百日计划第一周总结
1. 计划
1.彻底结束之前预定暑假完成的天善学院课程《七周数据分析师》
2.总结《七周数据分析师》。
2. 完成情况
1.完成《七周成为数据分析师》任务
2.周总结与《七周数据分析师》一起完成。
《七周数据分析师》总结
第一周:数据分析思维
1.核心数据分析思维
- 结构化
- 公式化
- 业务化
2.数据分析思维七大技巧
- 象限法
- 多维法
- 假设法
- 指数法
- 80/20法则(帕累托法则)
- 对比法
- 漏斗法
3.数据分析思维锻炼方法
- 好奇心!
- 案例分析
- 啤酒与尿布
- 去思考生活中商业案例的表现,背后的原理、摆放方法和数据差异
- 生活中的练习
- 例如夜市,一天的人流量?一人的流量?营业额?数据的分析方式?
- 换做你是商家,如何提高店面的利润?
- 工作中的练习
- 为什么领导和同事不认可?
- 如果我职位更高,我会怎么分析?
- 复盘,对于一个月,一年前等等的案例进行对比。需要,每个案例有记笔记的习惯,效果更好
- 历史分析,用这三种分析思维,分析更多的事情。结构化,公式化,业务化。
4.总结
- 核心思维为重点!结合案例理解了,这三种思维的重要性,运用范围极广,对于问题的思考都可以从这三方面开展。
- 七大技巧,展示了具体的分析技巧,但是需要配合分析工具如Python、excel中去实现他,需要记住特点,在需要时运用到数据分析中
- 数据分析思维的锻炼,来自于长期的思考习惯,从生活、案例和工作中日积月累的思考与积累,通过自己真正“思考”出来的结果,才是“真正”理解的思维。
第二周:业务篇-指标
1.为什么业务重要
唯有理解业务,才能建立完整的一套体系,简称业务数据模型。
想进入某个行业的数据分析,尽量需要一些业务知识,敲门砖。
2.经典的业务分析指标
模型未动,指标先行。
如果你不能衡量它,你就不能无法增长它
运用第一周的核心思维:结构化、公式化和业务化,形成指标。

指标建立的要点:
- 核心指标(公司和部门都认同的大目标,根据实际公司情况而认定)
- 好的指标应该是比率
- 好的指标能带来显著效果
- 好的指标不应该虚荣(如投入的钱很多,新增用户量大)
- 好的指标不应该复杂
3.市场营销指标
市场营销领域:
1.客户/用户生命周期
- 企业/产品和消费者再整个业务关系阶段的周期。
- 不同业务划分的阶段不同。传统营销中,分为潜在用户,兴趣用户,新客户,老客户,流失客户。
2.用户价值

3. 产品运营指标
AARRR框架
用户获取,用户活跃,用户留存,营收,传播
1.用户获取
- 渠道到达量:俗称曝光量。有多少人看到产品推广相关的线索。
- 渠道转换率:有多少用户因为曝光而心动Cost Per,包含CPM、CPC、CPS、CPD和CPT等。
- 渠道ROI:推广营销的熟悉KPI,投资回报率,利润/投资* 100
- 日应用下载量:App的下载量,这里指点击下载,不代表下载完成。
- 日新增用户数:以用户注册提交资料为基准
- 获客成本:为获取一位用户需要支付的成本
- 一次会话用户数占比:指新用户下载完App,仅打开过产品一次,且该次使用时长在2分钟以内。(衡量渠道可靠程度)
2.用户活跃
- 日/周/月活跃用户应用下载量:活跃标准是用户用过的产品,广义上,网页游览内容算用,公众号下单算用,不限于打开APP。
- 活跃用户占比:活跃用户数再总用户数的比例,衡量的是产品健康程度
- 用户会话session次数:用户打开产品操作和使用,直到推出产品的整个周期。5分钟无操作,默认结束
- 用户访问时长:一次会话的持续时间。
- 用户平均访问次数:一段时间内的用户平均产生会话次数。
3.用户留存
用户在某段时间内使用产品,过了一段时间后仍旧继续使用的用户。
4.营收
- 付费用户数:花了钱的
- 付费用户数占比:每日付费用户占活跃用户数比,也可以计算总付费用户占总用户数比
- ARPU:某个时间段内,每位用户平均收入
- ARPPU:某时间段内每位付费用户平均收入,排除了未付费。
- 客单价:每一位用户平均购买商品的金额。销量总额/顾客总数
- LTV:用户生命价值周期,和市场营销的客户价值接近,经常用在游戏运营电商运营中。
- LTV(经验公式):ARPU*1/流失率(比如说,一月份有一百个用户,这个月用户流失率0.3,那么1/流失率=3.3,那么一月份这批客户在3.3个月后流失光,这段时间的LTV=ARPU(用户的平均消费100元) *3.3 =330元),适合敏捷项目
5.传播
- K因子:每一个用户能够带来几个新用户
- K因子=用户数平均邀请人=人数邀请转换率
- 用户分享率:某功能/界面中,分享用户数占游览页面人数占比
- 活动/邀请曝光量:线上传播活动中,该活动被曝光的次数
4. 用户行为指标
1.用户行为
- 没有特别重要的框架,主要在于理解与应用。
- 功能使用率:使用某功能的用户占活动总活跃数之比。(比如点赞、评论、收藏、搜索等等)
- 用户会话:会话(session),是用户在一次访问过程中,从开始到结束的整个过程。在网页端,30分钟内没有操作,默认会话操作结束
2.用户路径
路径图:用户在一次会话的过程中,其访问产品内部的游览轨迹,通过此,可以加工出关键路径转换率。

全产品路径如上,但是关注关键路径才重要。比如下单的路径,观察各个路径的情况,进行优化。
5.电子商务指标
购物篮分析
- 笔单价:用户每次购买支付的金额,即每笔订单的支出,对应客单价
- 件单价:商品的平均价格
- 成交率:支付成功的用户在总的客流量中的占比
- 购物篮系数:平均每笔订单中,卖出了多少商品,与商品关联规则有关。
- 复购率:一段时间内多次消费的用户占到总消费用户数之比(忠诚度)
- 回购率:一段时间内消费过的用户,在下一段时间内仍然有消费行为的占比(消费欲望)
6. 流量指标
1.游览量和访客量
2.访客行为
7.怎么生存指标
组合!
- 访客访问时长+UV=重度访问用户占比(游览时间五分钟以上的用户占比)
- 用户会话次数+成交率=有效消费会话占比(用户在所有的会话中,其中有多少次有消费?)
- 机器学习,PCA学习,指数法,生成指标。(偏应用)
8.总结
- 通过三大核心思维,分解-理解-寻找,得到重要的指标。
- 根据不同行业,运用不同合适的模型
- 公司在不同时期、阶段和模式都有不同的指标,需要有根据目的,从更高层次去寻找有效的指标。
第二周:业务篇-框架与模型
1.业务的分析框架
- 从第一周数据分析思维,核心技巧,工具,都为了这部分做铺垫。
-
让指标形成闭环,成为真正靠谱的模型
从三个角度出发
- 从指标的角度出发
- 从业务的角度出发
- 从流程的角度出发
2.市场营销模型

本质是树形结构,从树形思维导图演变而来,但是加入闭环的循环结构。
3.AARRR模型

- 核心是形成闭环。
- 例子:饿了吗红包。
- 二次激活:推送激活率、有效推送到达率、用户打开率、不用推送的转化率(可以使用漏斗图)
4.用户行为模型(内容平台)

- 例如,知乎。完整闭环,各个环节都能进行分析
- 点赞/评论/收藏分析:点赞/评论/收藏用户活跃占比、内容指数等等
5.电子商务模型

遇到结构外的分析内容,在外面额外添加就行,如右上角。
分析各个节点,得到指标。例如,购物车分析:
- 不用商品类别的占比(对比法)
- 不同价格档次的占比(象限法)
- 不同商品的下单支付率(漏斗法)
6.流量模型

指标结构框架如上,分析各个要点。
分析搜索流量:

有些指标在其他模型也有,模型之间没有严格界限,可以共同使用相同指标
怎么从空白数据分析需求开始?
- 设立核心指标
- 经过三种核心思维
- 聚合成树形图
- 形成大量指标
- 将指标变成分析框架,闭环模型图,例如上面案例
- 每个节点都能分析,利用上周的七大分析工具。
7.如何应对各类业务场景
新手,面对数据分析依然是没有思路进行分析?
-
练习
重点,在于练习。参考上面,如何锻炼数据分析思维。
例如,出门的夜市商铺、京东的电商产品框架、阅读资讯软件。
-
熟悉业务
从熟悉的入手培养业务sense
-
应用三种核心思维
打开Xmind思维导图,开始画画。
-
归纳和整理出指标
对于基本完整的思维导图,提炼出,复购率、活跃度和用户行为等等基本指标结合。
-
画出框架
PPT,等等其他软件。
-
检查、应用、修正
没有框架是完美的,在时间维度上需要检查。
-
应用和迭代
在工作中应用,先从小问题开始,再把各个小问题组合成大问题。
8.如何应对业务场景(实践测试)

以科赛数据分析平台为例子,参考视频,设计了一个分析体系。
9. 数据管理
- 30%数据统计,70%数据管理
-
数据管理,重中之重。一直铭记,以后一定会在数据这条路上走的更远。
10.总结
- 框架,在某种程度上,是思维之下最高的体现。
- 框架尽量先形成闭环(树形图为核心),再逐点分析突破
- 通过设计框架,运用合适的指标,形成模型,实现最终的业务目标。
第三周:Excel篇
Excel常用于敏捷,快速,需要短时间相应的场景下是非常便捷的数据处理工具。
相对于语言类例如python和R等则用于常规的,规律的场景中应用,便于形成日常规则统计分析。
对于学习的路径:Excel函数—>SQL函数——>python
必知必会内容:保证使用版本是2013+;培养好的数据表格习惯;主动性的搜索;多练习
Excel常见函数
1.文本函数
- 查找文本位置:find(“字符”,位置),常与left()提取所需要的位数组合使用。
- 文本拼接函数:concatenate
- 文本替换函数:replace
- 删除字符串中多余的(前后的)空格:trim
- 文本长度:len()
2.关联匹配函数
LOOKUP
VLOOKUP
INDEX:相当于数组定位
MATCH:查找数据在数组中的位置
OFFSET:偏移函数
ROW
COLUMN
HYPERLINK:去掉超链接
3.逻辑运算函数
- ture—-1 false—–0 判断是真是假
- 通常配合其他函数进行判断,相加判断满足条件的个数
- if函数
- is系列函数
4.计算统计函数
- sum
- sumproduct:特殊用法—-直接累加对应相乘
- count
- max / min
- rank:查找排名
- rand randbetween
- average
- quartile:分位数,第几分位数
- stdev
- substotal:功能丰富,号称“瑞士军刀”
- int:向下取整函数
- round:四舍五入取整函数(可在小数点位置取整数)
rand:随机数字,用来随机抽样使用
多条件就和和多条件计数的情况下是非常多的,所以countifs和sumifs用的是非常的多,基本能搞定所有的统计报表,达到实时统计。缺点就是数据量达到一定程度后,Excel运行会比较慢
5.时间序列
时间的本质是数字
周函数中,中国的习惯方式参数常选择2
常用时间序列函数有:
- year
- month
- day
- date
- weekday
- now
- weeknum
- today
6.Excel使用常见技巧
快捷键
- ctrl+方向键,光标快速移动
- ctrl+shift+方向键,快速框选
- ctrl+空格键,选定整列
- shift+空格键,选定整行
- ctrl+A 选择整张表
- alt+enter 换行
功能
- 分裂功能;查找替换;数据条(可视化);数据透视表(水晶表);冻结首行;
7.Excel常见工具
8.总结
个人觉得主要还是在于实践当中的灵活运用,作为学习,掌握有什么样的函数用来做什么就可以了,工作中遇到的时候可能忘了怎么拼,但是能直接搜索把函数找出来用知道在哪里面找就好。当然,记得更多的函数好处就是能迅速的通过函数的用法把函数灵活的组合去解决问题。其实最重要的也是通过逻辑关系把各种函数进行组合去解决问题。
第四周:数据可视化
1.有用的图表
对于数据可视化,大多数人下意识是要好看,下意识的去追求美感,觉得高大尚。其实,美丽的图表应该是有用的图表。
数据可视化的目的是让数据更高效,让读者更高效的进行阅读,而不是自己使用。好的可视化能突出背后的规律,突出重要的因素,最后才是美观。
数据可视化的最终目的:数据作用的最大化。
2.常见的图表
1.散点图
核心:展现数据之间的规律

呈现出一定规律的散点图可增加趋势线,并通过选项将规律用公式表示出来。
改进图:
- 气泡图:散点图的变种,引入第三个度量单位作为气泡的大小
- 单轴散点图

2.折线图

3.柱形图

4.饼形图

用面积区分大小,很多情况下肉眼是很难区分的,上图为玫瑰图—饼图的变种
5.漏斗图

6.雷达图

3.高级图表
1.树形图
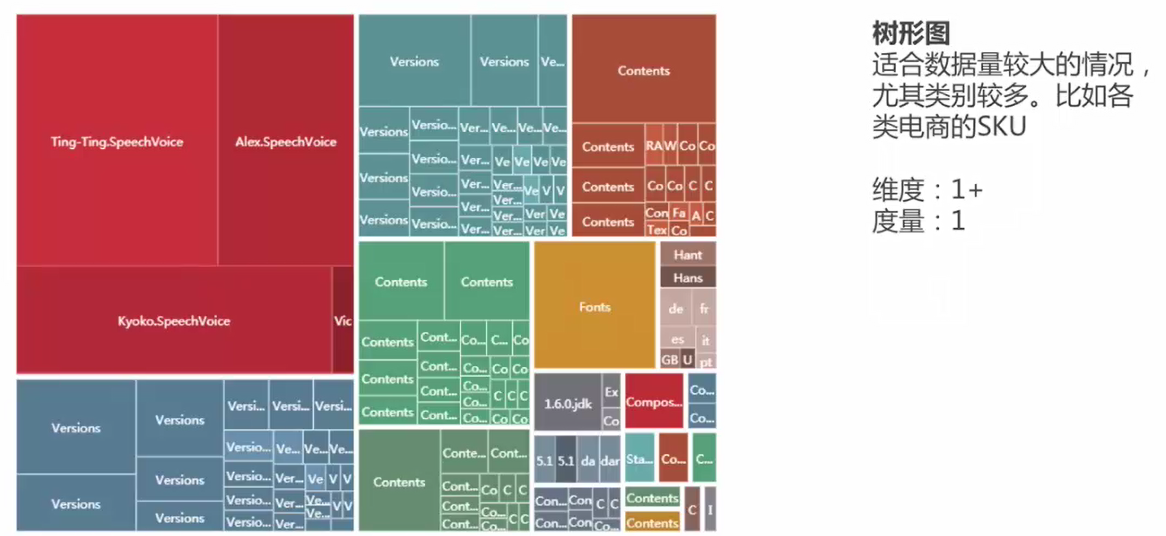
数据量较大、数据类别较多时,能更好的体现数据分类情况。
2.桑基图
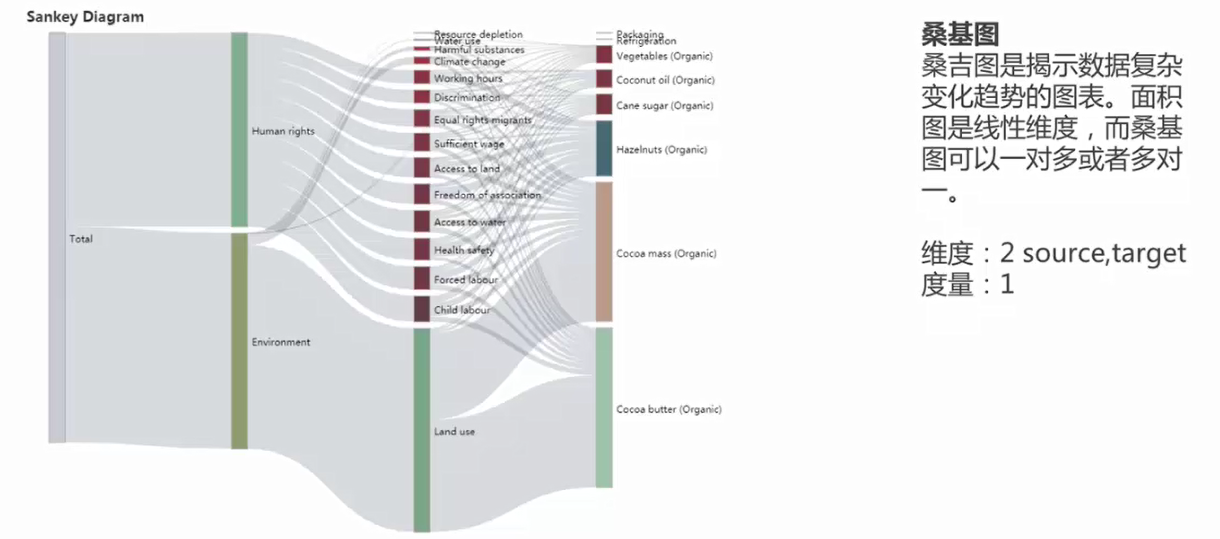
绘制流量变动最开始,网站的流量,监视用户的行为分析,表示用户在网站上的行为轨迹,一对多或多对一的关系
3.热力图
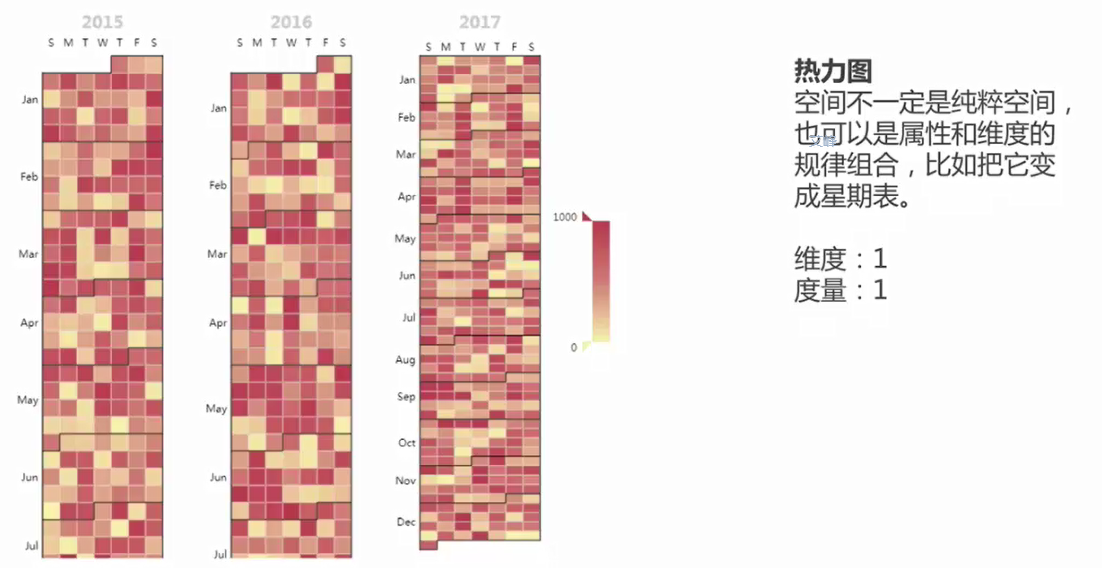
数据上下波动可用折线图观察,但是中间的某种关系展示揭示特殊关系使用热力图则可看出来。
4.关系图
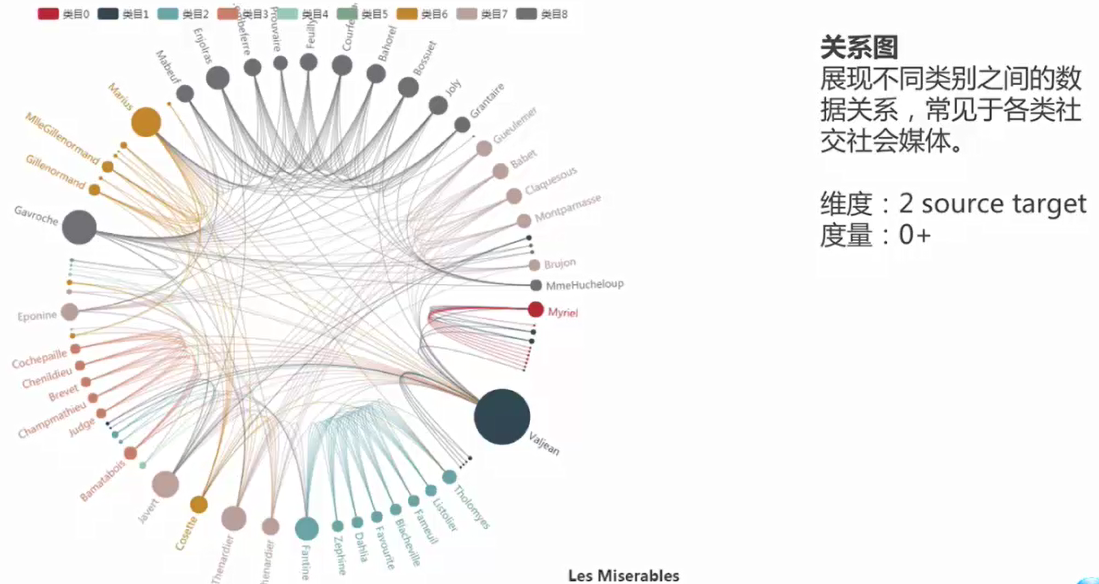
社交,社会媒体,微博的传播,用户和用户之间的关注等
5.箱线图

揭示数据的分布情况
6.标靶图

7.词云图

8.地理图
数据和空间的关系
4.图表绘制工具与技巧
1.绘制工具
- 初级—Excel
- 中高级—编程python、R和BI工具
2.绘制技巧
1.颜色搭配
color.adobe.com上有多种主流颜色搭配
2.颜色搭配原则
- 把需要聚焦的数据进行颜色凸显
- 去掉多余没有用的元素
- 横纵辅助线如果对肉眼观察无帮助则去掉
- 在报告中,内容交给单元格来解决
- 有设计规范
3.次坐标轴的使用,使得数据能体现更多细节。
3.杜邦分析法

5.Power BI
1.BI基本功能要素
- 单一图表没有意义,三表成虎,通过多表多因素展现分析。注意设计的表格揭示的是现象?还是原因?
- BI中,power BI和Tableau是最著名的BI软件。其中,Power BI免费易用适合新手入门。

BI中的数据链接,最好直接连接数据库或者CSV文件,尽量不要xls文件。
power BI 的功能特点:
- 制作的图表可以进行联动
- 多对对的关系不能进行关联
- power BI内的函数使用与Excel的函数应用基本一致,不建议话太多的精力去学power BI里面的函数。
- 建议使用Excel将数据进行清洗后,再已.csv的形式导入BI内进行操作。
- power BI可以引入第三方的一些高级功能(80%都是微软自己的)来满足使用者需求,例如添加更多的图表形式,词云图等等。
2.Dashbord
- 布局和设计要素:主次分明+贴合场景+指标结构
- 建议先自己规划好(自己用草稿纸动手去画,思路会更好的捋顺清楚)
1.场景案例


- 考虑是谁在使用?
- 用户的目的是什么?
- 是希望进行监控?还是希望分析?
- 用户怎么使用?
- 怎么改善BI?很多BI是有监控的,看使用人都干什么,使用那些报表,会使用后台监控日志去调整改善BI的布局
2.指标结构案例

Dashbord是一个不断迭代的设计过程,需要根据目的,不断进化。
第五周:Mysql
这里先放上菜鸟教程的Mysql:http://www.runoob.com/mysql/mysql-tutorial.html
遇到不会的内容,可以再进行查找复习。
1.数据库的概念
- Mysql是最流行的关系型数据库管理系统
- 数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,
- RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
- 数据库的基本类型:char–文本 int–整数 float–小数 date–日期 timestamp–秒或者毫秒
2.基本语法
- 以下是基本通用的select语法:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]
select*form data.表名称 *,为通配符,代表全部
limit 20,限制搜索结果
order by,排序依据,可以设置多个依据。
where,对搜索结果进行一次过滤。其中可使用各种逻辑判断条件。模糊查找“%京%”
-
跨表分析,需要利用子查询。join可以用来跨表整合,join left常用

对于数据类型的改变,可以在select一行进行设置。
3.总结
- 对于SQL语法,可能是个人记性或者SQL太过生疏,2倍速度看过的视频,回头总结时语法都忘记了。
- 加上其他人的经验,SQL应该是需要到实践中去记忆与进步。
-
https://leetcode.com/ 刷题地址在这里,面试前刷一些。
第六周:统计学
1.描述性统计学
- 分类数据的描述性统计:单纯计数就可以
- 数据描述统计:
- 统计度量:平均数–数据分布比较均匀的情况下进行,中位数,众数,分位数(4分位、10分位、百分位)
- 图形:
- 权重预估(分位数)
- 数据分布(波动情况,标准差,方差)
- 数据标准化:

在实际用用的时候,有很多情况量纲不一致(即数据单位不一样)导致差异很大无法进行比较
用数据标准化将数据进行一定范围的压缩,得到的结果与数据业务意义无关,纯粹是数据上的波动达到可进行对比。
xi:数据的具体值
u:平均值
σ:标准差
标准化之后一般都是在0上下直接按波动的数字,就可以反应原始数据的典型特征进行分析。
但是,标准化的办法还需要根据实际数据类型确认,不同标准化办法的实际标准化意义不同。
关于销量等特征与时间的关系,需要从多个时间维度去分析才能得到更多结论。如,周期、月份和年份。
- 切比雪夫定理是一个经验定理,可以用来排除大部分异常值。数据量越大,精确度更高。

2.描述统计可视化
1.箱线图:描述一组数据的分布情况。

Excel中能直接对数据进行作图,并且还能添加许多对比条件。
2.直方图:数值数据分布的精确图形表示

标准型:分布均匀,出现在大多数场景下。
陡壁型:比较容易出现在收费领域
- 锯齿型:说明数据不够稳定
- 孤岛型:要研究分析孤岛产生的原因
- 偏峰型:销售数据一般会产生偏锋,一般会出现长尾(或左或右)
- 双峰型:两者数据混合一般会形成双峰
直方图引出另外一个概念:偏度,统计数据分布偏斜方向和程度的度量
正态分布:也称“常态分布”

以上公式成立是,有标准正态分布。


可以用来进行异常值排查,或者假设的数据分布。
3.概率推断统计
统计推断(statistical inference),指根据带随机性的观测数据(样本)以及问题的条件和假定(模型),而对未知事物作出的,以概率形式表述的推断。

重要概念:贝叶斯定理

在知道结果A已经发生,想要推导出各种原因发生的可能性情况。
贝叶斯分析的思路对于由证据的积累来推测一个事物发生的概率具有重大作用, 它告诉我们当我们要预测一个事物, 我们需要的是首先根据已有的经验和知识推断一个先验概率, 然后在新证据不断积累的情况下调整这个概率。整个通过积累证据来得到一个事件发生概率的过程我们称为贝叶斯分析。
第七周:Python
1.Python基本功能
1.利用Python写脚本
2.excel可视化有性能瓶颈,需要Python来实现。
3.Python安装与数据分析相关如下
- Python的数据科学环境
- Python基础
- Numpy和Pandas
- 数据可视化
- 数据分析案例
- 数据分析平台(轻量级BI)
2.Numpy和pandas
1.Python groupby
mysql不支持分组排序
2.concat和merge
concat是强行耦合
merge,是有共同名,优先表进行耦合
3.多重索引
4.文本函数

填充空值,None需要用np.nan,c语言形式的控制
pd.dropna()去除所有还有空值的行

5.Python pandas apply

6.聚合 apply

7。pandas数据透视


输出结果
7.python连接数据库
Pandas中读取数据库:
conn=pymysql.connect(
host='localhost',
user='root',
password='123456',
db='data_kejilie',
port=3306,
charset='utf8'
)
def reader(query,db):
sql=query
engine=create_engine('mysql+pymysql://root:123456@localhost/{0}?charset=utf8').format(db))
df=pd.read_sql(sql,engine)
return df
reader
cur.execute('select * from article_link ')
data=cur.fetchall()
cur.close()
conn.commit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.数据可视化
可视化课程没有进行记录,详情可以参照
https://www.kesci.com/apps/home/project/5a6cac37afceb51770d6ee9f
中的可视化代码展示。
4.案例实战分析
https://www.kesci.com/apps/home/project/5aa687afcbc87e3f21332885
利用课程提供的数据集,简单分析练手了一下。
5.数据分析平台
本次使用的是Python中的superset库,基于web的数据分析平台。
严重提示:安装这个库一定要新建一个虚拟环境后再进行pip安装,不然会使得依赖库和Anaconda中的部分库冲突,使得原环境的库无法正常调用
使用逻辑:
- 先加载数据库或者数据文件
- 写好sql语法,进行一定编辑数据集。
- 在silces里面对于数据集,进行一个个图的绘画与调整
- Dashboard里进行最后图表的汇合。

详情安装可以参考这篇文章:
http://blog.csdn.net/qq273681448/article/details/75050513
这个作者总结的非常好,特此贴出文章地址:https://blog.csdn.net/weixin_39722361/article/details/79522111