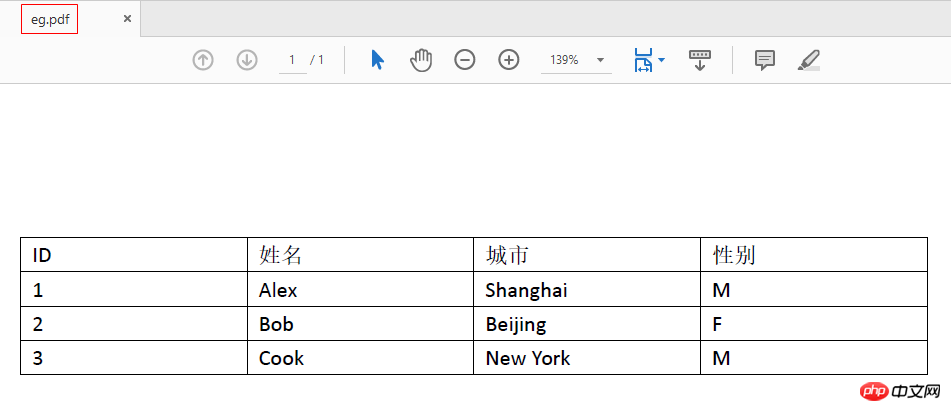
首先,让我们看一个简单的例子:eg.pdf,整个文件只有一页,这一页中只有一个表格,如下:
使用以下Python代码就可以提取该PDF文件中的表格:
import camelot
从PDF文件中提取表格
tables = camelot.read_pdf(‘E://eg.pdf’, pages=‘1’, flavor=‘stream’)
表格信息
print(tables)
print(tables[0])
表格数据
print(tables[0].data)
输出结果为:
<TableList n=1>
<Table shape=(4, 4)>
[['ID', '姓名', '城市', '性别'], ['1', 'Alex', 'Shanghai', 'M'], ['2', 'Bob', 'Beijing', 'F'], ['3', 'Cook', 'New York', 'M']]
分析代码,camelot.read_pdf()为camelot的从表格中提取数据的函数,输入的参数为PDF文件的路径,页码(pages)和表格解析方法(有stream和lattice两个方法)。对于表格解析方法,默认的方法为lattice,而stream方法默认会把整个PDF页面当做一个表格来解析,如果需要指定解析页面中的区域,可以使用table_area这个参数。
camelot模块的便捷之处还在于它提供了将提取后的表格数据直接转化为pandas,csv,JSON,html的函数,如tables[0].df,tables[0].to_csv()函数等。我们以输出csv文件为例:
import camelot
从PDF文件中提取表格
tables = camelot.read_pdf(‘E://eg.pdf’, pages=‘1’, flavor=‘stream’)
将表格数据转化为csv文件
tables[0].to_csv(‘E://eg.csv’)
得到的csv文件如下:
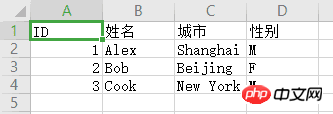
例2
在例2中,我们将提取PDF页面中的某一区域的表格的数据。PDF文件的页面(部分)如下:

为了提取整个页面中唯一的表格,我们需要定位表格所在的位置。PDF文件的坐标系统与图片不一样,它以左下角的顶点为原点,向右为x轴,向上为y轴,可以通过以下Python代码输出整个页面的文字的坐标情况:
import camelot
从PDF中提取表格
tables = camelot.read_pdf(‘G://Statistics-Fundamentals-Succinctly.pdf’, pages=‘53’,
flavor=‘stream’)
绘制PDF文档的坐标,定位表格所在的位置
tables[0].plot(‘text’)
输出结果为:
UserWarning: No tables found on page-53 [stream.py:292]
整个代码没有找到表格,这是因为stream方法默认将整个PDF页面当作表格,因此就没有找到表格。但是绘制的页面坐标的图像如下:
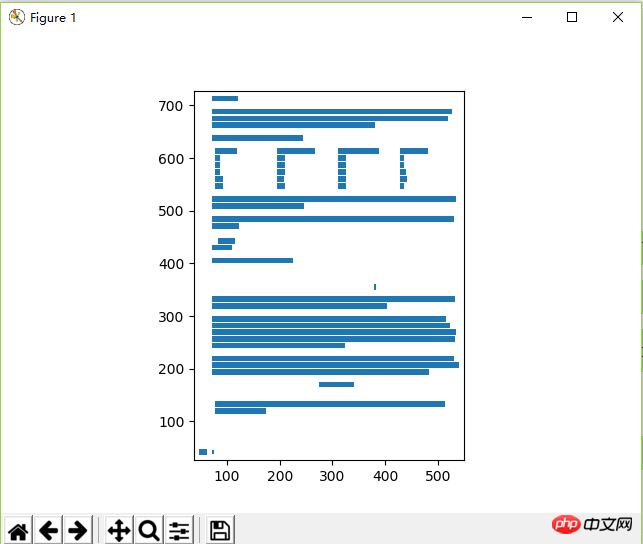
仔细对比之前的PDF页面,我们不难发现,表格对应的区域的左上角坐标为(50,620),右下角的坐标为(500,540)。我们在read_pdf()函数中加入table_area参数,完整的Python代码如下:
import camelot
识别指定区域中的表格数据
tables = camelot.read_pdf(‘G://Statistics-Fundamentals-Succinctly.pdf’, pages=‘53’,
flavor=‘stream’, table_area=[‘50,620,500,540’])
绘制PDF文档的坐标,定位表格所在的位置
table_df = tables[0].df
print(type(table_df))
print(table_df.head(n=6))
输出的结果为:
<class 'pandas.core.frame.DataFrame'>
0 1 2 3
0 Student Pre-test score Post-test score Difference
1 1 70 73 3
2 2 64 65 1
3 3 69 63 -6
4 … … … …
5 34 82 88 6
总结
在具体识别PDF页面中的表格时,除了指定区域这个参数,还有上下标、单元格合并等参数,详细地使用方法可参考camelot官方文档网址:https://camelot-py.readthedocs.io/en/master/
参考:https://www.php.cn/python-tutorials-412223.html
https://mp.weixin.qq.com/s?__biz=MjM5NzU0MzU0Nw==&mid=2651380263&idx=1&sn=514485e8c4fe820834bacbcccfbb4ae9&chksm=bd2411338a539825977b2ab6d6e7a1fd86dfe0c85ba54a50d1472c309f7b1efdc164d1da4f96&mpshare=1&scene=23&srcid=0520POo6Bt0M0FUTbhnwNptJ#rd