本例中代码使用 jupyter 运行
问题场景:
在处理dataframe时,可能会遇到少量数据缺失的情况,在连续缺失数据较少的情况可以考虑插值填充。
本文调用了scipy库的lagrange(x,y)这个函数,参数x,y分别是对应各个点的x值和y值,函数返回一个对象,即插值函数。lagrange(x,y)的具体描述可参考佐佑思维的博文。
本文就如何定位缺失值,并统一使用拉格朗日插值填充缺失值的原理进行详细说明。
不想看原理的,可以直接跳到“函数封装”
实现原理:
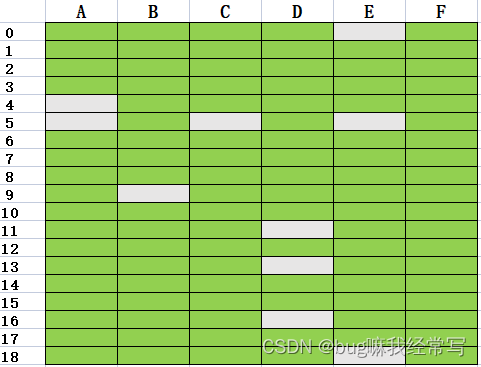
假设数据格式如上,绿色代表非空值,灰色代表nan值。
step 1.数据预处理
将dataframe的缺失值统一用np.nan进行替换
step 2.对于每一列数据
获取缺失值的index
step 3.顺序定位每一个缺失值
对每个缺失值,指定向前和向后分别获取k个数据及其index,并使用这2k个数据,和index值构建拉格朗日插值函数,输入缺失值得index,获得插值结果
step 4.重复循环
【注意】:
向前和向后获取数据时,有如下特殊情况
①向前取k个值,但是 缺失值前的数据数量 < k,此时有多少数据就取多少;
②向后取k个值,这里的取的值要是非空值,碰到空值就跳过;
③向后取k个值,碰到空值就跳过,然后一直跳到数据尾行都没有取够k个,此时也是有多少取多少。
函数封装:
def lagrange_value (data, k=2): # 输入需处理的数据(空值用nan填充),k是空值前后取得数据个数
df1 = data.copy(deep=True)
for col in df1.columns: # 取每一列
col_data = df1[col]
col_nan = col_data[col_data.isnull()] # 取每一列缺失值
col_nan_list = col_nan.index # 取每一列缺失值的index
for n in col_nan_list: # 对每一列缺失值index进行遍历,定位需要插值的位置
list1 = list(range(n-k,n)) # 缺失值前取k个值
if list1[0] < col_data.index[0]: # 判断缺失值前是否有k个值,没有的话就有多少取多少
list1 = list(range(col_data.index[0],n))
list2 = col_data[n:] # 缺失值后取k个非空值
list2 = list2[list2.notnull()]
list2 = list(list2[0:k].index)
y=col_data[list1+list2] # 取数
df1[col][n] = lagrange(y.index,list(y))(n) # 填充缺失值
return df1
函数要输入:需处理的数据(空值用nan填充),和k —— 空值前后取的数据个数
示例:
导入所需的包
简单创建一个dataframe
import pandas as pd
import numpy as np
from scipy.interpolate import lagrange
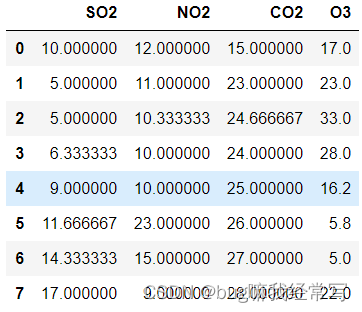
# 生成数据
NaN = np.nan
data = pd.DataFrame({"SO2":[10, 5, 5, NaN, 9, NaN, NaN, NaN],
"NO2":[12, NaN, NaN, 10, 10, 23, 15, 9],
"CO2":[15, 23, NaN, 24, 25, NaN, NaN, NaN],
"O3":[17, 23, 33, NaN, NaN, NaN, 5, 22]
})

调用一下函数
lagrange_value (data, k=2)
补充:
需要说明的是,本文编写的代码对数据格式有一定要求,数据预处理阶段需要reset_index,以保证dataframe的索引值顺序且连续。