目录
1、W初始值的设定
2、反向传播算法
反向传播的实例:
在其他的一些算法中对于分类问题易出现项数过多、过度拟合的情况,所以这里用一个新的方法来神经网络来解决问题,神经网络可以很好的适用特征空间n很大的情况。
用图像来做一些名词解释。在图像中,我们通常称Xo,X1,X2,X3为输入层input layer,中间不对用户输出结果的层我们称为隐藏层hidden layer,最后输出结果的为输出层output layer。像Xo,ao我们称为偏置单元,通常默认值为1。

在神经网络中,我们可以很好的解决多分类问题。如下图所示,我们可以利用下图的四个输出单元来判断到底属于什么类型的图片。
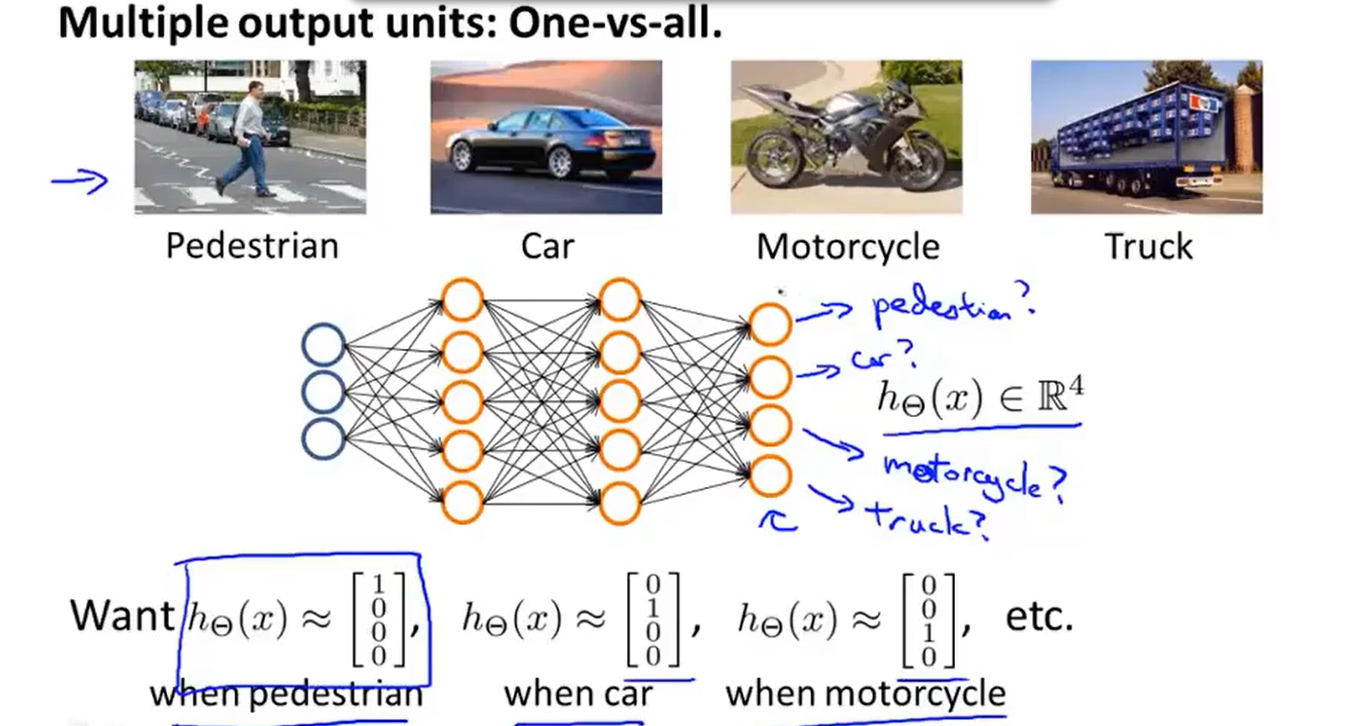
训练神经网络的步骤:
①构建一个神经网络、随机初始化权重
②正向传播,计算出相应的输出值Y的向量
③计算出代价函数
④通过反向传播算法,求出偏导数项
⑤将用数值方法得到的偏导数的预估值与反向传播算法得到的偏导数的值进行比较
⑥使用一个优化算法(例如梯度下降算法)


1、W初始值的设定
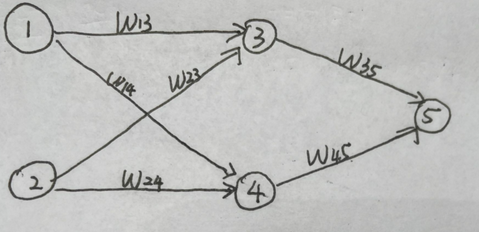
我们是否可以跟以前一样直接把所有W(在吴恩达教授的课程里面用θ来表示,都是一样的)设置为0呢?在这下面这个图中,如果我们把W13,W14,W23,W24,W35,W45全部都设置为0,会怎么样呢?我们可以得到W13,W23对X3的影响权重是一样的,在进行一次更新之后W13,W23的值不会为0,但是一定的是W13=W23,所有的都是如此,他们的权重都是一样的,对于这种情况,我们称之为高度冗余。
我们通常采用的方法是随机初始化W的值。初始化一个为10*11的矩阵(根据需要自己设定)。

2、反向传播算法
这里首先要讲解一下反向传播算法。什么是反向传播算法,说实话,我搞了一两天看着网上的一堆公式实在是看的晕乎乎的,只知道反向传播算法是链式求导,但是却不明白具体是什么东西,这里我将用一个实际的例子来说明什么是反向传播算法。
定义:反向传播算法就是用更新权值来最小化损失函数;
①正向传播;
正向传播计算出来的预测值Y
②损失函数;
 (这里的1/2是为了方便求偏微分)
(这里的1/2是为了方便求偏微分)
③反向传播计算偏微分;
这里最难理解,看下面的实例解释。
反向传播的实例:
将用一个简单的两层神经网络来解释(我赋予了他们一些具体的数值):
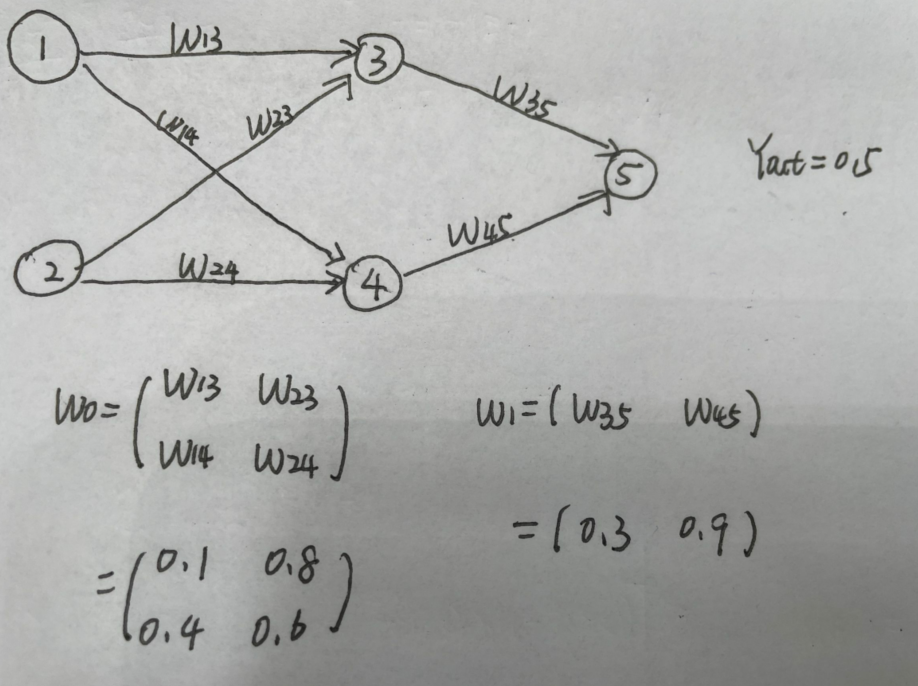
①正向传播:
以下的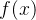 为激活函数,
为激活函数, ,
,
以后会用到对激活函数它的导数,![f'(x)=f(x)*[1-f(x)]](https://latex.csdn.net/eq?f%27%28x%29%3Df%28x%29*%5B1-f%28x%29%5D) ,可自己对求导证明。
,可自己对求导证明。
言归正传,首先对于第一层隐藏层(3、4)

然后对于第二层隐藏层(5)

这里我们得到的 就是我们的预测值
就是我们的预测值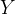 。
。
②损失函数;
(这里的1/2是为了方便求偏微分)
③反向传播计算偏微分;
我们计算 的偏微分是为了更新其值,将
的偏微分是为了更新其值,将
 ,以此类推更新,然后减小
,以此类推更新,然后减小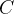 误差函数。
误差函数。
我们应该怎么求得 呢? 首先我们整理关于
呢? 首先我们整理关于 的公式有:
的公式有:



然后根据链式求导

现在我们来求 ,整理出公式
,整理出公式


同理,根据链式求导得:

已经可以求得所有的W的偏微分了,然后令
至此,“反向传播算法”及公式推导的过程总算是讲完了啦!