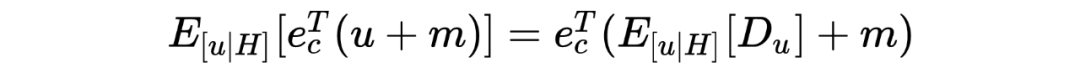加了干预后 P(Y|do(X)):遍历 Z 集合中所有的物体,计算干预后的条件概率,可以看到 P(Y|do(X))>P(Y|X),直觉上在“人”和“马桶”观测数据不足的情况下,因果干预后的条件概率有相应正向调整。
2.1.3 实现
训练目标为预测指定 ROI 的类别,Loss 包括两部分任务,1)Self Predict:直接 ROI 特征 x 通过全连接层预测其 label,2)Context Predict:基于待识别物体 y 的 ROI 以及其上下文物体 ROI 特征,预测 y 的 label,一张图片中 K 个上下文物体特征求和取评价。完整 Loss 如下:
其中 M 就是优化器的动量,X 是模型提取的特征,Y 是预测值。D 是 X 在动量特征下的带偏置的表示(基于 M 和 X 的特性 D 更偏好头部类别)。优化器的动量 M 包含了数据集的分布信息,他的动态平均会显著地将优化方向倾向于多数类,这也就造成了模型中的参数会有生成头部类特征的倾向,该部分偏好则体现在 D 中。
类似的,消除混淆因子 M 带来的头部类别偏置的方法也比较明确,即通过后门调整进行因果干预:
训练阶段优化
,以断开 M->X 之间的路径:
模型训练好后的预测阶段,由 得到最终预测结果,文中中
为 0 向量,其子项表示 M 对头部的偏置项,二者相减表示剔除了头部偏置的预测结果。
2.5.3 实现
训练时,后门调整需要计算:
由于无法得到 M 的分布,文章使用带 normalize 的 multi-head 来近似,这点类似 [4] 中的“基于特征维度分层”。具体的,将分类器输出维度等分成 K 份,可以看作是对模型进行了更细粒度的采样,而 P(M) 近似为 1/K,因此有:
从表达式上来看可以近似的理解为输入特征 x 和类别
的表示权重向量
的余弦相似度(表示该类别的置信概率),同时需要注意的是这里 x 依赖 m,而在公式中没有明示。
预测阶段:
公式比较复杂推导过程论文中有详细推倒过程,其意义是从 training 的 logits 中剔除代表对头部类过度倾向的部分。前者为
后者为
,
为协调因子进行 trade off。
小结
几篇论文读下来,感觉各文章的思路有不少共通之处(可能也与论文师出同源有关,哈哈)。大致“套路”是:
1)从数据和现象出发,分析基线模型的因果图假设和混杂因子;2)建立新的因果图(opt);3)因果干预;4)近似 do 算子网络计算;5)效果提升。话说回来,虽然脉络大致相同,但每个工作也都能给人新奇的感觉,尤其 [5] 想到从优化器的角度切入,实在佩服。
[1] Wang T, Huang J, Zhang H, et al. Visual commonsense r-cnn[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10760-10770.
[2] Zhang D, Zhang H, Tang J, et al. Causal intervention for weakly-supervised semantic segmentation[J]. arXiv preprint arXiv:2009.12547, 2020.
[3] Qi J, Niu Y, Huang J, et al. Two causal principles for improving visual dialog[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10860-10869.
[4] Yue Z, Zhang H, Sun Q, et al. Interventional few-shot learning[J]. arXiv preprint arXiv:2009.13000, 2020.
[5] Tang K, Huang J, Zhang H. Long-tailed classification by keeping the good and removing the bad momentum causal effect[J]. arXiv preprint arXiv:2009.12991, 2020.
[6] Yang X, Zhang H, Cai J. Deconfounded image captioning: A causal retrospect[J]. arXiv preprint arXiv:2003.03923, 2020.