一、独占锁原理
独占锁是利用zk同一目录下不能创建多个相同名称的节点这个特性,来实现分布式锁的功能。
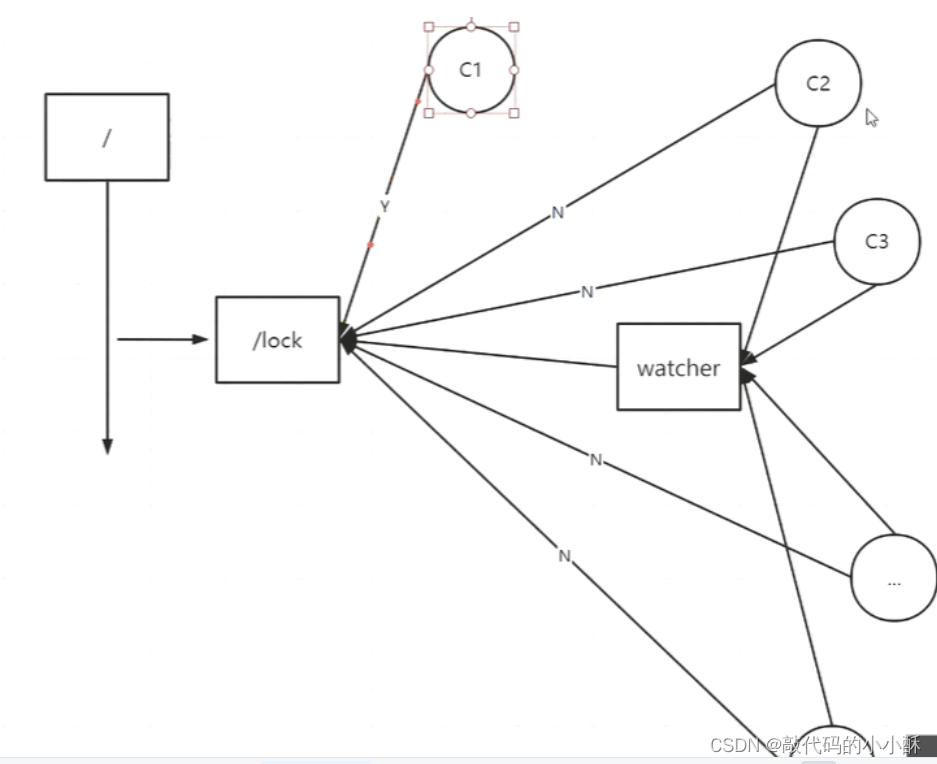
竞争锁的分布式系统,都在zk根目录下创建一个名为lock的节点。创建节点成功的系统,说明抢到了这把锁,没有创建成功的系统,说明这个节点已经被其他系统创建了,没有抢到锁,那么就监听这个节点的删除事件,来等待锁的释放。
当抢到锁的系统执行完业务逻辑后,删除这个lock节点。zk会向监听这个lock节点的所有客户端发送通知,告知lock节点被删除了。接到通知的各系统再次去创建lock节点。创建成功的,证明抢到了这把锁。然后循环上面的过程,以此实现分布式锁的功能。
弊端:
独占锁的弊端就是,如果抢锁的分布式系统很多的话,zk向各系统发送通知时,是走网络通信的,很多的客户端需要通知,就是大量的网络传输,很影响性能。如果分布式子系统少的话,这种方式可以考虑。
二、非独占锁原理
针对上述独占锁的设计缺陷,又提出了非独占锁的实现思路。非独占锁利用zk的有序节点的特性,对分布式系统进行排序,然后按照排序,依次给分布式系统抢到锁,执行业务。

争抢锁的分布式系统在lock节点下创建临时有序节点。各系统创建了节点后,可以获取到自己创建的节点编号。然后获取lock节点下的所有子目录,看自己创建的编号是否为最小。如果是最小,就争抢到了锁,执行锁住的业务逻辑。如果不是最小,就监听前一个编号的节点。
当抢到锁的系统执行完业务代码后,删除这个节点,zk通知监听该节点的客户端,去执行锁住的代码。依次类推,完成分布式锁功能。
可以看到,这种实现方式,zk每次只通知一个客户端去争抢锁,解决了独占锁设计中的缺陷问题。
三、代码实现
zk实现分布式锁的代码在zk的java客户端中已经实现好了。我们在使用时直接调用客户端提供的方法实现分布式锁即可。这里为了锻炼一下自己的代码水平,手动用代码实现一下上述的独占锁和非独占锁的原理。
注:以下代码实现使用ZkClient客户端连接操作zk服务。
第一步:
通过读框架源码可知,优秀的框架,都是从定义接口规范开始的,这里我们也要建立这种思想。先定义规范,再考虑实现。
首先,定义接口规范Lock接口:
public interface Lock {
public void lock();
public void unlock();
}
第二步:
然后,实现上述接口。先捋清楚上述接口方法的逻辑代码。
public void lock(){
//尝试获取锁
boolean getLock=tryLock();
//如果获取到锁,执行业务代码
if(getLock){//抢到锁,执行业务代码
}else{//没抢到锁,等待锁释放,重新抢锁
waitLock();
lock();
}
}
上述伪代码是利用递归的方式,一直抢锁,直到抢锁成功。为了实现lock加锁抢锁功能,我们需要实现获取锁和锁等待的逻辑。而通过独占锁和非独占锁的原理可知,两种方式获取锁和抢锁的实现是不一样的,因此,我们先封装出一个抽象类,来实现lock方法,而对于lock内部的获取锁和锁等待的方法,我们用模板设计模式,让不同的子类去实现。之所以手写代码实现zk的分布式锁,就是为了体会这种编码思想和规范。
public abstract class ZkAbstractLock implements Lock {
private static String connectStr = "ip:port";
public static String path = "/lock";
protected ZkClient client = new ZkClient(connectStr);
/**
lock方式是要去获取锁的方法
如果成功,那么代码往下走,执行创建订单的业务逻辑
如果失败,lock需要等待
1、等待到了前面那个获取锁的客户端释放锁以后
2、再去重新获取锁
*/
@Override
public void lock() {
//1、尝试去获取锁
if(tryLock()) {
System.out.println(Thread.currentThread().getName() + "--->获取锁成功!");
} else {
//在这里等待
waitforlock();
lock();
}
}
//钩子方法
protected abstract boolean tryLock();
//钩子方法
protected abstract void waitforlock();
//创建的临时节点,关闭session,节点自动删除
@Override
public void unlock() {
client.close();
}
}
第三步:
实现独占锁和非独占锁的获取锁和锁等待的代码实现。
独占锁:
public class ZkLockImpl extends ZkAbstractLock {
private CountDownLatch cdl = null;
//尝试获取锁
@Override
protected boolean tryLock() {
try {
client.createEphemeral(path);
return true;
} catch (ZkException e) {
return false;
}
}
//等待获取锁
//等前面那个获取锁成功的客户端释放锁
//没有获取到锁的客户端都会走到这里
//1、没有获取到锁的要注册对/lock节点的watcher
//2、这个方法需要等待
@Override
protected void waitforlock() {
IZkDataListener iZkDataListener = new IZkDataListener() {
@Override
public void handleDataChange(String dataPath, Object data) throws Exception {
}
//一旦/lock节点被删除以后,就会触发这个方法
@Override
public void handleDataDeleted(String dataPath) throws Exception {
//让等待的代码不再等待了
if(cdl != null) {
cdl.countDown();
}
}
};
//注册watcher
client.subscribeDataChanges(path, iZkDataListener);
if (client.exists(path)) {
cdl = new CountDownLatch(1);
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//取消该客户端的订阅关系
client.unsubscribeDataChanges(path, iZkDataListener);
}
}
非独占锁:
public class ZkImproveLockImpl extends ZkAbstractLock {
//记录当前客户端创建的临时节点
private String currentPath;
//记录上一个节点
private String beforePath;
private CountDownLatch cdl;
public ZkImproveLockImpl() {
if(!client.exists(path)) {
client.createPersistent(path,"");
}
}
@Override
protected boolean tryLock() {
if (currentPath == null || currentPath.length() <= 0) {
// /lock/0000000001
currentPath = client.createEphemeralSequential(path + "/", "");
}
//拿到/lock下面的所有儿子节点
List<String> children = client.getChildren(path);
Collections.sort(children);
//children.get(0) 就是最小的那个节点
if (currentPath.equals(path + "/" + children.get(0))) {
return true;
} else {
//如果不是第一个,那么就必须找出当前节点的上一个节点
//找到当前节点在所有子节点的索引
int i = Collections.binarySearch(children, currentPath.substring(6));
beforePath = path + "/" + children.get(i - 1);
}
return false;
}
@Override
protected void waitforlock() {
IZkDataListener iZkDataListener = new IZkDataListener() {
@Override
public void handleDataChange(String dataPath, Object data) throws Exception {
}
//一旦/lock节点被删除以后,就会触发这个方法
@Override
public void handleDataDeleted(String dataPath) throws Exception {
//让等待的代码不再等待了
if (cdl != null) {
cdl.countDown();
}
}
};
//每一个客户端就只需要注册对前一个节点的监听
client.subscribeDataChanges(beforePath, iZkDataListener);
if (client.exists(beforePath)) {
cdl = new CountDownLatch(1);
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
client.unsubscribeDataChanges(beforePath, iZkDataListener);
}
}
四、ZK分布式锁与redis分布式锁比较
在前面讲redis实现分布式锁时,无论怎么优化,redis分布式锁都不能满足各种极端情况下锁的安全性。那么zk实现的分布式锁,能经得住各种极端情况的考验吗?
redis分布式锁的问题是锁过期产生的一系列问题。在zk中,没有锁过期的概念,因此也避免了锁过期带来的一些问题。
但是zk分布式锁的问题是,靠临时节点来持有锁,删除临时节点代表释放锁。客户端和zk服务靠心跳保持的连接。假如网络异常,无法收到心跳,那么zk服务就认为客户端断开了连接,临时节点会被删除。如果此时锁住的代码还没执行完,就释放了锁,也会带来问题。
同样的,GC也会影响心跳的发送频率。因此也会影响分布式锁的安全性。
由此可知,在分布式环境下,没有可以做到百分之百安全的分布式锁。
综上,选择哪个作为分布式锁,就是仁者见仁,智者见智了。相比zk而已,redis的运维成本相对低一些。