*免责声明:
1\此方法仅提供参考
2\搬了其他博主的操作方法,以贴上路径.
3*
场景一:什么是Attention
场景二:Attention在cnn上的作用
场景三:常见的Attention机制
场景四:Attention机制的创新思路
场景五:yolov5中进行Attention结构插入实验
…
场景一:什么是Attention
更多attention细节—>神经网络与深度学习理论教程二,tensorflow2.0教程,rnn
一文看懂 Attention(本质原理+3大优点+5大类型)
深度学习中的注意力机制
1.1 基础



1.2 本质思想
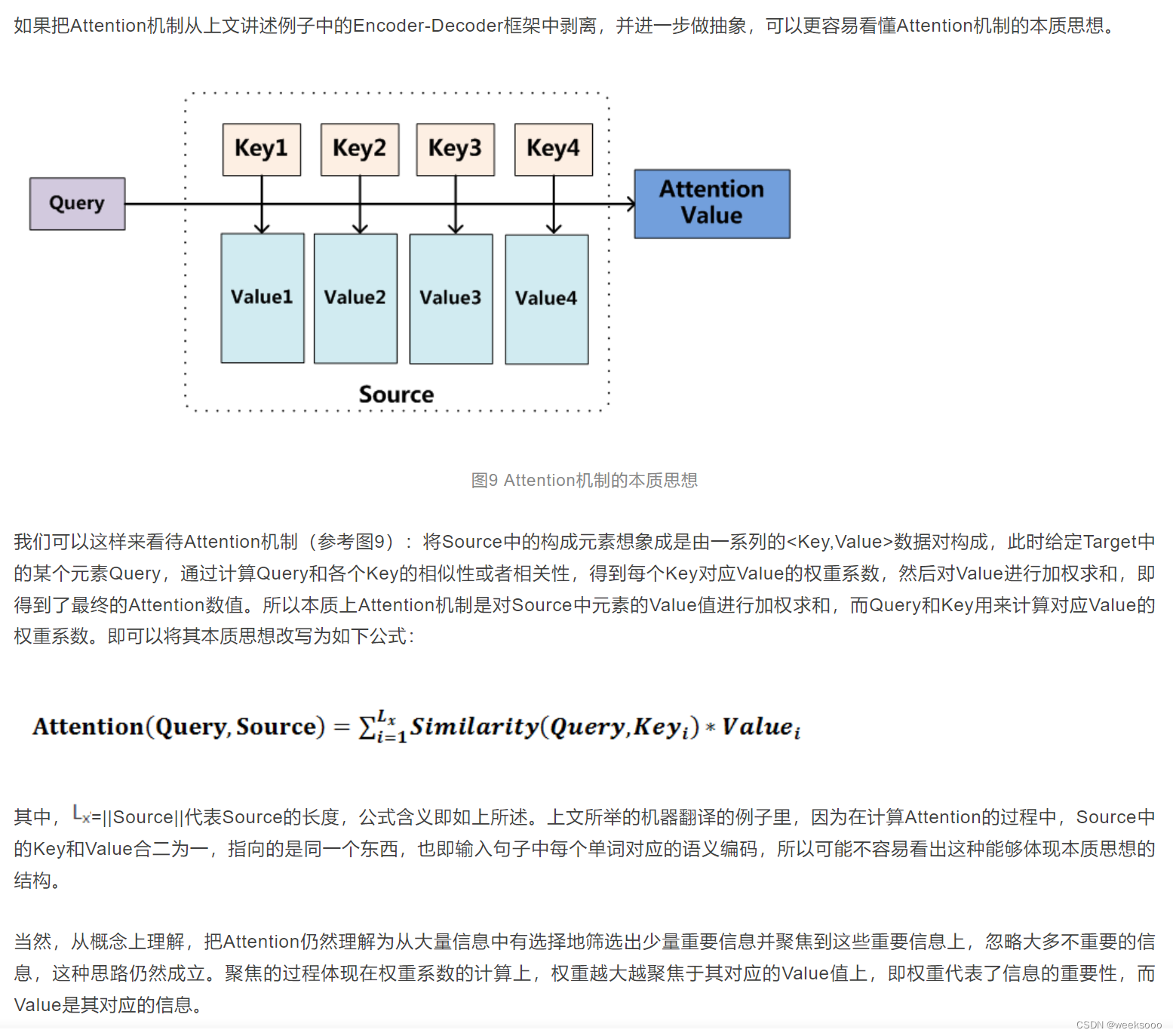
1.3 Attention计算过程
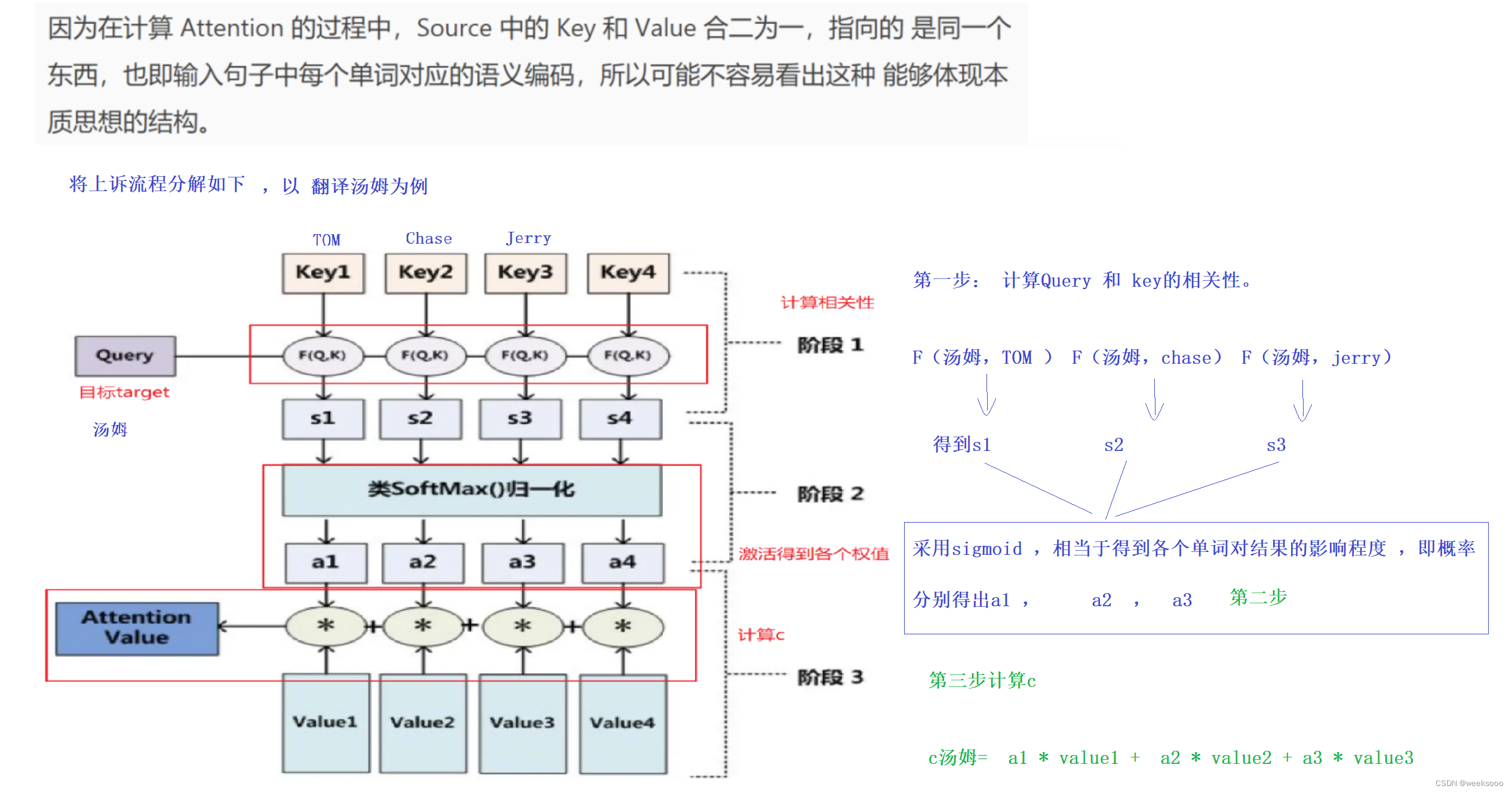


…
场景二:Attention在cnn上的作用
1.1 Attention机制的好处

1.2 Attention机制的种类



1.3 Attention机制在CNN中的应用
Attention in CNN



…
场景三:常见的Attention机制
注意力机制Attention论文整理收藏(最全,附代码,持续更新)
CV中的Attention和Self-Attention
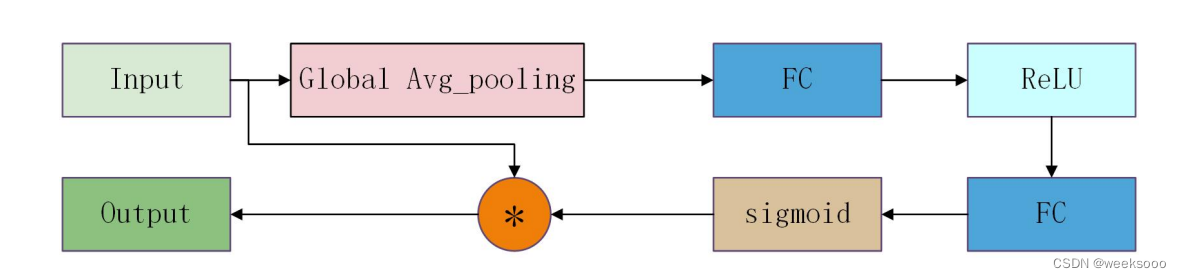
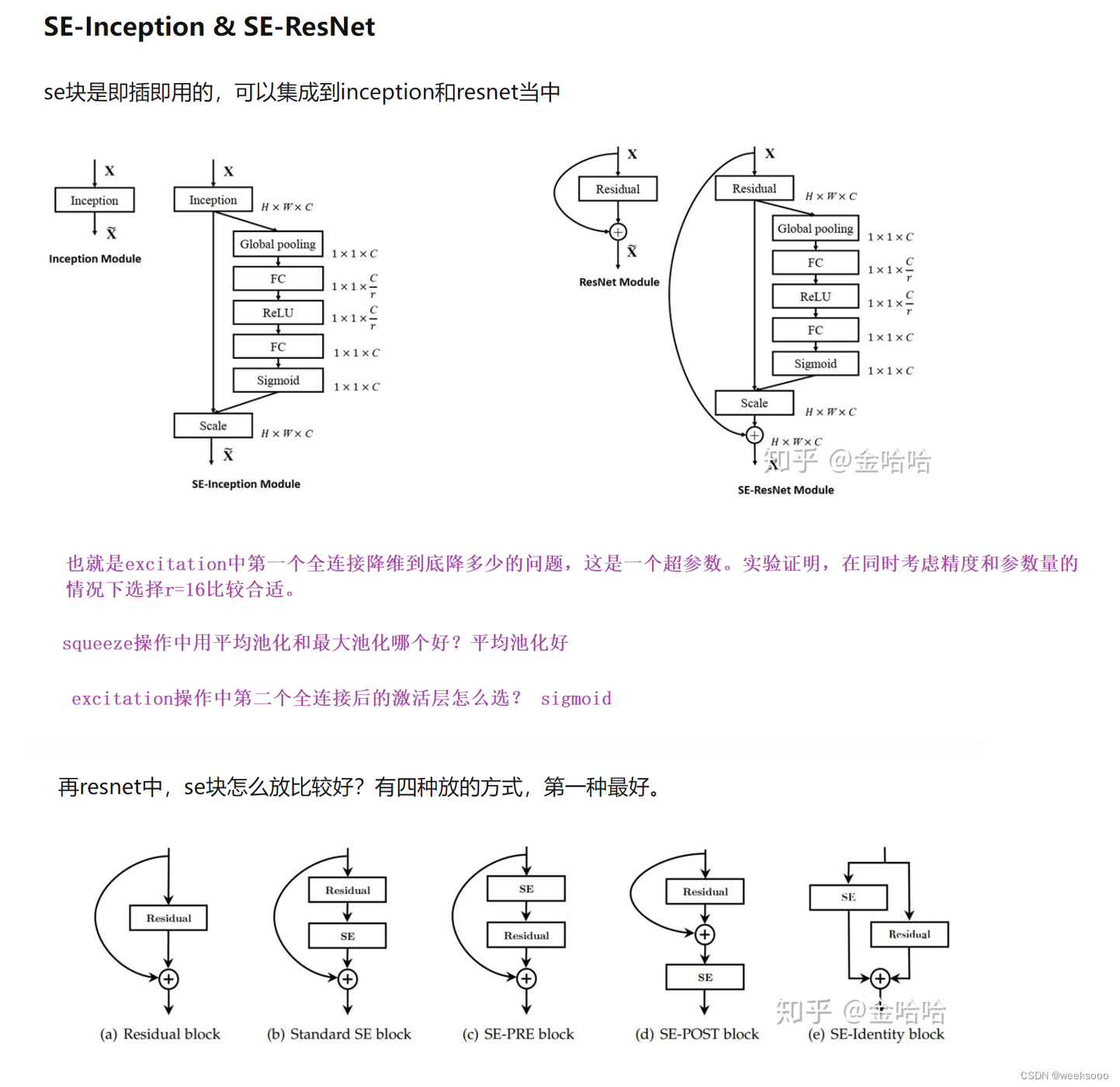
1.1 SENet
SENet论文地址
通道上的注意力:SENet论文笔记
大致流程
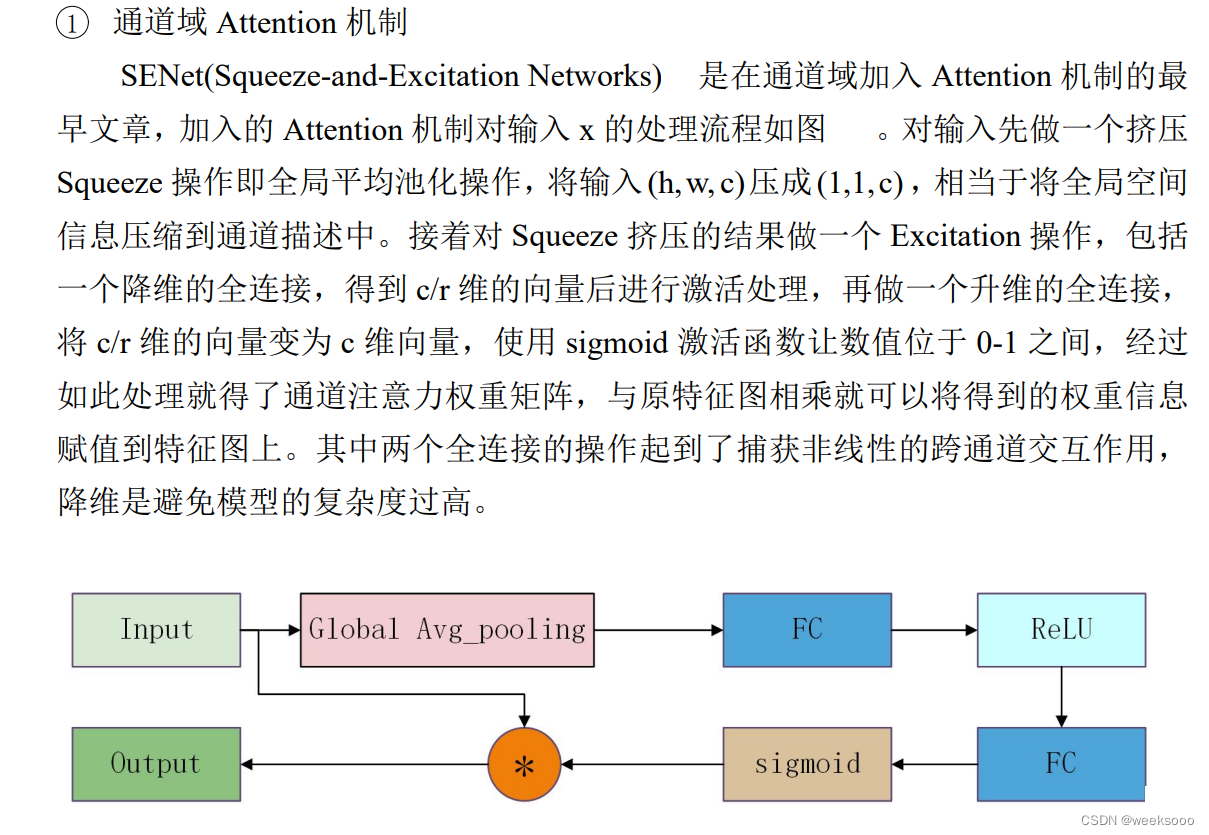
详细介绍

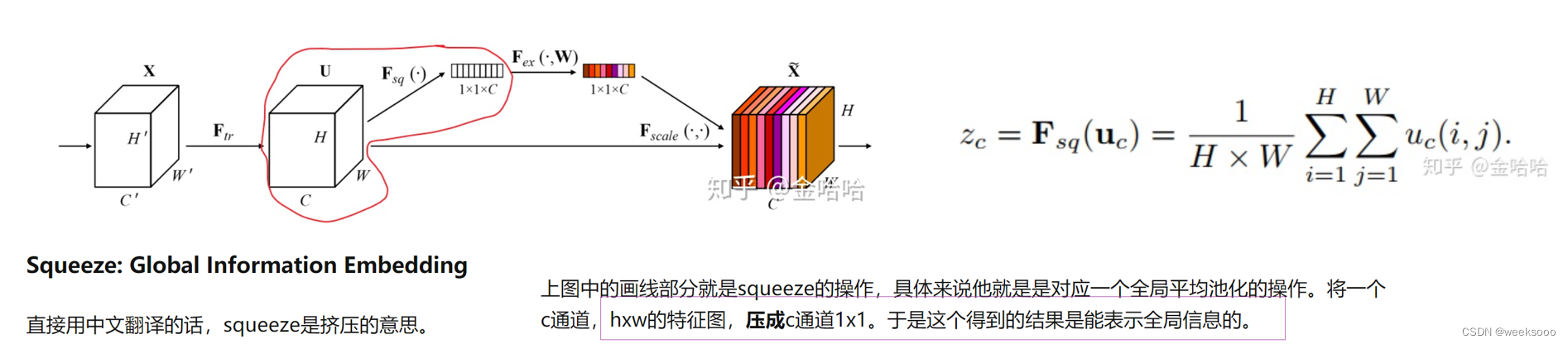

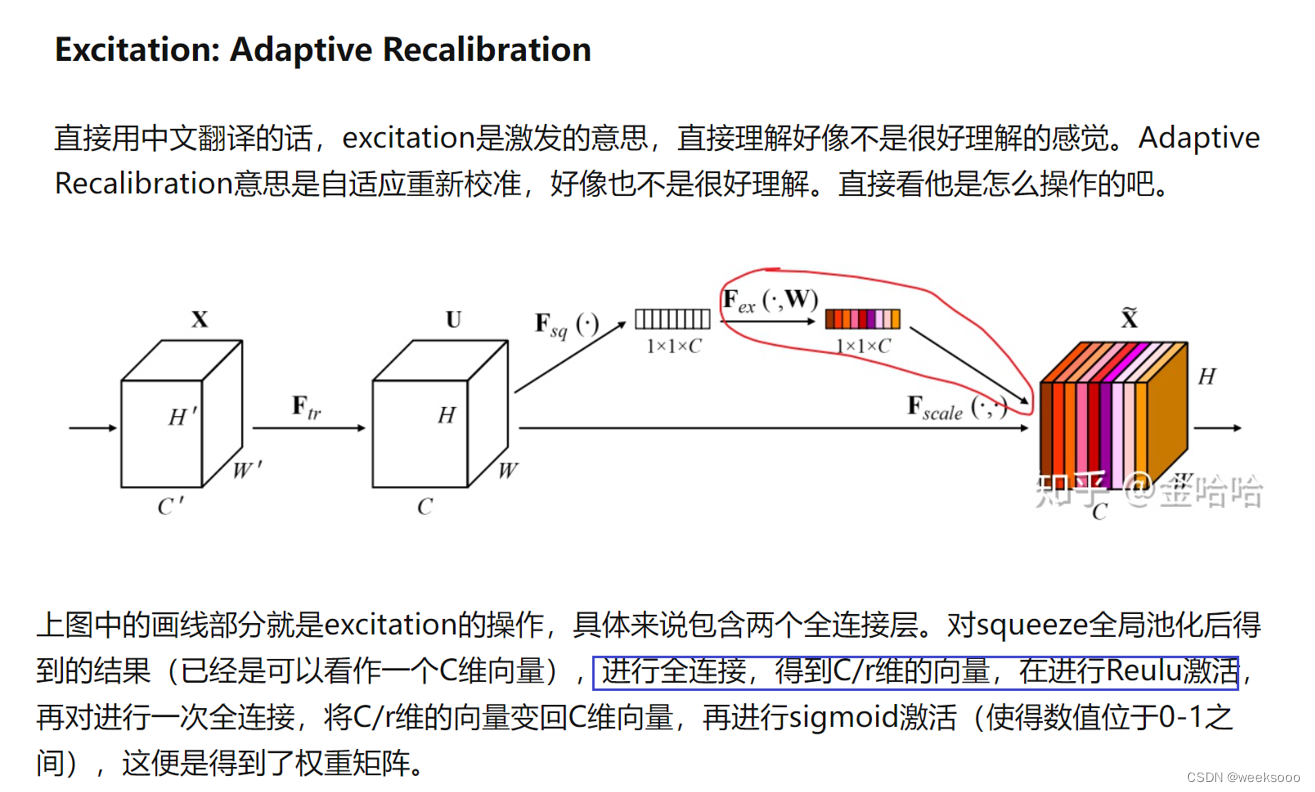

应用实例
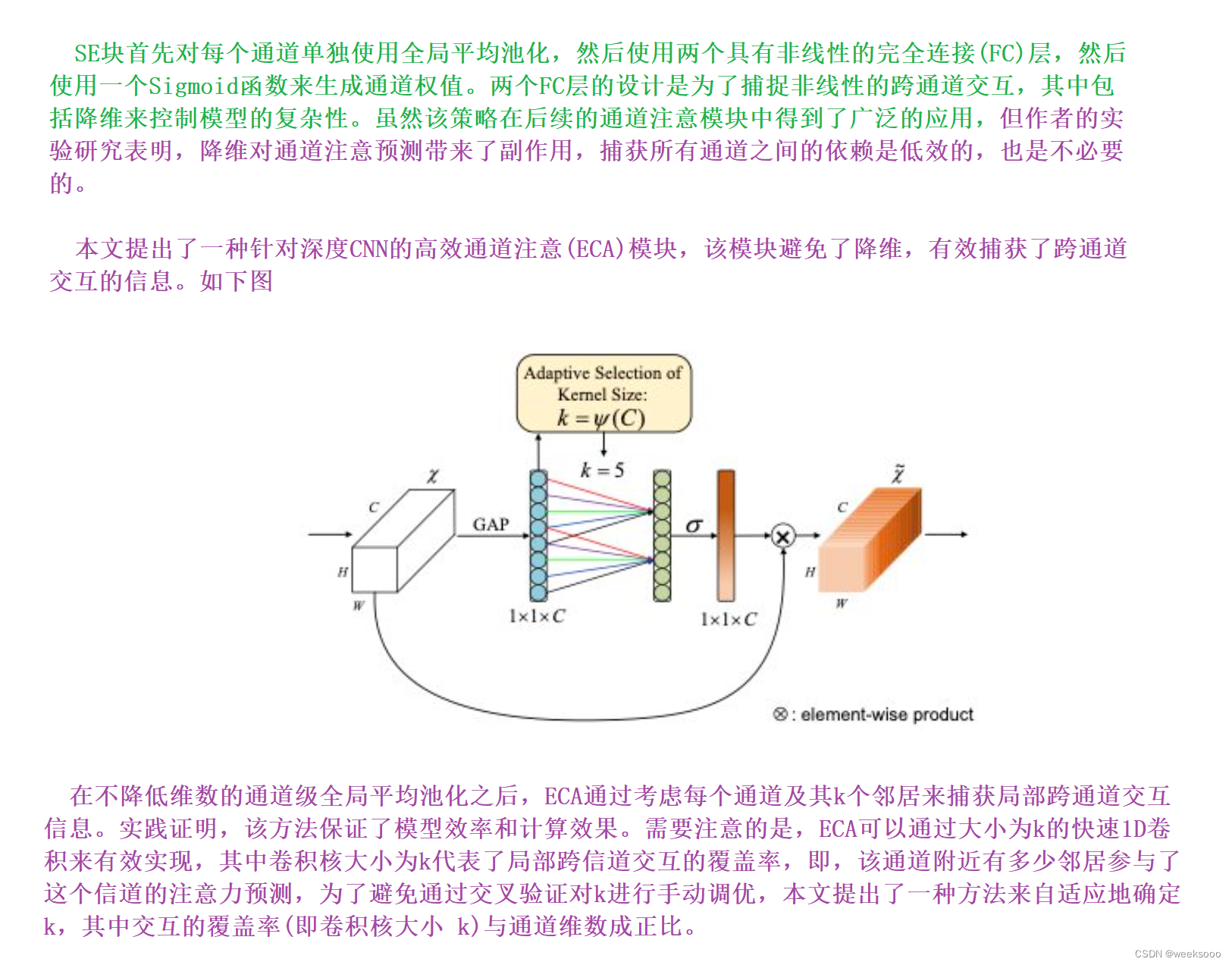
1.2 ECANet
ECANet论文地址
通道注意力超强改进,轻量模块ECANet来了!即插即用,显著提高CNN性能|已开源
大致流程
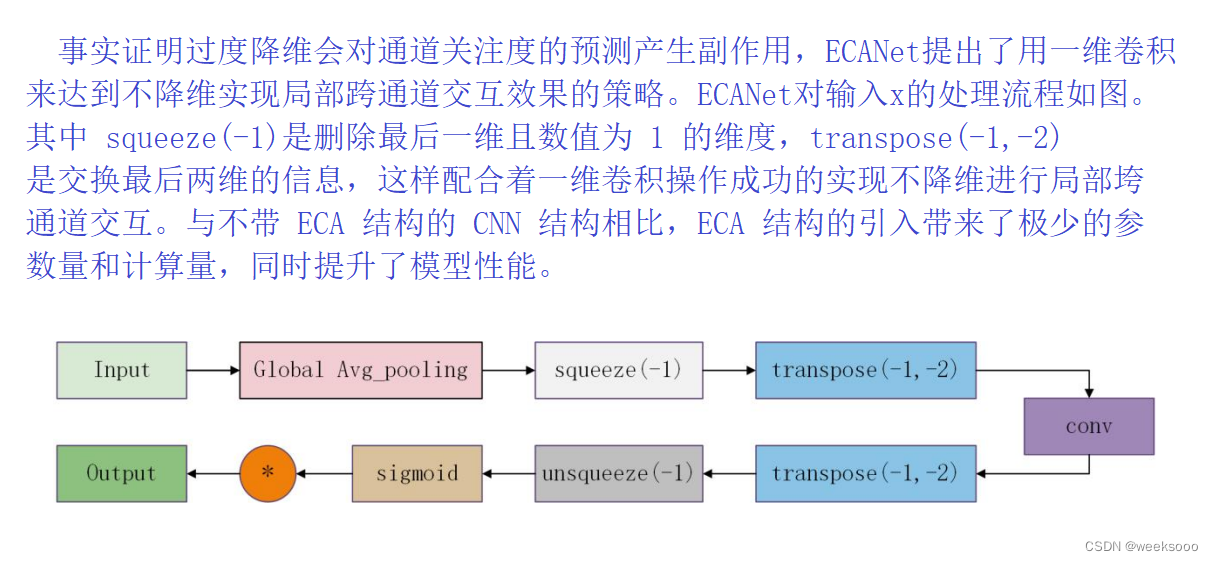
详细介绍


import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
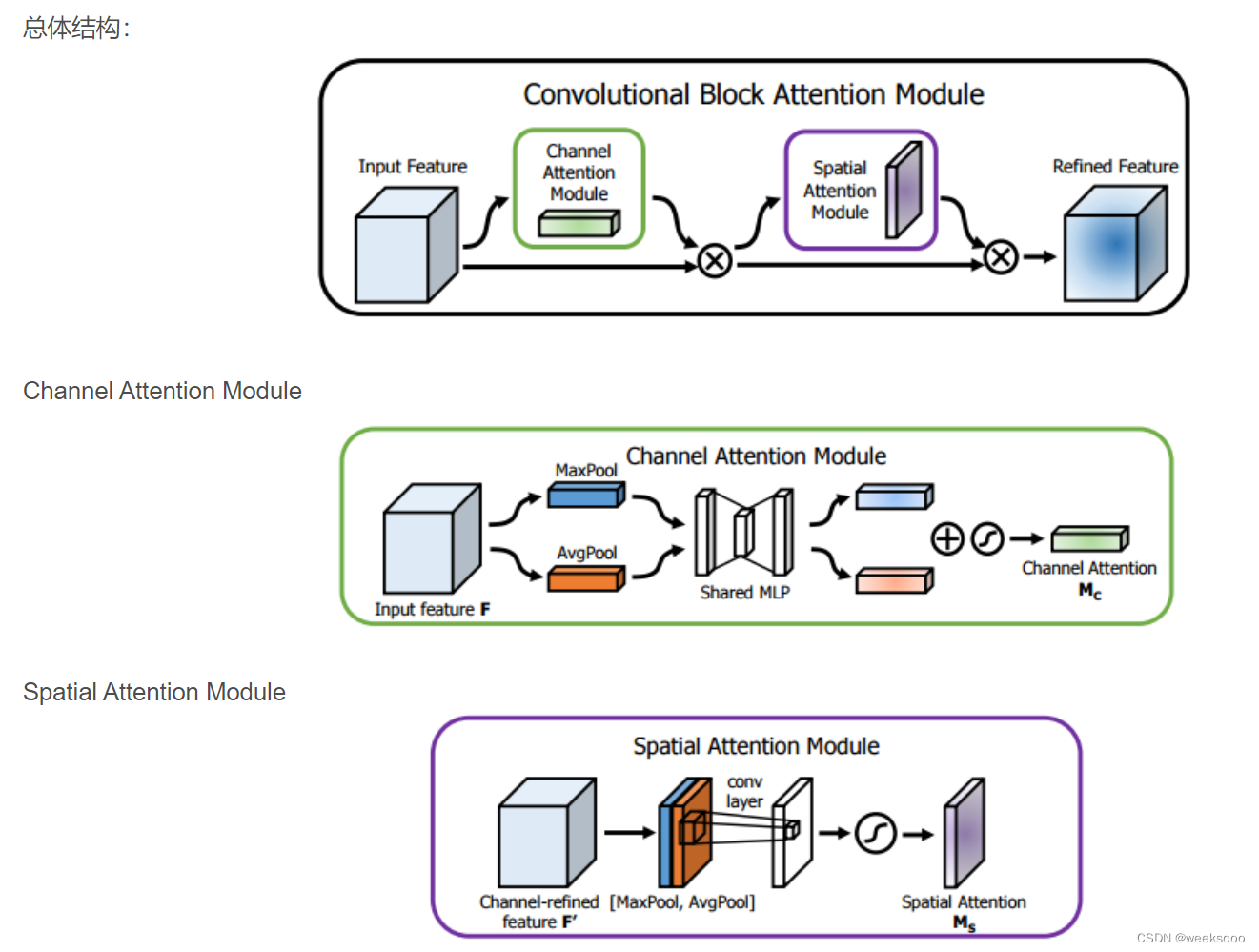
1.3 CBAM
CBAM论文地址
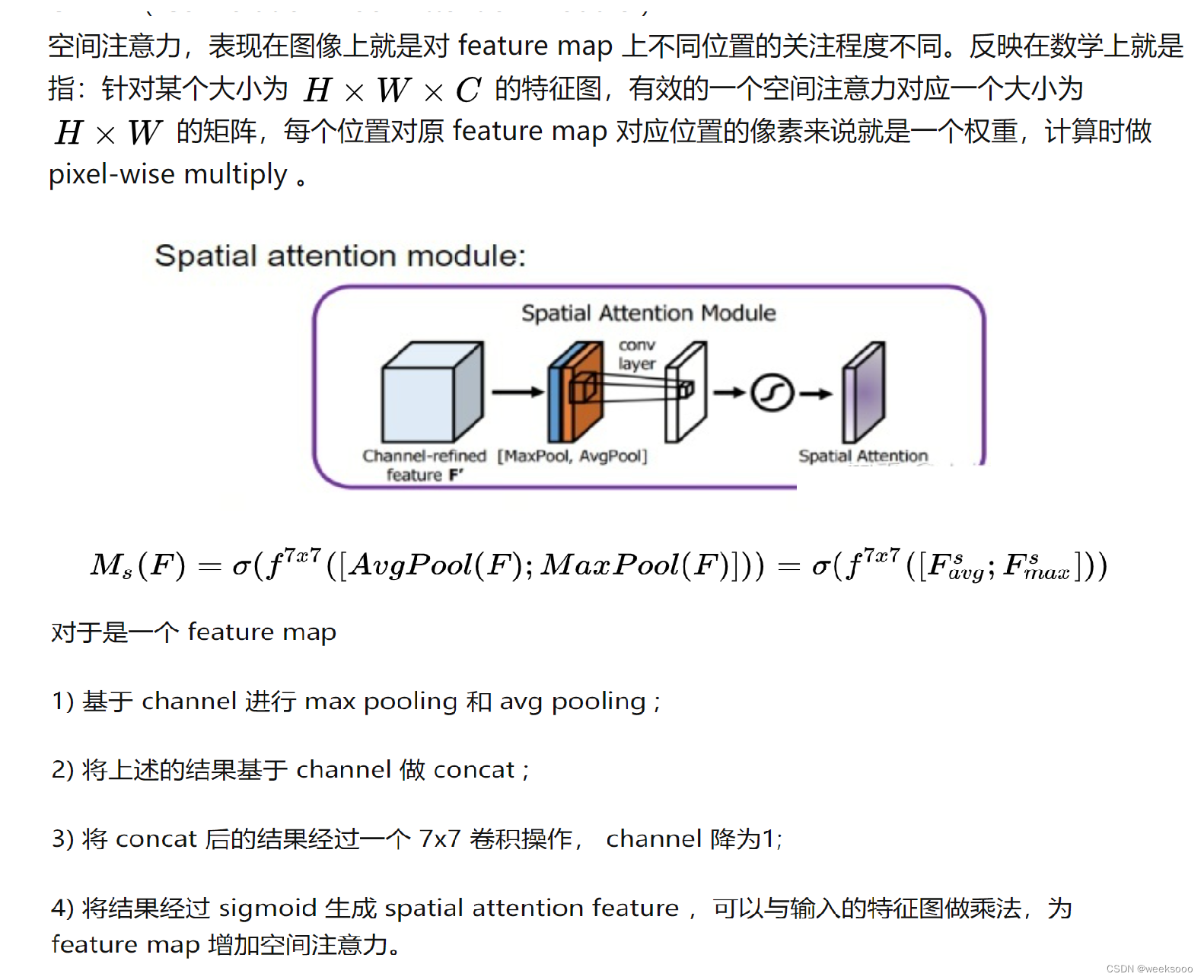
大致流程

细节描述
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes / 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes / 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self,c2):
super(CBAM, self).__init__()
self.channel_attenton = ChannelAttention(c2)
self.spatial_attention = SpatialAttention(7)
def forward (self , x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
…
场景四:Attention机制的创新思路
1.1 ECANet结合CBAM创新
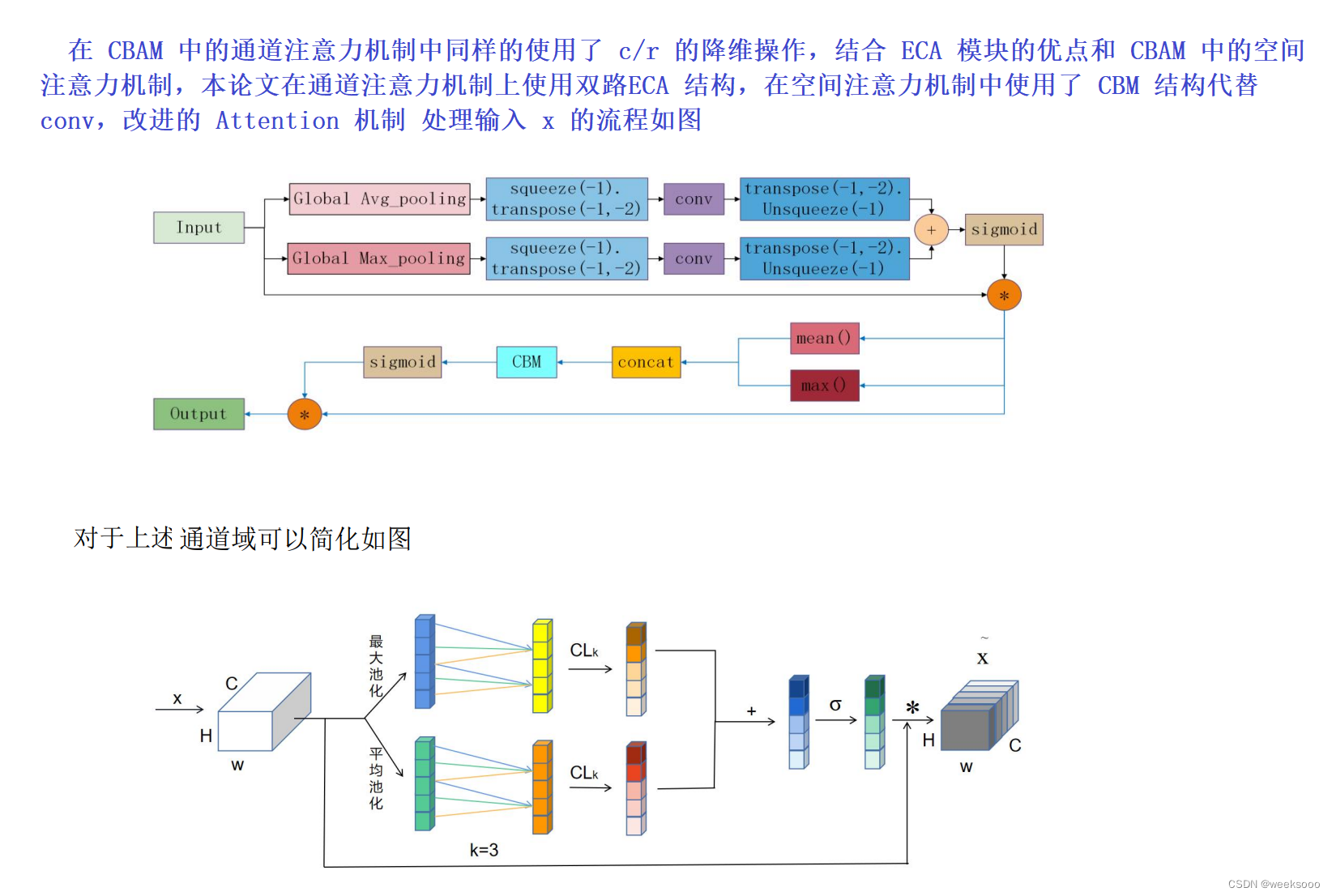

代码描述可以参考场景五的实验四
1.2 SENet结合CBAM创新
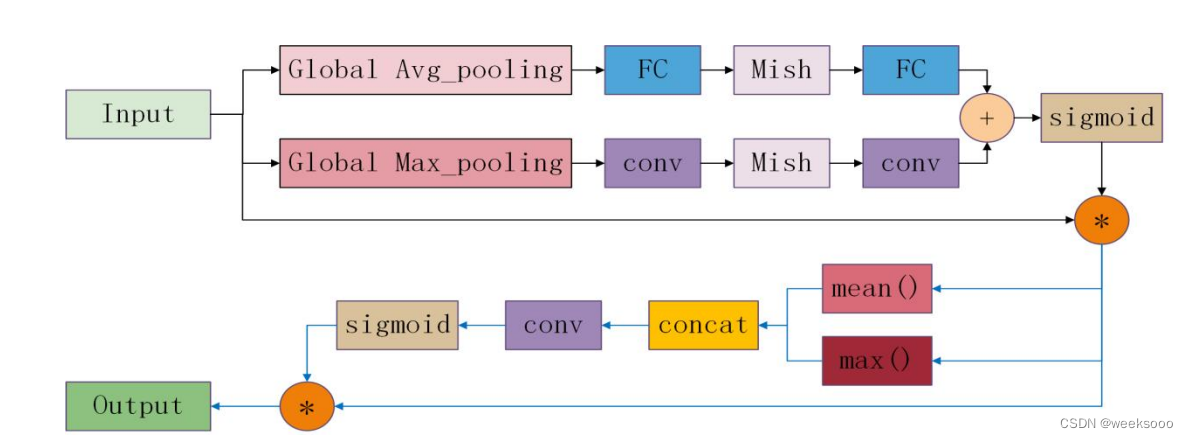
1.3 ECA创新尝试

1.4 创新寄语
强推一:更多Attention
强推二:网络中的注意力机制-CNN attention
强推三:综述—图像处理中的注意力机制

…
场景五:yolov5中进行Attention结构插入实验
代码看不懂请看–》场景四中的4 模型构建代码 common.py—>网络组件代码
实验列表
#实验一: 类名字: ECA1 原始类型的ECA : 单路ECA模型
#实验二:类名字: ECA2 改进的ECA : 多路ECA模型
#实验三: 类名字: EcA3 改进的ECA : 多路ECA模型+ SpatialAttention+ 普通的conv
#实验四:类名字: EcA4 改进的ECA : 多路ECA模型+ SpatialAttention+ Conv(自定义的Conv)
#实验五: 类名字: MishAttention5 单链CBAM的设计 使用了cbm ,激活函数,记得修改Conv里面的为Mish激活函数
#实验六: 类名字 : SiLUAttention6 单链CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
#实验七: 类名字: SiLUAttention7 双路CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
#实验八: 类名字: MishAttention8 双路CBAM的设计 使用了cbM ,激活函数,记得修改Conv里面的为Mish激活函数
#实验九: 类名字: SiLUAttention9 混合双路CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
#实验十: 类名字: MishAttention10 混合双路CBAM的设计 使用了cbM ,激活函数,记得修改Conv里面的为Mish激活函数
对应的attention结构


需要修改的地方为common.py / yolo.py / 和 yaml文件.
1.1 yaml文件中的修改
例如将我们构建的SiLUAttention7在backbone中插入在C3结构后,插入的方式修改如下。

1.2 yolo文件中的修改

如果你在通道注意力机制和空间注意力机制都改进了,那么新改进的模型放在这里的位置.因为SiLUAttention机制是混合域注意力机制,所以插入的位置修改如下:

如果你只是改进了通道注意力机制,请写在下面。

1.3 common.py文件中插入
# ..................................................................ECA 类型的attention........
# 实验一: 原始类型的ECA : 单路ECA模型
class ECA1(nn.Module):
def __init__(self, channel, k_size=3):
super(ECA1, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
a =np.array( [ [[ 1],[2] ] , [[ 1],[2] ] ,[[ 1],[2] ] ])
#print(a.shape,a) #结果为 ((3, 2, 1), array([ [[1],[2]] , [[1],[2]] ,[[1],[2]] ])
#删除最后一维如果是1
b=a.squeeze(-1)
#print(b.shape ,b) #(3,2) array[ [ 1,2] , [1,2] ,[1,2] ]
#交换相应的位置,
c=b.transpose(-1,-2)
#print(c.shape ,c ) #变为(2,3), array[ [ 1,1,1] , [2,2,2] ]
"""
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
# 实验二: 改进的ECA : 多路ECA模型
class ECA2(nn.Module):
def __init__(self, channel, k_size=3):
super(ECA2, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2))
y = y.transpose(-1, -2).unsqueeze(-1)
y2 = self.max_pool(x)
y2 = self.conv(y2.squeeze(-1).transpose(-1, -2))
y2 = y2.transpose(-1, -2).unsqueeze(-1)
y3 = self.sigmoid(y + y2)
return x * y3.expand_as(x)
# 实验三: 改进的ECA : 多路ECA模型+ SpatialAttention+ 普通的conv
class SpatialAttention_ECA3(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention_ECA3, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class ECA3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super(ECA3, self).__init__()
k_size = 3
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
self.spatial_attention_ecA3 = SpatialAttention_ECA3(7)
def forward(self, x):
b, c, h, w = x.size()
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2))
y = y.transpose(-1, -2).unsqueeze(-1)
y2 = self.max_pool(x)
y2 = self.conv(y2.squeeze(-1).transpose(-1, -2))
y2 = y2.transpose(-1, -2).unsqueeze(-1)
y3 = self.sigmoid(y + y2)
out = x * y3.expand_as(x)
out = self.spatial_attention_ecA3(out) * out
return out
# 实验四: 该进的ECA : 多路ECA模型+ SpatialAttention+ Conv(自定义的Conv)
class SpatialAttention_ECA4(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention_ECA4, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# .......................可能出问题
# self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.Conv1 = Conv(2, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.Conv1(x)
return self.sigmoid(x)
class ECA4(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super(ECA4, self).__init__()
k_size = 3
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
self.spatial_attention_ecA4 = SpatialAttention_ECA4(7)
def forward(self, x):
b, c, h, w = x.size()
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2))
y = y.transpose(-1, -2).unsqueeze(-1)
y2 = self.max_pool(x)
y2 = self.conv(y2.squeeze(-1).transpose(-1, -2))
y2 = y2.transpose(-1, -2).unsqueeze(-1)
y3 = self.sigmoid(y + y2)
out = x * y3.expand_as(x)
out = self.spatial_attention_ecA4(out) * out
return out
# .............................................................
# 实验五 : weeks的 单链CBAM的设计 使用了cbm ,激活函数,记得修改Conv里面的为Mish激活函数
class SpatialAttention5(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention5, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(1, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
x = self.conv(avg_out)
return self.sigmoid(x)
class MishAttention51(nn.Module):
def __init__(self, in_planes, ratio=16, n=1, shortcut=True, g=1, e=0.5):
super(MishAttention51, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.mish = Mish()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.mish(self.f1(self.avg_pool(x))))
out = self.sigmoid(avg_out)
return out
class MishAttention5(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(MishAttention5, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = MishAttention51(c2, 16)
self.spatial_attention = SpatialAttention5(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
# .............................................................
# 实验六 : hjf的 单链CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
class SpatialAttention6(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention6, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(1, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.mean(x, dim=1, keepdim=True)
x = self.conv(x)
return self.sigmoid(x)
class SiLUAttention61(nn.Module):
def __init__(self, in_planes, ratio=16, n=1, shortcut=True, g=1, e=0.5):
super(SiLUAttention61, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.silu = nn.SiLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.silu(self.f1(self.avg_pool(x))))
out = self.sigmoid(avg_out)
return out
class SiLUAttention6(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SiLUAttention6, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = SiLUAttention61(c2, 16)
self.spatial_attention = SpatialAttention6(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
# .............................................................
# 实验七 : hjf的 双路CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
class SpatialAttention7(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention7, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(2, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class SiLUAttention71(nn.Module):
def __init__(self, in_planes, ratio=16, n=1, shortcut=True, g=1, e=0.5):
super(SiLUAttention71, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.silu = nn.SiLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
avg_out = self.f2(self.silu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.silu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SiLUAttention7(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SiLUAttention7, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = SiLUAttention71(c2, 16)
self.spatial_attention = SpatialAttention7(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
# .............................................................
# 实验八 : weeks的 双路CBAM的设计 使用了cbM ,激活函数,记得修改Conv里面的为Mish激活函数
class SpatialAttention8(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention8, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(2, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class MishAttention81(nn.Module):
def __init__(self, in_planes, ratio=16, n=1, shortcut=True, g=1, e=0.5):
super(MishAttention81, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.mish = Mish()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.mish(self.f1(self.avg_pool(x))))
max_out = self.f2(self.mish(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class MishAttention8(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(MishAttention8, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = MishAttention81(c2, 16)
self.spatial_attention = SpatialAttention8(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
# .............................................................
# 实验九 : hjf的 混合双路CBAM的设计 使用了cbs ,激活函数,记得修改Conv里面的为SiLU激活函数
class SpatialAttention9(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention9, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(2, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class SiLUAttention91(nn.Module):
def __init__(self, in_planes, ratio=16, n=1, shortcut=True, g=1, e=0.5):
super(SiLUAttention91, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.silu = nn.SiLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
self.l1 = nn.Linear(in_planes, in_planes // ratio, bias=False)
self.l2 = nn.Linear(in_planes // ratio, in_planes, bias=False)
def forward(self, x):
max_out = self.f2(self.silu(self.f1(self.max_pool(x))))
b, c, _, _ = x.size()
y1 = self.avg_pool(x).view(b, c)
y1 = self.l1(y1)
y1 = self.silu(y1)
y1 = self.l2(y1)
y1 = self.sigmoid(y1)
y1 = y1.view(b, c, 1, 1)
out = self.sigmoid(max_out) + y1.expand_as(x)
return out
class SiLUAttention9(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SiLUAttention9, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = SiLUAttention91(c2, 16)
self.spatial_attention = SpatialAttention9(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
# .............................................................
# 实验十 : weeks的 混合双路CBAM的设计 使用了cbM ,激活函数,记得修改Conv里面的为Mish激活函数
class SpatialAttention10(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention10, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = Conv(2, 1, kernel_size, p=padding)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class MishAttention101(nn.Module):
def __init__(self, in_planes, ratio=16):
super(MishAttention101, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.mish = Mish()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
self.l1 = nn.Linear(in_planes, in_planes // ratio, bias=False)
self.l2 = nn.Linear(in_planes // ratio, in_planes, bias=False)
def forward(self, x):
max_out = self.f2(self.mish(self.f1(self.max_pool(x))))
b, c, _, _ = x.size()
y1 = self.avg_pool(x).view(b, c)
y1 = self.l1(y1)
y1 = self.mish(y1)
y1 = self.l2(y1)
y1 = self.sigmoid(y1)
y1 = y1.view(b, c, 1, 1)
out = self.sigmoid(max_out) + y1.expand_as(x)
return out
class MishAttention10(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(MishAttention10, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = MishAttention101(c2, 16)
self.spatial_attention = SpatialAttention10(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x).expand_as(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
...
you did it