源代码git地址
对于无序列表的唯一化算法:
从前往后依次处理节点p,在p的前驱中查找(通过find函数)值相同者,则调用remove函数将相同者删除
template <typename T>//删除重复元素,返回删除元素个数
int List<T>::deduplicate()
{
ListNodePtr pHead = _header;
ListNodePtr pBar = _tailer;
int oldsize = _size;//记录原始规模
int rmsize = 0;//记录删除的个数
int num = 0;//记录有序序列的个数
while (_tailer != pHead->succ)//遍历到尾节点
{
pHead = pHead->succ;
ListNodePtr nd = find(pHead->data, num, pHead);//查找数据位置
if (NULL != nd)
{
T rm = remove(nd);//删除重复
rmsize++;//记录重复个数
continue;
}
num++;//下一个位置查找
}
return oldsize - rmsize;
}
算法分析:
| 算法名称 |
时间复杂度(平均) |
时间复杂度(最坏) |
时间复杂度(最好) |
空间复杂度 |
稳定性 |
| |
O(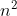 ) ) |
O() |
O() |
0(1) |
|
n + (n-1) + (n-2) + ...+2+1
有序列表的唯一化:
分别设置两个位置指针p与q,分别指向每一对相邻的节点,如果相同则删除,否则位置节点前进。
template <typename T>//删除重复元素,返回删除元素个数
int List<T>::uniqufy()
{
ListNodePtr pHead = _header;
int oldsize = _size;//记录原始规模
while (_tailer != pHead->succ)//遍历到尾节点
{
pHead = pHead->succ;
if (pHead->data == pHead->succ->data)
{
remove(pHead->succ);
}
}
return oldsize - _size;
}
算法分析:
| 算法名称 |
时间复杂度(平均) |
时间复杂度(最坏) |
时间复杂度(最好) |
空间复杂度 |
稳定性 |
| |
O(n) |
O(n) |
O(n) |
0(1) |
|