首先看下进程地址空间示意图:

我们简单的说,从低地址到高地址,代码区和数据区,空洞,堆栈区。
在Linux内核源代码情景分析-内存管理之用户堆栈的扩展,我们申请了从堆栈区往下,数据区上面的页面。
在Linux内核源代码情景分析-内存管理之用户页面的换入,我们申请了用于换入/换出的页面。
在本文中,我们申请的是从数据区往上,堆栈区下面的页面。
我们通过一个实例来分析,brk(),见下图:
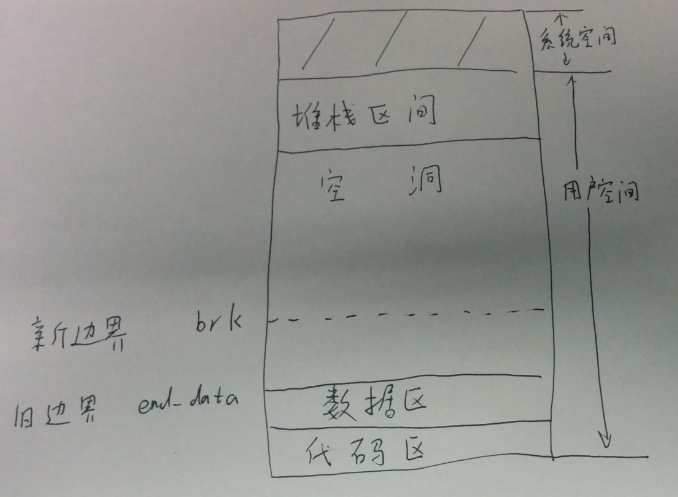
1、由于新边界比旧边界地址高,我们申请旧边界和新边界之间的页面。就是把对应的虚拟地址映射到物理页面。
brk对应的系统调用是sys_brk,代码如下:
asmlinkage unsigned long sys_brk(unsigned long brk)
{
unsigned long rlim, retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
down(&mm->mmap_sem);
if (brk < mm->end_code)//brk不能大于代码段末端地址
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {//目前新边界大于旧边界
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
goto set_brk;
goto out;
}
/* Check against rlimit.. */
rlim = current->rlim[RLIMIT_DATA].rlim_cur;
if (rlim < RLIM_INFINITY && brk - mm->start_data > rlim)//不能超过限制
goto out;
/* Check against existing mmap mappings. */
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))//看看是否与已经存在的虚拟空间有冲突
goto out;
/* Check if we have enough memory.. */
if (!vm_enough_memory((newbrk-oldbrk) >> PAGE_SHIFT))//是否有足够的空闲内存页面
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)//新边界大于旧边界,建立映射
goto out;
set_brk:
mm->brk = brk;//brk设置为新的边界
out:
retval = mm->brk;
up(&mm->mmap_sem);
return retval;
}
本例中,新边界大于旧边界,我们建立映射。do_brk代码如下:
unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma;
unsigned long flags, retval;
len = PAGE_ALIGN(len);
if (!len)
return addr;
/*
* mlock MCL_FUTURE?
*/
if (mm->def_flags & VM_LOCKED) {
unsigned long locked = mm->locked_vm << PAGE_SHIFT;
locked += len;
if (locked > current->rlim[RLIMIT_MEMLOCK].rlim_cur)
return -EAGAIN;
}
/*
* Clear old maps. this also does some error checking for us
*/
retval = do_munmap(mm, addr, len);//find_vm_intersection对冲突的检查,实际上检查的只是新区的高端,没有检查低端。对于低端的冲突是允许的,解决的办法是以新的映射为准,先通过do_munmap把原来的映射解除,再来建立映射
if (retval != 0)
return retval;
/* Check against address space limits *after* clearing old maps... */
if ((mm->total_vm << PAGE_SHIFT) + len
> current->rlim[RLIMIT_AS].rlim_cur)
return -ENOMEM;
if (mm->map_count > MAX_MAP_COUNT)
return -ENOMEM;
if (!vm_enough_memory(len >> PAGE_SHIFT))
return -ENOMEM;
flags = vm_flags(PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_FIXED|MAP_PRIVATE) | mm->def_flags;
flags |= VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
/* Can we just expand an old anonymous mapping? */
if (addr) {//先看看是否可以跟原有的区间合并
struct vm_area_struct * vma = find_vma(mm, addr-1);
if (vma && vma->vm_end == addr && !vma->vm_file &&
vma->vm_flags == flags) {
vma->vm_end = addr + len;
goto out;
}
}
/*
* create a vma struct for an anonymous mapping
*/
vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);//如果不能跟原有的区间合并,则分配vm_area_struct结构
if (!vma)
return -ENOMEM;
vma->vm_mm = mm;
vma->vm_start = addr;//起始地址
vma->vm_end = addr + len;//结束地址
vma->vm_flags = flags;
vma->vm_page_prot = protection_map[flags & 0x0f];
vma->vm_ops = NULL;
vma->vm_pgoff = 0;
vma->vm_file = NULL;
vma->vm_private_data = NULL;
insert_vm_struct(mm, vma);
out:
mm->total_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED) {//仅在对区间加锁时才调用make_pages_present
mm->locked_vm += len >> PAGE_SHIFT;
make_pages_present(addr, addr + len);//为新增的虚拟空间建立起对内存页面的映射
}
return addr;
}
make_pages_present,代码如下:
int make_pages_present(unsigned long addr, unsigned long end)
{
int write;
struct mm_struct *mm = current->mm;
struct vm_area_struct * vma;
vma = find_vma(mm, addr);
write = (vma->vm_flags & VM_WRITE) != 0;
if (addr >= end)
BUG();
do {
if (handle_mm_fault(mm, vma, addr, write) < 0)
return -1;
addr += PAGE_SIZE;
} while (addr < end);
return 0;
}
这里所用的方法很有趣,那就是对新区间中的每一个页面模拟一次缺页异常。
最后返回sys_brk,mm->brk设置为新的边界。
2、由于新边界比旧边界地址低,我们释放新边界和旧边界之前的页面。如下图:
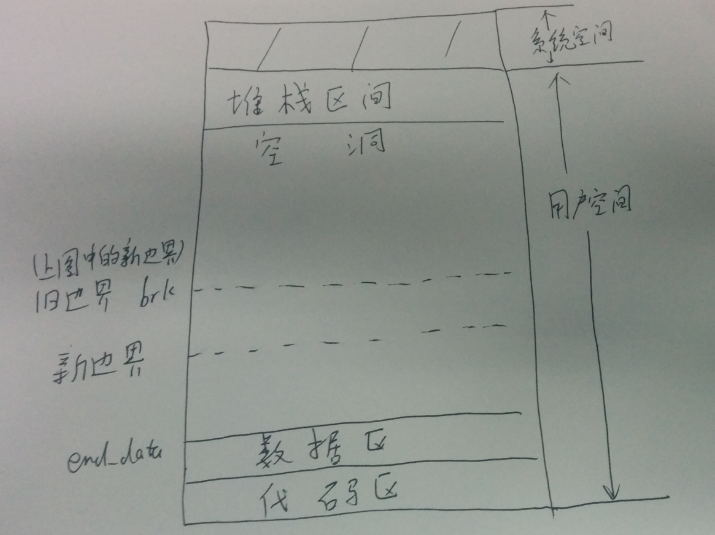
brk对应的系统调用是sys_brk,代码如下:
asmlinkage unsigned long sys_brk(unsigned long brk)
{
unsigned long rlim, retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
down(&mm->mmap_sem);
if (brk < mm->end_code)
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {//目前旧边界大于新边界
if (!do_munmap(mm, newbrk, oldbrk-newbrk))//解除映射
goto set_brk;
goto out;
}
/* Check against rlimit.. */
rlim = current->rlim[RLIMIT_DATA].rlim_cur;
if (rlim < RLIM_INFINITY && brk - mm->start_data > rlim)
goto out;
/* Check against existing mmap mappings. */
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
goto out;
/* Check if we have enough memory.. */
if (!vm_enough_memory((newbrk-oldbrk) >> PAGE_SHIFT))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
set_brk:
mm->brk = brk;//设置为新的边界
out:
retval = mm->brk;
up(&mm->mmap_sem);
return retval;
}
do_munmap解除映射,如下:
int do_munmap(struct mm_struct *mm, unsigned long addr, size_t len)
{
struct vm_area_struct *mpnt, *prev, **npp, *free, *extra;
if ((addr & ~PAGE_MASK) || addr > TASK_SIZE || len > TASK_SIZE-addr)
return -EINVAL;
if ((len = PAGE_ALIGN(len)) == 0)
return -EINVAL;
/* Check if this memory area is ok - put it on the temporary
* list if so.. The checks here are pretty simple --
* every area affected in some way (by any overlap) is put
* on the list. If nothing is put on, nothing is affected.
*/
mpnt = find_vma_prev(mm, addr, &prev);//试图找到结束地址高于addr的第一个区间
if (!mpnt)
return 0;
/* we have addr < mpnt->vm_end */
if (mpnt->vm_start >= addr+len)//如果该区间的起始地址也高于addr_len,说明落到了空洞中
return 0;
/* If we'll make "hole", check the vm areas limit */
if ((mpnt->vm_start < addr && mpnt->vm_end > addr+len)
&& mm->map_count >= MAX_MAP_COUNT)
return -ENOMEM;
/*
* We may need one additional vma to fix up the mappings ...
* and this is the last chance for an easy error exit.
*/
extra = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
if (!extra)
return -ENOMEM;
npp = (prev ? &prev->vm_next : &mm->mmap);
free = NULL;
spin_lock(&mm->page_table_lock);
for ( ; mpnt && mpnt->vm_start < addr+len; mpnt = *npp) {
*npp = mpnt->vm_next;
mpnt->vm_next = free;
free = mpnt;
if (mm->mmap_avl)
avl_remove(mpnt, &mm->mmap_avl);
}
mm->mmap_cache = NULL; /* Kill the cache. */
spin_unlock(&mm->page_table_lock);
/* Ok - we have the memory areas we should free on the 'free' list,
* so release them, and unmap the page range..
* If the one of the segments is only being partially unmapped,
* it will put new vm_area_struct(s) into the address space.
* In that case we have to be careful with VM_DENYWRITE.
*/
while ((mpnt = free) != NULL) {
unsigned long st, end, size;
struct file *file = NULL;
free = free->vm_next;
st = addr < mpnt->vm_start ? mpnt->vm_start : addr;
end = addr+len;
end = end > mpnt->vm_end ? mpnt->vm_end : end;
size = end - st;
if (mpnt->vm_flags & VM_DENYWRITE &&
(st != mpnt->vm_start || end != mpnt->vm_end) &&
(file = mpnt->vm_file) != NULL) {
atomic_dec(&file->f_dentry->d_inode->i_writecount);
}
remove_shared_vm_struct(mpnt);
mm->map_count--;
flush_cache_range(mm, st, end);
zap_page_range(mm, st, size);//解除若干连续页面的映射
flush_tlb_range(mm, st, end);
/*
* Fix the mapping, and free the old area if it wasn't reused.
*/
extra = unmap_fixup(mm, mpnt, st, size, extra);
if (file)
atomic_inc(&file->f_dentry->d_inode->i_writecount);
}
/* Release the extra vma struct if it wasn't used */
if (extra)
kmem_cache_free(vm_area_cachep, extra);
free_pgtables(mm, prev, addr, addr+len);//释放已经为空的页表所占的页面
return 0;
}
这里我们主要分析,zap_page_range,解除若干连续页面的映射;其他代码我们就假设是使vma->vm_end指向了新的边界,而不是旧的边界。
zap_page_range代码如下:
void zap_page_range(struct mm_struct *mm, unsigned long address, unsigned long size)
{
pgd_t * dir;
unsigned long end = address + size;
int freed = 0;
dir = pgd_offset(mm, address);
/*
* This is a long-lived spinlock. That's fine.
* There's no contention, because the page table
* lock only protects against kswapd anyway, and
* even if kswapd happened to be looking at this
* process we _want_ it to get stuck.
*/
if (address >= end)
BUG();
spin_lock(&mm->page_table_lock);
do {
freed += zap_pmd_range(mm, dir, address, end - address);
address = (address + PGDIR_SIZE) & PGDIR_MASK;
dir++;
} while (address && (address < end));
spin_unlock(&mm->page_table_lock);
/*
* Update rss for the mm_struct (not necessarily current->mm)
* Notice that rss is an unsigned long.
*/
if (mm->rss > freed)
mm->rss -= freed;
else
mm->rss = 0;
}
zap_pmd_range,如下:
static inline int zap_pmd_range(struct mm_struct *mm, pgd_t * dir, unsigned long address, unsigned long size)
{
pmd_t * pmd;
unsigned long end;
int freed;
if (pgd_none(*dir))
return 0;
if (pgd_bad(*dir)) {
pgd_ERROR(*dir);
pgd_clear(dir);
return 0;
}
pmd = pmd_offset(dir, address);
address &= ~PGDIR_MASK;
end = address + size;
if (end > PGDIR_SIZE)
end = PGDIR_SIZE;
freed = 0;
do {
freed += zap_pte_range(mm, pmd, address, end - address);
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while (address < end);
return freed;
}
zap_pte_range,代码如下:
static inline int zap_pte_range(struct mm_struct *mm, pmd_t * pmd, unsigned long address, unsigned long size)
{
pte_t * pte;
int freed;
if (pmd_none(*pmd))
return 0;
if (pmd_bad(*pmd)) {
pmd_ERROR(*pmd);
pmd_clear(pmd);
return 0;
}
pte = pte_offset(pmd, address);
address &= ~PMD_MASK;
if (address + size > PMD_SIZE)
size = PMD_SIZE - address;
size >>= PAGE_SHIFT;
freed = 0;
for (;;) {
pte_t page;
if (!size)
break;
page = ptep_get_and_clear(pte);//清空页表项,并返回原页表项
pte++;
size--;
if (pte_none(page))//如果页表项什么都没有,继续循环
continue;
freed += free_pte(page);//解除对内存页面以及盘上页面的使用
}
return freed;
}
free_pte,代码如下:
static inline int free_pte(pte_t pte)
{
if (pte_present(pte)) {//页表项一定有内容;如果页面没有在内存中,一定是交换页面,只要调用swap_free;如果页面在内存中,则往下执行,有可能是交换页面,也有可能是普通页面
struct page *page = pte_page(pte);//获得page结构指针
if ((!VALID_PAGE(page)) || PageReserved(page))
return 0;
/*
* free_page() used to be able to clear swap cache
* entries. We may now have to do it manually.
*/
if (pte_dirty(pte) && page->mapping)
set_page_dirty(page);//设置该页面page结构中的PG_dirty,并在相应的address_space结构中将其移入dirty_pages队列
free_page_and_swap_cache(page);//解除对交换页面或者普通页面的使用
return 1;
}
swap_free(pte_to_swp_entry(pte));//如果页面没有在内存,那就只调用swap_free
return 0;
}
free_page_and_swap_cache,解除对交换页面或者普通页面的使用,代码如下:
void free_page_and_swap_cache(struct page *page)
{
/*
* If we are the only user, then try to free up the swap cache.
*/
if (PageSwapCache(page) && !TryLockPage(page)) {//如果是交换页面
if (!is_page_shared(page)) {//当前进程是这个页面的最后一个用户,假设使用计数为2
delete_from_swap_cache_nolock(page);//从三个队列中脱离处理
}
UnlockPage(page);
}
page_cache_release(page);//普通页面现在使用计数为1,只调用这个函数,释放对应的页面;交换页面delete_from_swap_cache_nolock后使用计数也变为1,再调用这个函数,释放对应的页面
}
一个page数据结构,同时在三个队列,一是通过其队列头list链入某个换入/换出队列,即相应address_space结构中的clean_pages、dirty_pages以及locked_pages三个队列之一;二是通过其队列头lru链入某个LRU队列,即active_list、inactive_dirty_list或者某个inactive_clean_list之一;最后就是通过指针next_hash链入一个杂凑队列。
delete_from_swap_cache_nolock将页面从上述队列中脱离出来,代码如下:
void delete_from_swap_cache_nolock(struct page *page)
{
if (!PageLocked(page))
BUG();
if (block_flushpage(page, 0))
lru_cache_del(page);//lru脱链
spin_lock(&pagecache_lock);
ClearPageDirty(page);
__delete_from_swap_cache(page);//list,next_hash脱链
spin_unlock(&pagecache_lock);
page_cache_release(page);//使用计数减1,变成1了
}
返回free_page_and_swap_cache,调用page_cache_release。如果是普通页面现在使用计数为1,只调用这个函数,释放对应的页面;如果是交换页面,delete_from_swap_cache_nolock后使用计数也变为1,再调用这个函数,释放对应的页面。