文章目录
- 1copy outerHTML复制网站源码法
-
- 2 python爬取CSDN博客文章(保存为html,txt,md)
-
- 3 一键打包个人的csdn博客文章
-
有时候遇到自己喜欢的博客,除了收藏点赞外,转载一下也是不错的选择,下面记录一下转载的过程及遇到的问题。
为了防止源文章删除,转载并保存到本地也是有必要的。
下面介绍三种方法,转载博客的方法
1copy outerHTML复制网站源码法
1.1复制源码
打开想要转载的博客界面:
- 右键->检查,然后页面右侧出现html代码
- Ctrl+F搜索 #article_content ,可以看到,源码中
被选中,对应着网页中的博客内容被选中,如下图所示。当然你也可以尝试点击选中别的代码块,就可以看到对应的博客内容被选中。
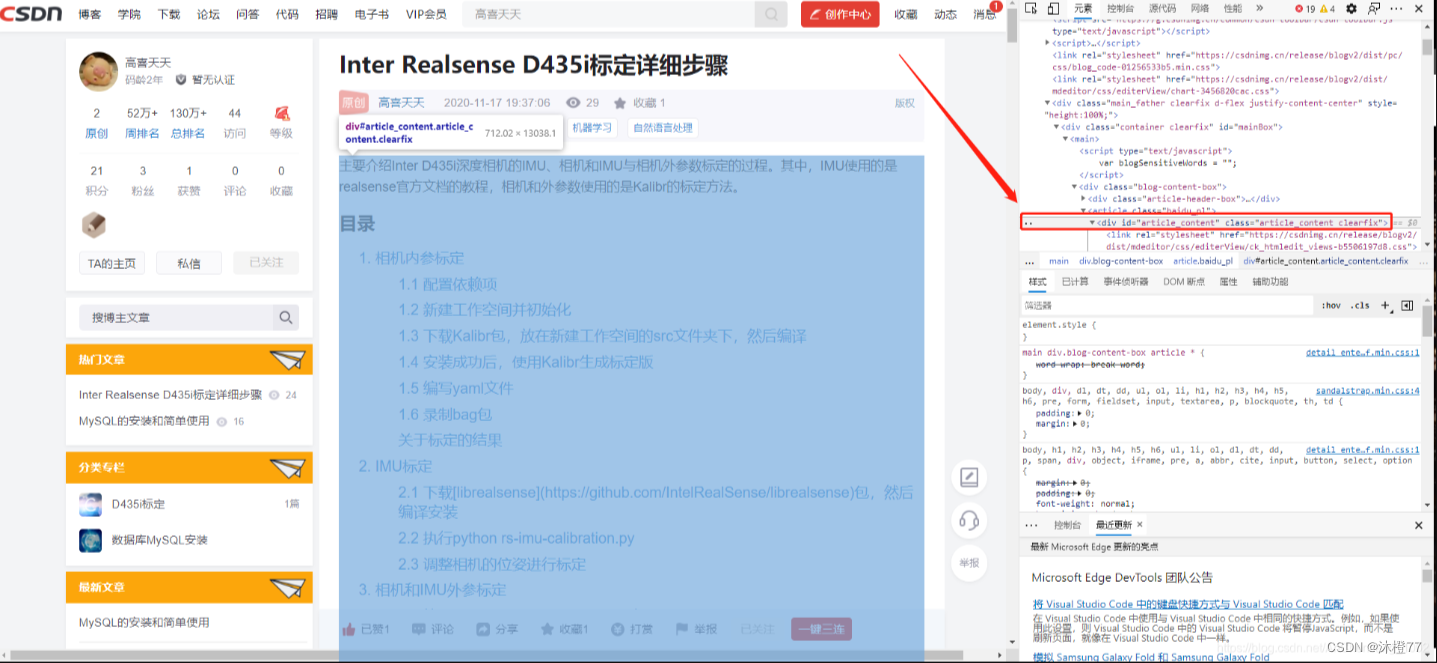
- 将鼠标放进上图所示的红框中,右键-> 复制 ->copy outerHTML,把内容复制下来,然后打开自己的Markdown编辑器,在里面粘贴即可。
1.2 遇到的问题
问题1:文章开头有大幅空白
如下图红框中,有大片的空白。
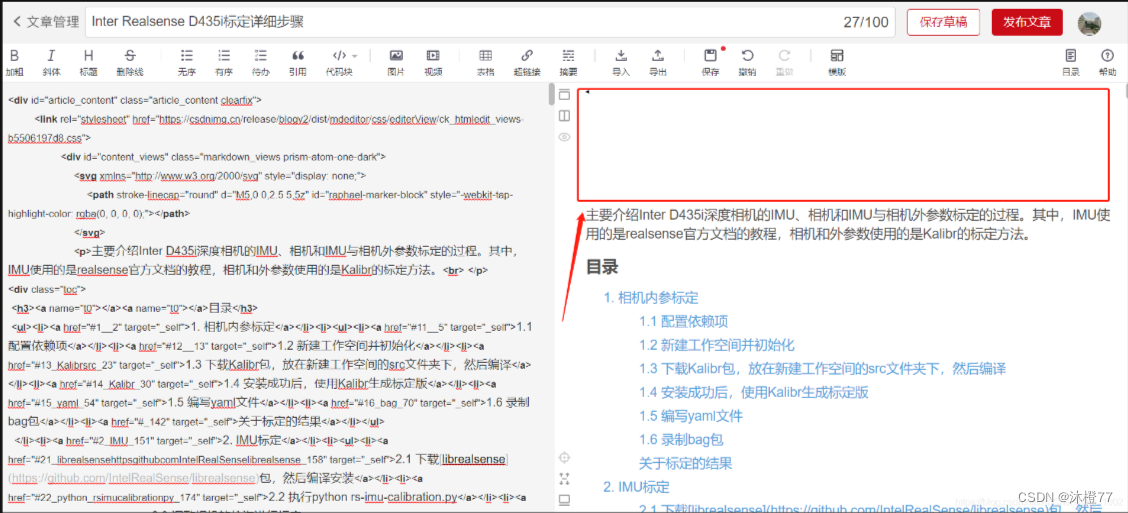
解决:
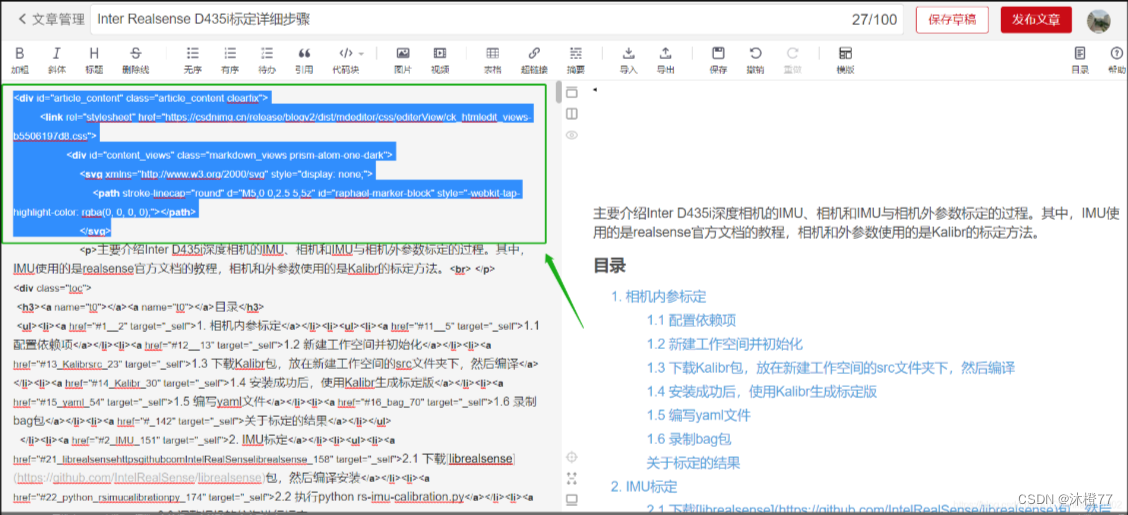
把绿框中的内容去掉,然后做相应的调整即可,最终版如下所示:
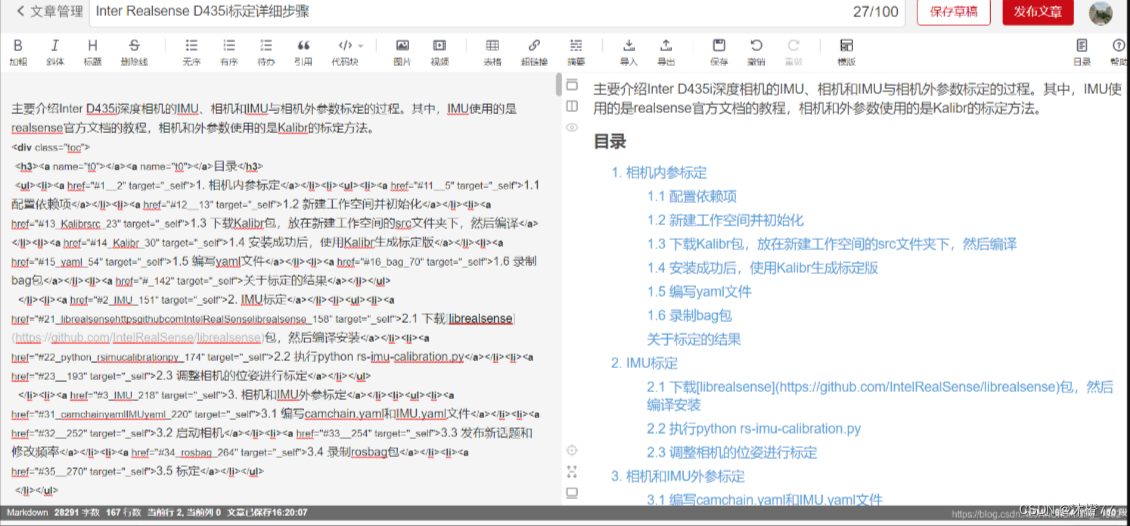
2 python爬取CSDN博客文章(保存为html,txt,md)
2.1 安装依赖
pip install html2text==2020.1.16
pip install lxml===4.6.3
pip install requests==2.26.0
2.2 完整代码
import requests
from html2text import HTML2Text
from lxml import etree
from html import unescape
import os
"""
requirements
打了箭头的才需要手动安装,其余是自动安装的依赖库
certifi==2021.10.8
charset-normalizer==2.0.7
cssselect==1.1.0
html2text==2020.1.16 -- <--
idna==3.3
lxml==4.6.3 ----------- <--
requests==2.26.0 ------- <--
urllib3==1.26.7
"""
def crawl(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
}
print("crawl...")
# 配置header破反爬
response = requests.get(url, headers=headers)
# 200就继续
if response.status_code == 200:
html = response.content.decode("utf8")
# print(html)
tree = etree.HTML(html)
print("look for text...")
# 找到需要的html块
title = tree.xpath('
block = tree.xpath('
# html
ohtml = unescape(etree.tostring(block[0]).decode("utf8"))
# 纯文本
text = block[0].xpath('string(.)').strip()
# print("html:", ohtml)
# print("text:", text)
print("title:", title)
save(ohtml, text,title)
# 完成!
print("finish!")
else:
print("failed!")
def save(html, text,title):
if "output" not in os.listdir():
# 不存在输出文件夹就创建
os.mkdir("output")
os.mkdir("output/html")
os.mkdir("output/text")
os.mkdir("output/markdown")
with open(f"output/html/{title}.html", 'w', encoding='utf8') as html_file:
# 保存html
print("write html...")
html_file.write(html)
with open(f"output/text/{title}.txt", 'w', encoding='utf8') as txt_file:
# 保存纯文本
print("write text...")
txt_file.write(text)
with open(f"output/markdown/{title}.md", 'w', encoding='utf8') as md_file:
# 保存markdown
print("write markdown...")
text_maker = HTML2Text()
# md转换
md_text = text_maker.handle(html)
md_file.write(md_text)
if __name__ == '__main__':
# 你想要爬取的文章url
url = ""
crawl(url)
将上面完整的代码保存到本地记事本,改后缀名为.py
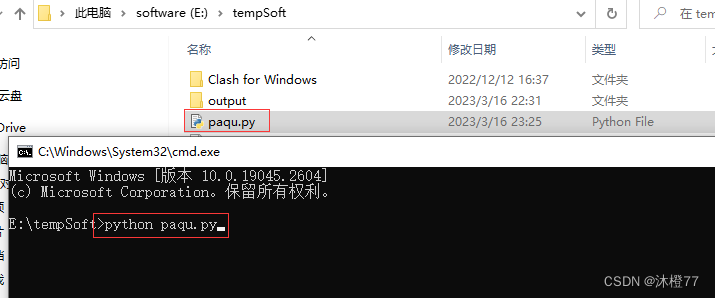
程序就会自动生成output文件夹了,其中有html,txt,md格式的文章了
参考资料
Xpath如何提取一个标签里的所有文本?_对明天的期待丶的博客-CSDN博客
python中HTML文档转义与反转义方法介绍_codingforhaifeng的博客-CSDN博客_python 反转义
html文件转md文件_OzupeSir-CSDN博客_html转md
两万字博文教你python爬虫requests库【详解篇】_孤寒者的博客-CSDN博客_python requests库
爬取CSDN博客文章
3 一键打包个人的csdn博客文章
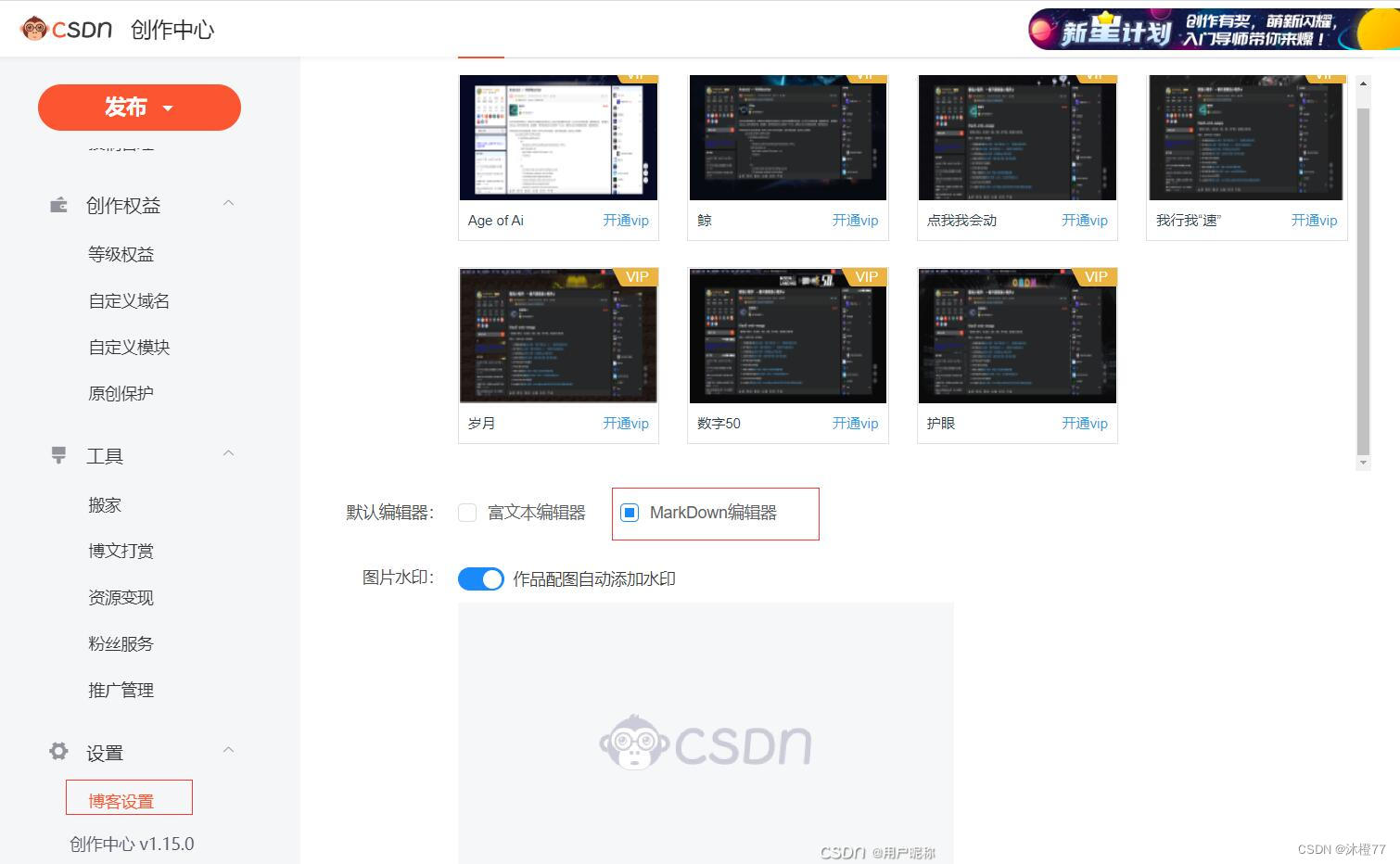
打包自己的csdn文章,发现用富文本编辑器写的文章,打包下来,也是md格式,但打开后内容为空
所以尽量设置MarkDown编辑器为默认编辑器
CSDN文章打包下载
CSDN 没有提供文章导出功能,只有导入功能,所以我们可以用下述方式下载 CSDN 上的文章并保存成 Markdown 格式
-
登录CSDN: https://blog.csdn.net/
-
前往:https://blog-console-api.csdn.net/(出现404也没关系)
-
点击F12,在控制台()中输入下段代码并回车
var s=document.createElement('script');s.type='text/javascript';
document.body.appendChild(s);
s.src='
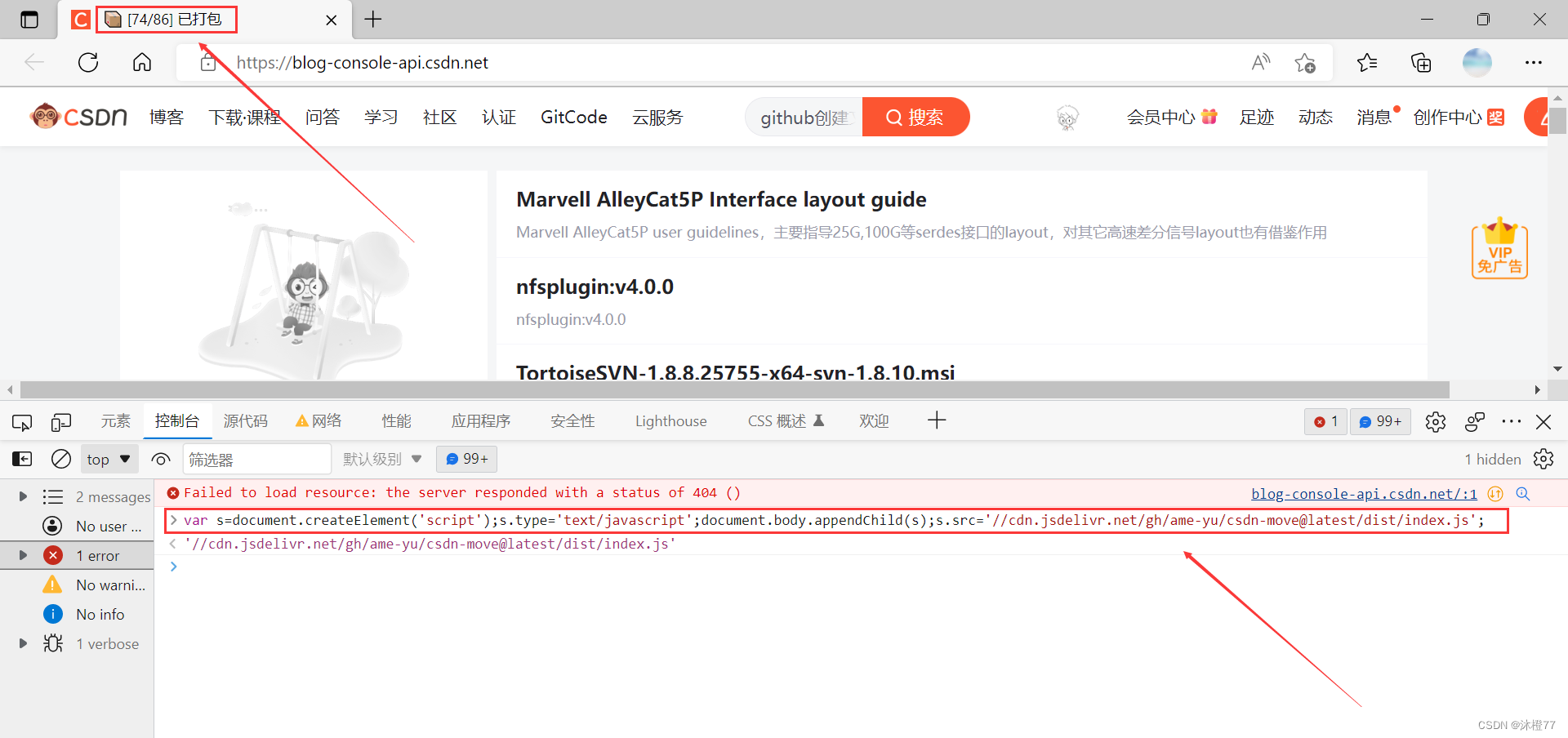
4. CSDN上的文章就会被下载下来啦!
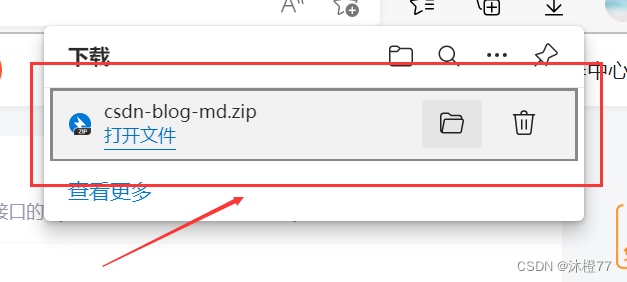
将下载打包的压缩包解压就可以看到文章了!
你用富文本编辑器写的文章,打包下载打开后,md文件是空的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)