写好的单元测试,对开发速度、项目维护有莫大的帮助。前端的测试工具一直推陈出新,而测试的核心、原则却少有变化。与产品代码一并交付可靠的测试代码,是每个专业开发者应该不断靠近的一个理想之地。本文就围绕测试讲讲,为什么我们要做测试,什么是好的测试和原则,以及如何在一个 React 项目中落地这些测试策略。
本文使用的测试框架、断言工具是 jest。文章不打算对测试框架、语法本身做过多介绍,因为已有很多文章。本文假定读者已有一定基础,至少熟悉语法,但并不假设读者写过单元测试。在介绍什么是好的单元测试时,我会简单介绍一个好的单元测试的结构。
为什么要做单元测试
-
有且仅有一个失败的理由
表达力极强
快、稳定
单元测试的上下文
测试策略:测试金字塔
如何写好单元测试:好测试的特征
React 单元测试策略及落地
-
业务型组件 - 分支渲染
业务型组件 - 事件调用
功能型组件 - children 型高阶组件
来自官方的错误姿势
正确姿势
React 应用的单元测试策略
actions 测试
reducer 测试
selector 测试
saga 测试
component 测试
utils 测试
总结
为什么要做单元测试
虽然关于测试的文章有很多,关于 React 的文章也有很多,但关于 React 应用之详细单元测试的文章还比较少。而且更多的文章都更偏向于对工具本身进行讲解,只讲「我们可以这么测」,却没有回答「我们为什么要这么测」、「这么测究竟好不好」的问题。这几个问题上的空白,难免使人得出测试无用、测试成本高、测试使开发变慢的错误观点,导致在「质量内建」已渐入人心的今日,很多人仍然认为测试是二等公民,是成本,是锦上添花。这一点上,我的态度一贯鲜明:不仅要写测试,还要把单元测试写好;不仅要有测试前移质量内建的意识,还要有基于测试进行快速反馈快速开发的能力。没自动化测试的代码不叫完成,不能验收。
「为什么我们需要做单元测试」,这是一个关键的问题。每个人都有自己关于该不该做测试、该怎么做、做到什么程度的看法,试图面面俱到、左右逢源地评价这些看法是不可能的。我们需要一个视角,一个谈论单元测试的上下文。做单元测试当然有好处,但本文不会从有什么好处出发来谈,而是谈,在我们在意的这个上下文中,不做单元测试会有什么问题。
那么我们谈论单元测试的上下文是什么呢?不做单元测试我们会遇到什么问题呢?
单元测试的上下文
先说说问题。最大的一个问题是,不写单元测试,你就不敢重构,就只能看着代码腐化。代码质量谈不上,持续改进谈不上,个人成长更谈不上。始终是原始的劳作方式。
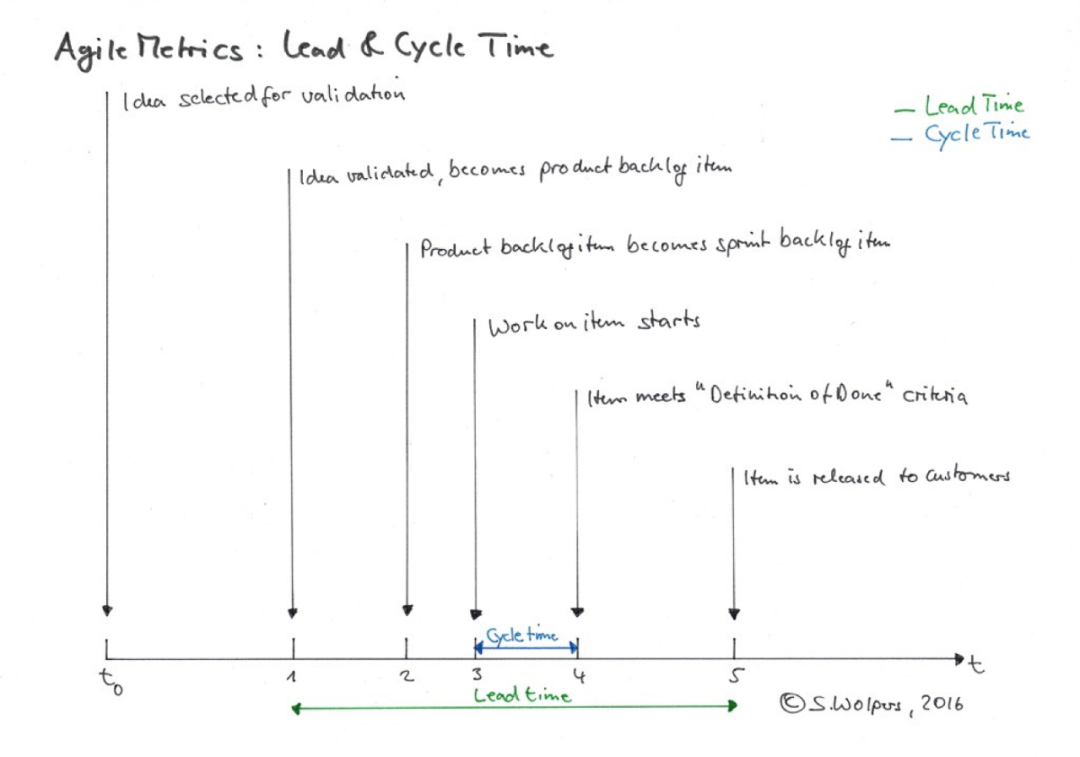

再说说上下文。我认为单元测试的上下文存在于「敏捷」中。现代企业数字化竞争日益激烈,业务端快速上线、快速验证、快速失败的思路对技术端的响应力提出了更高的要求:更快上线、更频繁上线、持续上线。怎么样衡量这个「更快」呢?那就是第一图提到的 lead time,它度量的是一个 idea 从提出并被验证,到最终上生产环境面对用户获取反馈的时间。显然,这个时间越短,软件就能越快获得反馈,对价值的验证就越快发生。这个结论对我们写不写单元测试有什么影响呢?答案是,不写单元测试,你就快不起来。为啥呢?因为每次发布,你都要投入人力来进行手工测试;因为没有测试,你倾向于不敢随意重构,这又导致代码逐渐腐化,复杂度使得你的开发速度降低。
再考虑到以下两个大事实:人员会流动,应用会变大。人员一定会流动,需求一定会增加,再也没有任何人能够了解任何一个应用场景。因此,意图依赖人、依赖手工的方式来应对响应力的挑战首先是低效的,从时间维度上来讲也是不现实的。那么,为了服务于「高响应力」这个目标,我们就需要一套自动化的测试套件,它能帮我们提供快速反馈、做质量的守卫者。唯解决了人工、质量的这一环,效率才能稳步提升,团队和企业的高响应力才可能达到。
那么在「响应力」这个上下文中来谈要不要单元测试,我们就可以很有根据了,而不是开发爽了就用,不爽就不用这样含糊的答案:
如果你说我的业务部门不需要频繁上线,并且我有足够的人力来覆盖手工测试,那你可以不用单元测试
如果你说我是个小项目小部门不需要多高的响应力,每天摸摸鱼就过去了,那你可以不用单元测试
如果你说我不在意代码腐化,并且我也不做重构,那你可以不用单元测试
如果你说我不在意代码质量,好几个没有测试保护的 if-else 裸奔也不在话下,脑不好还做什么程序员,那你可以不用单元测试
如果你说我确有快速部署的需求,但我们不 care 质量问题,出回归问题就修,那你可以不用单元测试 除此之外,你就需要写单元测试。如果你想随时整理重构代码,那么你需要写单元测试;如果你想有自动化的测试套件来帮你快速验证提交的完整性,那么你需要写单元测试;如果你是个长期项目有人员流动,那么你需要写单元测试;如果你不想花大量的时间在记住业务场景和手动测试应用上,那么你就需要单元测试。
至此,我们从「响应力」这个上下文中,回答了「为什么我们需要写单元测试」的问题。接下来可以谈下一个问题了:「为什么是单元测试」。
测试策略:测试金字塔
上面我直接从高响应力谈到单元测试,可能有的同学会问,高响应力这个事情我认可,也认可快速开发的同时,质量也很重要。但是,为了达到「保障质量」的目的,不一定得通过测试呀,也不一定得通过单元测试鸭。
这是个好的问题。为了达到保障质量这个目标,测试当然只是其中一个方式,稳定的自动化部署、集成流水线、良好的代码架构、组织架构的必要调整等,都是必须跟上的设施。我从未认为单元测试是解决质量问题的银弹,多方共同提升才可能起到效果。但相反,也很难想象单元测试都没有都写不好的项目,能有多高的响应力。
即便我们谈自动化测试,未必也不可能全部都是写单元测试。我们对自动化测试套件寄予的厚望是,它能帮我们安全重构已有代码、保存业务上下文、快速回归。测试种类多种多样,为什么我要重点谈单元测试呢?因为~~这篇文章主题就是谈单元测试啊…~~它写起来相对最容易、运行速度最快、反馈效果又最直接。下面这个图,想必大家都有所耳闻:
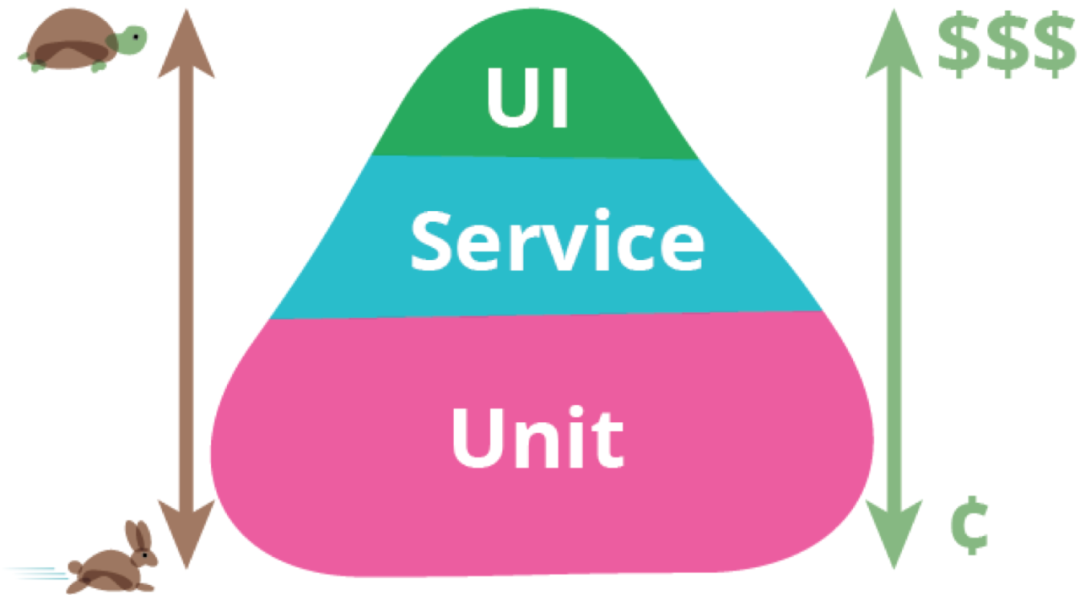

这就是有名的测试金字塔。对于一个自动化测试套件,应该包含种类不同、关注点不同的测试,比如关注单元的单元测试、关注集成和契约的集成测试和契约测试、关注业务验收点的端到端测试等。正常来说,我们会受到资源的限制,无法应用所有层级的测试,效果也未必最佳。因此,我们需要有策略性地根据收益-成本的原则,考虑项目的实际情况和痛点来定制测试策略:比如三方依赖多的项目可以多写些契约测试,业务场景多、复杂或经常回归的场景可以多写些端到端测试,等。但不论如何,整个测试金字塔体系中,你还是应该拥有更多低层次的单元测试,因为它们成本相对最低,运行速度最快(通常是毫秒级别),而对单元的保护价值相对更大。
以上是对「为什么我们需要的是单元测试」这个问题的回答。接下来一小节,就可以正式进入如何做的环节了:「如何写好单元测试」。
关于测试金字塔的补充阅读:测试金字塔实战。
如何写好单元测试:好测试的特征
写单元测试仅仅是第一步,下面还有个更关键的问题,就是怎样写出好的、容易维护的单元测试。好的测试有其特征,虽然它并不是什么新的东西,但总需要时时拿出来温故知新。很多时候,同学感觉测试难写、难维护、不稳定、价值不大等,可能都是因为单元测试写不好所导致的。那么我们就来看看,一个好的单元测试,应该遵循哪几点原则。
首先,我们先来看个简单的例子,一个最简单的 JavaScript 的单元测试长什么样:
// production code
const computeSumFromObject = (a, b) => {
return a.value + b.value
}
// testing code
it('should return 5 when adding object a with value 2 and b with value 3', () => {
// given - 准备数据
const a = { value: 2 }
const b = { value: 3 }
// when - 调用被测函数
const result = computeSumFromObject(a, b)
// then - 断言结果
expect(result).toBe(5)
})
以上就是一个最简答的单元测试部分。但麻雀虽小,五脏基本全,它揭示了单元测试的一个基本结构:准备输入数据、调用被测函数、断言输出结果。任何单元测试都可以遵循这样一个骨架,它是我们常说的 given-when-then 三段式。
为什么说单元测试说来简单,做到却不简单呢?除了遵循三段式,显然我们还需要遵循一些其他的原则。前面说到,我们对单元测试寄予了几点厚望,下面就来看看,它如何能达到我们期望的效果,以此来反推单元测试的特征:
下面来看看这三个原则都是咋回事:
有且仅有一个失败的理由
有且仅有一个失败的理由,这个理由是什么呢?是 「当输入不变时,当且仅当被测业务代码功能被改动了」时,测试才应该挂掉。为什么这会支持我们重构呢,因为重构的意思是,在不改动软件外部可观测行为的基础上,调整软件内部实现的一种手段。也就是说,当我被测的代码输入输出没变时,任我怎么倒腾重构代码的内部实现,测试都不应该挂掉。这样才能说是支持了重构。有的单元测试写得,内部实现(比如数据结构)一调整,测试就挂掉,尽管它的业务本身并没修改,这样怎么支持重构呢?不怪得要反过来骂测试成本高,没有用。一般会出现这种情况,可能是因为是先写完代码再补的测试,或者对代码的接口和抽象不明确所导致。
另外,还有一些测试(比如下文要看到的 saga 官方推荐的测试),它需要测试实现代码的执行次序。这也是一种「关注内部实现」的测试,这就使得除了业务目标外,还有「执行次序」这个因素可能使测试挂掉。这样的测试也是很脆弱的。
表达力极强
表达力极强,讲的是两方面:
这些表达力体现在许多方面,比如测试描述、数据准备的命名、与测试无关数据的清除、断言工具能提供的比对等。空口无凭,请大家在阅读后面测试落地时时常对照。
快、稳定
不快的单元测试还能叫单元测试吗?一般来讲,一个没有依赖、没有 API 调用的单元测试,都能在毫秒级内完成。那么为了达到快、稳定这个目标,我们需要:
在后面的介绍中,我会将这些原则落实到我们写的每个单元测试中去。大家可以时时翻到这个章节来对照,是不是遵循了我们说的这几点原则,不遵循是不是确实会带来问题。时时勤拂拭,莫使惹尘埃啊。
React 单元测试策略及落地

React 应用的单元测试策略
上个项目上的 React(-Native) 应用架构如上所述。它涉及一个常见 React 应用的几个层面:组件、数据管理、redux、副作用管理等,是一个常见的 React、Redux 应用架构,也是 dva 所推荐的 66%的最佳实践(redux+saga),对于不同的项目应该有一定的适应性。架构中的不同元素有不同的特点,因此即便是单元测试,我们也有针对性的测试策略:

对于这个策略,这里做一些其他补充:
关于不测 redux connect 过的组件这个策略。理由是成本远高于收益:要牺牲开发体验(搞起来没那么快了),要配置依赖(配置 store、,在大型或遗留系统中补测试还很可能遇到 @connect 组件里套 @connect 组件的场景);然后收益也只是可能覆盖到了几个极少数出现的场景。得不偿失,果断不测。
关于 UI 测试这块的策略。团队之前尝试过 snapshot 测试,对它寄予厚望,理由是成本低,看起来又像万能药。不过由于其难以提供精确快照比对,整个工作的基础又依赖于开发者尽心做好「确认比对」这个事情,很依赖人工耐心又打断日常的开发节奏,导致成本和收益不成正比。我个人目前是持保留态度的。
关于 DOM 测试这块的策略。也就是通过 enzyme 这类工具,通过 css selector 来进行 DOM 渲染方面的测试。这类测试由于天生需要通过 css selector 去关联 DOM 元素,除了被测业务外 css selector 本身就是挂测试的一个因素。一个 DOM 测试至少有两个原因可使它挂掉,并不符合我们上面提到的最佳实践。但这种测试有时又确实有用,后文讲组件测试时会专门提到,如何针对它制定适合的策略。
actions 测试
这一层太过简单,基本都可以不用测试,获益于架构的简单性。当然,如果有些经常出错的 action,再针对性地对这些 action creator 补充测试。
export const saveUserComments = (comments) => ({
type: 'saveUserComments',
payload: {
comments,
},
})
import * as actions from './actions'
test('should dispatch saveUserComments action with fetched user comments', () => {
const comments = []
const expected = {
type: 'saveUserComments',
payload: {
comments,
},
}
expect(actions.saveUserComments(comments)).toEqual(expected)
})
reducer 测试
reducer 大概有两种:一种比较简单,仅一一保存对应的数据切片;一种复杂一些,里面具有一些计算逻辑。对于第一种 reducer,写起来非常简单,简单到甚至可以不需要用测试去覆盖。其正确性基本由简单的架构和逻辑去保证的。下面是对一个简单 reducer 做测试的例子:
import Immutable from 'seamless-immutable'
const initialState = Immutable.from({
isLoadingProducts: false,
})
export default createReducer((on) => {
on(actions.isLoadingProducts, (state, action) => {
return state.merge({
isLoadingProducts: action.payload.isLoadingProducts,
})
})
}, initialState)
import reducers from './reducers'
import actions from './actions'
test('should save loading start indicator when action isLoadingProducts is dispatched given isLoadingProducts is true', () => {
const state = { isLoadingProducts: false }
const expected = { isLoadingProducts: true }
const result = reducers(state, actions.isLoadingProducts(true))
expect(result).toEqual(expected)
})
下面是一个较为复杂、更具备测试价值的 reducer 例子,它在保存数据的同时,还进行了合并、去重的操作:
import uniqBy from 'lodash/uniqBy'
export default createReducers((on) => {
on(actions.saveUserComments, (state, action) => {
return state.merge({
comments: uniqBy(state.comments.concat(action.payload.comments), 'id'),
})
})
})
import reducers from './reducers'
import actions from './actions'
test('should merge user comments and remove duplicated comments when action saveUserComments is dispatched with new fetched comments', () => {
const state = {
comments: [{ id: 1, content: 'comments-1' }],
}
const comments = [
{ id: 1, content: 'comments-1' },
{ id: 2, content: 'comments-2' },
]
const expected = {
comments: [
{ id: 1, content: 'comments-1' },
{ id: 2, content: 'comments-2' },
],
}
const result = reducers(state, actions.saveUserComments(comments))
expect(result).toEqual(expected)
})
reducer 作为纯函数,非常适合做单元测试,加之一般在 reducer 中做重逻辑处理,此处做单元测试保护的价值也很大。请留意,上面所说的单元测试,是不是符合我们描述的单元测试基本原则:
有且仅有一个失败的理由:当输入不变时,仅当我们被测「合并去重」的业务操作不符预期时,才可能挂掉测试
表达力极强:测试描述已经写得清楚「当使用新获取到的留言数据分发 action saveUserComments 时,应该与已有留言合并并去除重复的部分」;此外,测试数据只准备了足够体现「合并」这个操作的两条 id 的数据,而没有放很多的数据,形成杂音;
快、稳定:没有任何依赖,测试代码不包含准备数据、调用、断言外的任何逻辑
selector 测试
selector 同样是重逻辑的地方,可以认为是 reducer 到组件的延伸。它也是一个纯函数,测起来与 reducer 一样方便、价值不菲,也是应该重点照顾的部分。况且,稍微大型一点的项目,应该说必然会用到 selector。原因我讲在这里。下面看一个 selector 的测试用例:
import { createSelector } from 'reselect'
// for performant access/filtering in React component
export const labelArrayToObjectSelector = createSelector(
[(store, ownProps) => store.products[ownProps.id].labels],
(labels) => {
return labels.reduce(
(result, { code, active }) => ({
...result,
[code]: active,
}),
{}
)
}
)
import { labelArrayToObjectSelector } from './selector'
test('should transform label array to object', () => {
const store = {
products: {
10085: {
labels: [
{ code: 'canvas', name: '帆布鞋', active: false },
{ code: 'casual', name: '休闲鞋', active: false },
{ code: 'oxford', name: '牛津鞋', active: false },
{ code: 'bullock', name: '布洛克', active: true },
{ code: 'ankle', name: '高帮鞋', active: true },
],
},
},
}
const expected = {
canvas: false,
casual: false,
oxford: false,
bullock: true,
ankle: false,
}
const productLabels = labelArrayToObjectSelector(store, { id: 10085 })
expect(productLabels).toEqual(expected)
})
saga 测试
saga 是负责调用 API、处理副作用的一层。在实际的项目上副作用还有其他的中间层进行处理,比如 redux-thunk、redux-promise 等,本质是一样的,只不过 saga 在测试性上要好一些。这一层副作用怎么测试呢?首先为了保证单元测试的速度和稳定性,像 API 调用这种不确定性的依赖我们一定是要 mock 掉的。经过仔细总结,我认为这一层主要的测试内容有五点:
是否使用正确的参数(通常是从 action payload 或 redux 中来),调用了正确的 API
对于 mock 的 API 返回,是否保存了正确的数据(通常是通过 action 保存到 redux 中去)
主要的业务逻辑(比如仅当用户满足某些权限时才调用 API 等)
异常逻辑
其他副作用是否发生(比如有时有需要 Emit 的事件、需要保存到 IndexDB 中去的数据等)
来自官方的错误姿势
redux-saga 官方提供了一个 util: CloneableGenerator 用以帮我们写 saga 的测试。这是我们项目使用的第一种测法,大概会写出来的测试如下:
import chunk from 'lodash/chunk'
export function* onEnterProductDetailPage(action) {
yield put(actions.notImportantAction1('loading-stuff'))
yield put(actions.notImportantAction2('analytics-stuff'))
yield put(actions.notImportantAction3('http-stuff'))
yield put(actions.notImportantAction4('other-stuff'))
const recommendations = yield call(Api.get, 'products/recommended')
const MAX_RECOMMENDATIONS = 3
const [products = []] = chunk(recommendations, MAX_RECOMMENDATIONS)
yield put(actions.importantActionToSaveRecommendedProducts(products))
const {
payload: { userId },
} = action
const { vipList } = yield select((store) => store.credentails)
if (!vipList.includes(userId)) {
yield put(actions.importantActionToFetchAds())
}
}
import { put, call } from 'saga-effects'
import { cloneableGenerator } from 'redux-saga/utils'
import { Api } from 'src/utils/axios'
import { onEnterProductDetailPage } from './saga'
const product = (productId) => ({ productId })
test(`
should only save the three recommended products and show ads
when user enters the product detail page
given the user is not a VIP
`, () => {
const action = { payload: { userId: 233 } }
const credentials = { vipList: [2333] }
const recommendedProducts = [product(1), product(2), product(3), product(4)]
const firstThreeRecommendations = [product(1), product(2), product(3)]
const generator = cloneableGenerator(onEnterProductDetailPage)(action)
expect(generator.next().value).toEqual(
actions.notImportantAction1('loading-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction2('analytics-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction3('http-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction4('other-stuff')
)
expect(generator.next().value).toEqual(call(Api.get, 'products/recommended'))
expect(generator.next(recommendedProducts).value).toEqual(
firstThreeRecommendations
)
generator.next()
expect(generator.next(credentials).value).toEqual(
put(actions.importantActionToFetchAds())
)
})
这个方案写多了,大家开始感受到了痛点,明显违背我们前面提到的一些原则:
测试分明就是把实现抄了一遍。这违反上述所说「有且仅有一个挂测试的理由」的原则,改变实现次序也将会使测试挂掉
当在实现中某个部分加入新的语句时,该语句后续所有的测试都会挂掉,并且出错信息非常难以描述原因,导致常常要陷入「调试测试」的境地,这也是依赖于实现次序带来的恶果,根本无法支持「重构」这种改变内部实现但不改变业务行为的代码清理行为
为了测试两个重要的业务「只保存获取回来的前三个推荐产品」、「对非 VIP 用户推送广告」,不得不在前面先按次序先断言许多个不重要的实现
测试没有重点,随便改点什么都会挂测试
正确姿势
于是,针对以上痛点,我们理想中的 saga 测试应该:1) 不依赖实现次序;2) 允许仅对真正关心的、有价值的业务进行测试;3) 支持不改动业务行为的重构。如此一来,测试的保障效率和开发者体验都将大幅提升。
于是,我们发现官方提供了这么一个跑测试的工具,刚好可以用来完美满足我们的需求:runSaga。我们可以用它将 saga 全部执行一遍,搜集所有发布出去的 action,由开发者自由断言其感兴趣的 action!基于这个发现,我们推出了我们的第二版 saga 测试方案:runSaga + 自定义拓展 jest 的 expect 断言。最终,使用这个工具写出来的 saga 测试,几近完美:
import { put, call } from 'saga-effects'
import { Api } from 'src/utils/axios'
import { testSaga } from '../../../testing-utils'
import { onEnterProductDetailPage } from './saga'
const product = (productId) => ({ productId })
test(`
should only save the three recommended products and show ads
when user enters the product detail page
given the user is not a VIP
`, async () => {
const action = { payload: { userId: 233 } }
const store = { credentials: { vipList: [2333] } }
const recommendedProducts = [product(1), product(2), product(3), product(4)]
const firstThreeRecommendations = [product(1), product(2), product(3)]
Api.get = jest.fn().mockImplementations(() => recommendedProducts)
await testSaga(onEnterProductDetailPage, action, store)
expect(Api.get).toHaveBeenCalledWith('products/recommended')
expect(
actions.importantActionToSaveRecommendedProducts
).toHaveBeenDispatchedWith(firstThreeRecommendations)
expect(actions.importantActionToFetchAds).toHaveBeenDispatched()
})
这个测试略长,但它依然遵循 given-when-then 的结构。并且同样是测试「只保存获取回来的前三个推荐产品」、「对非 VIP 用户推送广告」两个关心的业务点,其中自有简洁的规律:
非常容易准备输入数据:action、store、mock API 返回
当输入不变时,无论你怎么修改优化内部实现,这个测试关心的业务场景都不会挂,真正做到了测试保护重构、支持重构的作用
可以仅断言你关心的点,忽略不重要或不关心的中间过程(比如上例中,我们就没有断言其他 notImportant 的 action 是否被 dispatch 出去)
与次序无关。调整产品代码内部 dispatch action 的次序也不会使测试失败
自定义的 expect(action).toHaveBeenDispatchedWith(payload) matcher 很有表达力,且出错信息友好.
这个自定义的 matcher 是通过 jest 的 expect.extend 扩展实现的:
expect.extend({
toHaveBeenDispatched(action) { ... },
toHaveBeenDispatchedWith(action, payload) { ... },
})
上面是我们认为比较好的副作用测试工具、测试策略和测试方案。使用时,需要牢记你真正关心的业务价值点(本节开始提到的 5 点),以及做到在较为复杂的单元测试中始终坚守三大基本原则。唯如此,单元测试才能真正提升开发速度、支持重构、充当业务上下文的文档。
component 测试
组件测试其实是实践最多,测试实践看法和分歧也最多的地方。React 组件是一个高度自治的单元,从分类上来看,它大概有这么几类:
展示型业务组件
容器型业务组件
通用 UI 组件
功能型组件
先把这个分类放在这里,待会回过头来谈。对于 React 组件测什么不测什么,我有一些思考,也有一些判断标准:除去功能型组件,其他类型的组件一般是以渲染出一个语法树为终点的,它描述了页面的 UI 内容、结构、样式和一些逻辑 component(props) => UI。内容、结构和样式,比起测试,直接在页面上调试反馈效果更好。测也不是不行,但都难免有不稳定的成本在;逻辑这块,还是有一测的价值,但需要控制好依赖。综合「好的单元测试标准」作为原则进行考虑,我的建议是:两测两不测。
组件分支渲染逻辑必须测
事件调用和参数传递一般要测
纯 UI 不在单元测试层级测
连接 redux 的高阶组件不测
其他的一般不测(比如 CSS,官方文档有反例)
组件的分支逻辑,往往也是有业务含义和业务价值的分支,添加单元测试既能保障重构,还可顺便做文档用;事件调用同样也有业务价值和文档作用,而事件调用的参数调用有时可起到保护重构的作用。
纯 UI 不在单元测试级别测试的原因,纯粹就是因为不好断言。所谓快照测试有意义的前提在于两个:必须是视觉级别的比对、必须开发者每次都认真检查。jest 有个 snapshot 测试的概念,但那个 UI 测试是代码级的比对,不是视觉级的比对,最终还是绕了一圈,去除了杂音还不如看 Git 的 commit diff。每次要求开发者自觉检查,既打乱工作流,也难以坚持。考虑到这些成本,我不推荐在单元测试的级别来做 UI 类型的测试。对于我们之前中等规模的项目,诉诸手工还是有一定的可控性。
连接 redux 的高阶组件不测。原因是,connect 过的组件从测试的角度看无非几个测试点:
mapStateToProps 中是否从 store 中取得了正确的参数
mapDispatchToProps 中是否地从 actions 中取得了正确的参数
map 过的 props 是否正确地被传递给了组件
redux 对应的数据切片更新时,是否会使用新的 props 触发组件进行一次更新
这四个点,react-redux 已经都帮你测过了,已经证明 work 了,为啥要重复测试自寻烦恼呢?当然,不测这个东西的话,还是有这么一种可能,就是你 export 的纯组件测试都是过的,但是代码实际运行出错。穷尽下来主要可能是这几种问题:
你在 mapStateToProps 中打错了字或打错了变量名
你写了 mapStateToProps 但没有 connect 上去
你在 mapStateToProps 中取的路径是错的,在 redux 中已经被改过
第一、二种可能,无视。测试不是万能药,不能预防人主动犯错,这种场景如果是小步提交发现起来是很快的,如果不小步提交那什么测试都帮不了你的;如果某段数据获取的逻辑多处重复,则可以考虑将该逻辑抽取到 selector 中并进行单独测试。
第三种可能,确实是问题,但发生频率目前看来较低。为啥呢,因为没有类型系统我们不会也不敢随意改 redux 的数据结构啊…(这侵入性重的框架哟)所以针对这些少量出现的场景,不必要采取错杀一千的方式进行完全覆盖。默认不测,出了问题或者经常可能出问题的部分,再策略性地补上测试进行固定即可。
综上,@connect 组件不测,因为框架本身已做了大部分测试,剩下的场景出 bug 频率不高,而施加测试的话提高成本(准备依赖和数据),降低开发体验,模糊测试场景,性价比不大,所以强烈建议省了这份心。不测 @connect 过的组件,其实也是 官方文档 推荐的做法。
然后,基于上面第 1、2 个结论,映射回四类组件的结构当中去,我们可以得到下面的表格,然后发现…每种组件都要测渲染分支和事件调用,跟组件类型根本没必然的关联…不过,功能型组件有可能会涉及一些其他的模式,因此又大致分出一小节来谈。

业务型组件 - 分支渲染
export const CommentsSection = ({ comments }) => (
<div>
{comments.length > 0 && <h2>Comments</h2>}
{comments.map((comment) => <Comment content={comment} key={comment.id} />)}
</div>
)
对应的测试如下,测试的是不同的分支渲染逻辑:没有评论时,则不渲染 Comments header。
export const CommentsSection = ({ comments }) => (
<div>
{comments.length > 0 && <h2>Comments</h2>}
{comments.map((comment) => <Comment content={comment} key={comment.id} />)}
</div>
)
对应的测试如下,测试的是不同的分支渲染逻辑:没有评论时,则不渲染 Comments header。
import { CommentsSection } from './index'
import { Comment } from './Comment'
test('should not render a header and any comment ps when there is no comments', () => {
const component = shallow(<CommentsSection comments={[]} />)
const header = component.find('h2')
const comments = component.find(Comment)
expect(header).toHaveLength(0)
expect(comments).toHaveLength(0)
})
test('should render a comments p and a header when there are comments', () => {
const contents = [
{ id: 1, author: '男***8', comment: '价廉物美,相信奥康旗舰店' },
{ id: 2, author: '雨***成', comment: '所以一双合脚的鞋子...' },
]
const component = shallow(<CommentsSection comments={contents} />)
const header = component.find('h2')
const comments = component.find(Comment)
expect(header.html()).toBe('Content')
expect(comments).toHaveLength(2)
})
业务型组件 - 事件调用
测试事件的一个场景如下:当某条产品被点击时,应该将产品相关的信息发送给埋点系统进行埋点。
export const ProductItem = ({
id,
productName,
introduction,
trackPressEvent,
}) => (
<TouchableWithoutFeedback onPress={() => trackPressEvent(id, productName)}>
<View>
<Title name={productName} />
<Introduction introduction={introduction} />
</View>
</TouchableWithoutFeedback>
)
import { ProductItem } from './index'
test(`
should send product id and name to analytics system
when user press the product item
`, () => {
const trackPressEvent = jest.fn()
const component = shallow(
<ProductItem
id={100832}
introduction="iMac Pro - Power to the pro."
trackPressEvent={trackPressEvent}
/>
)
component.find(TouchableWithoutFeedback).simulate('press')
expect(trackPressEvent).toHaveBeenCalledWith(
100832,
'iMac Pro - Power to the pro.'
)
})
简单得很吧。这里的几个测试,在你改动了样式相关的东西时,不会挂掉;但是如果你改动了分支逻辑或函数调用的内容时,它就会挂掉了。而分支逻辑或函数调用,恰好是我觉得接近业务的地方,所以它们对保护代码逻辑、保护重构是有价值的。当然,它们多少还是依赖了组件内部的实现细节,比如说 find(TouchableWithoutFeedback),还是做了「组件内部使用了 TouchableWithoutFeedback 组件」这样的假设,而这个假设很可能是会变的。也就是说,如果我换了一个组件来接受点击事件,尽管点击时的行为依然发生,但这个测试仍然会挂掉。这就违反了我们所说了「有且仅有一个使测试失败的理由」。这对于组件测试来说,是不够完美的地方。
但这个问题无法避免。因为组件本质是渲染组件树,那么测试中要与组件树关联,必然要通过 组件名、id 这样的 selector,这些 selector 的关联本身就是使测试挂掉的「另一个理由」。但对组件的分支、事件进行测试又有一定的价值,无法避免。所以,我认为这个部分还是要用,只不过同时需要一些限制,以控制这些假设为维护测试带来的额外成本:
如果你的每个组件都十分清晰直观、逻辑分明,那么像上面这样的组件测起来也就很轻松,一般就遵循 shallow -> find(Component) -> 断言的三段式,哪怕是了解了一些组件的内部细节,通常也在可控的范围内,维护起来成本并不高。这是目前我觉得平衡了表达力、重构意义和测试成本的实践。
功能型组件 - children 型高阶组件
功能型组件,指的是跟业务无关的另一类组件:它是功能型的,更像是底层支撑着业务组件运作的基础组件,比如路由组件、分页组件等。这些组件一般偏重逻辑多一点,关心 UI 少一些。其本质测法跟业务组件是一致的:不关心 UI 具体渲染,只测分支渲染和事件调用。但由于它偏功能型的特性,使得它在设计上常会出现一些业务型组件不常出现的设计模式,如高阶组件、以函数为子组件等。下面分别针对这几种进行分述。
export const FeatureToggle = ({ features, featureName, children }) => {
if (!features[featureName]) {
return null
}
return children
}
export default connect((store) => ({ features: store.global.features }))(
FeatureToggle
)
import React from 'react'
import { shallow } from 'enzyme'
import { View } from 'react-native'
import FeatureToggles from './featureToggleStatus'
import { FeatureToggle } from './index'
const DummyComponent = () => <View />
test('should not render children component when remote toggle is empty', () => {
const component = shallow(
<FeatureToggle features={{}} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(0)
})
test('should render children component when remote toggle is present and stated on', () => {
const features = {
promotion618: FeatureToggles.on,
}
const component = shallow(
<FeatureToggle features={features} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(1)
})
test('should not render children component when remote toggle object is present but stated off', () => {
const features = {
promotion618: FeatureToggles.off,
}
const component = shallow(
<FeatureToggle features={features} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(0)
})
utils 测试
每个项目都会有 utils。一般来说,我们期望 util 都是纯函数,即是不依赖外部状态、不改变参数值、不维护内部状态的函数。这样的函数测试效率也非常高。测试原则跟前面所说的也并没什么不同,不再赘述。不过值得一提的是,因为 util 函数多是数据驱动,一个输入对应一个输出,并且不需要准备任何依赖,这使得它非常适合采用参数化测试的方法。这种测试方法,可以提升数据准备效率,同时依然能保持详细的用例信息、错误提示等优点。jest 从 23 后就内置了对参数化测试的支持了,如下:
test.each([
[['0', '99'], 0.99, '(整数部分为0时也应返回)'],
[['5', '00'], 5, '(小数部分不足时应该补0)'],
[['5', '10'], 5.1, '(小数部分不足时应该补0)'],
[['4', '38'], 4.38, '(小数部分不足时应该补0)'],
[['4', '99'], 4.994, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['4', '99'], 4.995, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['4', '99'], 4.996, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['-0', '50'], -0.5, '(整数部分为负数时应该保留负号)'],
])(
'should return %s when number is %s (%s)',
(expected, input, description) => {
expect(truncateAndPadTrailingZeros(input)).toEqual(expected)
}
)

总结
好,到此为止,本文的主要内容也就讲完了。总结下来,本文主要覆盖到的内容如下:
单元测试对于任何 React 项目(及其他任何项目)来说都是必须的
我们需要自动化的测试套件,根本目标是为了提升企业和团队的 IT「响应力」
之所以优先选择单元测试,是依据测试金字塔的成本收益比原则确定得到的
好的单元测试具备三大特征:有且仅有一个失败的理由、表达力极强、快、稳定
单元测试也有测试策略:在 React 的典型架构下,一个测试体系大概分为六层:组件、action、reducer、selector、副作用层、utils。它们分别的测试策略为:
-
reducer、selector 的重逻辑代码要求 100% 覆盖
utils 层的纯函数要求 100% 覆盖
副作用层主要测试:是否拿到了正确的参数、是否调用了正确的 API、是否保存了正确的数据、业务逻辑、异常逻辑 五个层面
组件层两测两不测:分支渲染逻辑必测、事件、交互调用必测;纯 UI(包括 CSS)不测、@connect 过的高阶组件不测
action 层选择性覆盖:可不测
其他高级技巧:定制测试工具(jest.extend)、参数化测试等
推荐阅读
(点击标题可跳转阅读)
RxJS入门
一文掌握Webpack编译流程
一文深度剖析Axios源码
Javascript条件逻辑设计重构
Promise知识点自测
你不知道的React Diff
你不知道的GIT神操作
程序中代码坏味道(上)
程序中代码坏味道(下)
学习Less,看这篇就够了
一文掌握GO语言实战技能(一)
一文掌握GO语言实战技能(二)
一文达到Mysql实战水平
一文达到Mysql实战水平-习题答案
从表单抽象到表单中台
实战LeetCode 系列(一) (题目+解析)
一文掌握Javascript函数式编程重点
实战LeetCode - 前端面试必备二叉树算法
阿里、网易、滴滴、今日头条、有赞.....等20家面试真题
30分钟学会 snabbdom 源码,实现精简的 Virtual DOM 库
觉得本文对你有帮助?请分享给更多人
关注「React中文社区」加星标,每天进步
