目录
引言
一、List简介
二、常用List实现类
(一)ArrayList
(二)LinkedList
(三)LinkedList和ArrayList的比较
三、其他List实现类
(一)Vector
(二)Stack
(三)CopyOnWriteArrayList
四、List的一些补充
(一)遍历List
(二)线程同步问题
(三)List排序问题
结语
引言
无论学习什么编程语言,语法和数据结构总是绕不开的知识点;在面试过程中,集合也是面试官常常提问的知识点之一。List是一个常用的集合,这里就对一些常用的、面试可能会碰到的一些List进行一个知识点的总结。
一、List简介
1. 功能描述
List是Java中最常用的集合之一,我们常常使用List存储一些数据量大小未知且未来可能需要添加或者删除操作的数据。
List在Java中是一个泛型接口接口,其接口中的参数化类型E表示的是List中存储的数据类型。关于List接口的详细描述,我们可以查看下面的Java 8官方文档中对List接口的描述:
An ordered collection (also known as a sequence ). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
—— Java 8官方文档
笔者渣翻:一个有序的集合(也可以说是序列)。接口的使用者可以准确的控制元素插入到列表中的任意位置。使用者可以通过元素的整数下标在列表中访问、查找列表中的元素。
2. 继承介绍
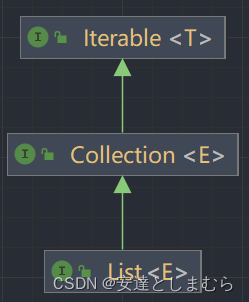
接口的继承关系如下图所示:
List接口的集成关系
在图中我们可以看到,List接口继承自Collection接口,Collection接口又继承自Iterable接口。这些接口都有什么作用,我们从最上面的说起。
Iterable是一个泛型接口,我们直译这个接口的名字就能大概明白它的作用,“可迭代的”。在这个接口中只定义了三个方法,但只有一个是抽象的,它们分别是forEach()、iterator()和spliterator(),其中iterator()是抽象方法,forEach()和spliterator()为默认实现,作用反别是遍历以及得到一个分割器(也有叫拆分器的,有许多叫法,都是指Spliterator)。iterator()返回值是一个迭代器,用于遍历元素。因此,只要实现该接口,就表明实现类是可迭代的,即可以使用迭代器对其进行遍历。
Collection继承自Iterable接口,因此,Collection接口同样也是一个泛型接口。我们对接口名称进行直译,翻译为“集合”。由此可见,Collection接口是对集合工具类的规范进行书写的一个规范接口,也是集合层次中的根接口。在其中定义了一些集合工具类统一规范:size()、isEmpty()、contains()、toArray()等。根据Java 8的官方文档,在Jdk中并没有直接提供该接口的实现类,只有该接口具体子接口。因此该接口一般用于集合的传递和需要最大泛用性的地方(使用Java的多态特性接收使参数可以同时接收List、Set等继承了Collection接口的集合),如下面列举的Collection接口中的两种使用。
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
3. 常用实现类
在List接口下,有许多的实现类与实现抽象类,但在我们平常的开发中并不是所有都能用到。
常用的如下(重点):
ArrayList、LinkedList
面试时可能会碰到的如下:
Vector、Stack、copyOnWriteArrayList
二、常用List实现类
(一)ArrayList
1. ArrayList简介
Resizable-array implementation of the List interface. Implements all optional list operations, and permits all elements, including null. In addition to implementing the List interface, this class provides methods to manipulate the size of the array that is used internally to store the list. (This class is roughly equivalent to Vector, except that it is unsynchronized.)
—— Java 8官方文档
笔者渣翻:(ArrayList)是List接口下可变长度数组的实现。实现了所有可选的List操作,并且允许所有类型的元素,包括null。除了实现List接口外,该类还提供了一些用于操作在内部存储列表的数组的长度。(该类与Vector相比,除了不同步外都大致相同)
该类的声明如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable总结:基于数组实现、允许有重复元素、允许有空元素、线程不安全、支持随机访问、可克隆、可序列化
2. ArrayList原理
通过查看官方文档我们知道,ArrayList底层是基于数组来实现的,我们查看Jdk(这里使用的是 Jdk 8)中的源码深入了解一下ArrayList。
进入ArrayList源码,首先映入眼帘的就是一下几个参数:
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;这几个参数中一些是比较容易理解的——DEFAULT_CAPACITY,ArrayList的默认容量;elementData,ArrayList用于存储元素的数组;size,ArrayList的当前长度。
而EMPTY_ELEMENTDATA和DEFAULTCAPACITY_EMPTY_ELEMENTDATA两个Object数组的用处后面再做解释。
(1)构造方法
参数后面便是ArrayList的构造方法,先看我们最常用(maybe)的无参构造:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}使用无参构造方法时,直接将DEFAULTCAPACITY_EMPTY_ELEMENTDATA赋值给了elementData,得到一个初始容量为10的ArrayList。
至于为什么初始容量是10,后面讲解add()方法时再做解释。
除了无参构造外,ArrayList还有一个接收一个int类型参数的构造方法。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: " +
initialCapacity);
}
}由方法中的形参名称便可猜出接收到的这个变量是干什么的。没错,这个构造方法就是接收一个ArrayList的初始化容量,然后使用这个容量构造ArrayList内部的Object数组。如果这个容量为0,则使用ArrayList中已经进行了初始化的EMPTY_ELEMENTDATA作为elementData的值。如果容量小于0,则抛出非法参数异常。
最后,ArrayList还可以通过其他Collection接口的实现类来构造一个实例:
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
elementData = EMPTY_ELEMENTDATA;
}
}在方法中可以看到,先通过Collection中声明了的toArray()方法将Collection转换为一个Object[] a,将a的length赋值给ArrayList的成员变量size。然后判断size是否等于0,如果是,则领elementData等于EMTPTY_ELEMENTDATA;否则,判断Collection的类型,如果是ArrayList,将a赋值给elementData,如果不是,则使用Arrays工具类对a进行拷贝,结果赋值给elementData。
(2)add()方法
下面详细讲解一下添加元素的过程,不想看过程可以直接看下面的红字总结,面试喜欢问。
add()的源码如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
} ensureCapacityInternal()的源码如下:
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}calculateCapacity()的源码如下:
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
} ensureExplicitCapacity()的源码如下:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}grow()的源码如下:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}列了这么多的方法,我们一个一个来看。
首先我们从add()方法开始,在方法的第一行就调用了ensureCapacityInternal()方法,我们通过直译得到这个方法的作用,确保内部容量,参数是minCapacity,值为size + 1,意思是最小容量应该是size + 1。然后在ensureCapacityInternal()方法内又调用了一个计算容量的方法,也即calculateCapacity()方法。在calculateCapacity()方法的内部我们看到有一个判断,判断elementData是否是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,如果是,返回size + 1和DEFAULT_CAPACITY(具体值为10)的最大值,否则返回size + 1。这里就解释了上面使用无参构造方法时初始容量为10。
在此之后,将计算得到的容量作为参数,调用了一个ensureExplicitCapacity(),确认显式容量。在该方法中首先对modCount进行了自增,modCount时ArrayList中定义的用来记录数组修改次数的一个成员变量。然后判断size + 1是否大于element.length来决定是否需要调用grow()方法来增加ArrayList的容量。
在grow()方法中,定义了两个临时变量oldCapacity和newCapacity。oldCapacity为elementData的长度,newCapacity为oldCapacity加上oldCapacity右移一位的结果,
相当于newCapacity = oldCapacity + oldCapacity / 2。然后在下面有一个newCapacity和MAX_ARRAY_SIZE的比较,MAX_ARRAY_SIZE是ArrayList内定义的一个常量,值为int最大值减8。如果newCapacity大,则调用hugeCapacity()方法返回int最大值或者MAX_ARRAY_SIZE作为新容量,如果size + 1 < 0,则抛出OOM(out of memory)异常。确定了新容量后,使用Arrays工具类对elementData进行拷贝,结果赋值给elementData。
确认是否需要扩容后,将需要添加的元素放到elementData中索引为size的位置,然后size自增,返回true。
以上就是add()方法的执行全过程。总结一下就是先确定添加这个元素是否需要对容器进行扩容操作,如果容器有空位,则不进行扩容;否则,采取一般扩容策略进行扩容操作,即新容量为老容量加上老容量的一半,如果新容量超过了MAX_ARRAY_SIZE,则看具体情况使用int最大值或者MAX_ARRAY_SIZE作为新容量。扩容完成后,将元素存到数组中,size自增。如果当前容量为int最大值且容器已经装满,无法扩容,抛出OOM异常。
针对一般扩容策略,这里举个栗子,初始容量为10,扩容后为10 + 10 / 2 = 15;15容量扩容后为15 + 15 / 2 = 22。以此类推……
-----------------------------------------------------------------------------------------------
到这里我觉得在我在面试中经常被问到的ArrayList相关的知识点也整理的差不多了,虽然还有很多操作和方法没有将,但是每一个都讲实在写不了了(悲),因此在这里只详细介绍了较为典型的add()操作。在理解了add()操作后再看其他操作相信也是如吃饭喝水一般了。对其他操作感兴趣的同学也可以自行阅读源码。如果觉得笔者上面讲的还是不怎么清楚,“纸上得来终觉浅”,自己debug一下或许也就念头通达了呢~
(二)LinkedList
1. LinkedList简介
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
Note that this implementation is not synchronized.
—— Java 8官方文档
笔者渣翻:(LinkedList)是Deque接口和List接口双向链表的实现。实现了所有List接口中的可选操作,并且允许所有类型的元素(包括空元素)。
所有操作地执行都和双向链表的期望一样。有用到List中索引的所有操作都将从(链表的)开始或者结尾遍历,从哪一段开始由索引距离哪一端近决定。
需要注意的是,此实现不是同步的。
该类的声明如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable总结:基于双向链表实现、允许有重复元素、允许有空元素、线程不安全、可克隆、可序列化
2. 链表基础
因为怕一些小伙伴没学过C语言或是数据结构的知识,理解这一块的知识有一定的障碍,因此这里对链表的知识进行一个补充。
觉得对链表有一定了解的小伙伴可以直接跳过这一部分。
(1)链表介绍
链表是一种物理存储单元 上非连续、非顺序的存储结构 ,数据元素 的逻辑顺序是通过链表中的指针 链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素 的数据域,另一个是存储下一个结点地址的指针 域。 相比于线性表 顺序结构 ,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间。
—— 百度百科
上述是百度百科中对链表的描述,读起来比较抽象,可以结合下面的栗子自己理解一下。
链表使用图形更加形象的表示出来如图:
其中每一个大方框表示链表中的一个节点。而在节点中又分为两部分(实际上一个节点解释一个完整的类,不作区分,这里为了形象强行分了出来),data部分用于存储数据,next是一个指针,指向下一个节点,也即存储了下一个节点的地址。最后一个节点的next指针则只想null。head是指向第一个节点的指针,称为“头指针”。一般来说,头指针不储存数据(也有储存数据的,看个人习惯)。
(2)链表的遍历、查找
由于链表是不同于数组的数据结构,数组是在内存中一片连续的区域,因此可以使用索引进行随机访问和快速遍历;而链表在内存中的存储可以是不连续的,因此在查找时不能通过索引直接获取到对应的元素。
因此需要使用一个指针p,令这个指针p等于头指针head,然后可以获取到第一个元素。获取到第一个元素后,令p等于第一个节点的next,因此指针就由最开始的指向第一个节点变为指向第二个节点。以此循环往复,直到p等于null就遍历完了整个链表。如果是查找的话,直到满足查找条件或者p为null即可。
(3)链表的插入和删除
因为插入和删除本质上都差不多,删除实际上就是插入的逆过程,因此,考略到篇幅原因,这里只讲插入。
数组中,在指定位置插入一个元素是非常困难的。因为你必须将该位置以及位置后面的所有元素往后挪一位,为插入元素腾出位置。
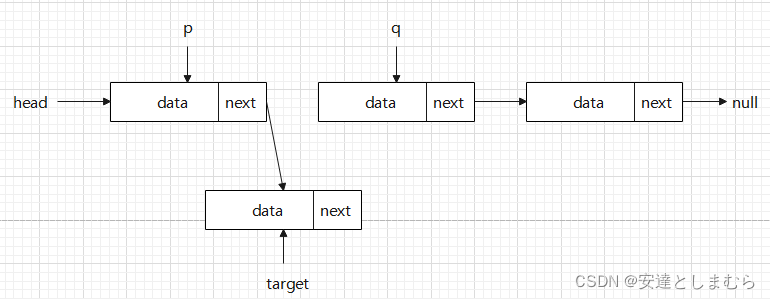
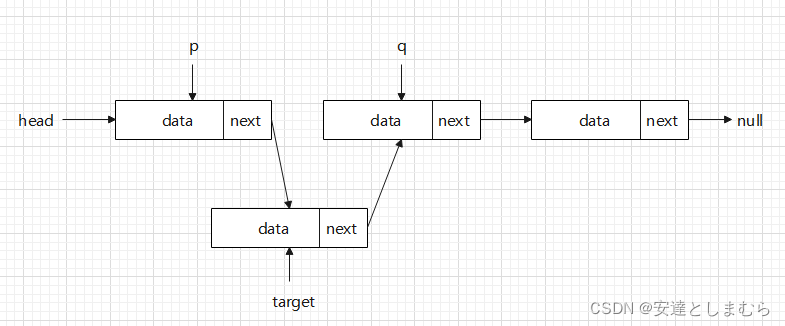
而链表中因为节点之间在内存中并不连续,因此只需要对节点中的next作文章即可。代码如下:
// 这里虚构一个类Node,表示节点
// 找到需要插入的位置p
// 需要插入的节点为target
Node q = p.next;
p.next = taget;
target.next = q; 形象表示如下:
(4)双向链表
以上所描述的都是单向链表,双向链表是对单向链表的升级。每个节点不只有后指针,也有一个前指针指向前一个结点。这样做解决了单向链表只能单向遍历的弊端。
形象表示如下:
双向链表再插入和删除时就必须对前指针和后指针都进行更改和设置,相较于单向链表操作更加复杂。
LinkedList的底层实现使用的就是双向链表。
3. LinkedList的使用
(1)链表节点
在LinkedList中,双向链表节点的实现使用了内部类的形式,代码如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}(2)LinkedList的使用
LinkedList一般作为栈、队列的替代使用,在算法中使用的较多。
-----------------------------------------------------------------------------------------------
LinkedList中也是有许多操作的,这里为什么不详细介绍呢?因为LinkedList内部操作还是比较简单的,具体一些查询、插入、删除等操作和基础链表中的操作相差无几,因此不多赘述。对链表操作不熟悉的小伙伴可以参考上面的链表基础或是参照其他数据结构教学资源自行了解。
(三)LinkedList和ArrayList的比较
这里使用Junit进行测试,测试类如下:
public class AppTest {
private List<Integer> linked;
private List<Integer> array;
@Before
public void before() {
linked = new LinkedList<>();
array = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
linked.add(i);
array.add(i);
}
}
}
这里再每个测试方法执行前,使用@Before注解对两个List进行初始化,存入了0-9999,即10000个数字,然后运行测试方法进行时间比较。
注:测试的运行时间根据不同的电脑配置、Jdk版本、测试方法、Junit版本而不同。
1. 插入、删除操作
测试代码:
@Test
public void testList() {
// 插入测试
long sta = System.nanoTime();
array.add(0, 0);
long end = System.nanoTime();
System.out.println("ArrayList在0处插入所需时间" + (end - sta) + " ns");
sta = System.nanoTime();
linked.add(0, 0);
end = System.nanoTime();
System.out.println("LinkedList在0处插入所需时间" + (end - sta) + " ns");
// 删除测试
sta = System.nanoTime();
array.remove(0);
end = System.nanoTime();
System.out.println("ArrayList在0处删除所需时间" + (end - sta) + " ns");
sta = System.nanoTime();
linked.remove(0);
end = System.nanoTime();
System.out.println("LinkedList在0处删除所需时间" + (end - sta) + " ns");
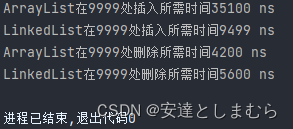
}在0处进行插入和删除:
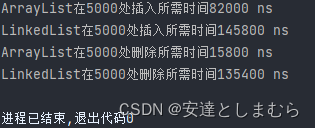
在5000处插入和删除:
在9999处插入和删除:
2. 根据索引取值
测试代码:
@Test
public void testList() {
long sta = System.nanoTime();
array.get(5000);
long end = System.nanoTime();
System.out.println("ArrayList在5000处取值所需D时间" + (end - sta) + " ns");
sta = System.nanoTime();
linked.get(5000);
end = System.nanoTime();
System.out.println("LinkedList在5000处取值所需时间" + (end - sta) + " ns");
}
3. 遍历
测试代码:
@Test
public void testList() {
long sta = System.nanoTime();
for (Integer i : array) {
int integer = i;
}
long end = System.nanoTime();
System.out.println("ArrayList遍历时间" + (end - sta) + " ns");
sta = System.nanoTime();
for (Integer i : linked) {
int integer = i;
}
end = System.nanoTime();
System.out.println("LinkedList遍历时间" + (end - sta) + " ns");
}
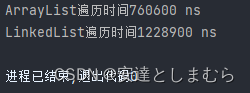
-----------------------------------------------------------------------------------------------
结论:在插入和删除上,如果数据量较小时,理论上LinkedList是要比ArrayList要快的;如果数据量比较的庞大,在对List两端或是离两端较近的位置上进行操作时,依然是LinkedList较快,但是在靠近中间的位置时,ArrayList要快一点(因为LinkedList要从开头或是结尾处一个一个遍历,数据量大时比较耗时)。
在根据索引取值上更是不必多说,数据量越大,两者之间的取值时间相差就越大,在这方面ArrayList完胜。在遍历方面,ArrayList以零点几毫秒的时间差小胜LinkedList。
因此,在平常开发中,使用哪种List储存数据得根据实际需求、数据量大小、使用场景来自行定夺。
三、其他List实现类
(一)Vector
The Vector class implements a growable array of objects. Like an array, it contains components that can be accessed using an integer index. However, the size of a Vector can grow or shrink as needed to accommodate adding and removing items after the Vector has been created.
......
Unlike the new collection implementations, Vector is synchronized. If a thread-safe implementation is not needed, it is recommended to use ArrayList in place of Vector.
—— Java 8官方文档
笔者渣翻:Vector类实现了一个长度可变的对象数组。跟数组一样,它包含了可以通过整数索引访问的组件。但是,Vector的长度可以根据需要增长或缩短,以此来适应Vector在创建实例后的添加和删除元素。
……
不像新集合的实现,Vector是同步的。如果不需要线程安全的实现,推荐使用ArrayList来代替Vector。
总结:基于数组实现、允许有重复元素、允许有空元素、线程安全、支持随机访问、可克隆、可序列化
-----------------------------------------------------------------------------------------------
Vector的使用、一般扩容策略基本与ArrayList相差无几,它们俩最大的区别就是线程安全还是不安全。Vector在几乎所有的方法上都加了synchronized关键字。
可能会奇怪,多线程现如今使用较广,为什么Vector会被人们忽略?
(1)Vector效率低下。 Vector使用的是synchronized关键字实现的线程同步,而synchronized关键字施加的是一种重量级的锁,加锁和释放锁都会非常的耗费系统资源,因此耗时会很大,效率也就非常低下。
(2)Vector是伪线程安全的。 虽然Vector对绝大多数方法都加上了synchronized关键字,表示同一时间只能用一个线程使用这个方法。但是,该关键字不能防止两个线程同一时间使用不同的方法。例如同时添加和删除。例如下面这段代码,一个线程进行添加操作,令一个线程进行删除操作,当数据量足够大时,就会抛出越界异常。因此,在对Vector进行复杂的操作时,要想实现真正的线程安全,还必须在Vector外面再加锁,非常的麻烦且耗费资源。
public class App {
private static final Vector<Integer> VECTOR = new Vector<>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
VECTOR.add(i);
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
VECTOR.remove(0);
}
}
}).start();
}
}
(二)Stack
The Stack class represents a last-in-first-out (LIFO) stack of objects. It extends class Vector with five operations that allow a vector to be treated as a stack.
—— Java 8官方文档
笔者渣翻:Stack类表示一个后进先出(LIFO)的对象栈。它通过五种操作扩展了Vector类来让一个Vector可以被看做一个栈。
总结:Vector的子类、线程安全、后进先出
-----------------------------------------------------------------------------------------------
Stack作为Vector的一个子类,在平时开放中同样不怎么能被人们想起。它逐渐过气的原因与它的父类基本相同,除此之还,它的作用也逐渐被Deque(双端队列接口)所取代。
(三)CopyOnWriteArrayList
A thread-safe variant of ArrayList in which all mutative operations (add, set, and so on) are implemented by making a fresh copy of the underlying array.
......
All elements are permitted, including null.
—— Java 8官方文档
笔者渣翻:(CopyOnWriteArrayList)是一个ArrayList线程安全的变体,所有元素变动操作(添加、设置等)都是通过创建一个基本数组的副本来实现的。
……
允许所有元素,包括空元素。
总结:基于数组实现、允许有重复元素、允许有空元素、线程安全、支持随机访问、可克隆、可序列化
-----------------------------------------------------------------------------------------------
CopyOnWriteArrayList同样也是相当于线程安全版的ArrayList,为什么Vector就遭到了冷落?
(1)CopyOnWriteArrayList的锁机制相较于Vector更加轻量级。 CopyOnWriteArrayList的锁没有Vector的锁那么耗费资源,因此在效率上要比Vector高。
(2)CopyOnWriteArrayList是真·线程安全。 参见Vector条目。
四、List的一些补充
(一)遍历List
1. for循环遍历
这是比较笨重,但是也是使用最广泛、最基础的一种遍历方式,参考代码如下:
List<Integer> list = new ArrayList<>();
... // 添加元素、删除元素等
for (Integer i : list) {
System.out.println(i);
}List<Integer> list = new ArrayList<>();
... // 添加元素、删除元素等
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
2. 迭代器遍历
因为集合类都实现了Iterable接口,因此可以通过该接口中定义的iterator()方法获取到一个该列表的迭代器,通过这个迭代器来遍历列表,参考代码如下:
List<Integer> list = new ArrayList<>();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
3. forEach lambda遍历
通过Iterable接口中定义的forEach()方法,该方法时Iterable接口中的默认实现。参考代码如下:
List<Integer> list = new ArrayList<>();
list.forEach(i -> {
System.out.println(i);
});
4. stream forEach遍历
该方法是通过调用Collection接口中定义的默认实现方法stream(),将List转换为Stream,通过遍历Stream,简介实现对List的遍历:
List<Integer> list = new ArrayList<>();
list.stream().forEach(i -> {
System.out.println(i);
});-----------------------------------------------------------------------------------------------
这里列举了4种,准确来说是5种遍历List的方式,使用下面的测试代码在Junit种对每种遍历方式测得了遍历时间:
@Before
public void before() {
for (int i = 0; i < 100000000; i++) {
list.add(i);
}
}
@Test
public void testList() {
long sta = System.nanoTime();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
long end = System.nanoTime();
System.out.printf("%-21s%d ns\n", "普通for遍历耗时", (end - sta));
sta = System.nanoTime();
for (Integer i : list) {
Integer a = i;
}
end = System.nanoTime();
System.out.printf("%-21s%d ns\n", "增强for遍历耗时", (end - sta));
sta = System.nanoTime();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
iterator.next();
}
end = System.nanoTime();
System.out.printf("%-21s%d ns\n", "迭代器遍历耗时", (end - sta));
sta = System.nanoTime();
list.forEach((i) -> {
Integer a = i;
});
end = System.nanoTime();
System.out.printf("%-21s%d ns\n", "forEach方法遍历耗时", (end - sta));
sta = System.nanoTime();
list.stream().forEach((i) -> {
Integer a = i;
});
end = System.nanoTime();
System.out.printf("%-21s%d ns\n", "stream forEach方法遍历耗时", (end - sta));
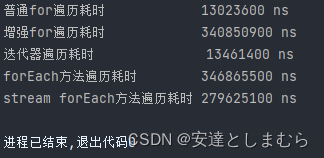
}在List种初始化了1亿个整数,测试结果如下:
结论:普通for、迭代器 < stream forEach < 增强for、forEach方法
这里如果追求效率的话推荐使用迭代器,追求功能性强大的话推荐使用stream。
如果对stream不熟悉的话,可以学习我之前写的stream API详解。
学习笔记(一):Java中Stream的基本用法和相关API详解
(二)线程同步问题
之前稍微介绍了一点List与线程相关的一点问题,下面详细讲一下如何得到一个线程安全的List集合。
1. 使用CopyOnWriteArrayList代替ArrayList
使用前面讲解过的CopyOnWriteArrayList可以很好的解决线程安全问题,但是得考虑资源消耗问题。
2. 使用Collections工具类中的synchronizedList()方法进行包装
该方法封装在Collections工具类中,是一个静态方法,可以直接通过类名调用。synchronizedList()方法接收一个List对象list,该方法会判断list是否实现了RandomAccess接口,对应返回一个基于list创建的SynchronizedRandomAccessList或是SynchronizedList的实例。这两个类都是线程同步的List集合,一个支持随机访问,一个不支持。
代码示例:
List<String> list = Collections.synchronizedList(new ArrayList<>()); 通过同步方法包装后便可以跟普通List一样使用了。
3. 使用早期的线程安全的集合(不推荐)
如果你对前面两种方法都不熟悉,可以使用Vector等早期的线程安全的集合,但是这里还是推荐学习前两种方法。这里非常不推荐早期的线程安全的集合。
(三)List排序问题
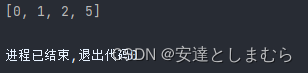
1. Collections.sort()
在集合工具类Collections中有对List排序的sort()方法。该方法有两种重载,接收一个List对象以及接收一个List对象和比较器。当List中的元素的类实现了Comparable接口,可以使用一个参数的排序方法;如果没有实现可比较接口,则必须提供一个比较器,使用两个参数的sort()方法。
@Test
public void testList() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(0);
Collections.sort(list);
System.out.println(list);
}
2. 通过Stream对List排序
我们可以先将List转化为Stream,然后使用Stream中的sort()方法进行排序。
如果对stream不熟悉的话,可以学习我之前写的stream API详解。
学习笔记(一):Java中Stream的基本用法和相关API详解
@Test
public void testList() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(0);
list = list.stream()
.sorted()
.collect(Collectors.toList());
System.out.println(list);
}
3. TreeSet
TreeSet是Java中一个不包含重复元素的Set集合,它的底层基于红黑树来维护,因此将List集合中的元素一个一个加入TreeSet中时也就对List完成了排序。
TreeSet的详细讲解后面也会更新的Set集合笔记中讲解。
@Test
public void testList() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(0);
list = new ArrayList<>(new TreeSet<>(list));
System.out.println(list);
}
-----------------------------------------------------------------------------------------------
上面介绍了三种对List排序方法,这较为推荐的的Stream,因为Stream不但可以对List进行排序,而且可以进行映射、查找等各种操作,非常的方便,笔者平时也非常喜欢使用这种方式。如果对stream不熟悉的话,可以学习我之前写的stream API详解。
学习笔记(一):Java中Stream的基本用法和相关API详解
结语
非常感谢看完这接近两万字的文章,我们应该大概可能也许不一定还会更新其他类型的集合讲解吧,对你有帮助的话还请点一个免费的赞或者收藏,想看后面的详解也可以点一个关注哦,非常感谢。
虽说讲的也比较多了,但是还是有许多的地方没有讲的很清楚,感兴趣的小伙伴也可以查询相关资料或是阅读源码自行理解。这里推荐阅读Java官方文档结合源码食用理解更加透彻哦。
笔者也是前一两个月才开始写文章的,有待改进、书写错误、逻辑漏洞、知识讲解有误的地方还请指出,大家友善讨论。
有不理解的地方也可以私信,或是评论留言。