ElasticSearch 8.9.0 开发模式安装
JDK安装
官方提供版本与JDK支持关系:https://www.elastic.co/cn/support/matrix#matrix_jvm
我们安装Elasticsearch 8.9.x,看到支持的最低JDK版本是17。
JDK(Windows/Mac含M1/M2 Arm原生JDK)安装,附各个版本JDK下载链接:https://es-cn.blog.csdn.net/article/details/126861940
Oracle JDK 官方下载:https://download.oracle.com/java/17/latest/jdk-17_windows-x64_bin.exe
按照默认设置进行安装。
安装之后我们默认的JDK版本会变成17,这是因为安装过程自动添加了环境变量。在Path环境变量中清理如下两个环境变量(一般在最上面,移动到下面也可以):
- C:\Program Files\Common Files\Oracle\Java\javapath
- C:\Program Files (x86)\Common Files\Oracle\Java\javapath
新建环境变量:
| 变量名 |
变量值 |
| ES_JAVA_HOME |
C:\Program Files\Java\jdk-17 |
ElasticSearch下载安装
ElasticSearch下载页面:https://www.elastic.co/cn/downloads/elasticsearch
ElasticSearch 8.9.0 版本下载:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.9.0-windows-x86_64.zip
注意:路径中不能存在空格
解压,修改config目录下elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
# 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的
# Elasticsearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看Elasticsearch集群,在逻辑上是个整体,你与任何一个节点的通信和与整个Elasticsearch集群通信是等价的。
# cluster.name可以确定你的集群名称,当你的elasticsearch集群在同一个网段中elasticsearch会自动的找到具有相同cluster.name的Elasticsearch服务。所以当同一个网段具有多个Elasticsearch集群时cluster.name就成为同一个集群的标识。
# Use a descriptive name for your cluster:
# 集群名称,默认是elasticsearch
cluster.name: elasticsearch
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名称同理,可自动生成也可手动配置.
node.name: es-node
#
# Add custom attributes to the node:
# 每个节点都可以定义一些与之关联的通用属性,用于后期集群进行碎片分配时的过滤
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# 可以指定Elasticsearch的数据存储目录,默认存储在es_home/data目录下
#path.data: /path/to/data
#
# Path to log files:
# 可以指定Elasticsearch的日志存储目录,默认存储在es_home/logs目录下
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
# 当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下,你应该保证它不会写入交换空间
# 锁定物理内存地址,防止elasticsearch内存被交换出去,也就是避免elasticsearch使用swap交换分区
bootstrap.memory_lock: true
#
# 确保ES_HEAP_SIZE参数设置为系统可用内存的一半左右
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
# 确保 ES_MIN_MEM 和 ES_MAX_MEM 环境变量设置为相同的值,以及机器有足够的内存分配给Elasticsearch
# 注意:内存也不是越大越好,一般64位机器,最大分配内存别才超过32G
#
# 当系统进行内存交换的时候,elasticsearch的性能很差
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
# 为Elasticsearch设置ip绑定,默认是127.0.0.1,也就是默认只能通过127.0.0.1 或者localhost才能访问
network.host: 127.0.0.1
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
# 为Elasticsearch设置自定义端口,默认是9200
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
#cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Allow wildcard deletion of indices:
#
#action.destructive_requires_name: false
# ---------------------------------- Xpack -----------------------------------
xpack.security.enabled: false
回到bin目录下,双击elasticsearch.bat启动
启动会占用系统物理内存的一半,建议根据实际情况调整jvm.options文件-Xms、-Xmx的值。
验证
访问:http://localhost:9200
ElasticSearch 8 默认启动Security,这对新手学习很不友好,实际上违背了Elastic官方设置开发模式的初衷,安全固然重要,但是没必要把门槛设置这么高。
参考:https://es-cn.blog.csdn.net/article/details/123936913
ElasticSearch目录结构
| 目录名称 |
描述 |
| bin |
可执行脚本文件,包括启动ElasticSearch服务、插件管理、函数命令等。 |
| config |
配置文件目录,如ElasticSearch配置、角色配置、jvm配置等。 |
| jdk |
7.x以后特有,自带的Java环境,8.x版本自带jdk 17 |
| lib |
ElasticSearch所依赖的Java库 |
| logs |
默认的日志文件存储路径,生产环境要求必须修改
|
| modules |
包含所有的ElasticSearch模块,如Cluster、Discovery、Indices等。 |
| plugins |
已经安装的插件的目录 |
| data |
默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境要求必须修改
|
SkyWalking
SkyWalking下载安装
SkyWalking官网:https://skywalking.apache.org/
Application performance monitor tool for distributed systems, especially designed for microservices, cloud native and container-based (Kubernetes) architectures.
SkyWalking 9.5.0 版本下载:https://dlcdn.apache.org/skywalking/9.5.0/apache-skywalking-apm-9.5.0.tar.gz
解压缩
注意:路径中不能存在空格
修改bin目录下startup.bat文件中
@REM
@REM Licensed to the Apache Software Foundation (ASF) under one or more
@REM contributor license agreements. See the NOTICE file distributed with
@REM this work for additional information regarding copyright ownership.
@REM The ASF licenses this file to You under the Apache License, Version 2.0
@REM (the "License"); you may not use this file except in compliance with
@REM the License. You may obtain a copy of the License at
@REM
@REM http://www.apache.org/licenses/LICENSE-2.0
@REM
@REM Unless required by applicable law or agreed to in writing, software
@REM distributed under the License is distributed on an "AS IS" BASIS,
@REM WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
@REM See the License for the specific language governing permissions and
@REM limitations under the License.
@echo off
setlocal
SET JAVA_HOME=%ES_JAVA_HOME%
call "%~dp0"\oapService.bat start
call "%~dp0"\webappService.bat start
endlocal
修改webapp目录下application.yml文件
serverPort: ${SW_SERVER_PORT:-8080}
修改为:
serverPort: ${SW_SERVER_PORT:-8888}
验证
访问:http://localhost:8888/
SkyWalking默认是使用H2作为存储的,我们修改为ElasticSearch。
修改config目录下application.yml文件
storage:
selector: ${SW_STORAGE:elasticsearch}
elasticsearch:
namespace: ${SW_NAMESPACE:"elasticsearch"}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:3000}
socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000}
responseTimeout: ${SW_STORAGE_ES_RESPONSE_TIMEOUT:15000}
numHttpClientThread: ${SW_STORAGE_ES_NUM_HTTP_CLIENT_THREAD:0}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
# trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
# trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Specify the settings for each index individually.
# If configured, this setting has the highest priority and overrides the generic settings.
specificIndexSettings: ${SW_STORAGE_ES_SPECIFIC_INDEX_SETTINGS:""}
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_STORAGE_ES_SUPER_DATASET_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index template
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
batchOfBytes: ${SW_STORAGE_ES_BATCH_OF_BYTES:10485760} # A threshold to control the max body size of ElasticSearch Bulk flush.
# flush the bulk every 5 seconds whatever the number of requests
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:5}
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:10000}
scrollingBatchSize: ${SW_STORAGE_ES_SCROLLING_BATCH_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
profileDataQueryBatchSize: ${SW_STORAGE_ES_QUERY_PROFILE_DATA_BATCH_SIZE:100}
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
# Enable shard metrics and records indices into multi-physical indices, one index template per metric/meter aggregation function or record.
logicSharding: ${SW_STORAGE_ES_LOGIC_SHARDING:false}
# Custom routing can reduce the impact of searches. Instead of having to fan out a search request to all the shards in an index, the request can be sent to just the shard that matches the specific routing value (or values).
enableCustomRouting: ${SW_STORAGE_ES_ENABLE_CUSTOM_ROUTING:false}
SpringBoot程序示例:https://download.csdn.net/download/liwenyang1992/88234045
启动参考下图:
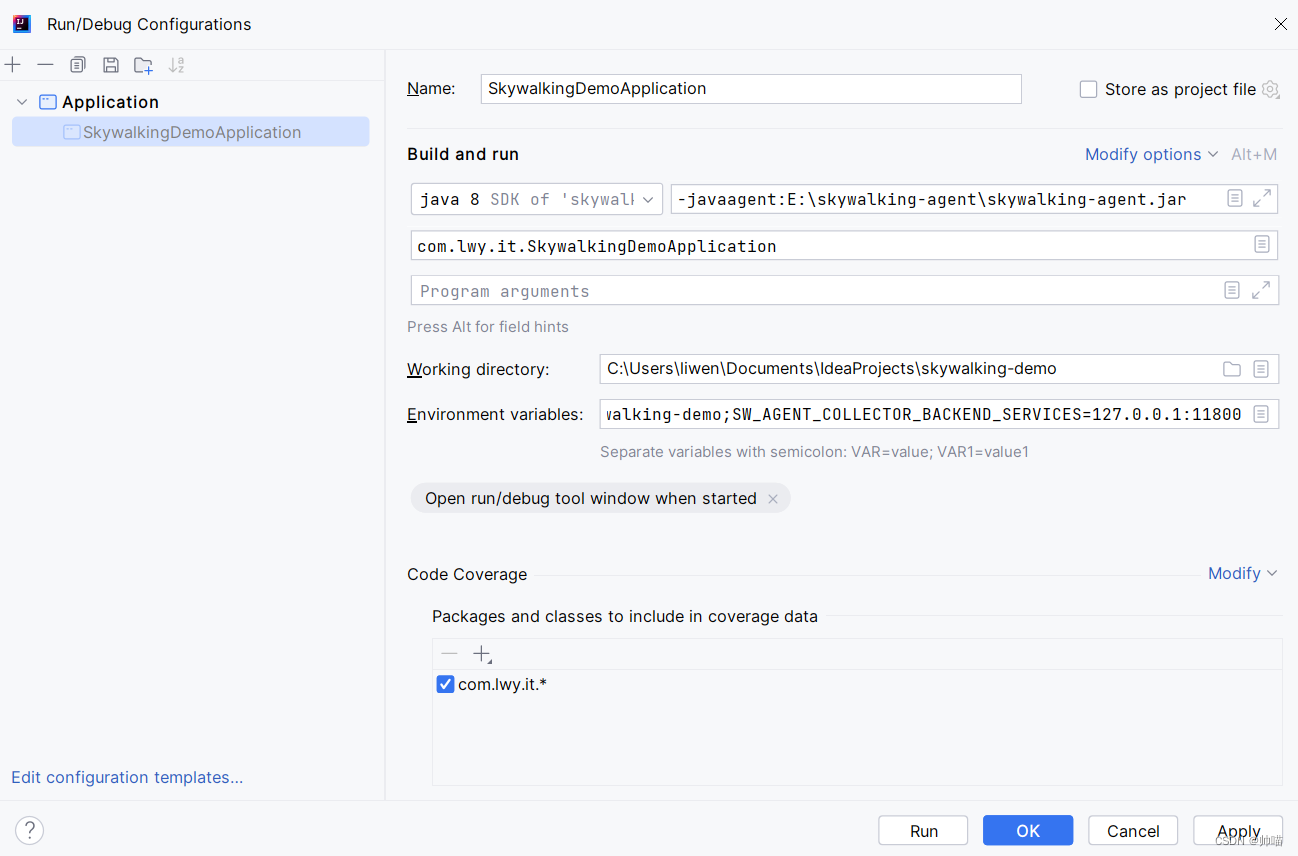
参考官方博客:https://skywalking.apache.org/zh/2020-04-19-skywalking-quick-start/
访问验证:http://localhost:8888/general
以命令行方式启动,通过Maven打包可执行jar包,编写start.bat内容如下:
SET SW_AGENT_NAME=skywalking-demo
SET SW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800
SET JAVA_AGENT=-javaagent:E:/skywalking-agent/skywalking-agent.jar
java -jar %JAVA_AGENT% -jar skywalking-demo.jar