1 爬虫
1.1 爬虫原理
这部分内容可以跳过,掌握与否对后面内容的阅读影响并不大,但有兴趣的话可以看看呐~
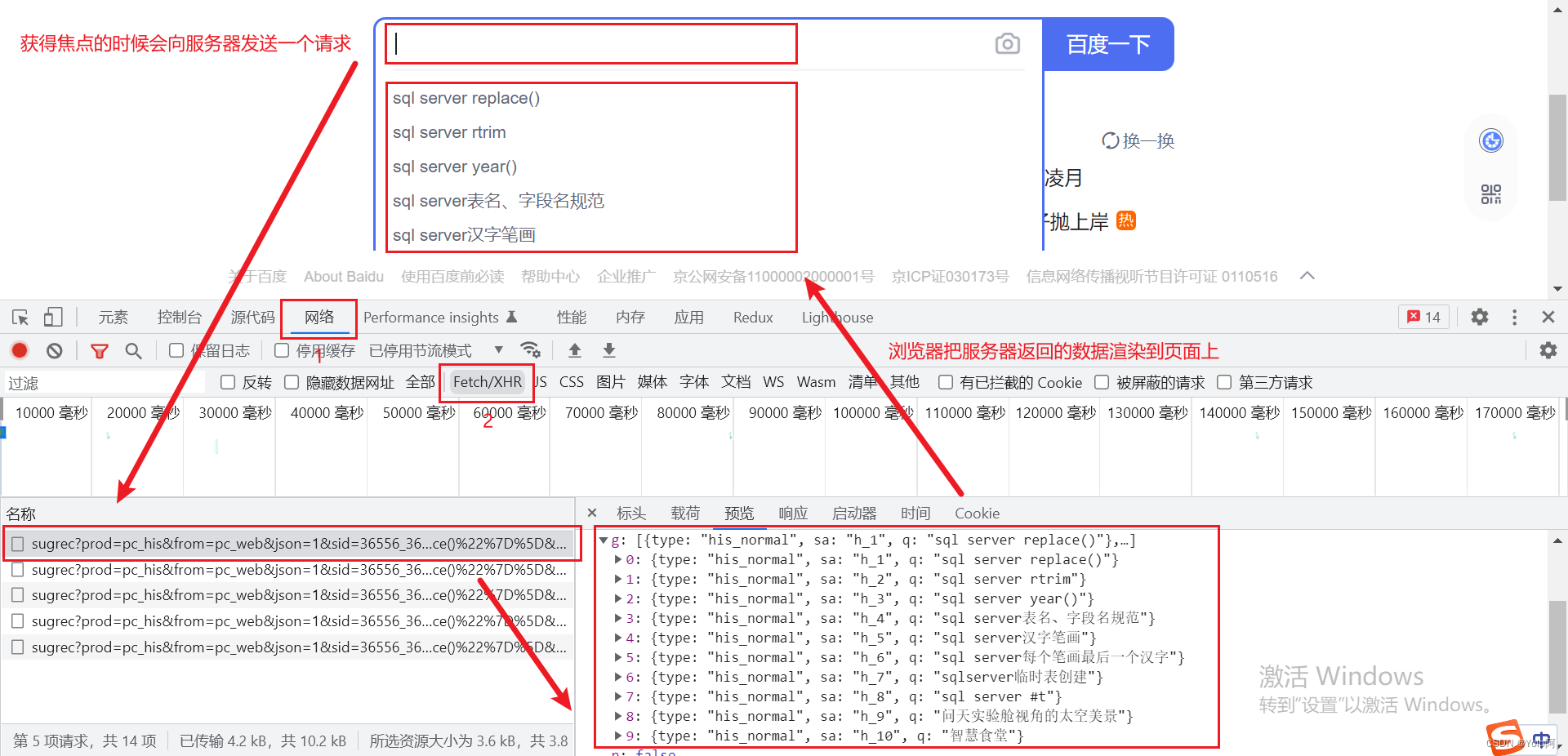
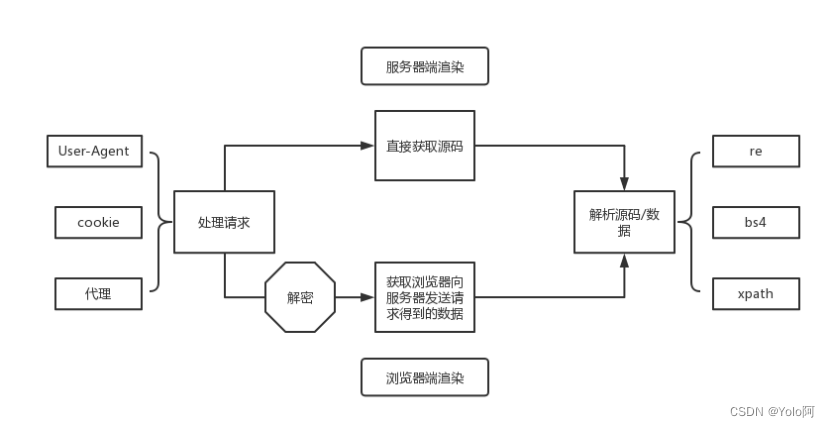
实现一个爬虫,一般需要经过两个步骤:处理请求和解析源码/数据。
处理请求方面,我们可以使用Python程序自动发送请求,然后根据返回的网页脚本,判断该页面是服务器端渲染还是浏览器端渲染。服务器端渲染可以直接获取到源码并进行解析,如果是浏览器端渲染则需要获取浏览器向服务器发送的二次请求得到的数据。其中,服务器端渲染的网页需要我们解析源码,而浏览器端渲染的网页一般可以直接获得数据。
对于浏览器端渲染的页面,我们直接获取二次请求得到的数据即可,而对于服务器端渲染的页面,我们需要从源码解析出有价值的内容。我们可以使用Python的第三方模块re、bs4、xpath等。re是使用正则表达式匹配网页源码,从而得到我们想要的内容;而bs4是通过标签和属性定位网页源码中我们需要的内容的位置,其更符合前端的编程习惯;xpath同样是通过标签和属性定位,但它看起来更加直观。
import re
list = re.findall(r"\d+", "我的电话号码是:10086, 我女朋友的电话号码是:10010") # ['10086', '10010']
from bs4 import BeautifulSoup
page = BeautifulSoup(res, "html.parser") # 把页面源代码(res)交给BeautifulSoup进行处理, 生成BeautifulSoup对象
table = page.find("table", attrs={"class": "hq_table"}) # 找到table
# xpath是在XML文档中搜索内容的一门语言,html是xml的一个子集
from lxml import etree
xml =
"""
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<author>
<nick>周大强</nick>
<nick>周芷若</nick>
</author>
</book>
"""
tree = etree.XML(xml)
result = tree.xpath("/book/name/text()") # ['野花遍地香']。/表示层级关系,第一个/是根节点,text() 拿文本
另外,在处理请求的过程中,可能需要解决一系列的反爬措施:(1)防止网站识别Python程序需要加上User-Agent请求头;(2)对于使用cookie验证登录的网站需要带上登录后服务器返回的cookie作为请求头;(3)防止因频繁的请求导致ip地址被封需要使用代理;(4)以及针对浏览器端渲染的情况,直接请求数据时可能遇到的一系列加密手段,这时候获取数据需要模拟加密过程进行解密……
个人理解的爬虫原理~
1.2 实现一个爬虫
一般来说,平台知名度越大,其反爬措施就越多,这时候获取数据也会变得更加困难,而下文将会介绍一种技巧性的方法。
1.2.1 Selenium
Selenium是一个用于Web应用程序测试的工具,它可以直接运行在浏览器中,模拟用户的操作,例如点击、输入、关闭、拖动滑块等,就像真正的用户在操作一样。通过Selenium我们可以直接定位到页面中某段文字的位置,在已经经过浏览器渲染的网页中获取需要的内容,而不需要关心网页是服务器端渲染还是浏览器端渲染,所见即所得。
另一方面,某些数据可能需要登录网站后才能获取,而在登录选项中选择账号密码登录一般会被要求输入验证码,比如常见的数字、汉字验证码等,某东平台使用的是滑块。我们可以使用超级鹰处理滑块,它是一款成熟的验证码处理工具,其使用原理是通过截取浏览器中验证码的图片传到超级鹰工具接口,然后接口会返回识别出来的数据(数字,汉字,坐标等),我们通过Selenium可以直接操作浏览器从而通过验证。
1.2.3 实现一个爬虫(源码在这里~)
- 在这之前,大家可以先注册一个超级鹰账号哈,1元=1000题分,识别一次只需不到50题分,还是相当良心的。
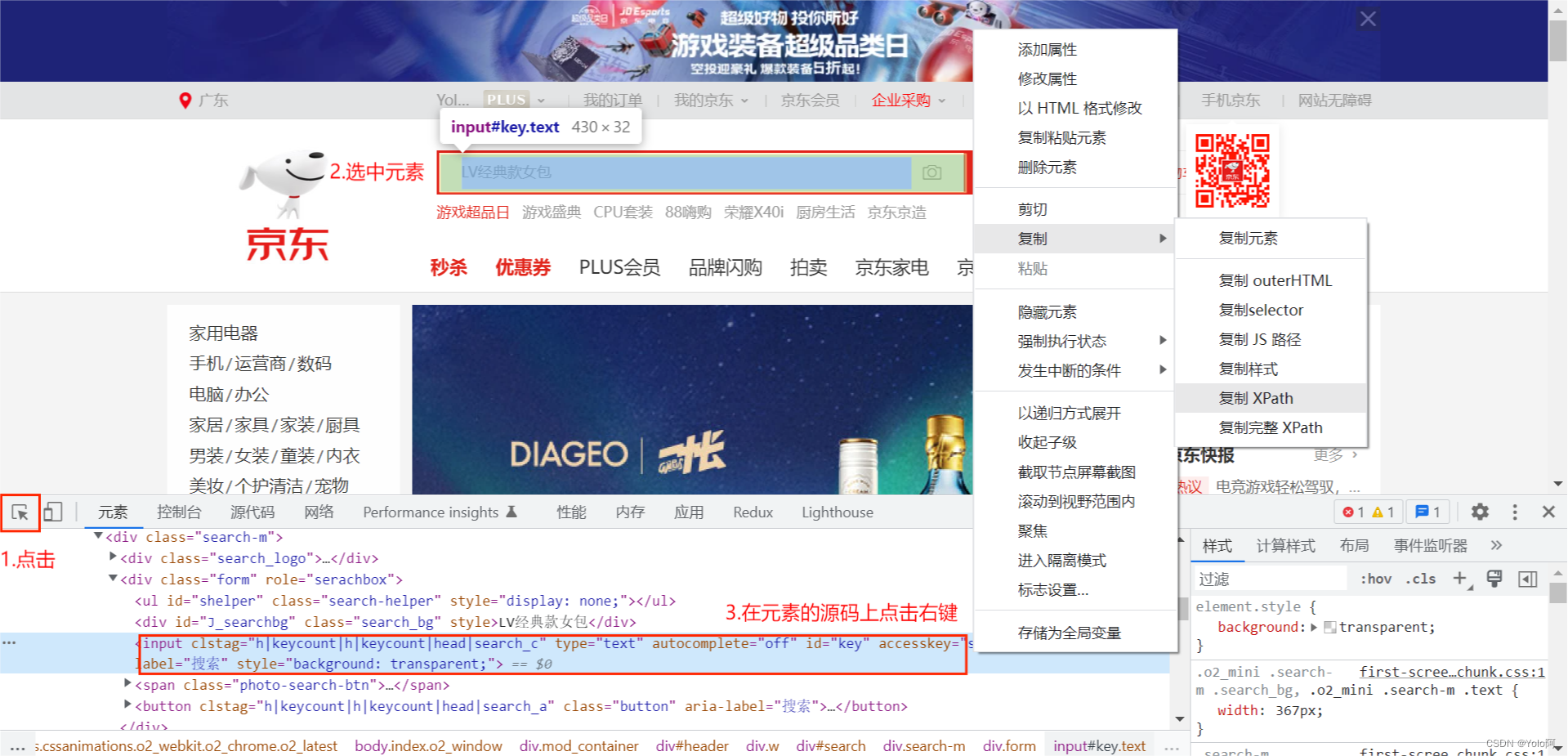
- 其次,在
1.1 爬虫原理部分有简单介绍过xpath,这里有一种更便捷的方法获取元素的xpath,就像这样:右键-检查
- 另外,部分商品可以使用
id搜索
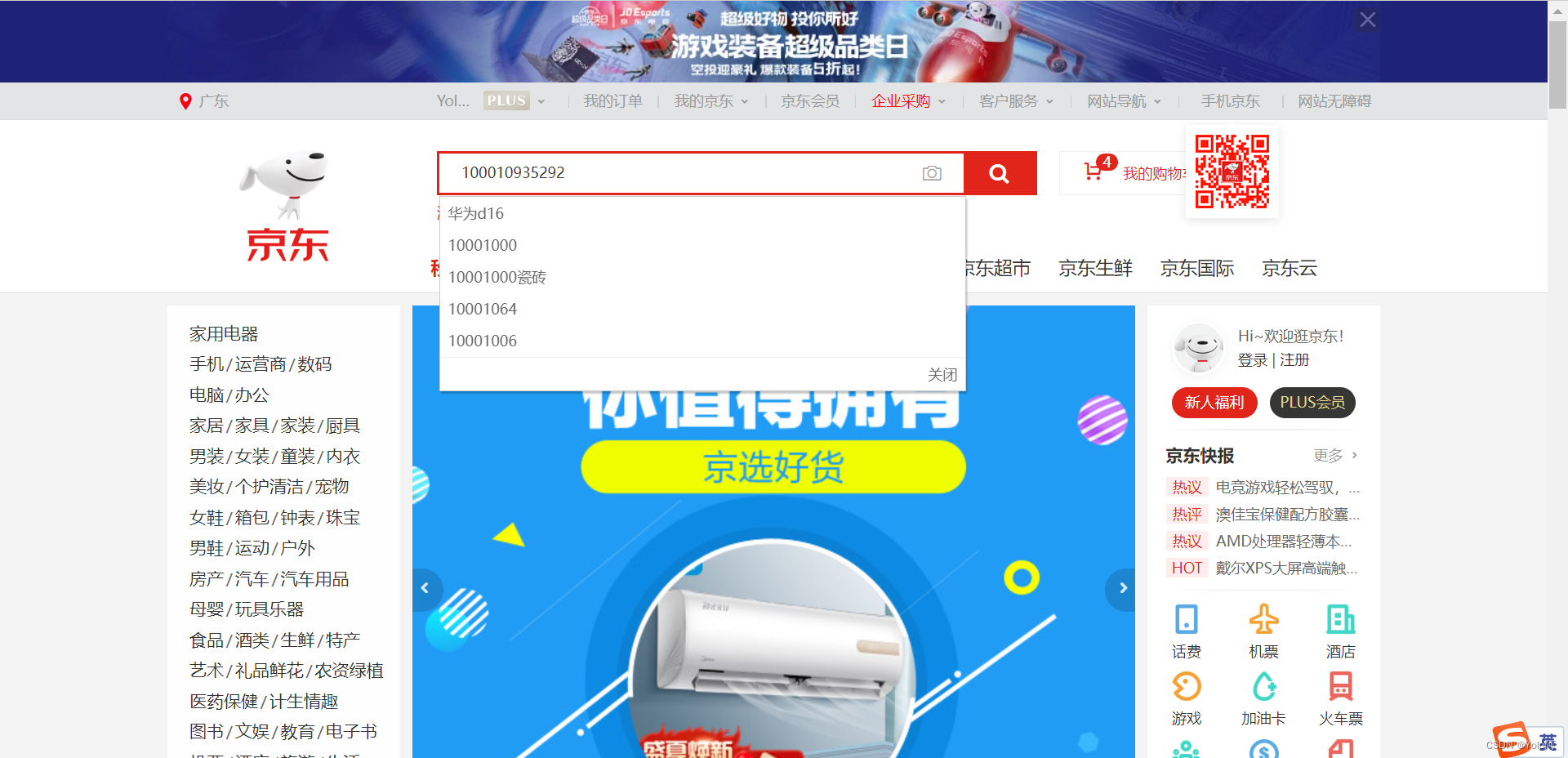
- 再有就是,
Selenium是需要配合浏览器驱动使用的,Chrome的驱动:chromedriver,对应浏览器版本的驱动下载完成后,将驱动放置在Python的安装目录,像下面这样:(也许还需要配置环境变量??如果遇到报错说没有找到浏览器驱动的话,可以自行搜一下具体是怎么配置的哈)

chaojiying.py(验证码处理)
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
# if __name__ == '__main__':
# 用户中心>>软件ID
# chaojiying = Chaojiying_Client('超级鹰账号', '密码', '软件ID')
# 本地图片文件路径替换code.png,有时WIN系统须要//
# im = open('code.png', 'rb').read() # im就是图片的所有字节
# 官方网站>>价格体系
# print(chaojiying.PostPic(im, 9101)) # 9101验证码类型
jd.py - 爬虫主程序
目标链接:(第24行代码)

from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from chaojiying import Chaojiying_Client
import time
# 初始化超级鹰
chaojiying = Chaojiying_Client('******', '********', '******') # 替换自己的账号、密码和软件ID
# 无头浏览器
# opt = Options()
# opt.add_argument("--headless")
# opt.add_argument("--disbale-gpu")
# options = opt
# 设置不关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
web = webdriver.Chrome(options = option)
# 打开登录页面
web.get("") # 填入某东登录页面链接,由于不能出现具体的目标链接,故以截图显示
# 最大化窗口,防止误触
web.maximize_window()
# time.sleep()是为了等待资源加载完
time.sleep(3)
# 使用账号登录
web.find_element(By.XPATH, '//*[@id="content"]/div[2]/div[1]/div/div[3]/a').click()
time.sleep(3)
# 输入用户名和密码
web.find_element(By.XPATH, '//*[@id="loginname"]').send_keys("***********") # 某东账号
web.find_element(By.XPATH, '//*[@id="nloginpwd"]').send_keys("********") # 某东密码
# 点击登录
web.find_element(By.XPATH, '//*[@id="loginsubmit"]').click()
time.sleep(3)
# 处理验证码,识别图像
verify_img = web.find_element(By.XPATH, '//*[@id="JDJRV-wrap-loginsubmit"]/div/div/div/div[1]/div[2]/div[1]/img')
dic = chaojiying.PostPic(verify_img.screenshot_as_png, 9101)
result = dic['pic_str'] # x1,y1
p_temp = result.split(",")
x = int(p_temp[0])
# 滑动滑块
btn = web.find_element(By.XPATH, '//*[@id="JDJRV-wrap-loginsubmit"]/div/div/div/div[2]/div[3]')
ActionChains(web).drag_and_drop_by_offset(btn, x, 0).perform()
time.sleep(8)
# 登陆成功,搜索界面(使用id搜索)
web.find_element(By.XPATH, '//*[@id="key"]').send_keys("100010935292", Keys.ENTER)
# time.sleep(5)
# # 点击商品
# web.find_element(By.XPATH, '//*[@id="J_goodsList"]/ul/li[1]/div/div[1]/a/img').click()
# time.sleep(5)
# # 移动到新窗口
# web.switch_to.window(web.window_handles[-1])
time.sleep(5)
# 商品属性
web.find_element(By.XPATH, '//*[@id="choose-attr-1"]/div[2]/div[1]/a').click()
time.sleep(5)
# 点击(商品评论)
comment_el = web.find_element(By.XPATH,'//*[@id="detail"]/div[1]/ul/li[5]')
comment_el.click()
time.sleep(5)
# 点击(只看当前商品评价)
only_el = web.find_element(By.XPATH, '//*[@id="comment"]/div[2]/div[2]/div[1]/ul/li[9]/label')
webdriver.ActionChains(web).move_to_element(only_el ).click(only_el ).perform()
f = open("comments.txt", mode="w", encoding='utf-8')
time.sleep(5)
# 评论列表
for i in range(100):
# 每一页的评论
div_list = web.find_elements(By.XPATH,'//*[@id="comment-0"]/div[@class="comment-item"]')
for div in div_list:
comment = div.find_element(By.TAG_NAME, 'p').text
f.write(comment + '\n\n')
# 打印页数
print(i)
if i < 99:
# 下一页
next_el = web.find_element(By.XPATH, '//*[@id="comment-0"]/div[12]/div/div/a[@class="ui-pager-next"]')
# 防止元素遮挡
webdriver.ActionChains(web).move_to_element(next_el ).click(next_el ).perform()
time.sleep(3)
f.close()
print('over!')
- 把
chaojiying.py和jd.py放在同一个目录下,然后下载相关依赖包,运行jd.py就ok了,再放个视频趴(懒得剪了
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)