从2010年开始,深度学习开始进入人们视野,2012年的Alexnet是第一个真真意义上的深度网络,尽管只有8层,但其错误率只有16.4%,2015年微软亚洲研究院的何凯明同学的Resnet使得错误率降低至3.57。


AlexNet 人工分配两块GPU,因此上图会有两条路线,但现在都是框架自己主动分配了。使用了11*11的卷积核。7层隐藏层,共8层,60M的参数,训练了1周。现在不会用这种网络结构了,因为太过时了。

VGG是牛津大学的成果,共有6个版本。比如-16版,-19版,11版。创新在于使用小窗口感受器(卷积核)。拿到了2014年的imageNet的第二名。1*1的卷积核作用:把多个通道累加起来,减少通道数,即减少维度。
2014年第一名是GoogNet,也使用了更小的卷积核。这个网络特点是使用了不同尺寸的卷积核对同一个通道操作,即同一层有不同的尺寸的卷积核,然后把结果concat,如果输出尺寸不一致,则可以控制步长即可。因此可以感受到不同层次的数据。共22层
按理说层数越多,模型复杂度可以更复杂。但当层数到了20层以上,训练很难,容易不收敛。因为随着网络深度加深,参数不断增加,每次求梯度都会使得梯度衰减,或者说梯度的误差累计,进而导致后面的网络因梯度消失而训练不动了。

深度残差网络:Resnet引入短路,可以退化至浅层网络。使得更深层次网络的训练成为可能。短路操作又叫残差,因为短路之间的部分网络,学习的是前后连接之间的差值。比如Resnet可以退化到VGG。152层。Resnet在多个领域都有10%以上的提升,是跨时代的网络。

这张图可以看出,性能最好的是inception-V4、resnet。尽管Alexnet计算量小,但是性能只有55%。VGG计算量非常大,但性能中等。所以不要使用VGG。所以现在使用inception-V4、resnet就OK。

Resnet由上图的基本单元堆叠而成,因此只需要实现基本单元,再在容器里堆叠即可。以上代码是实现基本单元。先是一个conv1卷积层,然后是一个BatchNorm2d归一化。激活函数使用F.relu。假设ch_in(通道输入)是256通道的图片,ch_out输出是256通道的图片,输入输出通道一致。如果不一致,即代码中extra中间部分if ch_out!=ch_in部分,可以使用1*1的卷积核降低通道数 。中间是1*1的卷积核,降低维度至64通道,然后继续用3*3尺寸卷积核提取特征,此时仍然为64通道,最后用1*1返回成256通道。先变成64通道是为了减少参数数量。代码中和图片不太一致,是用了两个3*3的卷积核,每次用完后赶紧数据归一化。最后是残差相加,即extra+out得到最终的out。
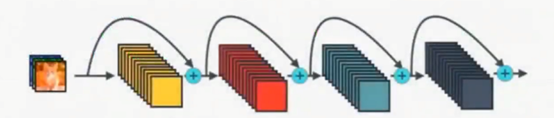
Densenet是在Resnet上改进的,上图是Resnet,下图是Densenet,使得每两层之间都可能断开,而不是仅相邻层间可以断开。因为断开很密集,所以叫Dense。

nn.Module是一个类,因此在我们自定义网络时,如下的My_Linear网络,先继承nn.Module类,再初始化定义w和b参数,然后定义前向计算构建的过程。

直接继承nn.Module的好处:nn.Module是一个基本的父类,其中有很多方便调用的函数(方法),比如nn.Conv2d,各种激活函数,各种卷积层。还有nn.Senquential函数可以方便重复某些网络,比如要建立152层网络,就可以使用这个,自动完成152层的前向计算。此外也方便管理w\b参数。
数据增强
Flip翻转

随机垂直翻转+随机水平翻转,再转化为Tensor,如果有需要可以Normalize归一化。
Rotate旋转、random Move随机移动、Crop裁剪
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)