1 目标函数(总)
论文笔记:Temporal Regularized Matrix Factorization forHigh-dimensional Time Series Prediction_UQI-LIUWJ的博客-CSDN博客

1.1 求解W
我们留下含有W的部分:

![min_{W_i} \frac{1}{2} [(y_{i1}-w_ix_1^T)^2+\dots+(y_{in}-w_ix_n^T)^2]+ \frac{1}{2}\lambda_w\sum_{i=1}^m w_iw_i^T](https://latex.csdn.net/eq?min_%7BW_i%7D%20%5Cfrac%7B1%7D%7B2%7D%20%5B%28y_%7Bi1%7D-w_ix_1%5ET%29%5E2+%5Cdots+%28y_%7Bin%7D-w_ix_n%5ET%29%5E2%5D+%20%5Cfrac%7B1%7D%7B2%7D%5Clambda_w%5Csum_%7Bi%3D1%7D%5Em%20w_iw_i%5ET)
然后对wi求导
线性代数笔记:标量、向量、矩阵求导_UQI-LIUWJ的博客-CSDN博客
![\frac{1}{2} [-2(y_{i1}-w_ix_1^T)x_1+\dots+-2(y_{in}-w_ix_n^T)x_n]+ \frac{1}{2}\lambda_w 2I w_i=0](https://latex.csdn.net/eq?%5Cfrac%7B1%7D%7B2%7D%20%5B-2%28y_%7Bi1%7D-w_ix_1%5ET%29x_1+%5Cdots+-2%28y_%7Bin%7D-w_ix_n%5ET%29x_n%5D+%20%5Cfrac%7B1%7D%7B2%7D%5Clambda_w%202I%20w_i%3D0)
![-(y_{i1}x_1+\dots+y_{in}x_n)+ [{(w_ix_1^T)x_1}+\dots+ (w_ix_n^T)x_n]+ \lambda_w I w_i=0](https://latex.csdn.net/eq?-%28y_%7Bi1%7Dx_1+%5Cdots+y_%7Bin%7Dx_n%29+%20%5B%7B%28w_ix_1%5ET%29x_1%7D+%5Cdots+%20%28w_ix_n%5ET%29x_n%5D+%20%5Clambda_w%20I%20w_i%3D0)
而 是一个标量,所以放在xi的左边和右边没有影响
是一个标量,所以放在xi的左边和右边没有影响
所以
![[{w_ix_1^Tx_1}+\dots+ w_ix_n^Tx_n]+ \lambda_w I w_i=(y_{i1}x_1+\dots+y_{in}x_n)](https://latex.csdn.net/eq?%5B%7Bw_ix_1%5ETx_1%7D+%5Cdots+%20w_ix_n%5ETx_n%5D+%20%5Clambda_w%20I%20w_i%3D%28y_%7Bi1%7Dx_1+%5Cdots+y_%7Bin%7Dx_n%29)
也即:

![w_i=[(\sum_{(i,t)\in \Omega}x_t^Tx_t) + \lambda_w I]^{-1}\sum_{(i,t)\in \Omega}y_{it}x_t](https://latex.csdn.net/eq?w_i%3D%5B%28%5Csum_%7B%28i%2Ct%29%5Cin%20%5COmega%7Dx_t%5ETx_t%29%20+%20%5Clambda_w%20I%5D%5E%7B-1%7D%5Csum_%7B%28i%2Ct%29%5Cin%20%5COmega%7Dy_%7Bit%7Dx_t)
对应的代码如下:(假设sparse_mat表示 观测矩阵)
from numpy.linalg import inv as inv
for i in range(dim1):
#W矩阵的每一行分别计算
pos0 = np.where(sparse_mat[i, :] != 0)
#[num_obs] 表示i对应的有示数的数量
Xt = X[pos0[0], :]
#[num_obs,rank
vec0 = sparse_mat[i, pos0[0]] @ Xt
#sparse_mat[i, pos0[0]] 是一维向量,
#所以sparse_mat[i, pos0[0]] @ Xt 和 sparse_mat[i, pos0[0]].T @ Xt 是一个意思,
#输出的都是一个一维向量
#[rank,1]
mat0 = inv(Xt.T @ Xt + np.eye(rank))
#[rank,rank]
W[i, :] = mat0 @ vec0
其中:
 |
vec0 = sparse_mat[i, pos0[0]] @ Xt
|
![[(\sum_{(i,t)\in \Omega}x_i^Tx_i) + \lambda_w I]^{-1}](https://latex.csdn.net/eq?%5B%28%5Csum_%7B%28i%2Ct%29%5Cin%20%5COmega%7Dx_i%5ETx_i%29%20+%20%5Clambda_w%20I%5D%5E%7B-1%7D) |
mat0 = inv(Xt.T @ Xt + np.eye(rank))
|
1.2 求解X
我们留下含有X的部分

![\lambda_x R_{AR}(X|\L,\Theta,\eta) =\frac{1}{2}\lambda_x \sum_{t=l_d+1}^f[(x_t-\sum_{l \in L}\theta_l \divideontimes x_{t-l})(x_t-\sum_{l \in L}\theta_l \divideontimes x_{t-l})^T]+\frac{1}{2}\lambda_x \eta \sum_{t=1}^f x_t x_t^T](https://latex.csdn.net/eq?%5Clambda_x%20R_%7BAR%7D%28X%7C%5CL%2C%5CTheta%2C%5Ceta%29%20%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%5B%28x_t-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%28x_t-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%5ET%5D+%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5Ceta%20%5Csum_%7Bt%3D1%7D%5Ef%20x_t%20x_t%5ET)
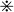 表示逐元素乘积 (两个向量a和b,ab可以用diag(a) b表示)
表示逐元素乘积 (两个向量a和b,ab可以用diag(a) b表示)
当t=1~ld的时候,我们没有 什么事情,所以此时我们更新X的方式和之前的W差不多
什么事情,所以此时我们更新X的方式和之前的W差不多
同理,X的更新方式为:
![\small x_t=[(\sum_{(i,t)\in \Omega}w_i^Tw_i) + \lambda_x \eta I]^{-1}\sum_{(i,t)\in \Omega}y_{it}w_i](https://latex.csdn.net/eq?%5Csmall%20x_t%3D%5B%28%5Csum_%7B%28i%2Ct%29%5Cin%20%5COmega%7Dw_i%5ETw_i%29%20+%20%5Clambda_x%20%5Ceta%20I%5D%5E%7B-1%7D%5Csum_%7B%28i%2Ct%29%5Cin%20%5COmega%7Dy_%7Bit%7Dw_i)
而当t≥ld+1的时候,我们就需要考虑了
对于任意xt(我们令其为xo),他会出现在哪些中呢?
首先 是 ![\frac{1}{2}\lambda_x[(x_o-\sum_{l \in L}\theta_l \divideontimes x_{o-l})(x_o-\sum_{l \in L}\theta_l \divideontimes x_{o-l})^T]](https://latex.csdn.net/eq?%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B%28x_o-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%28x_o-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%5ET%5D)
![=\frac{1}{2}\lambda_x[(x_o-\sum_{l \in L}\theta_l \divideontimes x_{o-l})(x_o^T-(\sum_{l \in L}\theta_l \divideontimes x_{o-l})^T)]](https://latex.csdn.net/eq?%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B%28x_o-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%28x_o%5ET-%28%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%5ET%29%5D)
![\tiny =\frac{1}{2}\lambda_x[x_ox_o^T-(\sum_{l \in L}\theta_l \divideontimes x_{o-l})x_o^T-x_o(\sum_{l \in L}\theta_l \divideontimes x_{o-l})^T+(\sum_{l \in L}\theta_l \divideontimes x_{o-l})(\sum_{l \in L}\theta_l \divideontimes x_{o-l})^T]](https://latex.csdn.net/eq?%5Cdpi%7B120%7D%20%5Ctiny%20%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5Bx_ox_o%5ET-%28%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29x_o%5ET-x_o%28%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%5ET+%28%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%28%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%29%5ET%5D)
对xo求导,有:
![\small =\frac{1}{2}\lambda_x[2x_o-2\sum_{l \in L}\theta_l \divideontimes x_{o-l}]](https://latex.csdn.net/eq?%5Cdpi%7B120%7D%20%5Csmall%20%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B2x_o-2%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%5D)
其次,是所有的 ![\frac{1}{2}\lambda_x[(x_{o+l}-\sum_{l \in L}\theta_l \divideontimes x_{o})(x_{o+l}-\sum_{l \in L}\theta_l \divideontimes x_{o})^T]](https://latex.csdn.net/eq?%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B%28x_%7Bo+l%7D-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo%7D%29%28x_%7Bo+l%7D-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo%7D%29%5ET%5D)
对每一个l,有用的项就是xo相关的项,于是我们可以写成,对每一个l的
![\frac{1}{2}\lambda_x[(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l}-\theta_{l} \divideontimes x_{o})(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l}-\theta_{l} \divideontimes x_{o})^T]](https://latex.csdn.net/eq?%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D-%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%29%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D-%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%29%5ET%5D)
![\small =\frac{1}{2}\lambda_x[(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})^T -\theta_{l} \divideontimes x_{o}(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})^T -(x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})(\theta_{l} \divideontimes x_{o})^T +\theta_{l} \divideontimes x_{o}(\theta_{l} \divideontimes x_{o})^T]](https://latex.csdn.net/eq?%5Csmall%20%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%5ET%20-%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%5ET%20-%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%28%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%29%5ET%20+%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%28%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20x_%7Bo%7D%29%5ET%5D)
对xo求导,有![\small =\frac{1}{2}\lambda_x [-2\theta_{l} \divideontimes (x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})^T+2(\theta_{l} ^2)\divideontimes x_o]](https://latex.csdn.net/eq?%5Csmall%20%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5B-2%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%5ET+2%28%5Ctheta_%7Bl%7D%20%5E2%29%5Cdivideontimes%20x_o%5D)
还要注意一点,此时我们考虑的是下标为o+l的AR,所以o+l需要大于ld,小于T,也就是此时o的范围是o>ld-l ,<T-l【也就是说,在ld之前的xo也会有一定的AR的更新项】
于是我们可以写成
![\small \sum_{l \in L, o+l<T,o+l>l_d}\frac{1}{2}\lambda_x [-2\theta_{l} \divideontimes (x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})^T+2(\theta_{l} ^2)\divideontimes x_o]](https://latex.csdn.net/eq?%5Cdpi%7B120%7D%20%5Csmall%20%5Csum_%7Bl%20%5Cin%20L%2C%20o+l%3CT%2Co+l%3El_d%7D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5B-2%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%5ET+2%28%5Ctheta_%7Bl%7D%20%5E2%29%5Cdivideontimes%20x_o%5D)
几部分拼起来,有
![\small \sum_{l \in L, o+l<T, o>l_d}\frac{1}{2}\lambda_x [-2\theta_{l} \divideontimes (x_{o+l}-\sum_{l' \in L-\{l\}}\theta_{l'} \divideontimes x_{o+l'-l})^T+2(\theta_{l} \divideontimes \theta_{l} ) \divideontimes x_o]](https://latex.csdn.net/eq?%5Csmall%20%5Csum_%7Bl%20%5Cin%20L%2C%20o+l%3CT%2C%20o%3El_d%7D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5B-2%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20%28x_%7Bo+l%7D-%5Csum_%7Bl%27%20%5Cin%20L-%5C%7Bl%5C%7D%7D%5Ctheta_%7Bl%27%7D%20%5Cdivideontimes%20x_%7Bo+l%27-l%7D%29%5ET+2%28%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20%5Ctheta_%7Bl%7D%20%29%20%5Cdivideontimes%20x_o%5D)
![\small +\frac{1}{2}\lambda_x[2x_o-2\sum_{l \in L,o>l_d}\theta_l \divideontimes x_{o-l}]](https://latex.csdn.net/eq?%5Csmall%20+%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%5B2x_o-2%5Csum_%7Bl%20%5Cin%20L%2Co%3El_d%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bo-l%7D%5D)
![\small +[(\sum_{(i,o)\in \Omega}w_i^Tw_i) + \lambda_x \eta I]x_o-\sum_{(i,o)\in \Omega}y_{io}w_i](https://latex.csdn.net/eq?%5Csmall%20+%5B%28%5Csum_%7B%28i%2Co%29%5Cin%20%5COmega%7Dw_i%5ETw_i%29%20+%20%5Clambda_x%20%5Ceta%20I%5Dx_o-%5Csum_%7B%28i%2Co%29%5Cin%20%5COmega%7Dy_%7Bio%7Dw_i)
=0


![\small +[(\sum_{(i,o)\in \Omega}w_i^Tw_i) + \lambda_x I]x_o](https://latex.csdn.net/eq?%5Csmall%20+%5B%28%5Csum_%7B%28i%2Co%29%5Cin%20%5COmega%7Dw_i%5ETw_i%29%20+%20%5Clambda_x%20I%5Dx_o)
=
+
所以xo(o≥ld+1)的更新公式为
![\small [(\sum_{(i,o)\in \Omega}w_i^Tw_i) + \lambda_x I+\lambda_x \eta I +\lambda_x\sum_{l \in L, o+l<T, o>l_d} diag(\theta_{l} \divideontimes \theta_{l} )]^{-1}](https://latex.csdn.net/eq?%5Csmall%20%5B%28%5Csum_%7B%28i%2Co%29%5Cin%20%5COmega%7Dw_i%5ETw_i%29%20+%20%5Clambda_x%20I+%5Clambda_x%20%5Ceta%20I%20+%5Clambda_x%5Csum_%7Bl%20%5Cin%20L%2C%20o+l%3CT%2C%20o%3El_d%7D%20diag%28%5Ctheta_%7Bl%7D%20%5Cdivideontimes%20%5Ctheta_%7Bl%7D%20%29%5D%5E%7B-1%7D) [+]
[+]
代码如下:
for t in range(2):
pos0 = np.where(sparse_mat[:, t] != 0)
#[num_obs] 表示i对应的有示数的数量
Wt = W[pos0[0], :]
#[num_obs,rank],t可见的wi
Mt = np.zeros((rank, rank))
#\sum diad (theta * theta)的那个矩阵
Nt = np.zeros(rank)
#Nt 相当于是 sum theta* x_{t-l}
if t < np.max(time_lags):
#这一个if,else考虑到的是首先的部分
Pt = np.zeros((rank, rank))
#t<ld的时候,是没有λx I的
Qt = np.zeros(rank)
#t<ld的时候,没有过去时间段的回归项
else:
Pt = np.eye(rank)
#t>ld+1的时候 有λx I
Qt = np.einsum('ij, ij -> j', theta, X[t - time_lags, :])
#theta [d,rank]
#X[t - time_lags, :] [d,rank]
'''
对于每一个theta和X[t - time_lags, :]中的j (j∈range(rank))
我们输出是一个rank长的向量,第j维是每个theta的(i,j)元素
和对应的X的(i,j)元素相乘,然后求和
每个theta的(i,j)元素表示向量第j个元素的第i个time lag的AR权重
每个X的(i,j)元素表示向量第j个元素的第i个time lag的数据
相乘再1求和,就是输出的第j个元素,有之前的时序数据加权求和得到的自归回值
'''
'''
换一个角度理解,就是theta和X[t - time_lags, :]逐元素乘积,
再从一个[d,rank]矩阵,压缩成一个rank长的向量
即np.sum(theta*X[t - time_lags, :],axis=0)
'''
if t < dim2 - np.min(time_lags):
#这个if 考虑的是其次的部分,所以需要t+l>ld 且t+l<T
#(ld是max(time_lags),T是dim2
#t+min(lag)小于T
if t >= np.max(time_lags) and t < dim2 - np.max(time_lags):
index = list(range(0, d))
#t>=ld,同时t+max(ld)也没有超过最大的时间限制,此时所有的d个time lad都可以使用
else:
index = list(np.where((t + time_lags >= np.max(time_lags))
& (t + time_lags < dim2)))[0]
#在两头,计算可以用的o+l
for k in index:
Ak = theta[k, :]
#[rank]
Mt += np.diag(Ak ** 2)
#对应的是Σdiag(θk*θk)
theta0 = theta.copy()
theta0[k, :] = 0
#第k行赋值为0的作用,就是Σ_{l'∈L-{l}}
Nt += np.multiply(Ak,
X[t + time_lags[k], :] - np.einsum(
'ij, ij -> j',
theta0,
X[t + time_lags[k] - time_lags, :]))
'''
AK——θl [rank]
X[t + time_lags[k], :] x_{o+l}
np.einsum('ij, ij -> j',theta0, X[t + time_lags[k] - time_lags, :])
对于每一个theta0和XX[t + time_lags[k] - time_lags, :]中的j (j∈range(rank))
我们输出是一个rank长的向量,第j维是每个theta的(i,j)元素
和对应的X的(i,j)元素相乘,然后求和
每个theta的(i,j)元素表示向量第j个元素的第i个time lag的AR权重
每个X的(i,j)元素表示向量第j个元素的第i个time lag的数据
相乘再求和,就是输出的第j个元素,有之前的时序数据加权求和
得到的自归回值(之前的时间序列不包括l,因为那一行被赋值为0了)
'''
#也就是Nt相当于其次括号里面的第一项
vec0 = Wt.T @ sparse_mat[pos0[0], t] + lambda_x * Nt + lambda_x * Qt
#Wt.T @ sparse_mat[pos0[0], t] [rank]
#lambda_x * Nt 第一项
#lambda_x * Qt 第二项
mat0 = inv(Wt.T @ Wt + lambda_x * Mt + lambda_x * Pt + lambda_x * eta * np.eye(rank))
#分别是第一项、第四项、第二项、第三项
X[t, :] = mat0 @ vec0
vec0:
+]
mat0:
3 更新θ
我们留下和θ (θk)有关的部分
![\small \frac{1}{2}\lambda_x \sum_{t=l_d+1}^f[(x_t-\sum_{l \in L}\theta_l \divideontimes x_{t-l})(x_t-\sum_{l \in L}\theta_l \divideontimes x_{t-l})^T]+\lambda_\theta R_\theta(\Theta)](https://latex.csdn.net/eq?%5Csmall%20%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%5B%28x_t-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%28x_t-%5Csum_%7Bl%20%5Cin%20L%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%5ET%5D+%5Clambda_%5Ctheta%20R_%5Ctheta%28%5CTheta%29)
![=\frac{1}{2}\lambda_x \sum_{t=l_d+1}^f[(x_t-\sum_{l \in L-\{k\}}\theta_l \divideontimes x_{t-l}-\theta_k \divideontimes x_{t-k})(x_t-\sum_{l \in L-\{k\}}\theta_l \divideontimes x_{t-l}-\theta_k \divideontimes x_{t-k})^T]+\lambda_\theta R_\theta(\Theta)](https://latex.csdn.net/eq?%3D%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%5B%28x_t-%5Csum_%7Bl%20%5Cin%20L-%5C%7Bk%5C%7D%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D-%5Ctheta_k%20%5Cdivideontimes%20x_%7Bt-k%7D%29%28x_t-%5Csum_%7Bl%20%5Cin%20L-%5C%7Bk%5C%7D%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D-%5Ctheta_k%20%5Cdivideontimes%20x_%7Bt-k%7D%29%5ET%5D+%5Clambda_%5Ctheta%20R_%5Ctheta%28%5CTheta%29)



![+(\theta_k \divideontimes x_{t-k})(\theta_k \divideontimes x_{t-k})^T]](https://latex.csdn.net/eq?+%28%5Ctheta_k%20%5Cdivideontimes%20x_%7Bt-k%7D%29%28%5Ctheta_k%20%5Cdivideontimes%20x_%7Bt-k%7D%29%5ET%5D)

关于θk求导
![\small \frac{1}{2}\lambda_x \sum_{t=l_d+1}^f[-2(x_t-\sum_{l \in L-\{k\}}\theta_l \divideontimes x_{t-l})\divideontimes x_{t-k}+2 diag (x_{t-k} \divideontimes x_{t-k})\theta_k]+\lambda_\theta I \theta_k=0](https://latex.csdn.net/eq?%5Csmall%20%5Cfrac%7B1%7D%7B2%7D%5Clambda_x%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%5B-2%28x_t-%5Csum_%7Bl%20%5Cin%20L-%5C%7Bk%5C%7D%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%5Cdivideontimes%20x_%7Bt-k%7D+2%20diag%20%28x_%7Bt-k%7D%20%5Cdivideontimes%20x_%7Bt-k%7D%29%5Ctheta_k%5D+%5Clambda_%5Ctheta%20I%20%5Ctheta_k%3D0)
![\small \theta_k=[\lambda_\theta I + \sum_{t=l_d+1}^f diag (x_{t-k} \divideontimes x_{t-k})\theta_k]^{-1} \sum_{t=l_d+1}^f[(x_t-\sum_{l \in L-\{k\}}\theta_l \divideontimes x_{t-l})\divideontimes x_{t-k}]](https://latex.csdn.net/eq?%5Csmall%20%5Ctheta_k%3D%5B%5Clambda_%5Ctheta%20I%20+%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%20diag%20%28x_%7Bt-k%7D%20%5Cdivideontimes%20x_%7Bt-k%7D%29%5Ctheta_k%5D%5E%7B-1%7D%20%5Csum_%7Bt%3Dl_d+1%7D%5Ef%5B%28x_t-%5Csum_%7Bl%20%5Cin%20L-%5C%7Bk%5C%7D%7D%5Ctheta_l%20%5Cdivideontimes%20x_%7Bt-l%7D%29%5Cdivideontimes%20x_%7Bt-k%7D%5D)
4 总结
x:
t ∈ 1~ld:
t ≥ld+1 [+]





