进程管理
进程的概念
大家比较熟悉 Windows 下的可执行文件,就是那些扩展名为exe的文件。
大家知道,只需要鼠标双击这些程序, 就可以运行了。
程序运行起来后,我们把这个程序正在运行的 实例 称之为 进程 。
操作系统对每个进程都分配一个数字标记,称为 进程ID (PID)。
Windows进程的信息可以通过 任务管理器看到。如下所示
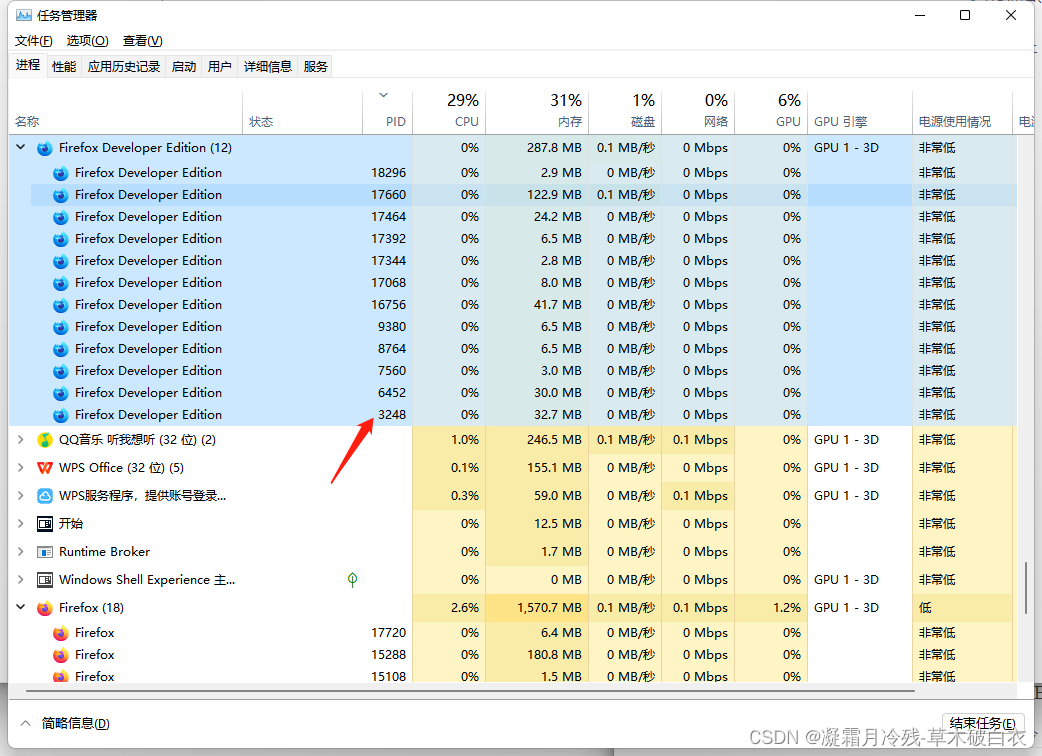
比如上图中,正在运行的计算器程序 Calculator.exe 的进程PID就是 3164
Linux系统中,进程也有PID。
在Linux中,你正在运行的交互式命令行程序 Shell, 它就是一个进程。
我们可以用命令 ps 查看进程信息的命令。
$ ps
PID TTY TIME CMD
4786 pts/0 00:00:00 bash
如上所示,当前bash shell的 进程 PID 为 4786
进程的创建与查看
Linux中,一个进程A里面可以创建出一个新的进程B,进程A就叫做进程B的 父进程 (parent process)。
进程B叫做进程A的子进程(child process)。
最典型的例子,我们在shell中运行的程序(命令),都是shell进程创建的,所以shell进程就是他们的父进程。
Linux中,主要是通过ps命令来查看进程信息的,我们运行命令ps -f ,结果如下所示
[byhy@localhost ~]$ ps -f
UID PID PPID C STIME TTY TIME CMD
byhy 4786 1780 0 06:45 pts/0 00:00:00 -bash
byhy 1865 4786 0 06:55 pts/0 00:00:00 ps –f
其中 PPID这一列就是该进程的父进程的PID。
我们可以看出 ps 命令对应的进程的父进程PID为4786,正是bash进程的PID。
下面列举了常用的 ps命令 的例子:
ps 显示和当前终端有关的进程信息
ps -u byhy 显示byhy用户所创建的进程信息
ps -f 详细显示每个进程信息
ps -e 显示所有正在运行的进程信息
ps -ef 显示当前系统所有的进程
ps –ef | grep python 查找python进程
ps –ef | grep -- "--python " 查找包含"--python"进程
ps –ef | grep tx.py|grep -v grep查找包含"tx.py"进程,但不包含grep本身
进程的前台、后台转换
Linux中,一个进程A里面可以创建出一个新的进程B,进程A就叫做进程B的 父进程 (parent process)。
进程B叫做进程A的子进程(child process)。
最典型的例子,我们在shell中运行的程序(命令),都是shell进程创建的,所以shell进程就是他们的父进程。
Linux中,主要是通过ps命令来查看进程信息的,我们运行命令ps -f ,结果如下所示
[byhy@localhost ~]$ ps -f
UID PID PPID C STIME TTY TIME CMD
byhy 4786 1780 0 06:45 pts/0 00:00:00 -bash
byhy 1865 4786 0 06:55 pts/0 00:00:00 ps –f
其中 PPID这一列就是该进程的父进程的PID。
我们可以看出 ps 命令对应的进程的父进程PID为4786,正是bash进程的PID。
下面列举了常用的 ps命令 的例子:
ps 显示和当前终端有关的进程信息
ps -u byhy 显示byhy用户所创建的进程信息
ps -f 详细显示每个进程信息
ps -e 显示所有正在运行的进程信息
ps -ef 显示当前系统所有的进程
ps –ef | grep python 查找python进程
ps –ef | grep -- "--switc" 查找包含 "--switc"
进程的前台、后台转换
Linux终端通过Shell程序来接收用户输入的命令,并且执行命令。
我们在Shell里正在执行的,和用户进行人机交互的进程叫 前台进程 (foreground process)
前台进程可以接收键盘输入并将结果显示在显示器上。
用户敲入什么命令,shell就会启动对应的程序,运行在 前台 。
比如,大家可以用vi 编写一个 下面的Python程序到 Linux主机上,代码文件名可以为t1.py
while True:
info = input("please input something:")
print("you input:%s\n\n" % info)
然后使用命令 python3 t1.py 运行。
可以发现及时这个 python 程序变成了前台进程,接收用户的输入。
有些程序运行时,并不需要和用户进行交互,也就是说,不需要用户输入什么内容。 比如一个日志分析程序,一个定时清理磁盘文件的程序。
比如,下面这样的一个Python程序 t2.py:
import time
while True:
print("execute a task ...")
time.sleep(2)
print("done, wait for an hour to proceed...")
time.sleep(3600)
我们可以执行命令 python3 t2.py 运行它
这样的程序,运行期间,如果在前台执行,我们只能等待它结束,不然我们没法执行下个程序。
但是既然不需要用户输入信息,在前台执行,没有太大意义,我们应该要让它在 后台 执行。
要让它在后台运行,启动时只需在命令行的最后加上“&”符号。
比如 python3 t2.py &
后台运行的进程我们叫后台进程(background process),或者后台任务 ,它不直接和用户进行交互的进程。用户一般是感觉不到后台进程程序的运行。
当在后台运行命令时,有时需要其输出重定向输出到一个文件中去,以便以后检查。
比如 在后台运行find命令,在当前目录及其子目路下查找文件名为 byhy 的文件。
$ find . -name byhy -print > log.txt &
4762
重定向的概念后面会讲。
nohup
我们可以执行命令的时候,使用 & 结尾使进程在后台运行。
但是如果终端关闭,那么程序也会被关闭,因为shell会发送SIGHUP信号给这些进程。进程接收的该信号,如果没有特别的处理,缺省就会结束运行。
为了避免这种情况,那么我们就可以使用 nohup 这个命令。
比如我们有个test.sh 需要在后台运行,并且希望在后台能够一直运行,即使关闭了终端,也不退出。那么就使用nohup:
nohup /root/test.sh &
进程的终止
进程一般有两种终止方式。
which ls 命令可以查看执行命令所在的位置。
有的进程执行完一段任务后,就自行退出了。
比如上面的ps命令,它执行完查看进程信息的任务后,就会结束。
也有的不是自动退出,而是用户操作它,让它退出。 比如 我们在Shell进程中运行exit命令后,该Shell进程就会退出。
也有的是异常退出,比如程序有个bug(比如代码里面有除以0的指令),该程序无法执行下去,也会终止。
有的进程一直不结束,如果用户觉得该进程应该被强行结束了,该怎么办呢?
对于一个前台进程,要结束它,我们只需要按组合键: Ctrl + C 。
对于一个后台运行的进程 ,如果用户觉得该进程应该被强行结束,可以使用 kill -9 命令强行杀死该进程。
比如上面的 python3 t2.py 命令运行的进程。 我们可以先用ps命令查出它的进程PID,
byhy@byhy-server:~$ ps -f
UID PID PPID C STIME TTY TIME CMD
byhy 2368 2367 0 08:38 pts/0 00:00:00 -bash
byhy 2386 2368 0 08:39 pts/0 00:00:00 python3 t1.py
byhy 2388 2368 0 08:39 pts/0 00:00:00 ps -f
如上所示的python进程PID为2386,我们再执行命令 kill -9 2386 。 这样就强行停止了该进程。
要注意的是, 上面所示的进程启动它的用户为byhy,那么只能是用户byhy或者root用户才能杀死该进程
环境变量
Shell是个特殊的进程,因为我们通过它来执行命令,启动其他的进程的。所以它是很多进程的父进程。
Shell 这个父进程有很多特性会影响到我们执行命令,其中非常重要的一个就是 环境变量 。
环境变量 设置了 进程运行的环境信息。
Linux 的环境变量具有继承性,即:子进程 会继承父进程 的环境变量。
我们可以用命令printenv来查看当前shell的环境变量。
我们可以看到环境变量有很多,通常我们最关注的一个就是环境变量是其中的 PATH
因为PATH 决定了当我们敲入命令的时候,到哪里去找这个命令对应的可执行程序。
用命令 echo $PATH 来查看环境变量PATH的值,比如
[byhy@localhost ~]$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/byhy/bin
当我敲入命令ps后,shell就会 依次 到下面的路径去寻找ps命令对应的可执行文件 /usr/local/bin -> /bin -> /usr/bin -> /usr/local/sbin -> /usr/sbin -> /sbin -> /home/byhy/bin
方法一:执行命令 export PATH
比如:
export PATH=/test:$PATH
再次查看环境变量PATH的值,结果如下
[byhy@localhost ~]$ echo $PATH
/test:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/byhy/bin
说明添加PATH成功。
但是这种方式生效时临时的。再次登录的时候,PATH里面就又没有这个环境变量了。
需要一直生效,可以使用方法二。
方式二:写入到shell启动文件中
所谓shell启动文件(Startup Files)是指Shell启动时 会 自动加载执行 的文件。
既然这些文件会自动被shell加载执行,通常我们可以在里面放入一些 例行 执行的命令,比如设置一些环境变量。
bash Shell启动文件有好几个,比如 /etc/profile (所有用户共享), ~/.bash_profile , ~/.bashrc。
具体细节参考这个文档
通常建议把某个用户 独有的 设置环境变量的 命令,放到用户家目录下面的 ~/.bashrc 文件中。
可以在文件的结尾加入一行
export PATH=/test:$PATH
好了,下次登录的时候,PATH里面就会多出/test;
如果要对当前的shell就立即生效,可以执行命令 source ~/.bashrc
重定向和管道
stdin/stdout/stderr 与 重定向
什么是终端设备
人在操作电脑时,其实是和 运行着的程序(术语称之为:进程) 在打交道(术语称之为:交互)。
进程 是 看不见 摸不着的,它们是 在 电脑CPU中执行的代码指令。
所以,我们 和 进程 交互的时候,必须有个设备,我们才能通过它 输入信息给进程,并且显示进程输出信息。
在上世纪六七十年代,计算机网络还没有出现, 计算机都是大型机器,非常的昂贵。 通常只有大公司和研究机构才有。
那时人们通过终端设备和计算机上的程序进行交互,见下图。

注意,终端设备 只有 显示器 和键盘 , 是没有 主机部分的。它和主机之间有根信号线,传递用户通过键盘输入的信息给程序,并显示程序输出的信息。
这样的终端设备,显然不能离主机太远。
人们需要在家、甚至在另外一个城市 操作远程主机,就不能使用这样的终端。
后来有了计算机网络,有了微型个人电脑,我们可以使用个人电脑,运行软件模拟终端设备,比如 putty,进行远程登录主机,访问主机上的进程。
我们在模拟终端程序putty中输入信息,查看putty程序窗口输出的内容。
这种 模拟终端的软件,对Linux来说,也是终端设备。
Linux进程在启动后,通常就会打开3个文件句柄,标准输入文件(stdin),标准输出文件(stdout)和 标准错误文件(stderr)。
Linux进程,要从用户那里读入输入的信息,就是从stdin文件里面读取信息,要 输出 信息 给用户看 都是 输出到 stdout, 要 输出 错误提示 给用户看 都是 输出到 stderr。
而缺省情况下这三个文件stdin、stdout、stderr 都指向 —— 终端设备。
也就是说:
Linux进程从stdin里面读取信息其实就是从终端设备(比如终端模拟程序Putty)读取信息;
Linux进程写入信息到stdout或者stderr,其实就是打印到终端设备上。
如下图所示
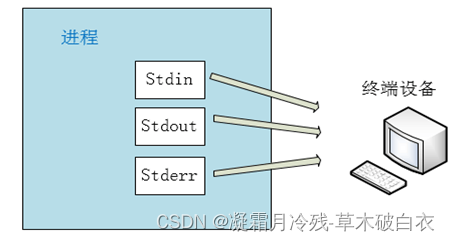
比如,运行下面的Python程序,要读入信息,就是从终端读入,因为stdin指向终端设备
input("please input info:")
再比如:下面的命令echo输出给用户看的,就是输入到终端上,因为stdout指向终端设备
[root@bogon ~]# echo "hello byhy"
hello byhy
Stdout、Stderr重定向
如果我们在Shell中输入命令的时候,使用 > 符号, 就可以将输入信息输出到其他文件(包括设备文件)中去。比如
ps > out
运行后,我们会发现out文件里面出现了ps的输入信息,而Putty终端窗口里面则没有任何内容打印出来了。
这个 > 就是 stdout 重定向符号, 它表示 stdout 不是指向 终端设备了,而是 重定向到 out 文件。 所以stdout 指向了 out 文件, 输入的信息就到 out 文件了。 终端屏幕上就没有信息了。
这时对应的示意图如下
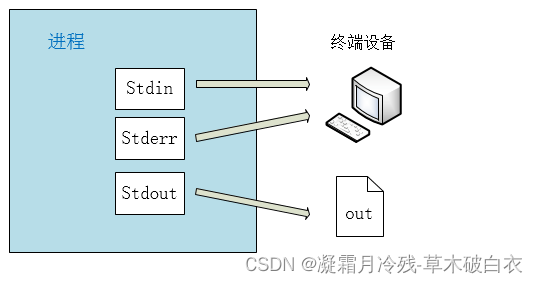
而Stderr的重定向符号 是 2> 。 注意 2 和 > 之间不能有空格。
比如我们执行下面的命令,其中hhhh是个不存在的文件
ps hhhh 2> err
我们就会发现putty屏幕上没有任何信息,而文件 err里面则有。
如果我们要,同时重定向stdout和stderr到同一个文件both中,命令写法如下:
command &> both
如果我们要,重定向stdout到out文件,并重定向stderr到err文件,命令写法如下:
command > out 2>err
stdin重定向
我们也可以在命令中,将 标准输入stdin 重定向,使用符号 <
用 vi 创建一个 Python 代码文件 add.py ,其内容如下
for i in xrange(3):
data=input()
print ('%s+1=%s' % (data,int(data)+1))
该程序从stdin 读取一个数字后,显示其加1后的结果。
再创建一个文件 add.dat内容如下(注意3后面有个空行)
1
2
3
执行如下命令
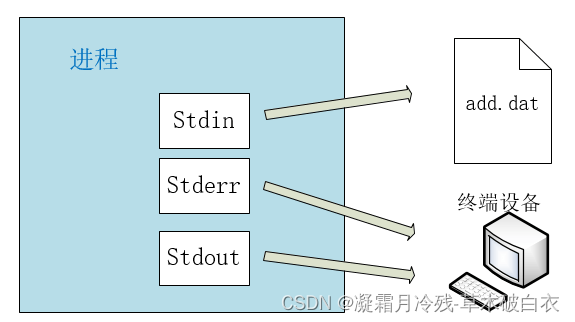
[byhy@localhost ~]$ python3 add.py < add.dat
1+1=2
2+1=3
3+1=4
看到了吗?不需要我们从终端输入数字,该程序直接从文件 add.dat中读取数据并执行操作了。
这个 < 就是 stdin 重定向符号, 它表示 stdin 不是指向 终端设备了,而是 重定向到 add.dat 文件。 所以 stdin 指向了 add.dat 文件, 程序就从add.dat 文件读入信息 了。
这时该进程对应示意图如下:
管道
上面我们曾经学习过grep命令,这个命令可以从文件中过滤出 包含指定字符串模式 的行。
比如我们有个文件file1,里面有的行包含了mike 这个词。如果我们想把所有包含mike的行都找出来。 可以执行命令 grep mike file1 。
当grep命令中没有文件参数的时候比如 grep mike, 它就会等待我们在标准输入(一般是putty终端设备)中输入一行行的内容,进行实时的过滤
在Linux操作过程中,我们经常需要 将一个命令的输出的内容,给另一个命令作为输入的内容 进行处理。
比如,我们想查出进程号是 6536 的进程的信息。
我们用ps -ef 可以显示出所有的进程信息,但是这里面的内容太多了,我想过滤出其中包含 6536 字符串的行。
当然可以 用重定向符号 ps –ef > info.txt , 然后再使用grep从 info.txt中过滤 grep 6536 info.txt
但是这样比较麻烦,我们可以使用 管道操作符 。
我们看 这个命令 ps –ef | grep 6536
注意其中的 竖线 | , 这个就是管道操作符,它起的作用就是
● 将 前面的 ps –ef 命令的stdout(本来是输出到终端设备的) 重定向到一个 临时管道设备里面,
● 同时 将后一个命令 grep 6536 的stdin重定向到这个临时的管道设备。
那么这时会发生什么事情呢?ps –ef 命令的结果直接被 命令 grep 6536 过滤出来了。
这个过程可以用如下示意图表示
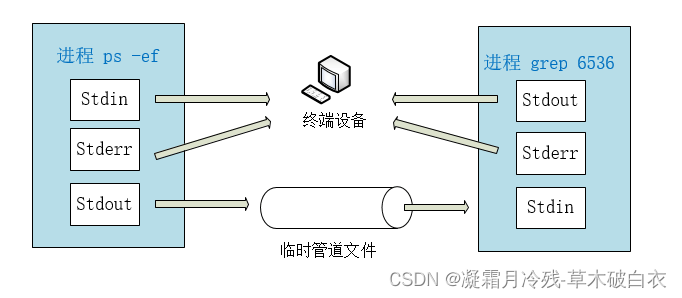
ps -ef | grep python == ps -ef >tmp1 grep python tmp1 > 标准输出tmp1
grep python < tmp1 < 标准输入tmp1
获取关键字
grep -r 'bind-address'
常用命令
apt安装软件包
在 Ubuntu上,安装软件通常使用 apt (全称 Advanced Packaging Tool) 软件包管理工具安装。
apt 能够从指定的 apt 源服务器自动下载安装包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
缺省的 apt 源服务器 (国内的是cn.archive.ubuntu.com)访问往往比较慢。
如果在安装Ubuntu时 , 就更换了源,会快很多。
如果安装Ubuntu时,没有更换源,现在想换,可以修改配置文件 /etc/apt/source.list, 把里面源服务器域名从 cn.archive.ubuntu.com 改为为国内的
比如网易的 mirrors.163.com , 或者阿里云的 mirrors.aliyun.com
步骤如下
-
以root账号登录,或者后续命令前面加 sudo 以root执行
-
执行命令 cd /etc/apt 进入到目录 /etc/apt 下
-
执行命令 cp sources.list sources.list.bak 先创建备份文件,这样万一改错,可以有备份文件恢复
-
执行 vi sources.list 打开文件, 准备把域名从从 cn.archive.ubuntu.com 替换为 mirrors.163.com
-
按 冒号,进入底行模式,输入命令 1,$s/cn.archive.ubuntu.com/mirrors.163.com/g 进行替换
-
确认一下域名修改正确后,输入 :wq 保存退出。
-
执行命令 apt update , 让修改生效
apt 命令用法
apt install package1
安装指定的安装包package1, 比如 apt install net-tools
apt list --installed
显示所有已经安装的程序包
apt list package1
显示指定程序包package1的安装情况
apt remove package1
删除程序包package1
删除不需要的依赖包
apt autoremove
默认情况下使用apt install安装包时,会自动下载安装包及其依赖包到/var/cache/apt/archieves目录,可通过如下配置改变这一行为:
#禁止保存
echo 'Binary::apt::APT::Keep-Downloaded-Packages "0";' | sudo tee /etc/apt/apt.conf.d/10apt-keep-downloads
#允许保存
echo 'Binary::apt::APT::Keep-Downloaded-Packages "1";' | sudo tee /etc/apt/apt.conf.d/10apt-keep-downloads
启动、重启、关闭服务
Linux上有些软件程序是以服务的形式安装的,比如 SSH 服务、 MySQL服务、 nginx服务等。
这些 软件 的启动、重启、关闭 要使用特殊的命令
在当前的 Ubuntu 系统上,使用命令 systemctl 来 启动、重启、关闭 服务。
比如,
要查看 服务 ssh 状态, 执行命令 systemctl status ssh
要启动 服务 ssh, 执行命令 systemctl start ssh
要重启 服务 ssh, 执行命令 systemctl restart ssh
要关闭 服务 ssh, 执行命令 systemctl stop ssh
构建web静态服务器nginx
apt install net-tools
apt install nginx
浏览器输入Ubuntu IP即可登陆
打包与压缩
打包
Linux下打包的最常用命令是tar 命令,可将多个文件、目录打包到一个文件中。
下面是使用tar命令打包的操作演示:
在当前工作目录下面创建3个文件,使用下列命令:
touch 123.txt 456.txt 789.txt
将这3个文件放到一个文件包files.tar,使用下列命令:
tar cvf files.tar 123.txt 456.txt 789.txt
也可以使用通配符,如 *.txt,这样的格式代表以txt结尾的文件
tar cvf files1.tar *.txt
tar命令同样可以打包目录,假设 当前目录下 byhy是一个子目录,byhy.txt是一个文件
tar cvf byhy.tar ./byhy byhy.txt
这个命令就把目录 byhy 和 文件 byhy.txt 都 打包到 文件 byhy.tar 中了。
要 将 上面创建的 files1.tar 解压到当前目录,使用下列命令:
tar xvf files.tar
如果只是想查看 上面创建的 files1.tar 内容,使用下列命令:
tar tvf files.tar
如果想 在 files1.tar中 添加 新文件 newfile,使用下列命令:
tar rvf files.tar newfile
注意:tar命令只是把文件、目录打包到一个文件中。 并不会压缩文件
压缩
gzip命令用于文件的压缩与解压缩,压缩后的文件名后缀为“.gz”
比如
要 压缩文件abc.txt ,执行命令
gzip abc.txt
这样就产生了一个名为 abc.txt.gz 的压缩后的文件
要 解压文件abc.txt.gz,执行命令
gzip -d abc.txt.gz
tar工具与gzip工具联合使用,实现打包并压缩、解压缩并解包功能
假设 在当前目录有如下3个文件 touch 111.txt 222.txt 333.txt
我们要,打包并压缩这3个文件,放到压缩包文件 byhy.tar.gz里面,使用下面命令:
tar zcvf byhy.tar.gz *.txt
解压缩并解包,使用下面命令:
tar zxvf byhy.tar.gz
● bzip2、zip 压缩、解压
bzip2 和 zip 也是常见的压缩解压工具, 使用方法和 gzip 类似
如下
---------------------------------------------
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
---------------------------------------------
.zip
解压:unzip FileName.zip
压缩:zip -r FileName.zip DirName
---------------------------------------------
注意:如果你的Linux上没有安装 bzip2、zip、unzip,可以执行命令 apt install bzip2 zip unzip 来安装
.xz方法压缩解压
压缩包xz格式的比7z要小,但是压缩时间比较长
xz使用格式
压缩
xz -z filename
解压
xz -d filename
tar格式
压缩
tar -cvf filename
解压
tar -xvf filename
另外,也可以直接解压
tar xvJf node-v6.10.1-linux-x64.tar.xz
两层压缩,外面是xz压缩方式,里层是tar压缩
所以可以分两步实现解压
| 1 2 |
$ xz -d node-v6.10.1-linux-x64.tar.xz
$ tar -xvf node-v6.10.1-linux-x64.tar
|
top 查看系统进程的动态运行情况
执行top命令可以查看 当前系统中,运行的进程的信息,比如
[root@localhost ~]# top
top - 14:01:00 up 15:52, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 97 total, 1 running, 96 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 2895572 total, 2507692 free, 118824 used, 269056 buff/cache
KiB Swap: 3145724 total, 3145724 free, 0 used. 2598756 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2041 root 20 0 0 0 0 S 0.3 0.0 0:03.60 kworker/0:3
1 root 20 0 127960 6580 4104 S 0.0 0.2 0:01.91 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.29 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kworker/u2:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:01.94 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-dra+
11 root rt 0 0 0 0 S 0.0 0.0 0:00.48 watchdog/0
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
14 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
15 root 20 0 0 0 0 S 0.0 0.0 0:00.01 khungtaskd
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 writeback
17 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd
18 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
● CPU 整体负载
在这行显示了 CPU 整体负载
Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
● 各个CPU 的负载(按键盘1,可以在整体cpu和所有cpu之间切换)
Cpu0 : 0.3%us, 0.3%sy, 0.0%ni, 97.7%id, 1.3%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
缺省情况下,进程列表里就是按CPU占用率来排序的。
如果不是,可以按快捷键大写的P要求top按照CPU占用率来排序。(按b,再按x可以显示当前排序列)
KiB Mem : 2895572 total, 2507692 free, 118824 used, 269056 buff/cache
KiB Swap: 3145724 total, 3145724 free, 0 used. 2598756 avail Mem
注意:上面显示 2507692 free,并非只有 2507692 的内存可用。
因为 buffer 和 cache 部分的内存都是临时缓存用了, 其实也是可用的内存
实际可用的内存大概是 free + buffers + cached
按快捷键大写的 M 可以 对进程列表按照内存使用率来排序
top -p 5413 只看nginx的进程
查看系统内存使用情况
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 2827 115 2449 8 262 2538
Swap: 3071 0 3071
查看设置系统时间
date 可以用来显示或设定系统的日期与时间。
[byhy@localhost ~]$ date
Mon Nov 7 23:25:05 PST 2018
运行tzselect来选择时区
tzselect
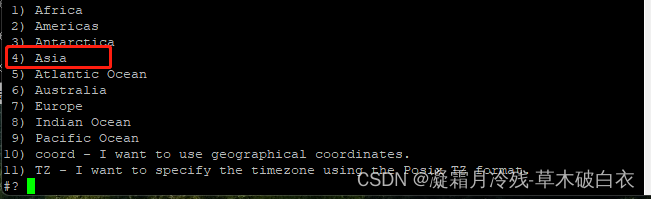
选择4
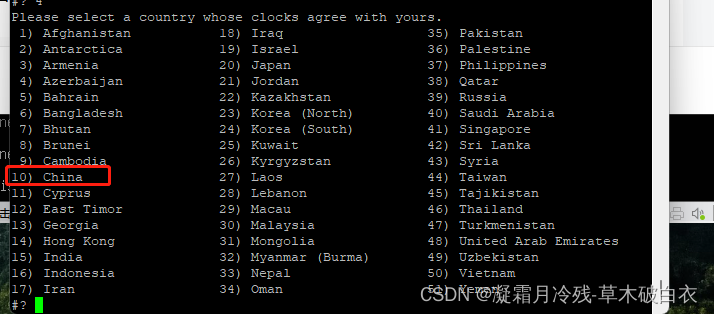
选择10

选择1
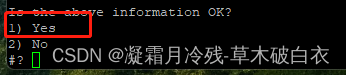
选择1确认
复制文件到/etc/localtime目录下
也可以直接跳过步骤2 直接将Shanghai的文件复制到/etc/localtime目录下
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看时区
-
date -R
-
# 此时,时区应该为北京时区'+0800'
设置时间
# 修改日期
sudo date -s 11/28/20
# 修改时间
sudo date -s 11:21:30
修改硬件的CMOS时间
# 修改 硬件CMOS时间
sudo hwclock --systohc
# 注意: 这个步骤非常重要,如果没有这一步,重启后,时区又会发生改变
使用date查看当前时间
date
# date -s 20161109
# date -s 21:05:50
查看系统版本
# uname -a
Linux byhy-server 5.4.0-80-generic #90-Ubuntu SMP Fri Jul 9 22:49:44 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
说明 5.4.0 为Linux内核的版本。
- 执行命令
lsb_release -a 查看Ubuntu系统版本信息
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.2 LTS
Release: 20.04
Codename: focal
其中,显示Ubuntu发行版本为 20.04 版本
网络管理
查看网络接口IP地址
查看所有网络接口的IP地址,可以使用命令 ip addr
例如:
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:e1:71:e8 brd ff:ff:ff:ff:ff:ff
inet 192.168.50.64/24 brd 192.168.50.255 scope global dynamic enp0s3
valid_lft 86125sec preferred_lft 86125sec
inet6 fe80::a00:27ff:fee1:71e8/64 scope link
valid_lft forever preferred_lft forever
上面显示了 两个网络接口 lo 和 enp0s3。其中 lo 是环回接口,我们关注的应该是 enp0s3 这个接口。
上面命令的结果显示:enp0s3 这个接口 的 IPv4 地址是 192.168.50.64
启用、禁用网络接口
启用和禁用网络接口,常用的是 ifup 和 ifdown ,要使用root用户执行
Ubuntu 现在缺省是没有这两个命令的, 可以先运行 apt install ifupdown 安装一下。
● 启用网络接口
使用命令 ifup,比如下面的命令就是启用网络接口 enp0s3
ifup enp0s3
● 禁用网络接口
使用命令 ifdown,比如下面的命令就是禁用网络接口 enp0s3
ifdown enp0s3
ping 检测网络连通性
我们经常需要检查是否可以从本机访问某个远程主机,这时应该使用 ping 命令
例如:
$ ping 192.168.100.1
PING 192.168.100.1 (192.168.100.1) 56(84) bytes of data.
64 bytes from 192.168.100.1: icmp_seq=1 ttl=64 time=0.158 ms
64 bytes from 192.168.100.1: icmp_seq=2 ttl=64 time=0.228 ms
64 bytes from 192.168.100.1: icmp_seq=3 ttl=64 time=0.281 ms
上面的结果就表示 本机 和 IP 为192.168.100.1 的设备(可能是计算机也可能是路由器)之间的网络是通畅的。
可以按 ctrl+C 终止 测试。
netstat 查看网络状态
Ubuntu 现在缺省安装的查看网络状态的工具是 Socket Statistics, 命令名为 ss 。
但是 目前这个工具使用还不是特别广泛,目前查看网络状态大多数人还是会使用著名的 netstat 。
netstat 这个命令通常用来 查看各种与网络相关的状态信息,包括:网络的连接、状态、接口的统计信息、路由表、端口的监听情况。
但是 Ubuntu 现在缺省没有安装这个netstat, 可以使用命令 sudo apt install net-tools 安装 net-tools 工具包后,即可使用。
常用参数:
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 不显示端口协议名,显示端口数字
-l 只显示 Listen (监听) 的状态端口
-p 显示建立相关链接的进程PID
-r 显示路由信息,路由表
Netstat 最常用的地方就是查看网络连接情况,比如查看22端口上的tcp网络连接情况
使用命令 netstat -anp|grep 22 |grep tcp
netstat -anp|grep :80
[root@localhost ~]# netstat -anp |grep 22 |grep tcp
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 977/sshd
tcp 0 52 192.168.10.199:22 192.168.10.92:63911 ESTABLISHED 2011/sshd: root@pts
tcp6 0 0 :::22 :::* LISTEN 977/sshd
ssh(secure shell)登录远程机器
之前我们使用的是Windows下面的终端模拟器PuTTY 远程登录Linux主机。
在Linux下,也可以远程登录其他Linux主机,只需要运行ssh命令即可。
命令的格式如下
ssh 用户名@IP地址或机器域名
比如,你要 使用 user1 账号 远程登录 192.168.1.12 这台Linux机器,执行下面的命令
[byhy@localhost ~]$ ssh user1@192.168.1.12
一般首次登录某个主机的时候,会出现如下提示:
The authenticity of host '192.168.1.12 (192.168.1.12)' can't be established.
RSA key fingerprint is cf:2c:22:d1:e8:4e:f3:16:43:09:9c:c6:fe:fc:9a:22.
Are you sure you want to continue connecting (yes/no)?
这是因为该远程机器没有被认证过(可能会有‘中间人’攻击的安全隐患),让你确认一下。这里如果是局域网里面的机器,一般安全没有什么问题,输入yes并回车即可。
接下来,会提示输入对应用户的密码,你输入正确的密码即可登录。
scp 拷贝文件
在Linux上,可以直接使用scp命令 和远程Linux主机 进行文件的拷贝。
scp是secure copy的缩写,意为文件安全拷贝,它可以将远程Linux系统上的文件拷贝到本地计算机,也可以将本地计算机上的文件拷贝到远程Linux系统上。
比如:
我们已经登录到主机A上面,要将 /home/byhy1 目录下面的文件abc.txt,拷贝到主机B的/home/byhy2目录下面,主机B的IP地址为:192.168.1.12
我们要拷贝到 B主机, 必须要有B主机的用户账号, 假如B主机的账号是 byhy2,应该这样写
scp /home/byhy1/abc.txt byhy2@192.168.1.12:/home/byhy2
接下来,会提示用户输入用户byhy2的密码,输入正确密码后,进行拷贝操作。
如果,我们要 在主机A上面,将主机B上面的文件/home/byhy2/123.txt 拷贝到主机A的/tmp/下面:
scp byhy2@192.168.1.12:/home/byhy2/123.txt /tmp/
在windows机器上,我们可以使用 WinSCP 工具和远程Linux主机 进行文件的拷贝。
点击这里下载WinSCP
这个工具,安装好后,创建一个到远程Linux主机的连接,随后只要在界面拖动文件即可完成下载,上传文件。
wget下载
Linux中,要从网络下载文件,可以使用 wget。
wget就是一个下载文件的命令行工具。
例如:
wget https://mirrors.aliyun.com/centos/timestamp.txt
防火墙
通常网站服务之类的产品运行在Ubuntu上,我们会开启防火墙。防止恶意的网络访问和攻击。
Ubuntu目前使用命令 ufw (uncomplicated firewall) 管理防火墙功能。
缺省 ufw 是未被激活的,执行如下命令激活。
ufw enable
注意:这个命令最好是在 虚拟机终端执行。
如果是Putty远程登录,并且当前没有允许SSH访问的ufw规则,执行这个命令可能就会断开连接。
可以执行如下命令检查 当前的 防火墙设置
ufw status
或者查看更详细的信息
ufw status verbose
● 开放端口
如果我们允许 外面从网络访问 本机的 SSH TCP 服务端口 22 ,应该这样执行命令
ufw allow 22/tcp
如果你知道端口对应的服务名,也可以使用名字。
比如下面的命令可以允许外面从网络访问 本机的 ssh 服务
sudo ufw allow ssh
比如下面的命令可以允许外面从网络访问 本机的 HTTP 服务端口 80
ufw allow http
关闭防火墙
Sudo ufw disable
● 删除规则
要删除一个前面设定的规则,执行下面的命令
ufw delete allow http
打开文档
getit a.txt