Spark安装配置
Spark基本概念
Spark基础知识(PySpark版)
Spark机器学习(PySpark版)
Spark流数据处理(PySpark版)
Spark 基本概念
Apache Spark是一个开源的、强大的分布式查询和处理引擎。
Apache Spark允许用户读取、转换、聚合数据,还可以轻松地训练和部署复杂的统计模型。提供了简明、一致的Java、Scala、Python、R和SQL API。
此外,Apache Spark还提供了几个已经实现并调优过的算法、统计模型和框架:
- 为机器学习提供的MLlib和ML
- 为图形处理提供的GraphX和GraphFrames
- 以及Spark Streaming(DStream和Structured),基于微批量方式的计算和处理,可以用于处理实时的流数据。
Hadoop 生态
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
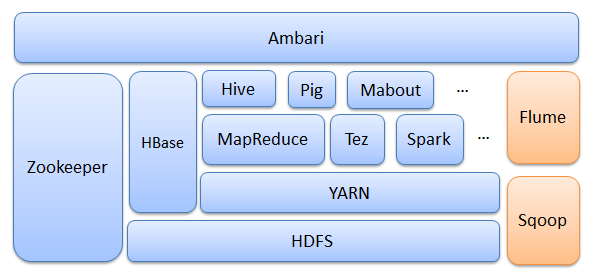
- Ambari:安装、部署、配置和管理工具
- HBase:实时分布式数据库
- HDFS:分布式文件系统
- YARN:集群资源管理系统
- MapReduce:分布式的离线并行计算框架
- Zookeeper:分布式协作服务
- Hive:数据仓库
- Pig:数据流处理
- Mahout:数据挖掘库
- Tez:TAG(有向无环图)计算框架
- Flume:收集各个应用系统和框架的日志
- Sqoop:将关系型数据库中的数据与 HDFS上的数据进行相互导入导出
Spark 生态
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 拥有Hadoop MapReduce所具有的优点,但不同的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
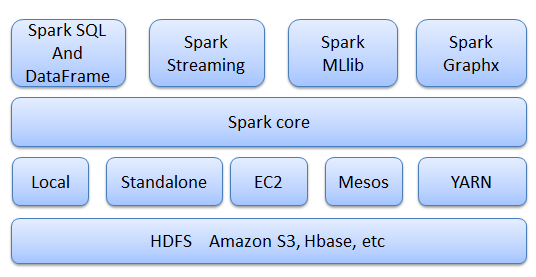
- Spark core:包含Spark的基本功能和 API
- Spark SQL:用于对结构化数据(DataFrame)进行处理
- Spark Streaming:用于进行实时流数据的处理
- Spark MLLib:分布式环境下的机器学习库
- Spark Graphx:控制图、并行图操作和计算的一组算法和工具的集合
Spark 基本架构
一个完整的Spark应用程序(Application),在提交集群运行时,它涉及到如下图所示的组件。
Spark 一般包括一个主节点(任务控制节点)和多个从节点(工作节点),每个任务(Job)会被切分成多个阶段(Stage),每个阶段并发多线程执行,结束后返回到主节点。
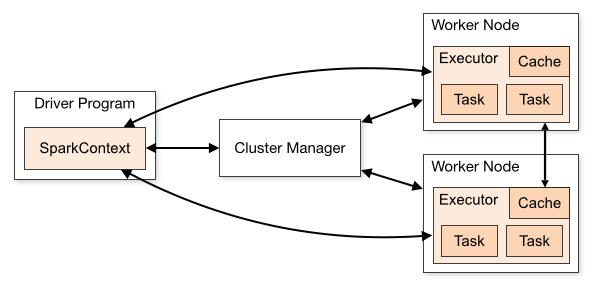
- Driver Program:(主节点或任务控制节点)执行应用程序主函数并创建SparkContext对象,SparkContext配置Spark应用程序的运行环境,并负责与不同种类的集群资源管理器通信,进行资源申请、任务的分配和监控等。当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
- Cluster Manager:(集群资源管理器)指的是在集群上进行资源(CPU,内存,宽带等)调度和管理。可以使用Spark自身,Hadoop YARN,Mesos等不同的集群管理方式。
- Worker Node:从节点或工作节点。
- Executor:每个工作节点上都会驻留一个Executor进程,每个进程会派生出若干线程,每个线程都会去执行相关任务。
- Task:(任务)运行在Executor上的工作单元。
Spark运行基本流程
RDD(Resilient Distributed Dataset)是Spark框架中的核心概念,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。
Spark通过分析各个RDD的依赖关系生成有向无环图DAG(Directed Acyclic Graph),通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage进行任务优化。
spark-submit提交Spark应用程序后,其执行流程如下:
- 创建SparkContext对象,然后SparkContext会向Clutser Manager(例如Yarn、Standalone、Mesos等)申请资源。
- 资源管理器在worker node上创建executor并分配资源(CPU、内存等)
- SparkContext启动DAGScheduler,将提交的作业(Job)转换成若干Stage,各Stage构成DAG(Directed Acyclic Graph有向无环图),各个Stage包含若干相task,这些task的集合被称为TaskSet
- TaskSet发送给TaskSet Scheduler,TaskSet Scheduler将Task发送给对应的Executor,同时SparkContext将应用程序代码发送到Executor,从而启动任务的执行
- Executor执行Task,完成后释放相应的资源。

- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作构成的DAG图。
- Stages:是Job的基本调度单位(DAGScheduler),一个Job会分解为多组Stage,每组Stage包含多组任务(Task),称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系(最耗费资源)的任务组成的任务集。
- Tasks:负责Stage的任务分发(TaskScheduler),Task分发遵循基本原则:计算向数据靠拢,避免不必要的磁盘I/O开销。
弹性分布式数据集(RDD)
在Spark里,对数据的所有操作,基本上就是围绕RDD来的,譬如创建、转换、求值等等。某种意义上来说,RDD变换操作是惰性的,因为它们不立即计算其结果,RDD的转换操作会生成新的RDD,新的RDD的数据依赖于原来的RDD的数据,每个RDD又包含多个分区。那么一段程序实际上就构造了一个由相互依赖的多个RDD组成的有向无环图(DAG)。并通过在RDD上执行行动将这个有向无环图作为一个Job提交给Spark执行。
该延迟执行会产生更多精细查询:DAGScheduler可以在查询中执行优化,包括能够避免shuffle数据。
RDD支持两种类型的操作:
-
变换(Transformation) :调用一个变换方法应用于RDD,不会有任何求值计算,返回一个新的RDD。
-
行动(Action) :它指示Spark执行计算并将结果返回。
窄依赖与宽依赖
在前面讲的Spark编程模型当中,我们对RDD中的常用transformation与action 函数进行了讲解,我们提到RDD经过transformation操作后会生成新的RDD,前一个RDD与tranformation操作后的RDD构成了lineage关系,也即后一个RDD与前一个RDD存在一定的依赖关系,根据tranformation操作后RDD与父RDD中的分区对应关系,可以将依赖分为两种:
-
窄依赖(narrow dependency):变换操作后的RDD仅依赖于父RDD的固定分区,则它们是窄依赖的。
-
宽依赖(wide dependency):变换后的RDD的分区与父RDD所有的分区都有依赖关系(即存在shuffle过程,需要大量的节点传送数据),此时它们就是宽依赖的。
如下图所示:
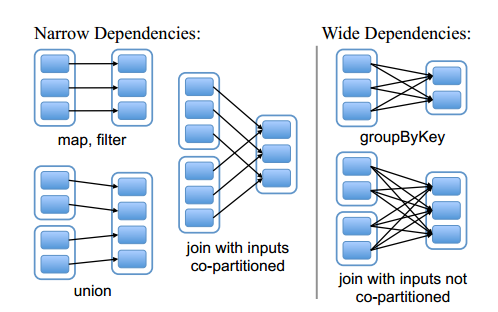
图中的实线空心矩形代表一个RDD,实线空心矩形中的带阴影的小矩形表示分区(partition)。从上图中可以看到, map,filter,union等transformation是窄依赖;而groupByKey是宽依赖;join操作存在两种情况,如果分区仅仅依赖于父RDD的某一分区,则是窄依赖的,否则就是宽依赖。
优化:fork/join
宽依赖需要进行shuffle过程,需要大量的节点传送数据,无法进行优化;而所有窄依赖则不需要进行I/O传输,可以优化执行。
当RDD触发相应的action操作后,DAGScheduler会根据程序中的transformation类型构造相应的DAG并生成相应的stage,所有窄依赖构成一个stage,而单个宽依赖会生成相应的stage。
参考链接: