3.1 程序的机器级表示
现有两个源文件:
main.c
#include<stdio.h>
void mulstore(long, long, long*);
int main()
{
long d;
mulstore(2, 3, &d);
printf("2 * 3 --> %ld\n", d);
return 0;
}
long mult2(long a, long b) {
long s = a * b;
return s;
}
mstore.c
long mult2(long, long);
void mulstore(long x, long y, long* dest) {
long t = mult2(x, y);
*dest = t;
}
执行指令
gcc -Og -o prog main.c mstore.c
其中-o prog表示将main.c和mstore.c编译后得到的可执行文件的文件名设置为prog,-Og是用来告诉gcc编译器生成符合原始C代码整体结构的机器代码。实际项目中可能会使用-O1或-O2(人称吸氧)等编译优化
执行指令
gcc -Og -S mstore.c
将获得mstore.c对应的汇编文件mstore.s

这其中,以.开头的行都是指导汇编器和链接器工作的伪指令,在查看时可以忽略,得到如下汇编

其中pushq %rbx表示将寄存器rbx的值压入程序栈进行保存。
这里引入寄存器的背景知识,在Intel x86-64的处理器中包含16个通用目的寄存器:

这16个寄存器用来存储数据和指针。
其中分为调用者保存寄存器和被调用者保存寄存器

这里是func_A调用func_B,所以func_A是调用者,func_B是被调用者。因为func_B中修改了寄存器%rbx,而func_A在调用func_B前后也使用了寄存器%rbx,因此需要保证在调用func_B前后,func_A使用%rbx的值应该是一致的。
第一种:在func_A调用func_B前,提前保存%rbx的值,然后再调用结束后再将提前保存的值重恢复到%rbx中,这称为调用者保存。
第二种:在func_B调用%rbx前,先保存%rbx的值,在调用结束后,返回前,再恢复%rbx的值,这称为被调用者保存。
每个寄存器的保存策略不一定相同。
其中调用者寄存器:
%rbx, %rbp, %r12, %r13, %r14, %r15
被调用者寄存器:
%r10, %r11
%rax
%rdi, %rsi, %rdx, %rcx, %r8, %r9
pushq就是用来保存% rbx的值,在函数返回前,使用popq来恢复%rbx的值。
movq就是将%rdx的值复制到%rbx中
这条指令执行后,%rbx的内容和%rdx的内容一致,都是dest指针所指向的内存地址
根据寄存器用法定义
函数multistore的三个参数分别保存在%rdi,%rsi,%rdx中
这里的pushq, movq的后缀q都表示数据的大小。早期机器是16位,后来才扩展到32位。Intel用字(word)来表示16位的数据类型,32位的数据类型称为双字,64位的数据类型称为4字。

其中:
b -> byte
w -> word
l -> long word(double word)
q ->quad word
call mult2@PLT的返回值保存到%rax中。
movq %rax (%rbx) 是指将%rax的值送到%rbx所指向的内存地址处
ret表示函数返回即return
对于从源文件生成机器代码文件
执行gcc -Og -c mstore.c,即可得到机器代码文件mstore.o
借反汇编工具objdump可以将机器代码文件反汇编成汇编文件
objdump -d mstore.o

3.2 寄存器与数据传送指令
寄存器
这是上述所说的保存寄存器
调用者保存寄存器(Callee Saved)
%rbx, %rbp, %r12, %r13, %r14, %r15
被调用者保存寄存器(Caller Saved)
%r10, %r11
%rax 保存函数返回值
%rdi, %rsi, %rdx, %rcx, %r8, %r9 传递函数参数
%rsp用于保存程序栈结束位置
指令
操作码
movq, addq, subq, xorq, ret等
操作数
- 立即数(Immediate)
在AT&T格式的汇编中,立即数以$符号开头,后面跟一个整数,这个整数需要满足标准C语言的定义,如$8。 - 寄存器(Register)
在64位处理器上,64,32,16,8位的寄存器都可以作为操作数,如%rdx 寄存器带了小括号的情况,表示内存引用,如(%rdx) - 内存引用(Memory Reference)
将内存抽象成一个字节数组,当需要从内存中存取数据时,需要获取目的地址的起始地址addr和数据长度b
关于内存引用

有效地址是通过立即数与基址寄存器的值相加,再加上变址寄存器的值和比例因子的乘积,其中比例因子必须是1、2、4、8,这是因为只有这4种字节的基本数据类型。
举个例子:有数组int a[32],首先你需要通过基址寄存器获得基地址,如果你想查a[30]这个元素,那么就需要变址寄存器存储30,此外,由于每个元素的大小都是int大小,所以需要加上前30个元素的地址才能得到a[30]的地址,即比例因子。
mov指令
其中源操作数可以为立即数,寄存器和内存引用,而目的寄存器只能为寄存器或内存引用。同时x86-64位规定,源操作数和目的操作数不能同时为内存引用,因此如果需要将内存地址A的内容赋值给内存地址B,需要进行两次mov操作,第一次mov A register,第二次mov register B。
使用movb,movw, movl, movq是与其寄存器的位数对应的,b -> 8, w ->16, l -> 32, q ->64。
当movq指令的源操作数是立即数时,该立即数只能是32位的补码表示。对该数进行符号位扩展(Signed extended),将64位数传送到目的位置。
当立即数是64位时,使用指令movabsq,该指令的源操作数可以是任意的64位整数,目的操作数只能是寄存器。
当使用movl指令且其目的操作数是寄存器时,会将该寄存器的高4字节设置为全0。x86-64位处理器规定,任何对寄存器生成的32位值的指令都会把该寄存器的高位部分设置为0
当源操作数的数位小于目的操作数,需要进行零扩展或符号位扩展
零扩展
z表示zero零扩展
b, w, l, q分别表示8,16,32,64位
movzbw
movzbl
movzbq
movzwl
movzwq
movl代替了movzlq的功能,所以不需要movzlq
符号位扩展
s表示signed 符号位扩展
b, w, l, q分别表示8,16,32,64位
movsbw
movsbl
movsbq
movswl
movswq
movslq
cltq = movslq %eax, %rax
3.3 栈与数据传送指令
以执行加法操作a+b为例
首先CPU执行数据传送指令将a和b的值从内存读到寄存器中
以Intel x86-64位处理器为例,寄存器%rax的大小是64个比特位,即8个字节
变量a是long类型,占8个字节,%rax的全部64位数据位都用来保存变量a,表示为%rax
变量a是int类型,占4个字节,%rax的低32位数据位保存变量a,表示为%eax
变量a是short类型,占2个字节,%rax的低16位数据位保存变量a,表示为%ax
变量a是char类型,占1个字节,%rax的低8位数据位保存变量a,表示为%al
需要注意的是,%ax的高8位表示为%ah

图源自:九曲阑干
main.c
#include<stdio.h>
long exchange(long *xp, long y);
int main()
{
long a = 4;
long b = exchange(&a, 3);
printf("a = %ld, b = %ld\n", a, b);
return 0;
}
exchange.c
long exchange(long* xp, long y) {
long x = *xp;
*xp = y;
return x;
}
执行指令
gcc -o main main.c exchange.c
运行得到
a = 3, b = 4
对于
exchange.c
long exchange(long* xp, long y) {
long x = *xp;
*xp = y;
return x;
}
执行
gcc -Og -S exchange.c
其汇编为
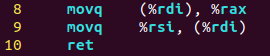
其中movq是数据传送指令,ret是返回指令
根据寄存器使用,%rdi存储函数传递的第一个参数long *xp,%rsi存储函数传递的第二个参数long y
-
movq (%rdi), %rax表示从xp指向的内存中读取数值到寄存器%rax,内存地址保存在寄存器%rdi中,这条指令对应
long x = *xp;
因为最后exchange函数返回变量x的值,因此这里直接将数值x保存到寄存器%rax中。
-
movq %rsi, (%rdi)表示将变量y的值写到内存中,变量y存储在寄存器%rsi中,内存地址保存在寄存器%rdi中,这条指令对应
*xp = y;
除此之外,将值传递给参数的这部分数据传送指令需要借助程序栈。
栈在内存中是从高地址到低地址的(User Stack),所以栈顶是所有栈元素地址中最低的。

当我们保存%rax中的数据0x123,可以使用pushq %rax,而这个指令又可以分解为:
subq $8 %rsp,表示将栈顶往低地址移动,然后指令movq %rax, (%rsp)表示将%rax中的数据存储到%rsp指向的内存地址处。
当使用popq %rbx时,指令又可以分解为:movq (%rsp), %rbx将%rsp指向的内存地址处的数据保存到%rbx中,然后指令addq $8 %rsp将栈顶的地址往高地址移动进行弹出操作。但是直到再次压栈访问到该地址时,才会将该地址的数据覆盖。
3.4 算术和逻辑运算指令
lea指令即Load Effective Address,即:将一个内存地址直接赋值给目的操作数,所以有些时候也被用来加法和有限的乘法运算
指令leaq 7(%rdx, %rdx, 4), %rax
若%rdx存储的值为x,则有leaq 5x+7, %rax
这个指令将5x+7直接赋值给%rax,相当于将内存地址传递给了返回值寄存器%rax
scale.c
long scale(long x, long y, long z) {
long t = x + 4 * y + 12 * z;
return t;
}
通过指令
gcc -Og -S scale.c
得到

首先根据寄存器使用惯例,%rdi存储第一个传递参数,%rsi传递第二个传递参数,%rdx传递第三个传递参数
指令leaq (%rdi, %rsi, 4), %rax是将%rdi+4%rsi赋值给%rax,对应到代码就是计算x+4y
指令leaq(%rdx,%rdx,2), %rcx是将3%rdx赋值给%rcx,即得到3z
指令leaq 0(,%rcx,4),%rdx是将4%rcx赋值给%rdx,即得到12z
指令addq %rdx,%rax是将%rax的值和%rdx的值加起来,再赋给%rax,得到最终的x+4y+12z
最后ret
Unary Operations 一元操作
这组指令只有一个操作数,即该操作数既是源操作数,又是目的操作数
INC D D自增1
DEC D D自减1
NEG D D取负
NOT D D补码取反
其中D可以是寄存器,也可以是内存地址
Binary Operations 二元操作
ADD S, D 将D+S的结果赋值给D 加法
SUB S, D 将D-S的结果赋值给D 减法
IMUL S, D 将D*S的结果赋值给D 乘法
XOR S, D 将D^S的结果赋值给D 异或
OR S, D 将D|S的结果赋值给D 或运算
AND S, D 将D&S的结果赋值给D 与运算
Shift Operations 移位操作
SAL k, D D = D << k 算术左移,填0
SHL k, D D = D << k 逻辑左移,填0
SAR k, D D = D >> k_A 算术右移,填符号位
SHR k, D D = D >> k_L 逻辑右移,填0
对于移位量k,可以是一个立即数,也可以是放在寄存器%cl中的数。移位指令的k,如果是使用寄存器中的值,只允许%cl寄存器的值。而对于寄存器%cl,是一个8位寄存器,但是对于w位的数,
2
m
=
w
2^m=w
2m=w,只由%cl的低m位决定。
对于salb,由%cl的低3位决定
对于salw,由%cl的低4位决定
对于sall,由%cl的低5位决定
对于salq,由%cl的低6位决定
arith.c
long arith(long x, long y, long z) {
long t1 = x ^ y;
long t2 = z * 48;
long t3 = t1 & 0x0F0F0F0F;
long t4 = t2 - t3;
return t4;
}
执行
gcc -Og -S arith.c
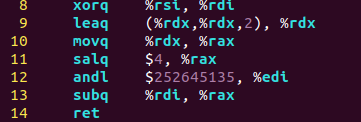
根据寄存器使用惯例,
%rsi存储第一个传递参数x,%rdi存储第二个传递参数y,%rdx存储第三个传递参数z
直接来看
-
异或
long t1 = x ^ y;
对应汇编
xorq %rsi, %rdi
这里是将%rdi和%rsi中的值异或得到的结果存储到%rdi中
-
乘法
long t2 = z * 48;
对应汇编
leaq (%rdx, %rdx, 2), %rdx --> 3%rdx = 3 * z
movq %rdx, %rax
salq $4, %rax --> (3 * z) << 4 = 3 * z * 16 = 48 * z
-
与运算
long t3 = t1 & 0x0F0F0F0F;
对应汇编
andl $252645135 %edi
这里由于立即数0x0F0F0F0F的高32位为0,所以只需要寄存器的低32位参与运算即可,所以只需要用%edi(%rdi的低32位)表示即可
-
减法
long t4 = t2 - t3;
对应汇编
subq %rdi, %rax
由于t2的值已经存储在寄存器%rax中,t3的值存储在寄存器%rdi中
所以两个寄存器的值进行一个减法,最后将结果存储在返回值寄存器%rax中即可
3.5 指令与条件码
subq %rax, %rdx
这条指令是使用算术逻辑单元ALU来执行的,ALU从寄存器中读取数据后,进行计算,并将计算结果返回到目的寄存器%rdx
如图所示:

除了执行算术和逻辑运算指令,ALU还会根据该运算的结果去设置条件码寄存器
条件码寄存器(Condition Code Register)
由CPU维护的,长度是单个比特位的(因此取值只能为0或1),描述最近执行操作的属性的寄存器
现有两条指令
t1时刻: addq %rax, %rbx
t2时刻: subq %rcx, %rdx
t1时刻条件码寄存器保存的就是指令addq %rax, %rbx的执行结果的属性,
t2时刻,条件码寄存器中的内容将被指令subq %rcx, %rdx所覆盖
- CF — Carry Flag 进位标志。当CPU最近执行的一条指令最高位产生了进位时,CF会被置为1,这里是针对无符号数的溢出。
- ZF — Zero Flag 零标志。当最近的操作结果等于零时,ZF会被置为1。
- SF — Sign Flag 符号标志。当最近的操作结果小于零时,SF会被置为1
- OF — Overflow Flag 溢出标志。针对有符号数,当最近的操作导致正溢出或者负溢出时,OF会被置为1
算术和逻辑运算指令设置CCR
条件码寄存器的值是由ALU在执行算术和逻辑运算指令时写入的,主要是在执行3.4算术和逻辑运算指令时被写入
对于不同指令制定了相应规则来设置条件码寄存器
XOR S, D指令会使得CF=0,OF=0
INC D和DEC D会设置OF和ZF,但不会改变CF (这些是具体实现做出的具体操作)
cmpq和testq指令设置CCR
cmpq %rax, %rdx和subq %rax, %rdx类似,区别在于,在进行计算后,cmpq指令不会将计算结果存放到目的寄存器中,而仅仅是设置条件码寄存器
testq %rax, %rdx和andq %rax, %rdx类似,区别在于,在进行计算后,testq指令只会设置条件码寄存器
示例一
int comp(long a, long b) {
return (a == b);
}
对应汇编
comp:
cmpq %rsi, %rdi
sete %al
movzbl %al, %eax
ret
其中
cmpq %rsi, %rdi对应计算a-b的结果,当a=b,即a-b=0,会将ZF设置为1
sete %al 通常是不会直接读条件码寄存器,其中一种是根据条件码的某种组合,通过set类指令,将一个字节设置为0或1。这里是根据ZF的值,对%al寄存器进行赋值,后缀e是equal的意思。
如果ZF=1,指令sete将%al设置为1,如果ZF=0,指令sete将%al设置为0,再使用mov指令对%al进行零扩展,这里由于是返回int,所以扩展成32位即可,即%eax
示例二
int comp(char a, char b) {
return (a < b);
}
对应汇编
comp:
cmpq %rsi, %rdi
setl %al
movzbl %al, %eax
ret
判断小于的情况需要根据SF和OF的异或结果来判定,当SF^OF=1,设置%al等于1,否则设置%al等于0
进行a-b计算时,当a-b<0,SF=1,当发生溢出时,OF=1
当不发生溢出时
- 如果a-b<0,SF=1,OF=0
- 如果a-b>=0,SF=0,OF=0
当发生溢出时
有符号数的表示范围为:
[
−
2
w
−
1
,
2
w
−
1
−
1
]
[-2^{w-1},2^{w-1}-1]
[−2w−1,2w−1−1]
正溢出的结果一定是负,正溢出最大是转换成无符号数计算
(
2
w
−
1
−
1
)
−
(
−
2
w
−
1
)
=
2
w
−
1
(2^{w-1}-1)-(-2^{w-1})=2^w-1
(2w−1−1)−(−2w−1)=2w−1,再解释成有符号数就是
−
1
-1
−1,所以正溢出的结果最大为
−
1
-1
−1,即正溢出的结果永远是负数
负溢出的结果一定是正,负溢出最小是转换成无符号数计算
(
−
2
w
−
1
)
−
(
2
w
−
1
−
1
)
=
−
2
w
+
1
(-2^{w-1})-(2^{w-1}-1)=-2^w+1
(−2w−1)−(2w−1−1)=−2w+1,再解释成有符号数就是
1
1
1,所以负溢出的结果最小为
1
1
1,即负溢出的结果永远是正数
上述可以看到当a<b时,一定有SF^OF=1
关于其他计算也类似
3.6 跳转指令和循环
跳转指令
如下代码
abs.c
long absdiff_se(long x, long y) {
long result;
if(x < y) {
result = y - x;
} else {
result = x - y;
}
return result;
}
对应汇编
absdiff_se:
cmpq %rsi, %rdi
jl .L4
movq %rdi, %rax
subq %rsi, %rax
ret
.L4:
movq %rsi, %rax
subq %rdi, %rax
ret
根据寄存器使用惯例:%rsi存储第一个传递参数的值,%rdi存储第二个传递参数的值
cmpq %rsi, %rdi,即计算%rdi-%rsi的值并设置条件码寄存器,并且jl根据SF和OF的异或值进行跳转判断
相关的Jump指令跳转判断

对于绝对值实现的另一种方式
abstemp.c
long cmovdiff_se(long x, long y) {
long rval = y - x;
long eval = x - y;
long ntest = x >= y;
if(ntest) rval = eval;
return rval;
}
对应汇编
cmovdiff_se:
movq %rsi, %rdx
subq %rdi, %rdx
movq %rdi, %rax
subq %rsi, %rax
cmpq %rdi, %rsi
jg .L3
.L1:
rep ret
.L3:
movq %rdx, %rax
jmp .L1
根据寄存器使用惯例:%rsi存储第一个传递参数的值,%rdi存储第二个传递参数的值
%rdx通过movq和subq得到了x-y的值
%rax通过movq和subq得到了y-x的值
通过cmpq指令,通过%rsi-%rdi的值对条件码寄存器进行赋值
这里发现,我们给ntest赋的值是x>=y的判断bool值,但是编译器做了优化,因为x=y时一定有x-y=y-x, 所以这里并不是jge而是jg来跳转
这里的rep ret,应该是为了解决预测器出现的问题,解决办法就是在ret前添加rep,而CPU会忽略该前缀,并修复预测器。
以上汇编中:
jg .L3
.L1:
rep ret
.L3:
movq %rdx, %rax
jmp .L1
更好的实现是cmov相关指令
cmovge %rdx, %rax
ret
关于实现循环的指令
C语言中,没有专门实现循环的指令,循环通常是通过条件测试和跳转的结合来实现的
如下代码
long fact_do(long n) {
long result = 1;
do {
result *= n;
n = n - 1;
} while(n > 1);
return result;
}
对应汇编代码
fact_do:
movl $1, %eax
.L2:
imulq %rdi, %rax
subq $1, %rdi
cmpq $1, %rdi
jg .L2
rep ret
for和while的阶乘实现
for.c
long fact_for(long n) {
long i;
long result = 1;
for(i = 2; i <= n; i++)
result *= i;
return result;
}
while.c
long fact_for_while(long n) {
long i = 2;
long result = 1;
while(i <= n) {
result *= i;
i++;
}
return result;
}
查看两者的汇编

可以发现实际操作部分是完全一样的。
以下待完成
关于switch语句的实现指令
switch语句通过跳转表这种数据结构,使得实现更为高效
如下代码
void switch_eg(long x, long n, long* dest) {
long val = x;
switch(n) {
case 0:
val *= 13;
break;
case 2:
val += 10;
case 3:
val += 11;
break;
case 4:
case 6:
val += 11;
break;
default:
val = 0;
}
*dest = val;
}
对应汇编
.LFB0:
cmpq $6, %rsi
ja .L8
-------------------------
leaq .L4(%rip), %rcx
movslq (%rcx,%rsi,4), %rax
addq %rcx, %rax
jmp *%rax
-------------------------
.L4:
.long .L3-.L4
.long .L8-.L4
.long .L5-.L4
.long .L6-.L4
.long .L7-.L4
.long .L8-.L4
.long .L7-.L4
.L3:
leaq (%rdi,%rdi,2), %rax
leaq (%rdi,%rax,4), %rdi
jmp .L2
.L5:
addq $10, %rdi
.L6:
addq $11, %rdi
.L2:
movq %rdi, (%rdx)
ret
.L7:
addq $11, %rdi
jmp .L2
.L8:
movl $0, %edi
jmp .L2
关于这里被--------所包括的汇编代码,原版解释
首先:这里的.L4是指跳转表的地址,而跳转表中存储的是每个case函数的偏移量,例如对于case函数.L3,.L4中存储的是.L3-.L4
leaq, .L4(%rip), %rcx 这里的.L4(%rip)是一种特殊的寻址模式,指令的结果是基于给定相对地址的绝对地址,这样获得了.L4的绝对地址,存到%rcx中movslq (%rcx, %rsi, 4), %rax这里相当于将具体的某个函数数组中的元素(例如:.L3-.L4)保存到%rax中addq %rcx, %rax是将%rax = %rax + %rcx = (.L3-.L4) + .L4=.L3jmp *rax跳转到对应case函数处
这里的实现是:
C代码将跳转表声明为一个长度为7的数组,每个元素都指向代码未知的指针。
长度为7是因为要覆盖case0~case6的情况。
对于重复情况case4和case6,使用了相同的标号。
对于缺失情况case1和case5,使用了默认情况的标号。
使用跳转表的优点是执switch语句的时间和case数量无关,因此处理多重分治,switch的效率更高。
3.7 过程(函数调用)
函数调用包括传递控制(Passing Control),传递数据(Passing data)内存的分配与释放(Allocating and deallocating memory)
long Q() {}
long P() { Q();}
以上述代码为例,当函数Q正在执行时,函数P及其相关调用链上的函数都会被暂时挂起。
当函数执行所需要的内存空间超过寄存器能够存放的大小时,就会借助栈的存储空间,这部分存储空间叫作函数的栈帧,对于函数P调用函数Q的例子,包括较早的帧(Earlier Frames),调用函数P的帧(Frame for calling function P),正在执行的函数Q的帧(Frame for executing function Q)
返回地址
当函数P调用函数Q时,会把函数Q返回后应该返回到继续执行函数P的地址压入栈中。
这个将地址压入栈的操作是由调用指令call来实现的
这里以如下命令为例:
00000000000006da<main>:
6fb: e8 41 00 00 00 callq 741 <multstore>
700: 48 8b 14 24 mov (%rsp), %rdx
....
0000000000000741<multstore>
741: 53 push %rbx
742: 48 89 d3 mov %rdx, %rbx
这里执行时,先调用6fb这条指令,将multstore的地址写入到%rip程序指令寄存器中,同时也要将调用multstore后的返回地址(从multstore返回后的下一条指令的地址)压入栈中。当multstore执行完毕,指令ret从栈中将返回地址弹出 ,写入到%rip中,函数返回,继续执行main函数的剩余操作。
参数传递
前6个参数依次存放在
%rdi, %rsi, %rdx, %rcx, %r8, %r9
这里具体使用的寄存器是通过传递参数的字节大小来判断的

当参数超过6,多出的参数就会通过栈来传递
通过栈传递参数时,所有的数据大小都是向8的整数对齐,这里的返回地址是处于栈顶位置,所以相应被保存在栈中的参数的位置都是对应栈顶位置+8的倍数。

函数调用中的局部变量
当代码中对一个局部变量使用地址运算符时,需要对这个局部变量在栈上开辟相应的存储空间,栈提供了内存的分配与回收机制。
函数调用中的寄存器
如下代码
long P(long x, long y) {
long u = Q(y);
long v = Q(x);
return u + v;
}
long Q(long x) {}
对应P的汇编
P:
pushq %rbp
pushq %rbx
movq %rdi, %rbp
movq %rsi, %rdi
call Q
movq %rax, %rbx
movq %rbp, %rdi
call Q
addq %rbx, %rax
popq %rbx
popq %rbp
ret
在调用P时,%rdi保存x,%rsi保存y
而在P中调用Q时,%rdi要用来保存y,所以这里需要提前保存P的传递参数x,这里使用了%rbp保存了x的值,这里是先将两个寄存器%rbp和%rbx的值压栈,然后%rbp保存参数x的值,%rbx保存调用Q函数的结果值u。最后程序执行完毕,得到的返回值u+v存储到%rax中,最后将预先存储到栈中的原%rbp和%rbx的值弹出重新保存到对应的寄存器中。
这里的原因是因为%rbp和%rbx都是被调用者存储寄存器Caller Saved Register
函数调用之递归
如下代码
long rfact(long n) {
long result;
if(n <= 1) {
result = 1;
} else {
result = n * rfact(n - 1);
}
return result;
}
对应汇编
rfact:
cmpq $1, %rdi
jg .L8
movl $1, %eax
ret
.L8:
pushq %rbx
movq %rdi, %rbx
leaq -1(%rdi), %rdi
call rfact
imulq %rbx, %rax
popq %rbx
ret
这里首先是比较,当n大于1时,跳转到.L8处,否则直接将1赋值给返回值寄存器然后返回
对于.L8这里,实际还是上面的栈保存寄存器的值,然后将参数传递到%rbx中保存,然后减1进行rfact的函数调用
函数调用结束后进行乘法,最后将栈保存的寄存器值弹出重新赋值给寄存器,然后返回。
递归可以看成特殊的普通函数调用。
当然这里的问题是,当n很大时,会造成栈上保存过多的值,造成栈内存空间不足而导致的栈溢出现象。
3.8 数组的分配和访问
数组基本准则和指针运算
对于一个char类型的数组char A[8];,数组的首地址是
x
A
x_A
xA,那么数组A第i个元素A[i]的地址就是
x
A
+
i
x_A+i
xA+i
对于一个int类型的数组int B[4];,数组的首地址是
x
B
x_B
xB,那么数组B第i个元素B[i]的地址就是
x
B
+
4
×
i
x_B+4\times i
xB+4×i
如下代码
#include<stdio.h>
int main()
{
int x = 10;
char* p = &x;
int* q = &x;
if(p == q) printf("Yes\n");
else printf("No\n");
p++;
q++;
if(p == q) printf("Yes\n");
else printf("No\n");
return 0;
}
执行指令gcc -Og pq.c,并运行./a.out,会发现是输出Yes和No
初始两者都执行变量x的地址,两个指针p和q分别执行加1操作后,因为两个指针可以指向的数据类型的大小不同,其中char是1个字节,int是4个字节,所以对于指针对应进行加1操作后,p是在原地址的基础上加1,而q是在原地址的基础上加4,所以这里会使得两者之后指向的地址不同。这里也可以发现这样可以用来输出一个数据类型的每个字节的二进制表达形式。
对于访问一个数组int E[6];的元素,可以采用E[i]或者*(E+i)来访问
嵌套数组
对于一个数组int A[5][3];
其逻辑分布为:
A[0][0] A[0][1] A[0][2]
A[1][0] A[1][1] A[1][2]
A[2][0] A[2][1] A[2][2]
A[3][0] A[3][1] A[3][2]
A[4][0] A[4][1] A[4][2]
而物理上是按行优先的顺序存储每个元素的
A[0][0] A[0][1] A[0][2] ... A[4][0] A[4][1] A[4][2]
我的理解是将A看成一个一维数组,而这个一维数组的每个元素A[i]又是一个一维的长度为3的数组
数组的内存地址计算,这里A的首地址为
x
A
x_A
xA,则
A
]
i
]
[
j
]
A]i][j]
A]i][j]的地址为:
x
A
+
4
(
3
×
i
+
j
)
x_A+4(3\times i + j)
xA+4(3×i+j)
数组动态分配内存空间
在ISO C99的标准中,引入了变长数组的概念
即可以用变量来声明数组大小
1.
int n = 10;
int a[n];
2.
int func(int n, int a[n]) {}
这里注意n在参数表中的位置必须在a之前
3.9 结构体和联合体
结构体访问
对于如下结构体
struct rec{
int i;
int j;
int a[2];
int* p;
};
其内存表示为:
i: 0~3
j: 4~7
a: 8~15
a[0]: 8~11
a[1]: 12~15
p: 16~23
其中根据汇编寄存器使用规则,%rdi保存r,%rsi保存访问结构体中数组a的索引,那么这里如何访问r中的每个元素呢?
movl (%rdi), %eax //将r->i的值取出放到%eax中
movl %eax, 4(%rdi) // 将%eax的值放到r->j中,这里的立即数偏移是根据变量在结构体中定义的顺序确定的,因为int i占4个字节,所以立即数偏移4
leaq 8(%rdi, %rsi, 4), %rax // 这里是先获得了数组a[index]的地址,存放到%rax中,这里是因为只能对寄存器进行括号访问内存的格式
结构体对齐
struct S1 {
int i;
char c;
int j;
}
sizeof(S1) = 12
这里是进行了内存对齐操作
变量T必须在其字节数的倍数处开始存储
如int存储的起始地址必须是4的倍数,char存储的起始地址必须是1的倍数,long long存储的起始地址必须是8的倍数
那么对于S1这个结构体,int起始地址为0,char起始地址为4,起始地址都是其字节倍数,而int j的起始地址是5,并非4的倍数,所以为了内存对齐,这里需要保证j的起始存储地址为4的倍数,即8,这样S1的字节数就是12。
struct S2{
int i;
int j;
char c;
}
sizeof(S2) = 12
这里根据上述的要求,i的起始存储地址为0,j的起始存储地址为4,c的起始存储地址为8,总字节数应该为9
但是存在S2是作为数组去存储的,那么为了避免数组元素连续存储时发生问题,所以最后的char c要添加字节数以保证内存对齐,即最后添加3个字节,最终为12字节。
总的来说,结构体对齐需要满足,每个元素的起始存储地址都是其字节数的倍数,同时最后的总字节数需要是元素字节数的最大值的倍数
联合体
一个例子,对于二叉树,有叶子结点和内部节点。内部节点不含数据,都有指向两个孩子节点的指针,叶子节点都有两个double类型的数据值
struct node_s {
struct node_s* left;
struct node_s* right;
double data[2];
};
sizeof(node_s) = 32
因为该二叉树不是内部节点就是叶子节点
使用联合体定义
union node_u {
struct {
union node_u* left;
union node_u* right;
} internal;
double data[2];
};
sizeof(node_u) = 16
存在的问题是没办法确定一个节点是内部节点还是叶子节点,添加一个枚举类型用于确认节点类型
typedef enum{N_LEAF, N_INTERNAL} nodetype_t;
union node_t {
nodetype_t type;
union {
struct {
union node_t* left;
union node_t* right;
} internal;
double data[2];
}info;
};
sizeof(node_t) = 24
这里根据内存对齐直观上应该是32,但是由于枚举类型本质是int,占4个字节,同时因为机器字长为8,所以对齐到8即可,至于查看内存对齐的长度可以使用类似sizeof的alignof
联合体的另一种使用是可以查看一个元素每个字节的存储模式
对于一个double类型
union check_double {
double a;
unsigned char ch[8];
}
这时候就可以通过ch来查看a的每个字节存储模式。
3.10 缓冲区溢出
运行时栈
栈帧中会保存程序执行所需要的重要信息,如返回地址以及保存的寄存器的值。
在C语言中并不会对数组越界进行检查
- 此时若对越界数组进行写操作,就会破坏存储在栈中的状态信息
- 当程序使用了被修改的返回地址时,就会导致严重的错误
缓冲区溢出
如下代码
void echo() {
char buf[8];
gets(buf);
puts(buf);
}
gets是用来从stdin读入一行字符串的函数,在遇到回车换行或错误时停止,回车换行并不会被实际读入。
gets将读入的字符串复制到传入的buf首地址处,并在字符串最后一个字符之后加上一个'\0'字符表示结束。
gets函数自C++14或C11后已经被弃用,原因在于gets并不能确定是否有足够大空间保存整个字符串,如果说输入的字符串过长,超过了传递参数中申请的内存大小,很可能会覆盖一些内存区域,导致安全问题
对抗缓冲区溢出攻击
很多计算机病毒就依靠缓冲区溢出这点对计算机系统进行攻击。
编译器和操作系统采取很多机制来限制入侵者通过这种攻击方式获得系统控制权,如:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)