HTTP响应详解

认识 "状态码" (status code)
状态码表示访问一个页面的结果
. (
是访问成功
,
还是失败
,
还是其他的一些情况
...).
以下为常见的状态码
.
200 OK 这 是一个最常见的状态码, 表示访问成功
.
抓包抓到的大部分结果都是 200
例如访问搜狗主页

注意
:
在抓包观察响应数据的时候
,
可能会看到压缩之后的数据
, 形如:

200 成功
404 访问资源不存在
403 访问的资源没有权限
表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆
直接访问, 就容易见到 403.
502 服务器挂了
504 服务器超时
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况.
这种情况在双十一等 "秒杀" 场景中容易出现, 平时不太容易见到.
302 重定向(浏览器会自动跳转到其他页面)
在登陆页面中经常会见到 302. 用于实现登陆成功后自动跳转到主页.
响应报文的
header
部分会包含一个
Location
字段
,
表示要跳转到哪个页面
理解 "重定向"
就相当于手机号码中的 "呼叫转移" 功能.
比如我本来的手机号是 186-1234-5678, 后来换了个新号码 135-1234-5678, 那么不需要让我的朋友知道新号码,只要我去办理一个呼叫转移业务, 其他人拨打 186-1234-5678 , 就会自动转移到 135-1234-5678上.
面试常考介绍你所了解的"状态码"
认识响应 "报头" (header)
响应报头的基本格式和请求报头的格式基本一致
.
类似于
Content
-
Type
,
Content
-
Length
等属性的含义也和请求中的含义一致
.
Content-Type
响应中的
Content-Type
常见取值有以下几种
:
-
text/html : body 数据格式是 HTML
-
text/css : body 数据格式是 CSS
-
application/javascript : body 数据格式是 JavaScript
-
application/json : body 数据格式是 JSON
认识响应 "正文" (body)
正文的具体格式取决于
Content-Type.
观察上面几个抓包结果中的响应部分
.
1) text/html
2) text/css
3) application/javascript
4) application/json
通过 form 表单构造 HTTP 请求
form (
表单
)
是
HTML
中的一个常用标签
.
可以用于给服务器发送
GET
或者
POST
请求
.
不要把
form
拼写成
from!!
form 发送 GET 请求
form
的重要参数
:
-
action: 构造的 HTTP 请求的 URL 是什么.
-
method: 构造的 HTTP 请求的 方法 是 GET 还是 POST (form 只支持 GET 和 POST).
input
的重要参数
:
-
type: 表示输入框的类型. text 表示文本, password 表示密码, submit 表示提交按钮.
-
name: 表示构造出的 HTTP 请求的 query string 的 key. query string 的 value 就是输入框的用户输入的内容.
-
value: input 标签的值. 对于 type 为 submit 类型来说, value 就对应了按钮上显示的文本.
对于开始标签来说, 可以写一些"属性"(键值对)
action 属性, 描述了构造的HTTP请求 url是什么等等
<form action="http://abcdef.com/myPath" method="GET">
<input type="text" name="userId">
<input type="text" name="classId">
<input type="submit" value="提交">
</form>

页面展示效果: 在输入框随便填写数据, 点击"提交", 此时就会构造出HTTP请求并发送出去

蓝色部分就是发送的请求 ,获得搜狗响应结果

详细看请求内容
 对应内容:
对应内容:

-
form 的 action 属性对应 HTTP 请求的 URL
-
form 的 method 属性对应 HTTP 请求的方法
-
input 的 name 属性对应 query string 的 key
-
input 的 内容 对应 query string 的 value
form 发送 POST 请求
修改上面的代码
,
把
form
的
method
修改为
POST
<form action="http://abcdef.com/myPath" method="POST">
<input type="text" name="userId">
<input type="text" name="classId">
<input type="submit" value="提交">
</form>
主要的区别
:
-
method 从 GET 变成了 POST
-
数据从 query string 移动到了 body 中
 form表单只支持get, post两种方法
form表单只支持get, post两种方法
通过 ajax 构造 HTTP 请求
现在更经常通过Ajax方式构造
从前端角度, 除了浏览器地址栏能构造 GET 请求, form 表单能构造 GET 和 POST 之外, 还可以通过 ajax 的方式来构造 HTTP 请求. 并且功能更强大.
ajax 全称 Asynchronous(异步) Javascript And XML, 是 2005 年提出的一种 JavaScript 给服务器发送 HTTP 请求的方式.
特点是可以不需要 刷新页面/页面跳转 就能进行数据传输.
在 JavaScript 中可以通过 ajax 的方式构造 HTTP 请求
Ajax是一种异步的通信方式, 通过代码, 发出了http请求, 请求发出去了之后, js代码就继续往下执行了, 当服务器的响应回来了之后, 就会自动的通知到咱们代码中, 进一步就能处理响应了
同步通信则不会继续往下执行


发送 GET 请求


和form方法的区别

发送 Post 请求
创建
test.html,
在
<script>
标签中编写以下代码
.
POSTMAN发送请求

HTTPS
HTTPS 是什么
HTTPS
也是一个应用层协议
.
是在
HTTP
协议的基础上引入了一个加密层
.
HTTP
协议内容都是按照文本的方式明文传输的
.
这就导致在传输过程中出现一些被篡改的情况
.
臭名昭著的
"
运营商劫持
"
下载一个 天天动听
未被劫持的效果
,
点击下载按钮
,
就会弹出天天动听的下载链接

已被劫持的效果, 点击下载按钮, 就会弹出 QQ 浏览器的下载链接
点击
"
下载按钮
",
其实就是在给服务器发送了一个
HTTP
请求
,
获取到的
HTTP
响应其实就包含了该
APP 的下载链接.
运营商劫持之后
,
就发现这个请求是要下载天天动听
,
那么就自动的把交给用户的响应给篡改成 "QQ
浏览器" 的下载地址了

不止运营商可以劫持, 其他的 黑客 也可以用类似的手段进行劫持, 来窃取用户隐私信息, 或者篡改内容.
试想一下, 如果黑客在用户登陆支付宝的时候获取到用户账户余额, 甚至获取到用户的支付密码.....
在互联网上, 明文传输是比较危险的事情!!!
HTTPS 就是在 HTTP 的基础上进行了加密, 进一步的来保证用户的信息安全~
HTTPS 的工作过程
既然要保证数据安全
,
就需要进行
"
加密
".
网络传输中不再直接传输明文了
,
而是加密之后的
"
密文
".
加密的方式有很多
,
但是整体可以分成两大类
:
对称加密
和
非对称加密
引入对称加密
对称加密其实就是通过同一个
"
密钥
" ,
把明文加密成密文
,
并且也能把密文解密成明文
.
一个简单的对称加密, 按位异或
假设 明文 a = 1234, 密钥 key = 8888
则加密 a ^ key 得到的密文 b 为 9834.
然后针对密文 9834 再次进行运算 b ^ key, 得到的就是原来的明文 1234.
(对于字符串的对称加密也是同理, 每一个字符都可以表示成一个数字)
当然, 按位异或只是最简单的对称加密. HTTPS 中并不是使用按位异或
最简单保证安全的做法, 引入对称密钥, 针对出传输的数据(HTTP的header和body)进行加密

每个人用的秘钥都必须是不同的(
如果是相同那密钥就太容易扩散了
,
黑客就也能拿到了
).
因此服务器就需要维护每个客户端和每个密钥之间的关联关系,
比较理想的做法
,
就是能在客户端和服务器建立连接的时候
,
双方
协商
确定这次的密钥是啥
但是如果直接把密钥明文传输
,
那么黑客也就能获得密钥了
~~
此时后续的加密操作就形同虚设了
.
因此密钥的传输也必须加密传输
!
但是要想对密钥进行对称加密
,
就仍然需要先协商确定一个
"
密钥的密钥
".
这就成了
"
先有鸡还是先有蛋
" 的问题了.
此时密钥的传输再用对称加密就行不通了
.
就需要引入
非对称加密
引入非对称加密
非对称加密要用到两个密钥
,
一个叫做
"
公钥
",
一个叫做
"
私钥
".
公钥和私钥是配对的
.
最大的缺点就是
运算速度非常慢,比对称加密要慢很多.
因此我们这里使用的非对称加密只是针对于加密明文的密钥
我们把公钥想向成保险柜, 私钥想象成钥匙
- 当我们客户端和服务器建立连接时, 服务器将保险柜(公钥)传递给客户端, (钥匙)私钥则保留在服务器
- 客户端在本地生成对称密钥, 加对称密钥放入保险柜(用公钥加密)中, 之后发送给服务端
- 因为保险柜的钥匙(私钥)始终保留在服务端手中, 所以经过公钥加密过的数据(对称密钥)完全不怕被截获
- 服务端用私钥解密被公钥加密过的对称密钥之后, 服务器和客户端都有了对称密文, 并且没有被半路劫持(锁在保险柜中)
- 明文被对称密钥加密成密文, 后续通信直接发送密文就可以了
那么问题又来了:
-
客户端如何获取到公钥?
-
客户端如何确定这个公钥不是黑客伪造的?
引入证书
在客户端和服务器刚一建立连接的时候
,
服务器给客户端返回一个
证书
.
这个证书包含了刚才的公钥
,
也包含了网站的身份信息
.
这个证书就好比人的身份证, 作为这个网站的身份标识. 搭建一个 HTTPS 网站要在CA机构先申请一 个证书. (类似于去公安局办个身份证).

解决中间人攻击的关键, 需要让客户端能够确认当前收到的公钥, 确实是服务器返回的, 而不是黑客伪造的
于是引入证书机制
需要一个第三方的认证机构, 通过第三方机构作保, 确保当前的公钥是有效的
客户端在尝试和服务器建立连接的时候, 服务器会向第三方公证机构申请一个证书,
证书包含很多属性 : 比如网站的域名, 证书过期时间, 还有数字签名等
数字签名即对整个证书的数据计算hash值, 得到的结果具有唯一性, 若是证书数据发生变动(被黑客修改)就会导致计算出的hash值不同
上边我们讲过服务器会生成一个非对称密钥用于加密对称密钥(对称密钥加密明文), 因此需要把服务器公钥传递给客户端, 而传递的方法就是将服务端公钥放入证书中.
因此我们在申请到证书之后, 还会向其中加入服务器生成的公钥, 当然 随后数字签名对应修改
最终得到完整的证书
但是我们发现, 若是黑客将证书中的公钥修改, 再修改证书的数字签名, 同样会发生劫持情况.
所以数字签名不能传输明文
为了避免这一情况, 每个第三方公证机构会有一个单独的公钥, 私钥,
- 机构私钥 : 第三方公证机构在向服务器发送证书时, 还会发送一个公证机构私钥
- 机构公钥 : 不通过网络传递, 直接系统内置, 如Windows系统会内置各种知名机构的公钥
那么有了私钥, 公钥之后能干什么呢?
服务器使用收到的机构私钥 加密 证书中的数字签名
然后客户端通过操作系统里已经存的了的证书发布机构的公钥进行解密, 还原出原始的数字签名明文, 再进行校验.
那如何校验呢?
解析出来的数字签名作为哈希值1, 这个肯定是服务端发送的正确签名, 我们只需要在按照服务器计算数字签名的方法再计算一次数字签名作为哈希值2, 两者比较 若相等就是未被修改过的证书
注意: 虽然黑客能获得CA认证机构的公钥, 能够解析出数字签名, 但黑客没有机构私钥, 改完之后没法重新加密, 客户端可以直接发现
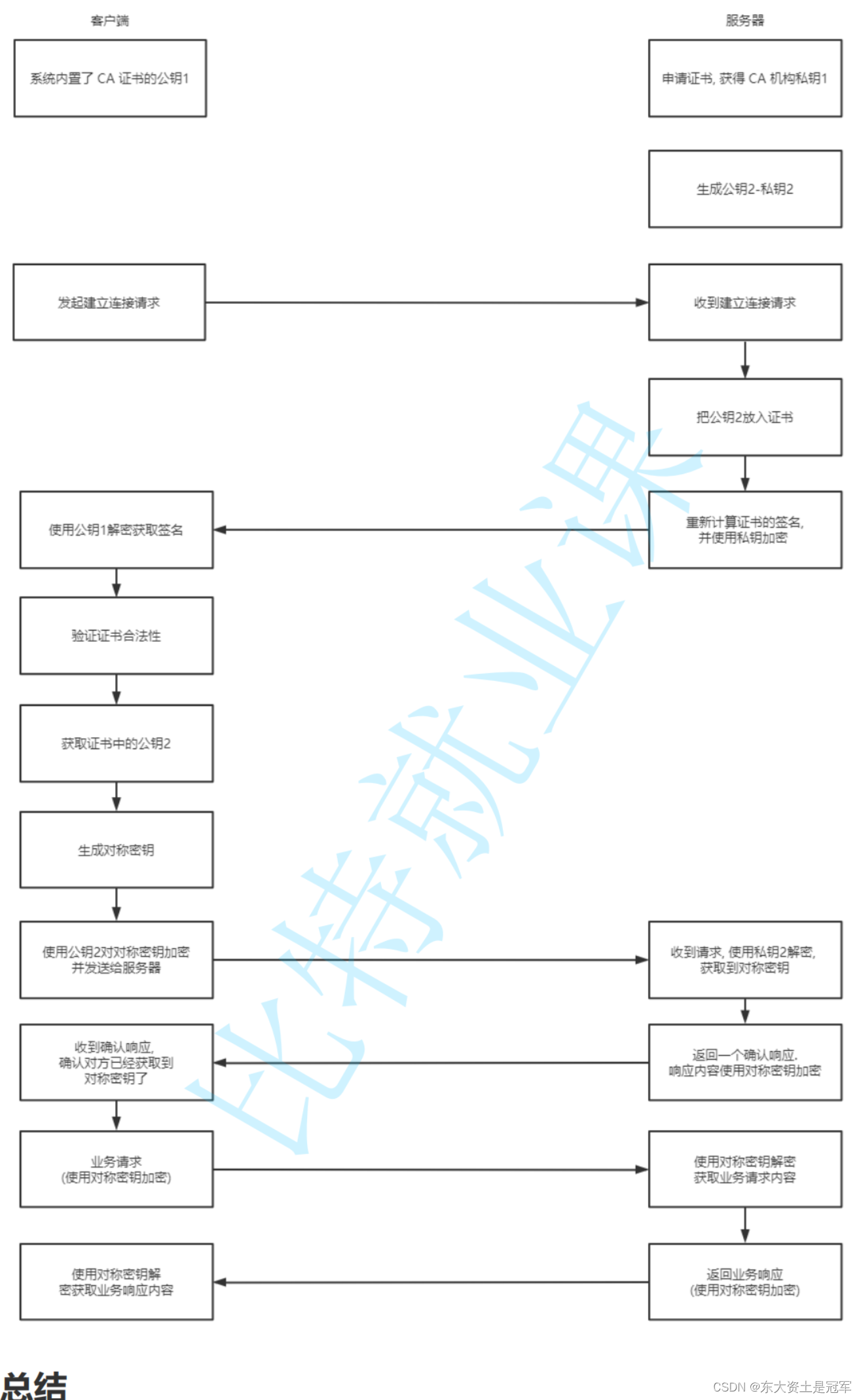
完整流程
左侧都是客户端做的事情
,
右侧都是服务器做的事情
 总结
总结
HTTPS 工作过程中涉及到的密钥有三组
第一组
(
非对称加密
)
:
用于校验证书是否被篡改
.
服务器持有私钥
(
私钥在注册证书时获得
),
客户端持有公钥(
操作系统包含了可信任的
CA
认证机构有哪些
,
同时持有对应的公钥
).
服务器使用这个私钥对证书的签名进行加密.
客户端通过这个公钥解密获取到证书的签名
,
从而校验证书内容是否是篡改过
.
第二组
(
非对称加密
):
用于协商生成对称加密的密钥
.
服务器生成这组 私钥
-
公钥 对
,
然后通过证书把公钥传递给客户端.
然后客户端用这个公钥给生成的对称加密的密钥加密
,
传输给服务器
,
服务器通过私钥解密获取到对称加密密钥.
第三组
(
对称加密
):
客户端和服务器后续传输的数据都通过这个对称密钥加密解密
.
其实一切的关键都是围绕这个对称加密的密钥
.
其他的机制都是辅助这个密钥工作的
.
- 第二组非对称加密的密钥是为了让客户端把这个对称密钥传给服务器.
- 第一组非对称加密的密钥是为了让客户端拿到第二组非对称加密的公钥