
来源:集智俱乐部
作者:Fernando E. Rosas, Pedro A. M. Mediano, Henrik J. Jensen等
译者:潘佳栋
审校:梁金
编辑:邓一雪
导语
大量个体聚集起来,常常涌现出新的复杂结构。鸟儿聚集起来形成兼具灵活性与秩序的鸟群,大量神经元聚集产生强大的心智。然而,要从数学上严格地量化涌现却是一个巨大挑战。2020年12月,发表在 PLOS Computational Biology 上的论文《量化涌现:信息论方法识别多变量数据中的因果涌现》,提出了多变量系统中因果涌现的一个形式理论,该理论为在大型系统中进行有效计算提供了实用标准。集智对这篇论文进行了全文翻译。
因果涌现理论的提出者、塔夫茨大学助理教授 Erik Hoel将做客集智读书会:用信息度量因果。该活动为集智俱乐部「因果涌现」系列读书会的附加活动,拟于美国东部时间1月25日(8PM~9PM),北京时间1月26日(9AM~10AM)线上开展。欢迎对本话题感兴趣的朋友点击文末“阅读原文”报名直播!
研究领域:因果涌现,信息论,鸟群模型,生命游戏,do-演算

论文题目:
Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data
论文地址:
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1008289
目录
摘要
作者总结
1、引入
2、基本直觉
3、因果涌现的形式理论
4、度量因果涌现
5、案例研究
6、讨论
7、结论
摘要
涌现这个广泛的概念在各种最具挑战性的开放性科学问题中发挥着作用。然而,关于什么是涌现现象的定量理论却很少被提出。本文介绍了多变量系统中因果涌现的一个形式理论,研究系统各部分的动力学与人们关注的宏观特征之间的关系。我们的理论提供了一个自上而下因果(downward causation)的定量定义,并引入了涌现行为的补充形式——我们称之为因果解耦(causal decoupling)。此外,该理论允许在大型系统中进行有效计算的实用标准,使我们的框架适用于一系列实际感兴趣的情况。我们用一些案例研究说明这一发现,包括康威的生命游戏、雷诺的鸟群模型和脑皮层电图测量的神经活动。
作者总结
许多科学领域表现出的现象似乎“超过其各部分的总和”;例如,鸟群似乎不只是鸟的集合,意识似乎不只是神经元之间的电脉冲。但是,对于一个物理系统来说,涌现具体是什么意思?关于这个问题的文献中包含各种彼此矛盾的方法,其中许多都不能提供定量、可证伪的观点。拥有一个严格、定量的涌现理论,可以帮助我们发现使鸟群超越单只鸟的确切条件,并更好地理解意识如何从大脑中涌现。这里,我们提供的正是这样一个理论:关于什么构成因果涌现的一个形式理论,如何度量它,以及存在哪些不同“类型”的涌现。为了做到这一点,我们利用信息动力学——研究信息如何流经动力学系统并被其修改——的最新发展。作为这个框架的一部分,我们提供了一个因果涌现的数学定义,以及用于分析经验数据的实用公式。利用这些,我们能够确认在标志性的康威的生命游戏中,在特定的鸟群模式中,以及在猴子大脑神经活动表征中的涌现。
1. 简介
虽然我们对物理世界的大多数表述都是分层次的,但是对于这个层次中共存的“层”如何相互作用,仍然没有达成共识。一方面,还原论(reductionism)声称,所有层次总是可以根据对最低尺度的充分了解来解释,因此——故意举一个极端的例子——足够精确的基本粒子理论应该能够预测像共产主义这样的社会现象的存在。另一方面,涌现论(emergentism)认为,层级之间可以有自主性,也就是说,宏观层面的一些现象或许只能用其他宏观现象解释。虽然涌现论似乎更符合我们的直觉,但我们并不完全清楚,如何在我们受还原论原则主导的现代科学世界观中,提出严格的涌现理论。
涌现现象通常被描述为强或弱[1]。强涌现(strong emergence)对应于具有不可还原因果效应的随附特征这一略微矛盾的情况[2];即特征完全由微观水平决定,但可以施加不完全由微观因素解释的因果效应(文献中最常论证的强涌现情况是意识经验相对于其相应物理基础的情况[3, 4])。强涌现既是一个奇迹,也是一个长期令人头疼的哲学问题,它被描述为 "像魔术一样令人不舒服",同时被指责在逻辑上不一致[2],并得到不合法的形而上学的支持[5]。弱涌现(weak emergence)被提出来作为强涌现的一个更温和的替代方案,即宏观特征在实践中具有不可还原的因果效应,但在原则上却没有。弱涌现的一个流行表述由 Bedau 提出[5],它对应的特征由微观层面的元素以如此复杂的方式产生,以至于不能通过解析方法得出,而只能通过详尽的模拟。虽然这种表述通常被科学界所接受,但它并不适合于解决在部分-整体关系为主要研究对象的情况下关于涌现的分体论(mereological)问题。
在建立对强涌现的深入理解时,部分困难在于缺乏简单而清晰的分析模型,以指导社区中的讨论并产生成熟的理论。人们已经致力于引入对弱涌现的量化度量[6],这使得可以用细粒度的数据驱动方法替代传统的全或无分类。在这种情况下,一个有吸引力的替代方案来自于文献[7]中介绍、之后在文献 [8, 9] 中得到发展的关于因果涌现的工作,它表明宏观可观测量有时可以比微观变量表现出更多的因果效应(在 Pearl 的do-演算 [10] 框架内理解)。然而,这个框架依赖于在实践中很难满足的强假设,这严重阻碍了它的适用性(这一点将在它与其他定量涌现理论的关系部分进一步阐述)。
受参考文献[6, 7]的启发,在此我们引入一个实用且哲学上无缪误的框架来研究多变量数据中的因果涌现。在此前工作[11]的基础上,我们从一个实验者的角度出发,他对感兴趣的底层现象没有预先的知识,但有所有相关变量的充足数据,可以对现象进行准确的统计描述。在这种情况下,我们提出了一个因果涌现的形式定义,它不是如文献[7]中那样依赖于粗粒度的函数,而是基于多变量系统中的信息流规律来解决强涌现的“悖论”特性。
这项工作的主要贡献是对自上而下因果进行了严格的定量定义,并引入因果解耦的新概念作为因果涌现的补充方式。另一个贡献是扩大因果涌现分析的适用范围,以包括观察性数据的情况,在这种情况下,因果应该从 Granger 所说的预测能力的意义上理解[12]。此外,我们的框架产生了实用的标准,可以有效地应用于大型系统,绕过严重限制先前方法的限制性估计问题。
本文的其余部分结构如下。首先,“基本直觉”部分讨论涌现的最小示例。然后,"因果涌现的形式理论"部分介绍理论的核心,"测量涌现"部分讨论从实验数据中量化涌现的实际方法。我们的框架在一些案例研究中得到了说明,这在“案例研究”部分。最后,在“讨论”一节中,我们讨论了我们的发现所带来的一些影响。
2. 基本直觉
为了给我们的直觉打下基础,让我们首先介绍一些最小示例,这些例子体现了因果涌现行为的几个关键概念。在本节中,我们考虑由n个部分组成的系统,由二进制向量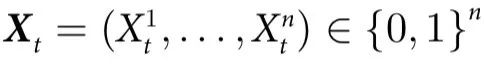 描述,它们按照转移概率
描述,它们按照转移概率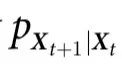 经历马尔可夫过程的随机动力学。为了简单起见,我们假设在时间t,系统处于一个完全随机的位形(即
经历马尔可夫过程的随机动力学。为了简单起见,我们假设在时间t,系统处于一个完全随机的位形(即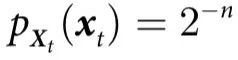 )。从这里开始,我们考虑三种演化规则。
)。从这里开始,我们考虑三种演化规则。
例1:考虑一个时间演化,其中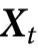 的奇偶性以概率
的奇偶性以概率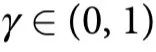 保存。数学上,
保存。数学上,
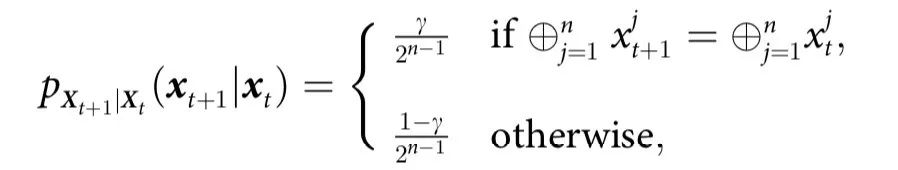
对所有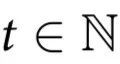 ,当
,当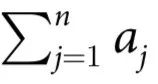 为偶数时,
为偶数时,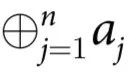 为1;当
为1;当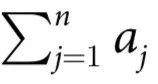 为奇数时,
为奇数时, 为0。简单地说:
为0。简单地说: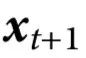 为从所有与
为从所有与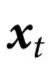 奇偶性相同的字符串集合中随机抽取的样本的概率为 γ,来自与奇偶性相反的字符串的样本的概率为 1-γ。
奇偶性相同的字符串集合中随机抽取的样本的概率为 γ,来自与奇偶性相反的字符串的样本的概率为 1-γ。
这个演化规则有许多有趣的性质。首先,该系统有一个非平庸的因果结构,因为未来状态的一些属性(其奇偶性)可以从过去状态中预测出来。然而,这种结构只在集体层面上是明显的,因为没有任何一个变量对其自身或任何其他变量的演化有预测能力(见图1)。此外,即使是系统的完整过去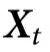 对任何单个个体的未来
对任何单个个体的未来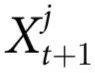 也没有预测能力。这种情况显示了一种极端的因果的出现,我们称之为“因果解耦”。在这种情况下,奇偶性预测自己的演化,但没有一个元素(或元素的子集)可以预测任何其他元素的演化。
也没有预测能力。这种情况显示了一种极端的因果的出现,我们称之为“因果解耦”。在这种情况下,奇偶性预测自己的演化,但没有一个元素(或元素的子集)可以预测任何其他元素的演化。
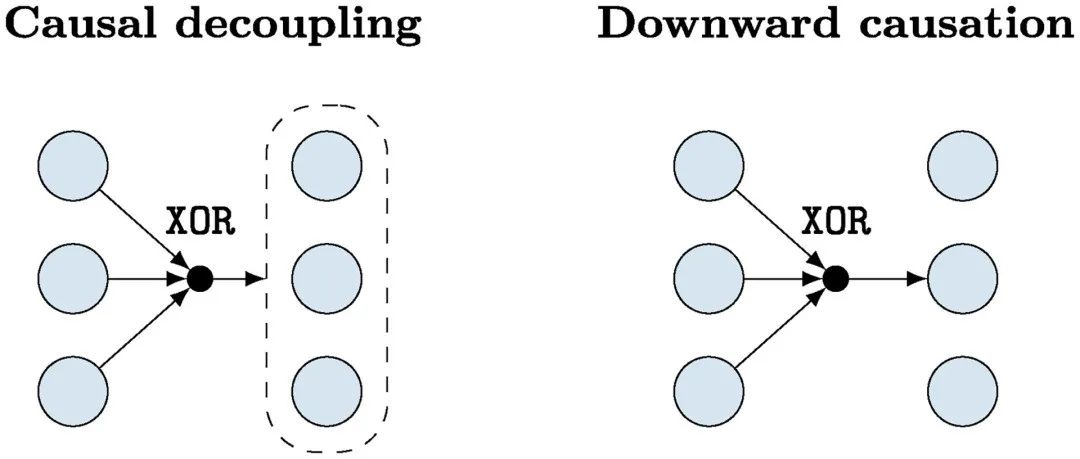
图1. 因果涌现的动力学演化的最小示例。在左图(例1)中,系统的奇偶性倾向于被保留,而底层元素之间没有发生相互作用,这是一个因果解耦的例子。在右图(例2)中,系统的奇偶性只决定一个元素,对应于自上而下因果。
例2:现在考虑一个系统, 的奇偶性决定了
的奇偶性决定了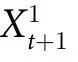 (即
(即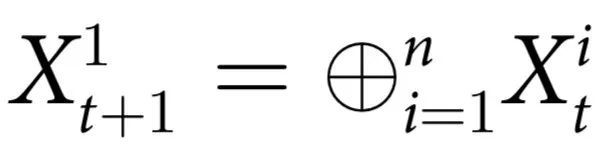 ),而
),而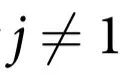 时的
时的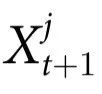 是一个独立于
是一个独立于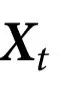 的随机抛硬币情形(见图1)。在这种情况下,
的随机抛硬币情形(见图1)。在这种情况下,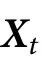 完全准确地预测
完全准确地预测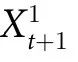 ,同时可以验证,对于所有的
,同时可以验证,对于所有的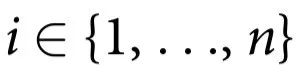 ,
,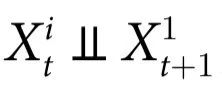 。因此,在这个演化规则下,整个系统对一个特定的元素具有因果效应,尽管这个效应不能归因于任何单独的元素(相关讨论见文献[13])。这是一个自上而下因果的最小例子。
。因此,在这个演化规则下,整个系统对一个特定的元素具有因果效应,尽管这个效应不能归因于任何单独的元素(相关讨论见文献[13])。这是一个自上而下因果的最小例子。
例3:现在让我们来研究一个包含例1和例2两种机制的演化规则。具体来说,考虑:
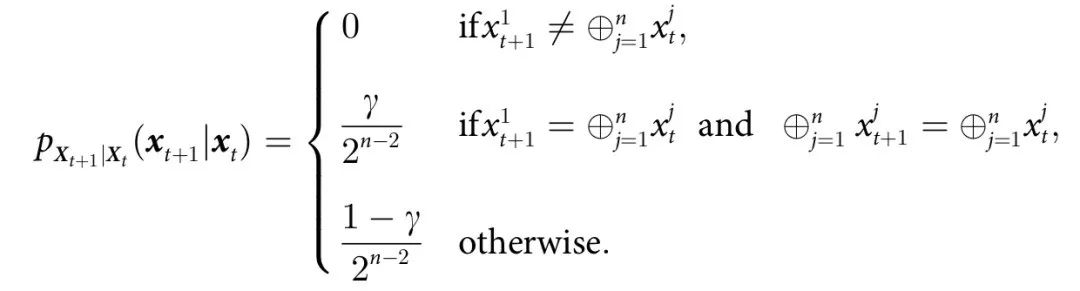
与例1一样, 的奇偶性被转移到
的奇偶性被转移到 的概率为γ;除此之外,可以保证
的概率为γ;除此之外,可以保证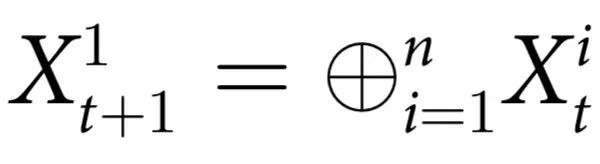 。因此,在这种情况下,不仅有一个无法从部分解释的宏观效应,同时还有另一个从整体到其中一个部分的效应。重要的是,这两种效应是独立存在的。
。因此,在这种情况下,不仅有一个无法从部分解释的宏观效应,同时还有另一个从整体到其中一个部分的效应。重要的是,这两种效应是独立存在的。
以上是不能从基本组成部分之间的相互作用出发,追踪到整体动力学演化规律的最小示例。例1显示了一个集体属性如何在不与底层元素相互作用的情况下传播;例2显示了一个集体属性如何影响特定部分的演化;例3显示了这两种现象如何在同一个系统中发生。所有这些问题都由下一节中提出的理论来形式化描述。
3. 因果涌现的形式理论
本节介绍了我们的因果涌现理论的主要内容。为了明确思路,我们设想一个科学家测量一个由n个部分组成的系统。假设科学家在一段时间内定时测量系统,而这些测量的结果用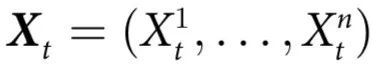 表示,其中
表示,其中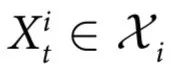 对应于第i部分在时间
对应于第i部分在时间 的状态,
的状态,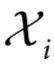 为相空间。当提到一个部分的集合时,我们使用的符号是
为相空间。当提到一个部分的集合时,我们使用的符号是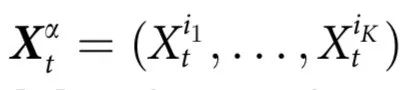 ,其中
,其中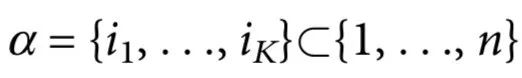 。我们还使用了简短的符号
。我们还使用了简短的符号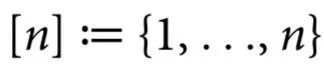 。
。
3.1 随附性
我们的分析考虑了系统演化的两个时间点,分别表示为 t 和 t',其中 t<t'。相应的动力学编码为转移概率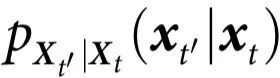 。我们考虑通过条件概率
。我们考虑通过条件概率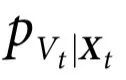 产生的特征
产生的特征 ,这些特征与底层系统具有随附性(supervenience);也就是说,如果系统在 t 时间的完整状态可以完全准确地知道,转移概率对 t'>t 时间的未来状态不提供任何预测能力。我们在下面的定义中形式化地说明这一点。
,这些特征与底层系统具有随附性(supervenience);也就是说,如果系统在 t 时间的完整状态可以完全准确地知道,转移概率对 t'>t 时间的未来状态不提供任何预测能力。我们在下面的定义中形式化地说明这一点。
定义1:设 为一随机过程,如果对于所有
为一随机过程,如果对于所有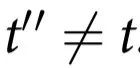 ,
,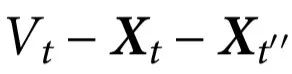 形成马尔可夫链,那么称
形成马尔可夫链,那么称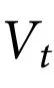 对
对 具有随附性。
具有随附性。
上面的条件相当于要求当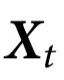 给定时,
给定时,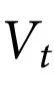 在统计上与
在统计上与 无关。图2说明了随附特征和底层系统之间的关系。
无关。图2说明了随附特征和底层系统之间的关系。
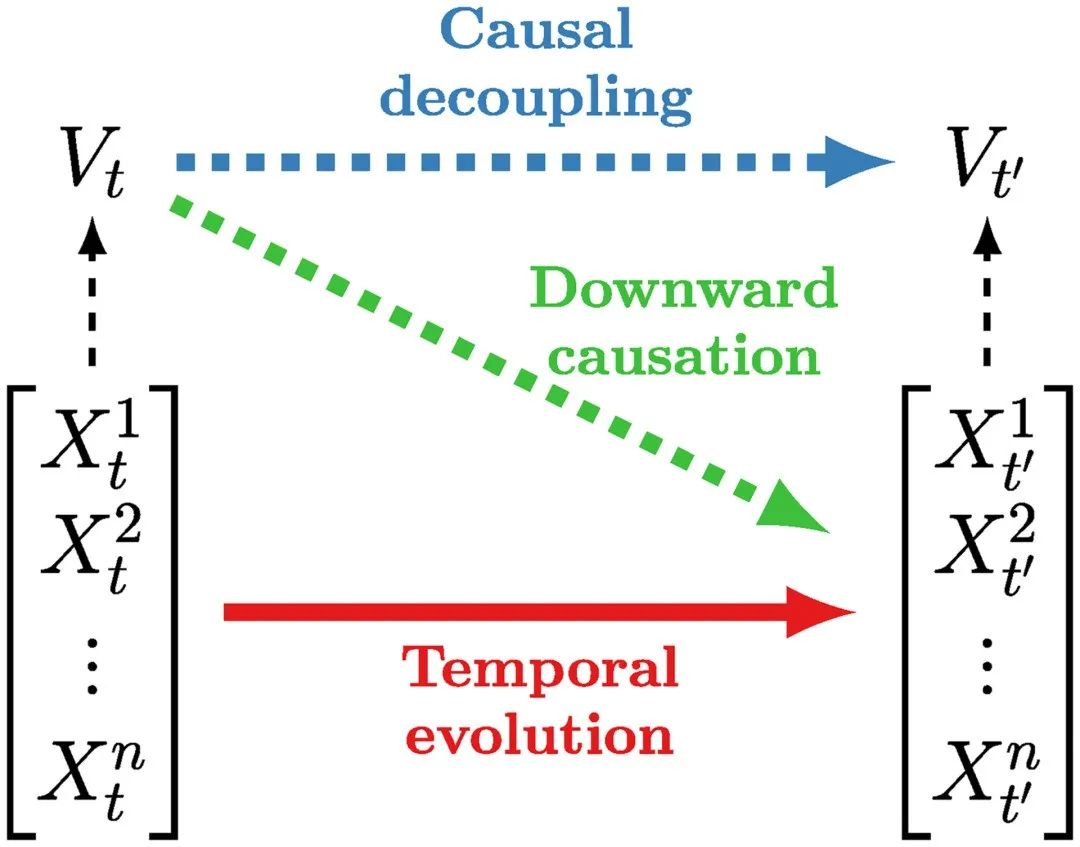
图2. 因果涌现关系图。因果涌现的特征具有超越个别成分的预测能力。当这种预测能力指向单个元素时,就会发生自上而下因果;当它指向自身或其他高阶特征时,就会发生因果解耦。
这一对随附性的形式化刻画了特征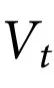 (它完全由系统在给定时间t的状态决定),并且允许特征是有噪声的——这对我们的结果并不关键,但对于将其适用领域扩展到实际场景是很有用的。实际上,定义1包括作为特定情况的确定性函数F:
(它完全由系统在给定时间t的状态决定),并且允许特征是有噪声的——这对我们的结果并不关键,但对于将其适用领域扩展到实际场景是很有用的。实际上,定义1包括作为特定情况的确定性函数F: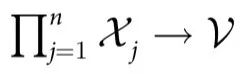 ,使得
,使得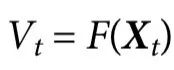 ,以及在观察噪声下计算的特征,例如
,以及在观察噪声下计算的特征,例如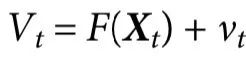 ,其中
,其中 在所有t下与
在所有t下与 无关。相反,利用
无关。相反,利用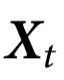 在多个时间点的值(如
在多个时间点的值(如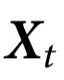 的傅里叶变换)计算的特征通常不具有随附性。
的傅里叶变换)计算的特征通常不具有随附性。
3.2 部分信息分解
我们的理论基于部分信息分解(Partial Information Decomposition,PID)框架[14],它为推理多变量系统中的信息提供了强大的工具。简而言之,PID 将n个源 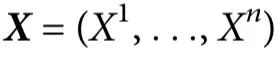 提供的关于目标变量Y的信息以信息原子(information atoms)的形式分解:
提供的关于目标变量Y的信息以信息原子(information atoms)的形式分解:
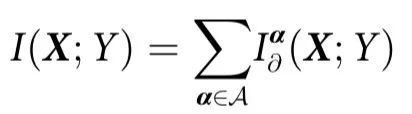
其中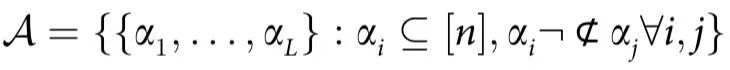 是一套反链集合(antichain collections)[14]。直观地说,对
是一套反链集合(antichain collections)[14]。直观地说,对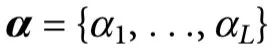 ,
,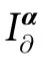 代表变量集合
代表变量集合 提供、但其子集合不提供的冗余信息。例如,对于n=2个源变量,α = {{1}{2}} 对应于两个源提供的关于Y的信息,α = {{i}} 对应于 Xi 单独提供的信息。最有趣的是,α = {{12}} 对应于两个源共同提供但不单独提供的信息,这通常被称为信息协同(informational synergy)。
提供、但其子集合不提供的冗余信息。例如,对于n=2个源变量,α = {{1}{2}} 对应于两个源提供的关于Y的信息,α = {{i}} 对应于 Xi 单独提供的信息。最有趣的是,α = {{12}} 对应于两个源共同提供但不单独提供的信息,这通常被称为信息协同(informational synergy)。
PID 的一个缺点是信息原子的数量(即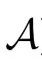 的势)随着源的数量超指数增长。因此,根据特定标准对分解进行粗粒化是很有用的。这里我们引入n个变量之间的 k 阶协同效应(k th-order synergy)的概念,其计算方法为:
的势)随着源的数量超指数增长。因此,根据特定标准对分解进行粗粒化是很有用的。这里我们引入n个变量之间的 k 阶协同效应(k th-order synergy)的概念,其计算方法为:
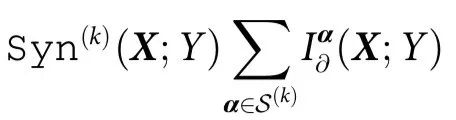
其中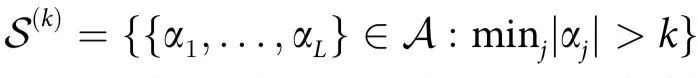 。直观地说,
。直观地说,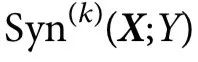 对应的是关于目标的信息,这些信息由整个
对应的是关于目标的信息,这些信息由整个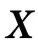 提供,但不包含在任何由k个或更少部分组成的集合中,当这些部分与其他部分分开考虑时。因此,
提供,但不包含在任何由k个或更少部分组成的集合中,当这些部分与其他部分分开考虑时。因此,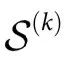 只包含有k个以上源的组的集合。
只包含有k个以上源的组的集合。
同样地,我们引入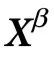 的独特信息(unique information),其中
的独特信息(unique information),其中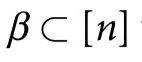 为关于最多k个其他变量的集合,其计算公式为:
为关于最多k个其他变量的集合,其计算公式为:
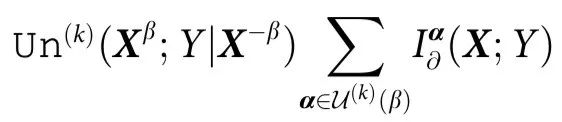
其中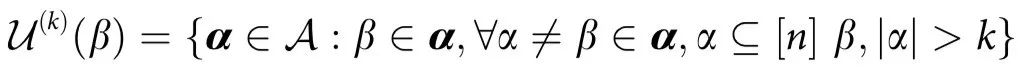 ,
,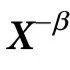 为
为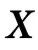 中不包含在
中不包含在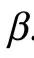 中的所有变量。简单地说,
中的所有变量。简单地说,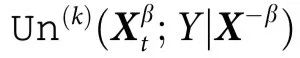 表示
表示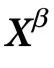 携带的关于
携带的关于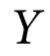 的信息,但是
的信息,但是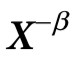 中任何k个或更少的变量组都不具有这些信息。注意这些粗粒化的项可以用来建立附录S1(第1节)中描述的
中任何k个或更少的变量组都不具有这些信息。注意这些粗粒化的项可以用来建立附录S1(第1节)中描述的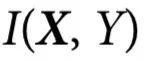 的一般分解,其属性在附录S1(第2节)中得到证明。
的一般分解,其属性在附录S1(第2节)中得到证明。
PID的一个特点是,它规定了信息原子的结构和它们之间的关系,但它没有规定一个特定的函数形式来计算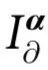 。事实上,只有一个信息原子必须被指定来确定整个PID——通常是所有单个元素之间的冗余[14]。在PID文献中,有多个关于
。事实上,只有一个信息原子必须被指定来确定整个PID——通常是所有单个元素之间的冗余[14]。在PID文献中,有多个关于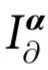 的具体函数形式的建议,可以见文献[15-18]。一个基于最近的PID[19]的完全计算信息原子的特殊方法将在“通过协同通道测量涌现”一节中讨论。
的具体函数形式的建议,可以见文献[15-18]。一个基于最近的PID[19]的完全计算信息原子的特殊方法将在“通过协同通道测量涌现”一节中讨论。
方便的是,我们的理论并不依赖于PID的具体函数形式,而只是依赖于附录S1(第2节)中精确表述的几个基本属性。因此,该理论可以使用任何PID进行实例化,只要这些属性得到满足。重要的是,如“大型系统的实用标准”一节所示,该理论允许推导出独立于所选PID的实用度量。
3.3 定义因果涌现
有了PID的工具,现在我们介绍对因果涌现的形式定义。
定义2:对于一个由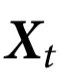 描述的系统,一个随附特征
描述的系统,一个随附特征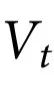 被认为表现出 k 阶因果涌现,如果
被认为表现出 k 阶因果涌现,如果
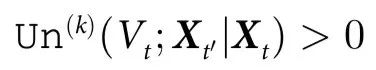
相应地,当一个随附特征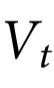 具有不可还原因果效应时,即当它施加的因果效应不是由系统的任何部分传递时,因果涌现就发生了。换句话说,
具有不可还原因果效应时,即当它施加的因果效应不是由系统的任何部分传递时,因果涌现就发生了。换句话说,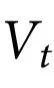 代表系统中涌现的集体属性,如果它:1)包含动态相关的信息(这意味着它预测系统的未来演化);2)这个信息超出了系统中k个部分的群体单独考虑时所给出的信息。
代表系统中涌现的集体属性,如果它:1)包含动态相关的信息(这意味着它预测系统的未来演化);2)这个信息超出了系统中k个部分的群体单独考虑时所给出的信息。
为了更好地理解这个定义的含义,我们研究它的一些基本属性。
引理1:考虑一个特征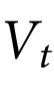 ,它在
,它在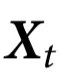 上表现出一阶因果涌现,那么:
上表现出一阶因果涌现,那么:
(1)系统的维度符合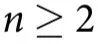 。
。
(2)不存在一个确定性的函数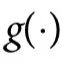 ,使
,使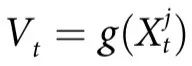 ,对于任何 j = 1, ..., n。
,对于任何 j = 1, ..., n。
证明见S1附录第3节。
这两个属性将因果涌现确立为一种基本的集体现象。实际上,属性(1)指出,因果涌现是多变量系统的一个属性,而属性(2)指出,如果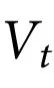 可以通过一个单一变量完美预测,它就不可能有涌现行为。
可以通过一个单一变量完美预测,它就不可能有涌现行为。
为了使用定义2,我们需要一个可以测试的候选特征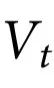 。然而,在某些情况下,并没有明显的候选涌现特征,对于这种情况,定义2似乎有问题。我们的下一个结果提供了一个完全基于系统动力学的涌现特征的存在标准。
。然而,在某些情况下,并没有明显的候选涌现特征,对于这种情况,定义2似乎有问题。我们的下一个结果提供了一个完全基于系统动力学的涌现特征的存在标准。
定理1:一个系统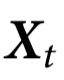 具有k阶因果涌现特征,当且仅当
具有k阶因果涌现特征,当且仅当
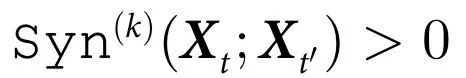
证明见S1附录第2节。
推论1:下面的约束对于任何随附特征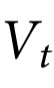 都成立:
都成立:
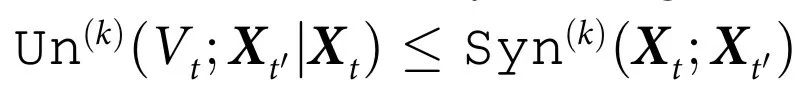
这一结果表明,表现出涌现能力与系统各部分在未来演化中的协同性密切相关。重要的是,这一结果使我们能够仅仅通过检查系统各部分之间的协同效应——而不需要知道这些特征可能是什么,就能确定系统是否具有任何涌现特征。相反,这个结果也使我们能够通过检查一个简单的条件,即动力学协同效应的缺失,来排除因果涌现的存在。此外,推论1意味着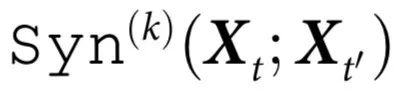 可以作为系统涌现能力的衡量标准,因为它为所有可能的随附特征的独特信息提供了上界。
可以作为系统涌现能力的衡量标准,因为它为所有可能的随附特征的独特信息提供了上界。
定理1在因果涌现和系统的统计学之间建立了直接联系,从而无需观察者提出感兴趣的特定特征。值得注意的是,一个系统的涌现能力取决于系统的微观元素的划分——事实上,系统在一种微观表示下可能有涌现能力,但在改变变量后,相对于另一种微观表示可能就没有涌现能力。因此,在我们的理论中,涌现总是指“关于一种给定微观划分的涌现”。
3.4 涌现的分类
到目前为止,我们的理论能够检测到是否有涌现发生;下一步则需要确定是哪种涌现。
为此,我们将定理1中提出的涌现的特征判断标准与整合信息分解(Integrated Information Decomposition, ΦID)结合,ΦID 是 PID 在多目标环境下的最新扩展[20]。
使用 ΦID,我们可以将一个 PID 原子分解为:
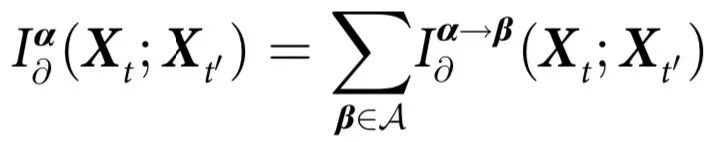
例如,如果n=2,那么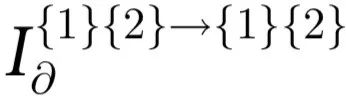 代表两个时间序列在两个时间段共享的信息(例如
代表两个时间序列在两个时间段共享的信息(例如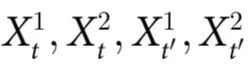 都是彼此的拷贝)。并且
都是彼此的拷贝)。并且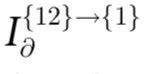 对应于
对应于 中对
中对 有独特影响的协同原因(例如
有独特影响的协同原因(例如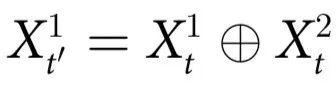 )。关于 ΦID 的更多细节和直觉可以在文献[20]中找到。
)。关于 ΦID 的更多细节和直觉可以在文献[20]中找到。
通过 ΦID 提供的细粒度分解,我们可以分辨出不同情形的协同作用。特别地,我们引入k阶自上而下因果 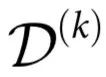 和因果解耦
和因果解耦 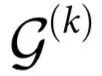 :
:
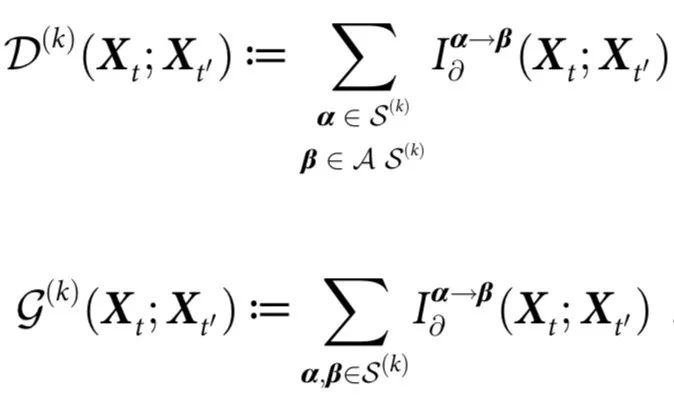
从这些定义和公式中,我们可以验证:
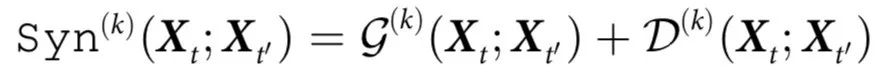
因此,一个系统的因果涌现能力自然分解为两个不同部分:关于 k-plets 未来变量的信息,以及超出k-plets以外的未来集体属性的信息。属于这两个概念的 ΦID 原子在图3中两个时间序列的 ΦID 格点中得到了说明。本节的其余部分将表明,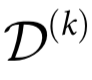 和
和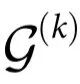 分别是自上而下因果和因果解耦的自然度量。
分别是自上而下因果和因果解耦的自然度量。
自上而下因果:直观地说,当集体性质对个体部分具有不可还原的因果效应时,就会出现自上而下因果。形式化表述就是:
定义3:一个随附特征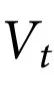 表现出k阶自上而下因果,如果对于某个α,|α|=k:
表现出k阶自上而下因果,如果对于某个α,|α|=k:
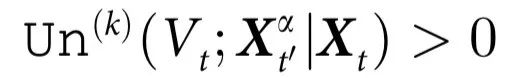
请注意,与定义2不同的是,自上而下因果要求特征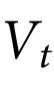 对整个系统的特定子集的演化有独特的预测能力。特别是,一个对比如说
对整个系统的特定子集的演化有独特的预测能力。特别是,一个对比如说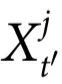 有预测能力的特征
有预测能力的特征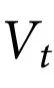 被称为发挥了自上而下因果效应,因为它预测了
被称为发挥了自上而下因果效应,因为它预测了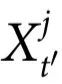 的一些情况,而这些情况在
的一些情况,而这些情况在 的任何特定
的任何特定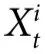 中无法预测。换句话说,在一个具有自上而下因果的系统中,整体对部分的影响不能还原为低层次的相互作用。“基本直觉”一节中的例2提供了一个最小示例。
中无法预测。换句话说,在一个具有自上而下因果的系统中,整体对部分的影响不能还原为低层次的相互作用。“基本直觉”一节中的例2提供了一个最小示例。
我们的下一个结果是将自上而下因果与公式中引入的指数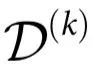 形式化地联系起来。
形式化地联系起来。
定理2:如果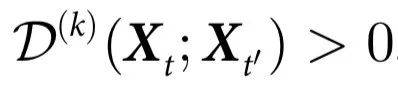 ,则一个系统
,则一个系统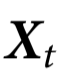 具有施加 k 阶自上而下因果的特征。
具有施加 k 阶自上而下因果的特征。
证明见附录S1第3节。
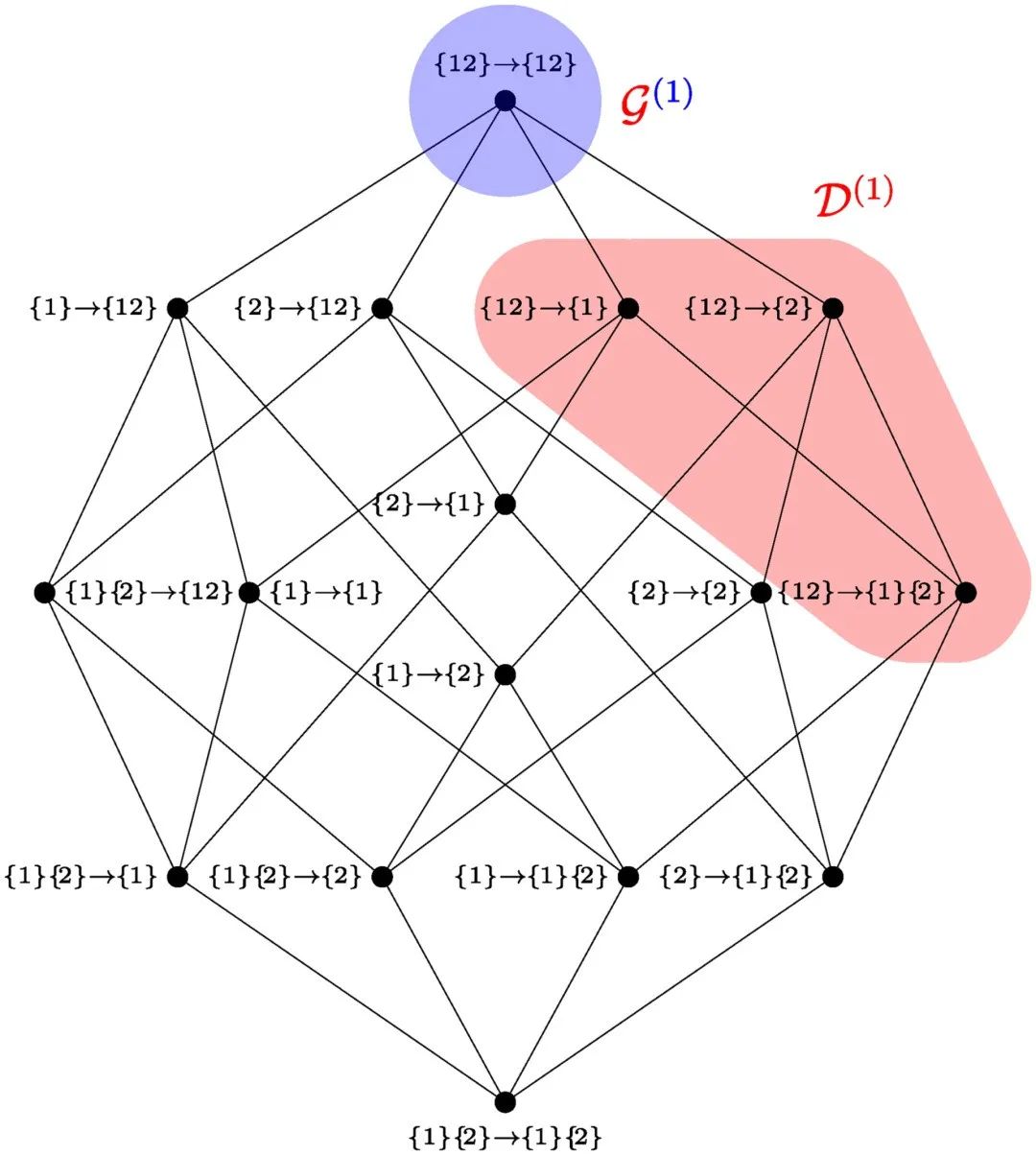
图3. 整合信息分解(ΦID):n=2 个时间序列的 ΦID 网格[20],强调了自上而下因果(D)和因果解耦(G)项。
因果解耦。除了自上而下因果外,当集体属性对其他集体属性具有不可还原因果效应时,因果解耦也会发生。用术语来表示:
定义4:一个随附特征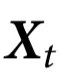 被称为表现出k阶因果解耦,如果
被称为表现出k阶因果解耦,如果
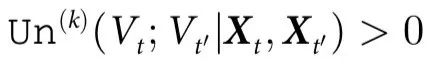
此外,如果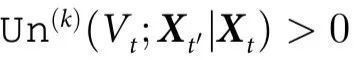 ,并且对于所有
,并且对于所有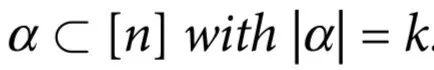 ,有
,有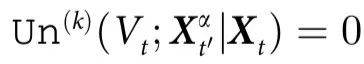 ,那么
,那么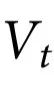 就被认为具有纯因果解耦(pure causal decoupling)。最后,如果所有涌现特征都表现出纯因果解耦,那么系统就被认为是完全解耦的。
就被认为具有纯因果解耦(pure causal decoupling)。最后,如果所有涌现特征都表现出纯因果解耦,那么系统就被认为是完全解耦的。
以上,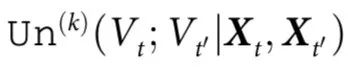 指的是
指的是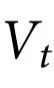 和
和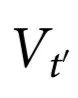 共享,且在任何微观元素中都找不到的信息,无论是在时间t还是t'。(注意
共享,且在任何微观元素中都找不到的信息,无论是在时间t还是t'。(注意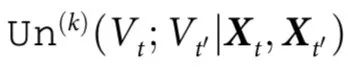 是
是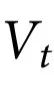 和
和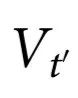 之间共享,而
之间共享,而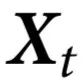 或
或 的k个或更少变量组合本身没有的信息。)
的k个或更少变量组合本身没有的信息。)
表现出因果解耦的特征仍然可以对个体元素的演化施加影响,而表现出纯解耦的特征则不能。实际上,条件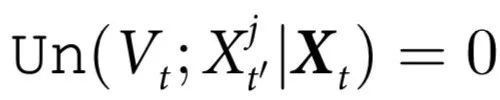 意味着高阶因果效应不影响任何特定部分,只影响系统整体。有趣的是,一个表现出纯因果解耦的特征可以被认为是有“自己的生命”;一种统计学上的幽灵,它随着时间推移而延续,系统的任何单个部分都不会影响它或被它影响。在“基本直觉”部分的第一个例子中,系统的奇偶性构成了完美因果解耦的一个简单例子。重要的是,“案例研究”一节中的案例研究表明,因果解耦不仅可以发生在玩具模型中,也可以发生在具有实际意义的各种情况下。
意味着高阶因果效应不影响任何特定部分,只影响系统整体。有趣的是,一个表现出纯因果解耦的特征可以被认为是有“自己的生命”;一种统计学上的幽灵,它随着时间推移而延续,系统的任何单个部分都不会影响它或被它影响。在“基本直觉”部分的第一个例子中,系统的奇偶性构成了完美因果解耦的一个简单例子。重要的是,“案例研究”一节中的案例研究表明,因果解耦不仅可以发生在玩具模型中,也可以发生在具有实际意义的各种情况下。
在这一节的最后,我们正式建立因果解耦和公式中引入的指数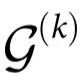 之间的联系。
之间的联系。
定理3:当且仅当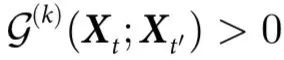 时,系统拥有表现出因果解耦的特征。此外,如果
时,系统拥有表现出因果解耦的特征。此外,如果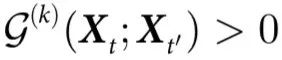 且
且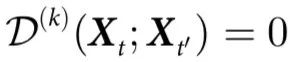 ,系统是完全解耦的。
,系统是完全解耦的。
证明见附录S1第3节。
4. 度量因果涌现
本节探讨将上一节中提出的框架付诸实施的方法。我们讨论两种方法:首先,4.1节“大型系统的实用标准”介绍在大型系统中实用的充分性标准;然后,4.2节“通过使用协同通道测量因果涌现”,说明如果采用计算 ΦID 原子的特定方法,应如何进一步考虑。后一种方法提供了准确的判别,但代价是数据密集,因此只适用于小系统;前一种方法可以在大系统中计算,其结果独立于所选择的 PID,但容易出现错误检测(即假阴性)。
4.1 大型系统的实用标准
我们提出的框架虽然在理论上很有吸引力,但在估计许多随机变量的联合概率分布以及ΦID原子本身的计算方面存在挑战。作为替代方案,我们考虑不需要采用任何特定 ΦID 或 PID 函数的近似方法,并且由于这些近似方法只基于成对分布,因而是数据高效的。
作为衡量k阶因果的实际标准,我们引入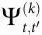 ,
,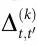 和
和 。为简单起见,我们在此写出k=1的特殊情况,并提供任意k的完整公式证明。在附录S1第4节中提供了相应证明。
。为简单起见,我们在此写出k=1的特殊情况,并提供任意k的完整公式证明。在附录S1第4节中提供了相应证明。
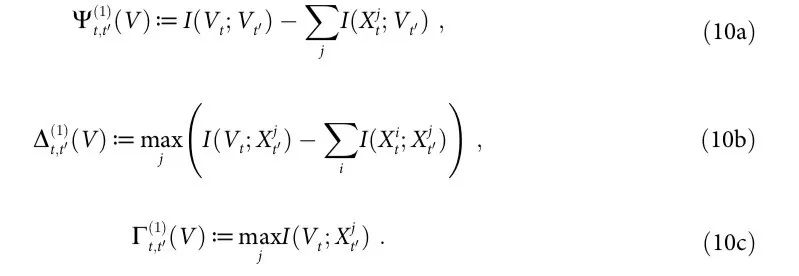
我们的下一个结果是将这些量与第一节“因果涌现的形式理论”中的形式定义联系起来,显示它们作为检测因果涌现的实用标准的价值。
命题1: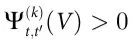 是Vt具有因果涌现特性的充分条件。同样地,
是Vt具有因果涌现特性的充分条件。同样地, 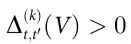 是Vt 表现出自上而下因果的充分条件。最后,
是Vt 表现出自上而下因果的充分条件。最后,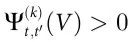 和
和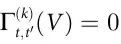 是因果解耦的充分条件。
是因果解耦的充分条件。
证明见附录S1第4节。
虽然通过命题1计算一个系统是否具有涌现特征可能在计算上具有挑战性,但是如果我们有一个可能是涌现的候选特征V,就可以计算公式 (10) 中只依赖于标准互信息和双变量边际、并且与系统大小呈线性比例(对于 k=1)的简单量。这些量很容易用标准的信息论工具计算并测试其显著性[21, 22]。此外,这些方法的结果对任何与附录S1第2节中规定的属性兼容的ΦID和PID的选择都是有效的。
在更广泛的背景下,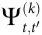 和
和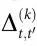 与相互作用信息[14, 23]、冗余-协同指数[24]以及最近的O-信息Ω[25]一样,都属于“整体减去总和”(whole-minus-sum)系列的度量——它们不能测量协同本身,只能测量协同和冗余的差值。在实践中,这意味着如果系统中存在冗余,将更难发现涌现,实际的冗余将推动
与相互作用信息[14, 23]、冗余-协同指数[24]以及最近的O-信息Ω[25]一样,都属于“整体减去总和”(whole-minus-sum)系列的度量——它们不能测量协同本身,只能测量协同和冗余的差值。在实践中,这意味着如果系统中存在冗余,将更难发现涌现,实际的冗余将推动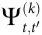 和
和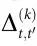 变得更负。此外,通过对所有边际互信息(如
变得更负。此外,通过对所有边际互信息(如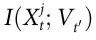 在
在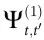 的情况下)求和,这些方法有效地重复计算冗余度达n次,进一步让度量标准变得更糟糕。如果我们愿意致力于一个特定的ΦID或PID函数,这种重复计算问题是可以避免的,正如我们接下来所展示的。
的情况下)求和,这些方法有效地重复计算冗余度达n次,进一步让度量标准变得更糟糕。如果我们愿意致力于一个特定的ΦID或PID函数,这种重复计算问题是可以避免的,正如我们接下来所展示的。
值得注意的是,可以调整k的值以探索不同“尺度”的涌现。例如,k=1对应于单个微观元素的涌现,而k=2指的是所有耦合的涌现——即单个元素及其成对相互作用。因此,一般来说,命题1中的标准对于较大的k值来说很难满足。此外,从实际角度来看,考虑较大的k值需要在高维分布中估计信息量,这通常需要指数级的大量数据。
4.2 通过协同通道度量因果涌现
本节利用参考文献[19]中报告的关于信息分解的最新工作,提出一种直接测量涌现能力以及自上而下因果和因果解耦指数的方法。本节的主要内容是,如果采用一个特定的ΦID,那么就有可能直接评估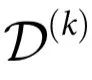 和
和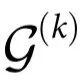 ,提供一个直接检测涌现的途径,而不需要重复计算冗余,就像“大型系统的实用标准”一节介绍的方法那样。此外,由于所选择的特定ΦID的特性,额外的属性可能会变得可用。
,提供一个直接检测涌现的途径,而不需要重复计算冗余,就像“大型系统的实用标准”一节介绍的方法那样。此外,由于所选择的特定ΦID的特性,额外的属性可能会变得可用。
让我们首先介绍一下k-协同通道(k-synergistic channel)的概念:在所有 |α|=k 的情况下,传递关于X的信息但不传递关于任何部分 信息的映射
信息的映射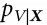 。所有k-协同通道的集合表示为:
。所有k-协同通道的集合表示为:
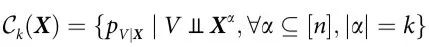
通过k-协同通道产生的变量 V 被称为k-协同可观测量。
有了这个定义,我们可以认为k阶协同效应是可以从一个k-协同通道中提取的最大信息:
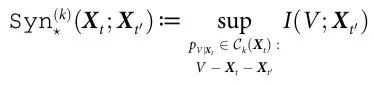
这个想法可以自然扩展到因果解耦的情况,要求双方都有协同通道,也就是
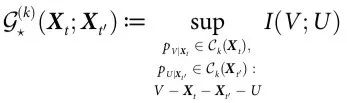
最后,自上而下因果指数可以从两者的差计算出来:
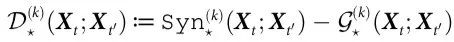
请注意,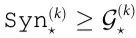 是应用在
是应用在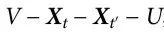 上的数据处理不等式的直接结果,因此
上的数据处理不等式的直接结果,因此 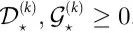 。
。
通过利用这种测量协同作用的特定方式的特性,我们可以证明以下结果。为此,可以说,如果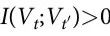 ,则特征
,则特征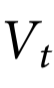 是自关联的。
是自关联的。
命题2:如果Xt是稳定的,所有自关联k-协同可观测量都是k阶涌现的。
证明。见S1附录第4节。
总之,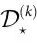 和
和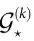 提供了数据驱动的工具来测试——可能是拒绝——关于感兴趣的场景中出现的假设。参考文献[26]中讨论了计算这些量的有效算法。虽然目前的实现只能用于相对较小的系统,但这一思路表明,未来PID的发展可能会使涌现指数的计算更具可扩展性,避免公式(10)的限制。
提供了数据驱动的工具来测试——可能是拒绝——关于感兴趣的场景中出现的假设。参考文献[26]中讨论了计算这些量的有效算法。虽然目前的实现只能用于相对较小的系统,但这一思路表明,未来PID的发展可能会使涌现指数的计算更具可扩展性,避免公式(10)的限制。
5. 案例研究
让我们总结一下到目前为止的结果。我们首先基于PID给出了涌现特征的一个严格定义(3.3节“定义因果涌现”),然后用ΦID将涌现能力分解为因果解耦和自上而下因果指数(3.4节“涌现的分类”)。尽管这些指数不是直接计算的,但ΦID框架允许我们制定容易计算的充分条件(4.1节“大型系统的实用标准”)。本节说明这些条件在各种案例研究中的应用。公式(10)中计算所有涌现条件的代码在在线开放源码库中提供(https://github.com/pmediano/ReconcilingEmergences)。
5.1 推定的因果涌现的典型例子
在这里,我们提出用两个著名系统对我们的实用涌现标准(命题1)进行评估。康威生命游戏(Conway’s Game of Life)[27]和雷诺鸟群模型(Reynolds’ flocking model)[28]。两者都被广泛认为是涌现行为的典型例子,并在复杂性和人工生命文献中得到了深入研究[29]。因此,我们使用这些模型作为我们方法的测试案例。模拟的技术细节在附录S1第5节中提供。
康威的生命游戏。生命游戏的一个众所周知的特征是粒子的存在:这里的粒子是指负责传递和修改信息的连贯、自我维持的结构[30]。这些粒子一直是广泛研究的对象,并有详细的分类方法和分类[29, 31]。
为了测试粒子的涌现特性,我们模拟15x15方形元胞阵列的演化,我们将其视为二进制向量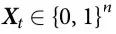 ,n = 225。作为初始条件,我们考虑对应于“粒子对撞机”设置的位形,两个已知类型的粒子面对面(图4)。在每次试验中,通过改变粒子的位置、类型和相对位移,系统被随机化。在选择一个初始位形后,著名的生命游戏演化规则[27]被应用1000次,导致最终状态
,n = 225。作为初始条件,我们考虑对应于“粒子对撞机”设置的位形,两个已知类型的粒子面对面(图4)。在每次试验中,通过改变粒子的位置、类型和相对位移,系统被随机化。在选择一个初始位形后,著名的生命游戏演化规则[27]被应用1000次,导致最终状态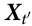 。模拟表明,这个时间间隔足以使系统在碰撞后处于稳定状态。
。模拟表明,这个时间间隔足以使系统在碰撞后处于稳定状态。
为了使用公式(10)的标准,我们需要选择一个候选的涌现特征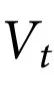 。在这种情况下,我们考虑一个符号化的、离散值向量来编码网格上的粒子类型。具体来说,我们考虑
。在这种情况下,我们考虑一个符号化的、离散值向量来编码网格上的粒子类型。具体来说,我们考虑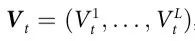 ,其中
,其中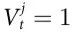 ,如果在时间t有一个j类型的粒子,无论其位置或方向。
,如果在时间t有一个j类型的粒子,无论其位置或方向。
有了这些变量,我们使用互信息的贝叶斯估计器来计算公式(10)中的量[32]。结果是,正如预期那样,因果关系出现的标准是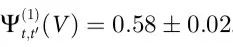 。此外,我们发现
。此外,我们发现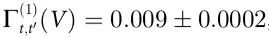 ,这比
,这比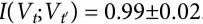 小了几个数量级。误差代表代用数据的标准偏差,如附录S1第5节所述。使用命题1,这两个结果表明,生命游戏中的粒子动力学可能不仅是涌现的,而且与它们的底层是因果解耦的。
小了几个数量级。误差代表代用数据的标准偏差,如附录S1第5节所述。使用命题1,这两个结果表明,生命游戏中的粒子动力学可能不仅是涌现的,而且与它们的底层是因果解耦的。
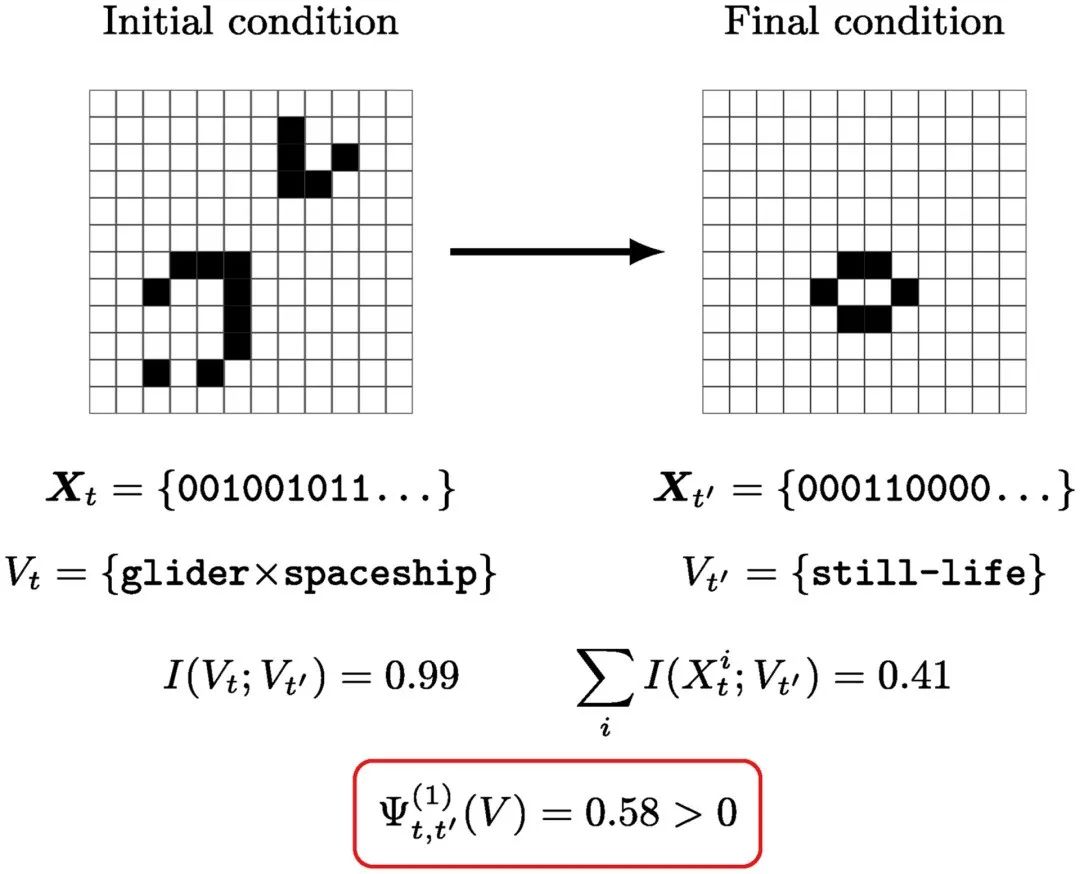
图4. 康威生命游戏中的因果涌现。系统被初始化为 "粒子对撞机"设置,并运行到碰撞后达到一个稳定位形。使用粒子类型作为随附特征V,我们发现该系统符合我们对因果涌现的实用标准。
雷诺的鸟群模型。作为第二个测试案例,我们考虑雷诺的集群行为模型。这个模型由 boids(类似鸟的物体)组成,每个boid由三个数字表示:它在二维空间的位置和行进方向的角度。作为涌现的候选特征,我们按照Seth[6]的做法,使用鸟群质心的二维坐标。
在这个模型中,boid之间的相互作用遵循三个规则,每个规则由一个标量参数调节[6]。
· 聚集(a1):当它们飞向鸟群中心时。
· 回避(a2):当它们飞离其最近的邻居时;
· 对齐(a3):当它们的飞行方向与邻居一致时。
根据参考文献[6],我们研究了不同参数设置下 N=10 个 boid 的小鸟群,以展示我们的实用涌现标准的一些特性。请注意,这项研究是为了说明所提出的理论,而不是作为对鸟群模型的详细探索,关于这个模型已有大量文献存在(例如,见Vicsek的工作[33]和其中的参考文献)。
图5显示了在保持 a1 和 a3 固定的情况下,对回避参数a2进行参数扫描的结果。当没有回避时,boid 围绕缓慢移动的质心旋转,可称为有序的形态。相反,当回避参数 a2 较大时,近邻的排斥力太强,无法形成持久的鸟群,孤立的 boid 分散在空间中,相互回避。当回避参数处于中间值时,随着鸟群聚集和解体,质心形成一个平滑的轨迹。与Seth[6]的研究结果一致,我们的标准表明,在这个中间范围内,群体表现出因果涌现行为。
通过分别研究构成 Ѱ 的两个项,我们发现,对于较小和较大的回避参数 a2,都没有出现涌现,但未出现的原因不同(见图5)。实际上,对于较大的 a2 来说,质心的自我可预测性(即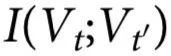 )较小;而对于较小的 a2 来说,质心的自我可预测性较大,但仍然低于单个boid的互信息(即
)较小;而对于较小的 a2 来说,质心的自我可预测性较大,但仍然低于单个boid的互信息(即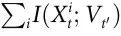 )。这些结果表明,低回避情景不是由协同作用的减少,而是由冗余的增加所主导,这有效地增加了检测涌现所需的协同作用阈值。然而,请注意,由于该标准的局限性,
)。这些结果表明,低回避情景不是由协同作用的减少,而是由冗余的增加所主导,这有效地增加了检测涌现所需的协同作用阈值。然而,请注意,由于该标准的局限性,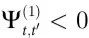 这一事实并不是结论性的,不能排除涌现的可能性。这是对像 Ѱ 这样的“整体减去总和”估计器的常见限制;进一步的完善可能会提供不那么容易受这些问题影响,并在这些情况下准确执行的界限。
这一事实并不是结论性的,不能排除涌现的可能性。这是对像 Ѱ 这样的“整体减去总和”估计器的常见限制;进一步的完善可能会提供不那么容易受这些问题影响,并在这些情况下准确执行的界限。
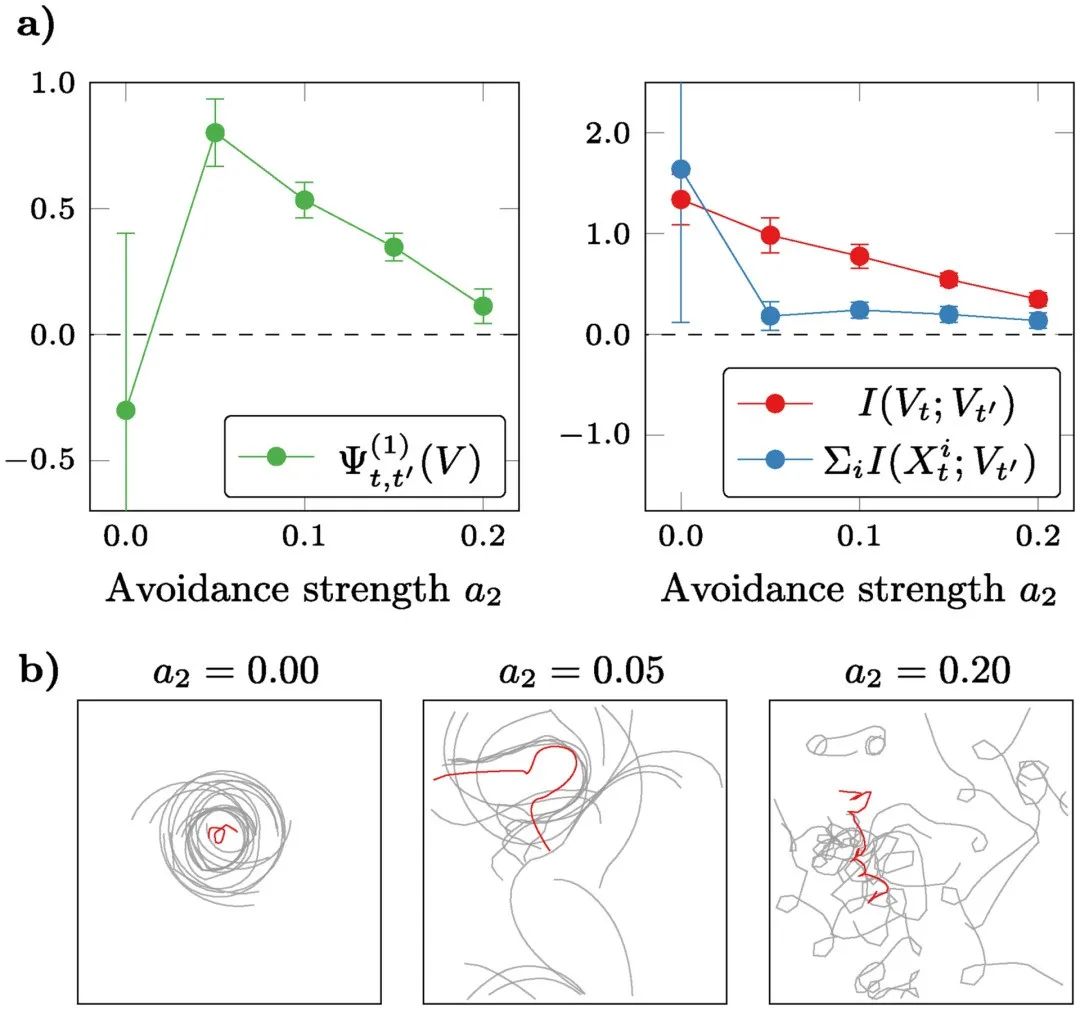
图5. 鸟群模型中的因果涌现。随着回避参数的增加,群体从吸引的形态(其中所有鸟有规律地围绕一个稳定质心旋转)转变为排斥的形态(其中鸟在空间扩散,看不到群体)。a)我们的标准 Ѱ 在回避参数的中间范围检测到因果涌现(误差条代表对代用数据估计的标准偏差)。b) boid(灰色)和其质心(红色)的样本轨迹。
5.2 心智来自物质:涌现、行为和神经生理学
拥有形式化的涌现理论的一个诱人结果是,能够从定量角度看待一个涌现的原型:心智-物质关系[35, 36]。作为这个方向的第一步,我们在本节的最后将我们的涌现标准应用于神经生理学数据。
我们研究了日本猕猴进行伸手任务的同步皮质脑电图(electrocorticogram,ECoG)和动作捕捉(motion capture,MoCap)数据[34],这些数据从在线Neurotycho数据库获得。请注意,MoCap数据不能被假定为现有ECoG数据的随附特征,因为它不满足我们的随附定义所要求的条件独立性条件(见“因果涌现的形式理论”一节)。这种情况很可能发生,因为神经系统只被部分观察到——即ECoG并没有捕捉到猕猴皮层中相关活动的每一个来源。请注意,我们的框架对非随附特征的兴趣有限,因为它们可以以平庸的方式满足命题1(例如,如果独立于底层系统的时间序列是自关联的,它们将满足 Ѱ>0)。相反,我们重点关注与预测猕猴行为有关的编码在ECoG信号中的那部分神经活动,并推测这一信息是底层神经活动的一个涌现特征(图6)。
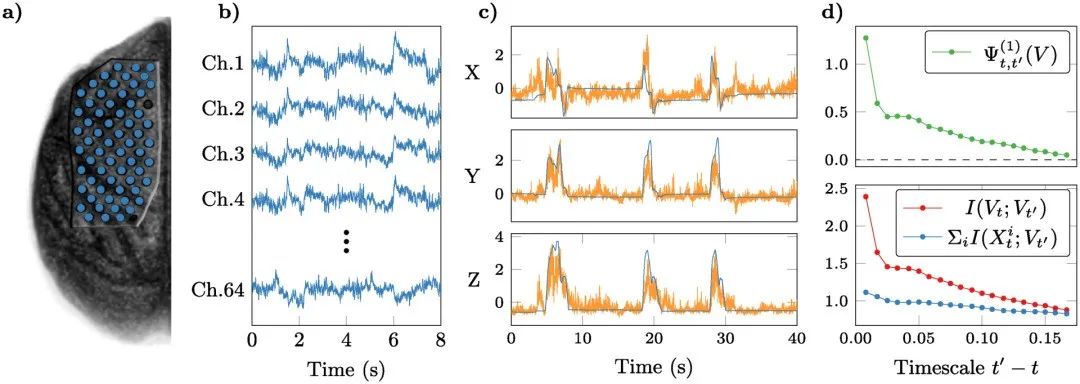
图6. 清醒猕猴运动行为中的因果涌现。a) 录音中使用的皮质脑电图(ECoG)电极的位置(蓝色)叠加在猕猴左半球的图像上(大脑前方朝向页面顶部)。b) 所用的64通道ECoG记录的时间序列样本(蓝色),对应于感兴趣的系统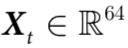 。c) 猕猴手腕的三维位置由运动捕捉测量(蓝色),并由回归模型预测(橙色),可以作为一个随附特征
。c) 猕猴手腕的三维位置由运动捕捉测量(蓝色),并由回归模型预测(橙色),可以作为一个随附特征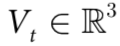 。d) 我们的涌现标准得到
。d) 我们的涌现标准得到 ,检测到与ECoG源有关行为的因果涌现。原始数据和图像来自参考文献[34]和Neurotycho数据库。
,检测到与ECoG源有关行为的因果涌现。原始数据和图像来自参考文献[34]和Neurotycho数据库。
为了验证这一假设,我们把神经活动(由分布在左半球的64个ECoG通道测量)作为感兴趣的系统,并考虑根据ECoG信号对猕猴右手腕的三维坐标进行无记忆预测。因此,在这种情况下,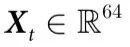 ,且
,且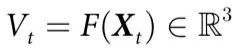 。为了建立Vt,我们使用了部分最小二乘法(Partial Least Squares,PLS)和支持向量机(Support Vector Machine,SVM)回归器,其细节可在附录S1第6节中找到。
。为了建立Vt,我们使用了部分最小二乘法(Partial Least Squares,PLS)和支持向量机(Support Vector Machine,SVM)回归器,其细节可在附录S1第6节中找到。
在对解码器进行训练并在一个保持不变的测试集上进行评估后,结果显示 Ѱ>0,证实了我们的猜想,即与运动有关的信息是猕猴皮层活动的一个涌现特征。对于短时间尺度(t'-t = 8 ms),我们发现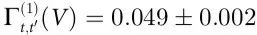 ,比
,比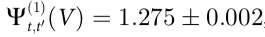 小几个数量级,表明该行为可能有一个与单个ECoG通道解耦的重要组成部分(误差是根据时间数据估计的标准偏差)。此外,在多个不超过 ~0.2s 的时间尺度 t'-t 上,涌现标准都得到满足,超过这个时间尺度,Vt和单个电极的预测能力下降,变得几乎相同。
小几个数量级,表明该行为可能有一个与单个ECoG通道解耦的重要组成部分(误差是根据时间数据估计的标准偏差)。此外,在多个不超过 ~0.2s 的时间尺度 t'-t 上,涌现标准都得到满足,超过这个时间尺度,Vt和单个电极的预测能力下降,变得几乎相同。
作为对照,我们进行了一个替代数据测试,以确认图6中的结果不是由ECoG时间序列的自关联驱动的。为此,我们使用相同的ECoG数据重新进行分析(包括训练和测试PLS-SVM),但对手腕位置进行了时间调整,结果是 Vt没有从ECoG中提取任何有意义的信息,但具有由自关联、过滤和正则化引起的相同属性。正如预期的那样,替代数据 明显低于使用未调整的手腕位置数据,证实测量的
明显低于使用未调整的手腕位置数据,证实测量的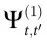 是正的,高于对ECoG的类似随机投影的预期值(详情见附录S1第6节)。
是正的,高于对ECoG的类似随机投影的预期值(详情见附录S1第6节)。
这种分析虽然只是一个概念的证明,但有助于我们量化行为如何以及在多大程度上从集体神经活动中涌现;并为进一步测试和量化心智-物质关系的经验探索打开了大门。
6. 讨论
很大一部分现代科学文献认为,强涌现是不可能的或定义不清的。这种判断并不是完全没有根据的:一个同时具有随附性(即可以从系统的状态中计算出来)和不可还原因果效应(即告诉我们一些部分所没有的东西)的属性确实可以看起来颇为矛盾 [5]。尽管如此,通过将随附性与静态关系联系起来,将因果效应与动态特征联系起来,我们的框架显示,这两种现象与多变量信息动力学的规律[20]是完全兼容的——这一点是反直觉的——为这个悖论提供了一个初步解决方案。
我们的因果涌现理论是关于预测能力,而不是“可解释性”[3],因此与强涌现的观点无关,如Chalmers的观点[3]。然而,我们的框架包含通常与强涌现相关的方面——比如自上而下因果——并且使它们可以量化。我们的框架也不符合弱涌现的传统定义(在“基本直觉”一节中研究的系统不是Bedau[5]意义上的弱涌现,它们简单,且容易被解释的捷径所影响),但与更普遍的弱涌现概念兼容,例如Seth提出的概念(见“与其他涌现量化理论的关系”一节)。因此,我们的理论可以被看作是调和这些方法的一种尝试[36],表明一个“弱”框架可以有多“强”。
我们理论的一个重要结果是在因果涌现和统计协同之间建立基本联系:研究发现,系统承载涌现特征的能力由其元素在未来演化中的协同程度决定。虽然在过去关于协同的想法与涌现有松散的联系[37],但这是(就我们所知)第一次利用多变量信息论的最新进展,形式化地提出和量化这种想法。
接下来,我们将研究一些关于所提出理论的适用性的注意事项,它与先前工作的关系,以及一些开放性问题。
6.1 理论的范围
我们的理论侧重于涌现的同步性[38]方面,分析动态系统各要素之间的相互作用以及它们随时间共同演变的集体属性。因此,我们的理论直接适用于任何具有明确动力学演化的系统,包括由具有随机初始条件的确定性动力系统描述的系统[11],和由 Fokker-Planck 方程描述的随机系统[39]。相比之下,我们的理论在热力学平衡系统中的应用可能并不直接,因为它们的动力学往往不是由相应的吉布斯分布唯一确定的(举一个明确的例子,当考虑 Ising 模型时,即使系统处于平衡状态,Kawasaki 和 Glauber 动力学的行为已知是不同的[40];因此可能提供与“测量涌现”部分描述的相当不同的测量值)。寻找原则性方法来指导我们的理论在这些情况下的应用是未来研究的一个有趣挑战。
此外,考虑到“涌现”这个概念的广度,还有一些更倾向于哲学的其他理论,与我们的框架正交。这包括,例如,作为根本的新颖性(radical novelty,指系统中没有预先观察到的特征)的涌现理论[41],最著名的是安德森的格言“more is different” [42, 43],特别是他对生物学中涌现的方法(注意,安德森的一些观点,特别是与刚度(rigidity)有关的观点,与我们的框架所发展的方法密切相关),也在考夫曼的工作中得到阐述[44, 45]。另外,上下文涌现(contextual emergence)强调了宏观层面的上下文作用,它们无法在微观层面上描述,但为宏观涌现在微观层面施加了限制[46, 47]。这些都是有价值的哲学立场,在文献[46, 48]中已经从统计力学角度进行了研究。未来的工作将试图把这些其他方法与我们提出的框架统一起来。
6.2 因果
评估一个系统的因果结构的实际方法是分析其对干预的反应,或基于专业知识建立干预模型(因果图),这导致了由Judea Pearl[10]率先提出的著名的 do-演算 。不幸的是,这种方法不适用于许多人们感兴趣的场景,因为干预可能会产生过高的成本,甚至是不可能的,而且专业知识可能无法获得。这些情况仍然可以通过统计因果的 Wiener-Granger 理论来评估,该理论通过考虑过去和未来事件之间的非中介相关性,研究整个感兴趣系统的预测能力蓝图[12]。当所有相关变量都被测量时,这两个框架提供相似的结果,但当存在未观察到的相互作用变量时,这两个框架会有根本不同[10]。Wiener-Granger学派和Pearl学派之间的争论已经在其他相关背景下进行了讨论,例如参考文献[49, 50]关于整合信息理论(Integrated Information Theory,IIT)的讨论,以及参考文献[51]对神经影像时间序列分析中的有效连接和功能连接的讨论(简而言之,有效连接旨在揭示观察数据背后的最小物理因果机制,而功能连接则描述有向或无向的统计依赖[51])。
在我们的理论中,主要分析对象是香农的互信息 ,它取决于联合概率分布
,它取决于联合概率分布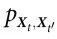 。这个分布的来源(无论是通过被动观察还是主动干预得到)将改变对上述数量的解释,并对 Pearl 学派和 Wiener-Granger 学派有不同的说法;这些差异的一些影响将在下面讨论文献[7]时探讨。尽管如此,由于获得
。这个分布的来源(无论是通过被动观察还是主动干预得到)将改变对上述数量的解释,并对 Pearl 学派和 Wiener-Granger 学派有不同的说法;这些差异的一些影响将在下面讨论文献[7]时探讨。尽管如此,由于获得 的两种方法都允许发生协同作用,我们的结果原则上适用于这两个框架——这使我们能够在不对关于因果本身的理论采取僵硬立场的情况下,制定我们的因果涌现理论。
的两种方法都允许发生协同作用,我们的结果原则上适用于这两个框架——这使我们能够在不对关于因果本身的理论采取僵硬立场的情况下,制定我们的因果涌现理论。
6.3 与其他量化涌现理论的关系
这项工作是通过信息论将复杂性理论形式化这一更广泛运动的一部分。特别是,我们的框架最直接地受到Seth[6]和Hoel等人[7]工作的启发,同时也与Chang等人[52]的最新工作有关。本节将简要介绍这些理论,并讨论它们与我们的理论有何不同。
Seth[6]提出,一个过程Vt 相对于Xt 是 Granger-涌现的(或G-涌现的),如果满足两个条件:(i) Vt 相对 Xt 是自主的(即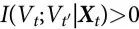 ),和 (ii) Vt 相对 Xt 是 G-因果的(即
),和 (ii) Vt 相对 Xt 是 G-因果的(即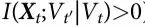 )。后一个条件被用来保证Xt 和Vt 之间的关系;在我们的框架中,与此等价的作用由随附性的要求来承担。自主性的条件当然与我们的因果解耦概念有关。然而,正如参考文献[14]所显示的那样,条件互信息混淆了独特信息和协同信息,这可能导致不理想的情况:例如,可能是
)。后一个条件被用来保证Xt 和Vt 之间的关系;在我们的框架中,与此等价的作用由随附性的要求来承担。自主性的条件当然与我们的因果解耦概念有关。然而,正如参考文献[14]所显示的那样,条件互信息混淆了独特信息和协同信息,这可能导致不理想的情况:例如,可能是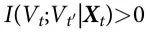 ,而同时
,而同时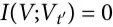 ,这意味着特征 Vt 的动力学只有在与整个系统 Xt 一起考虑时才是可见的,而不能单独考虑。我们的框架通过PID细化这个标准来避免这个问题,并且只使用独特信息来定义涌现。
,这意味着特征 Vt 的动力学只有在与整个系统 Xt 一起考虑时才是可见的,而不能单独考虑。我们的框架通过PID细化这个标准来避免这个问题,并且只使用独特信息来定义涌现。
我们的工作也受到 Hoel 及其同事在参考文献[7]中提出的框架的强烈影响。他们的方法是基于一个与系统的一个感兴趣特征相关的粗粒化函数F(·),即 Vt = F(Xt),这是我们对随附性的更普遍定义的一个特殊情况。当 Vt 和 Vt' 之间的依赖关系比 Xt 和 Xt' 之间的依赖关系“更强”时,即认为发生了涌现。请注意,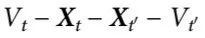 是一个马尔可夫链,由于数据处理不等式,从而有 I(Vt;Vt' )<= I(Xt;Xt' ) ;因此,直接使用香农互信息无法实现上述标准。相反,这个框架工作的重点是转移概率
是一个马尔可夫链,由于数据处理不等式,从而有 I(Vt;Vt' )<= I(Xt;Xt' ) ;因此,直接使用香农互信息无法实现上述标准。相反,这个框架工作的重点是转移概率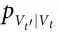 和
和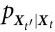 ,因此,互信息项是用最大熵分布而不是静态边际来计算的。通过这样做,Hoel 等人不是考虑系统实际做什么,而是考虑系统可能做的所有潜在转移。然而,在我们看来,这种方法并不适合评估动力学系统,因为它可能考虑到从未实际探索过的转移。静态分布和最大熵分布之间的差异在具有多个吸引子的非遍历系统中可能特别明显——见参考文献[50],整合信息论语境下的相关讨论。此外,这个框架依赖于对
,因此,互信息项是用最大熵分布而不是静态边际来计算的。通过这样做,Hoel 等人不是考虑系统实际做什么,而是考虑系统可能做的所有潜在转移。然而,在我们看来,这种方法并不适合评估动力学系统,因为它可能考虑到从未实际探索过的转移。静态分布和最大熵分布之间的差异在具有多个吸引子的非遍历系统中可能特别明显——见参考文献[50],整合信息论语境下的相关讨论。此外,这个框架依赖于对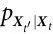 所编码的微观转移的确切了解,这在大多数应用中是不可能得到的。
所编码的微观转移的确切了解,这在大多数应用中是不可能得到的。
最后,Chang等人[4]考虑的随附变量对相应的微观底层是 "非平庸信息封闭的"(non-trivially informationally closed,NTIC)。NTIC的基础是基于将 X 划分为一个感兴趣的子系统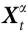 及其所处的由
及其所处的由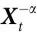 给出的“环境”。有趣的是,作为 NTIC 的系统要求 Vt 只对
给出的“环境”。有趣的是,作为 NTIC 的系统要求 Vt 只对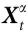 是随附的(即
是随附的(即  ),并且从环境到特征的信息流(即
),并且从环境到特征的信息流(即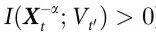 )由特征本身介导,因此,
)由特征本身介导,因此,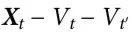 是一个马尔可夫链。因此,NTIC 要求特征对其自身的动力学有足够的统计,这类似于我们的因果解耦概念,但侧重于宏观特征、主体和其环境之间的互动。将我们的框架扩展到主动推理所涉及的主体-环境系统,是我们未来工作的一部分。
是一个马尔可夫链。因此,NTIC 要求特征对其自身的动力学有足够的统计,这类似于我们的因果解耦概念,但侧重于宏观特征、主体和其环境之间的互动。将我们的框架扩展到主动推理所涉及的主体-环境系统,是我们未来工作的一部分。
6.4 局限性和开放问题
本文提出的框架主要关注具有马尔可夫动力学的完全可观察系统的特征。然而,这些假设在处理实验数据——特别是生物和社会系统中的实验数据时往往不成立。作为一个重要扩展,未来的工作应该研究未观测变量对我们的度量的影响。例如,可以利用 Takens 的嵌入定理(embedding theorem)[53-55]或其他方法[56]。
我们的框架的一个有趣特点是,尽管它取决于PID和ΦID的选择,但它的实际应用通过“大型系统的实用标准”一节中讨论的标准是与这些选择无关的。然而,由于对微观冗余的高估,它们导致的代价是检测涌现的灵敏度有限;因此,当涌现很显著时,它们可以检测到,但在涌现更微小的情况下可能会遗漏。此外,这些标准不能排除涌现,因为它们是充分条件而不是必要条件。
因此,未来工作的另一个途径应该是寻找改进的实用标准,以便从数据中检测涌现。一个有趣的研究方向是为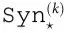 和
和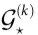 提供可扩展的近似,就像在“通过协同通道测量涌现”一节中介绍的,这可以在大型系统中计算。
提供可扩展的近似,就像在“通过协同通道测量涌现”一节中介绍的,这可以在大型系统中计算。
另一个有待解决的问题是,涌现能力如何受到系统的微观划分的变化所影响(参见“定义因果涌现”一节)。这方面有趣的应用包括感兴趣的元素受到混合过程影响的情景,例如脑电图的情况,其中每个电极检测混合的大脑信号源。其他有趣的问题包括研究对所有合理的微观划分具有非零涌现能力的系统,这可能对应于一种更强类型的涌现。
7. 结论
本文介绍了对因果涌现的一个定量定义,它利用多变量统计学原理解决了具有不可还原因果效应的随附宏观特征这一看似悖论的问题。我们提供了一个形式的量化理论,体现了许多归因于强涌现的原则,同时又是可测量的并符合现有的科学世界观。这项工作最重要的贡献也许在于,使关于涌现的讨论更接近于定量的实证科学研究,补充正在进行的关于这个主题的哲学研究。
在数学上,该理论基于部分信息分解(PID)框架[14],及其最近的扩展,整合信息分解(ΦID)[20]。该理论允许推导一个充分性标准,用于检测可扩展、易于从数据中计算,并且只基于香农互信息的涌现。我们在三个案例研究中说明了这些实践标准的使用,并得出结论:i)粒子碰撞是康威生命游戏中的一个涌现特征;ii)鸟群动力学是模拟鸟类的一个涌现特征;iii)大脑皮层中的运动行为表征来自神经活动的涌现。我们的理论,加上这些实际的标准,使新的数据驱动工具能够科学地解决广泛系统中的涌现猜想。
我们发展这一理论的最初目的,除了对复杂性理论的贡献之外,还在于帮助弥合心智和物质之间的鸿沟,并最终理解心智如何从物质中涌现。本文提供了形式原则,以探索心理学现象可能从集体神经模式中涌现,并以因果解耦的方式动态地相互作用——也许类似于在因果解耦一节中提到的 "统计幽灵"。简单地说:就像生命游戏中的粒子有它们自己的碰撞规则一样,我们想知道思维模式是否有它们自己的涌现动力学规律,相对于它们的底层神经基质在更大的尺度上运行(Kent[57]最近也探索了类似的想法)。重要的是,本文提出的理论不仅提供了概念性工具来严格构建这一猜想,而且还提供了实用工具来从数据中检验它。对这一猜想的探索将作为未来研究的一条令人兴奋的途径。
原文附录:
https://figshare.com/articles/journal_contribution/Provides_the_mathematical_proofs_of_our_results_and_further_details_about_simulations_and_preprocessing_pipelines_/13473042
参考文献
1. Gibb S, Findlay RH, Lancaster T. The Routledge Handbook of Emergence. Routledge; 2019.
2. Bedau M. Downward causation and the autonomy of weak emergence. Principia: An International Journal of Epistemology. 2002;6(1):5–50.
3. Chalmers DJ. Strong and Weak Emergence. Oxford University Press; 2006. p. 244–256.
4. Chang AY, Biehl M, Yu Y, Kanai R. Information Closure Theory of Consciousness. arXiv preprint arXiv:190913045. 2019;.
5. Bedau MA. Weak emergence. Noûs. 1997;31:375–399.
6. Seth AK. Measuring autonomy and emergence via Granger causality. Artificial Life. 2010;16(2):179–196. pmid:20067405
7. Hoel EP, Albantakis L, Tononi G. Quantifying causal emergence shows that macro can beat micro. Proceedings of the National Academy of Sciences. 2013;110(49):19790–19795. pmid:24248356
8. Hoel EP. When the map is better than the territory. Entropy. 2017;19(5):188.
9. Klein B, Hoel E. The emergence of informative higher scales in complex networks. Complexity. 2020;2020.
10. Pearl J. Causality: Models, Reasoning and Inference. Cambridge University Press; 2000.
11. Rosas F, Mediano PAM, Ugarte M, Jensen HJ. An information-theoretic approach to self-organisation: Emergence of complex interdependencies in coupled dynamical systems. Entropy. 2018;20(10). pmid:33265882
12. Bressler SL, Seth AK. Wiener–Granger causality: A well established methodology. Neuroimage. 2011;58(2):323–329. pmid:20202481
13. James RG, Ayala BDM, Zakirov B, Crutchfield JP. Modes of information flow. arXiv preprint arXiv:180806723. 2018;.
14. Williams PL, Beer RD. Nonnegative decomposition of multivariate information. arXiv preprint arXiv:10042515. 2010;.
15. Ay N, Polani D, Virgo N. Information decomposition based on cooperative game theory. arXiv preprint arXiv:191005979. 2019;.
16. Lizier JT, Bertschinger N, Jost J, Wibral M. Information decomposition of target effects from multi-source interactions: Perspectives on previous, current and future work. Entropy. 2018;20(4). pmid:33265398
17. James R, Emenheiser J, Crutchfield J. Unique information via dependency constraints. Journal of Physics A: Mathematical and Theoretical. 2018;.
18. Ince RA. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy. 2017;19(7):318.
19. Rosas F, Mediano P, Rassouli B, Barrett A. An operational information decomposition via synergistic disclosure. arXiv preprint arXiv:200110387. 2020;.
20. Mediano PA, Rosas F, Carhart-Harris RL, Seth AK, Barrett AB. Beyond integrated information: A taxonomy of information dynamics phenomena. arXiv preprint arXiv:190902297. 2019;.
21. Kraskov A, Stögbauer H, Grassberger P. Estimating mutual information. Physical Review E. 2004;69(6):066138.
22. Lizier JT. JIDT: An information-theoretic toolkit for studying the dynamics of complex systems. Frontiers in Robotics and AI. 2014;1:37.
23. McGill WJ. Multivariate information transmission. Psychometrika. 1954;19(2):97–116.
24. Timme N, Alford W, Flecker B, Beggs JM. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. Journal of Computational Neuroscience. 2014;36(2):119–140. pmid:23820856
25. Rosas FE, Mediano PAM, Gastpar M, Jensen HJ. Quantifying high-order interdependencies via multivariate extensions of the mutual information. Physical Review E. 2019;100:032305. pmid:31640038
26. Rassouli B, Rosas FE, Gündüz D. Data Disclosure under Perfect Sample Privacy. IEEE Transactions on Information Forensics and Security. 2019;.
27. Conway J. The game of life. Scientific American. 1970;223(4):4.
28. Reynolds CW. Flocks, Herds and Schools: A Distributed Behavioral Model. vol. 21. ACM; 1987.
29. Adamatzky A, Durand-Lose J. Collision-based computing. Springer; 2012.
30. Lizier J. The local information dynamics of distributed computation in complex systems. University of Sydney; 2010.
31. Wolfram S. A new kind of science. Wolfram Media; 2002.32.
Archer E, Park I, Pillow J. Bayesian and quasi-Bayesian estimators for mutual information from discrete data. Entropy. 2013;15(5):1738–1755.
33. Vicsek T. Universal patterns of collective motion from minimal models of flocking. In: 2008 IEEE Conference on Self-Adaptive and Self-Organizing Systems. IEEE; 2008. p. 3–11.
34. Chao Z, Nagasaka Y, Fujii N. Long-term asynchronous decoding of arm motion using electrocorticographic signals in monkey. Frontiers in Neuroengineering. 2010;3:3. pmid:20407639
35. Dehaene S. Consciousness and the brain: Deciphering how the brain codes our thoughts. Penguin; 2014.
36. Turkheimer FE, Hellyer P, Kehagia AA, Expert P, Lord LD, Vohryzek J, et al. Conflicting emergences. Weak vs. strong emergence for the modelling of brain function. Neuroscience & Biobehavioral Reviews. 2019;99:3–10. pmid:30684520
37. Corning PA. The synergism hypothesis: On the concept of synergy and its role in the evolution of complex systems. Journal of Social and Evolutionary Systems. 1998;21(2):133–172.
38. Rueger A. Physical emergence, diachronic and synchronic. Synthese. 2000;124(3):297–322.
39. Breuer HP, Petruccione F, et al. The Theory of Open Quantum Systems. Oxford University Press; 2002.
40. Smith TH, Vasilyev O, Abraham DB, Maciołek A, Schmidt M. Interfaces in confined Ising models: Kawasaki, Glauber and sheared dynamics. Journal of Physics: Condensed Matter. 2008;20(49):494237.
41. Corning PA. The re-emergence of “emergence”: A venerable concept in search of a theory. Complexity. 2002;7(6):18–30.
42. Anderson PW. More is different. Science. 1972;177(4047):393–396. pmid:17796623
43. Anderson PW. Basic notions of condensed matter physics. CRC Press; 2018.44.
Kauffman S, Clayton P. On emergence, agency, and organization. Biology and Philosophy. 2006;21(4):501–521.
45. Kauffman SA. A World Beyond Physics: The Emergence and Evolution of Life. Oxford University Press; 2019.
46. Bishop RC, Atmanspacher H. Contextual emergence in the description of properties. Foundations of Physics. 2006;36(12):1753–1777.
47. Atmanspacher H, beim Graben P. Contextual emergence. Scholarpedia. 2009;4(3):7997. pmid:19731148
48. Jensen HJ, Pazuki RH, Pruessner G, Tempesta P. Statistical mechanics of exploding phase spaces: Ontic open systems. Journal of Physics A: Mathematical and Theoretical. 2018;51(37):375002.
49. Mediano PAM, Seth AK, Barrett AB. Measuring Integrated Information: Comparison of Candidate Measures in Theory and Simulation. Entropy. 2018;21(1). pmid:33266733
50. Barrett A, Mediano P. The Phi measure of integrated information is not well-defined for general physical systems. Journal of Consciousness Studies. 2019;26(1-2):11–20.
51. Seth AK, Barrett AB, Barnett L. Granger causality analysis in neuroscience and neuroimaging. Journal of Neuroscience. 2015;35(8):3293–3297. pmid:25716830
52. Chang AYC, Biehl M, Yu Y, Kanai R. Information closure theory of consciousness. Frontiers in Psychology. 2020;11:1504. pmid:32760320
53. Takens F. Detecting strange attractors in turbulence. In: Dynamical Systems and Turbulence. Springer; 1981. p. 366–381.
54. Cliff OM, Prokopenko M, Fitch R. An information criterion for inferring coupling of distributed dynamical systems. Frontiers in Robotics and AI. 2016;3:71.
55. Tajima S, Kanai R. Integrated information and dimensionality in continuous attractor dynamics. Neuroscience of consciousness. 2017;2017(1):nix011. pmid:30042844
56. Wilting J, Priesemann V. Inferring collective dynamical states from widely unobserved systems. Nature Communications. 2018;9(1):1–7. pmid:29899335
57. Kent A. Toy Models of Top Down Causation. arXiv preprint arXiv:190912739. 2019.
(参考文献可上下滑动查看)
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
