从2006年开始,NVIDIA开始统一使用科学家的名字命名其显卡的微架构,第一个架构Tesla是第一个实现统一渲染(Unified Shaders)的微架构,同时引进了CUDA与Compute Capability(计算能力)的概念,对NVIDIA而言具有划时代的意义。
GPU的Compute Capability由其微架构与显卡核心确定:

Compute Capability决定了GPU的通用规格和可用特性,具体来说,可以用以下两个表格来表示:
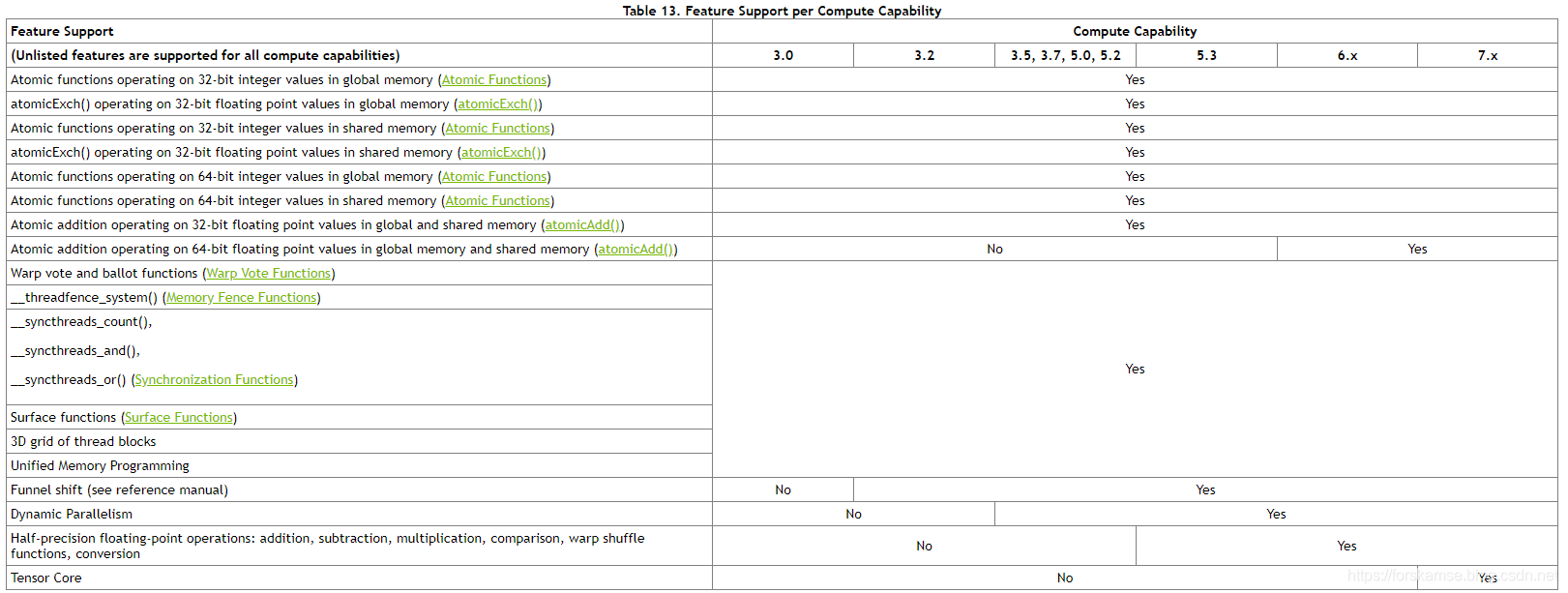
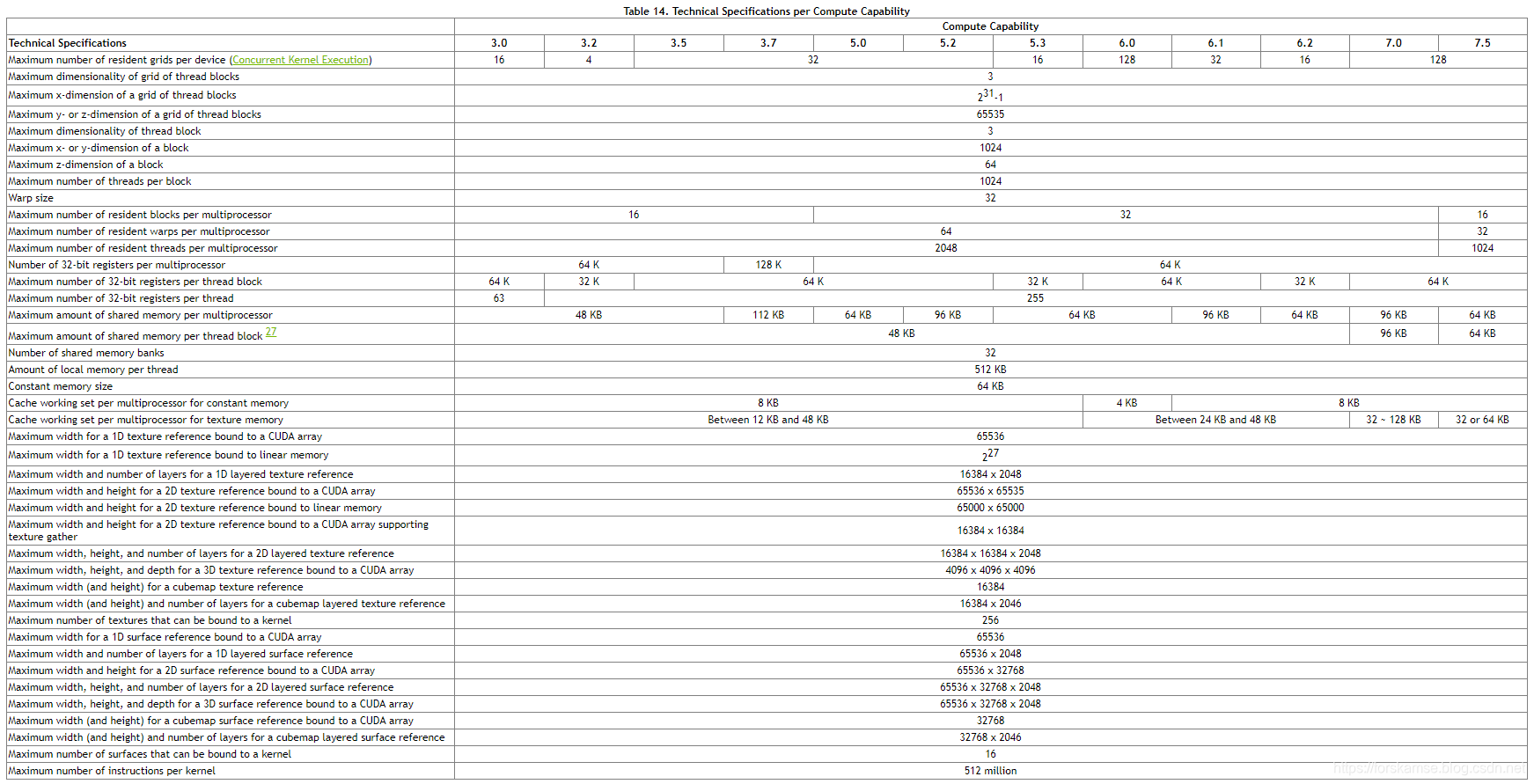
参考资料
https://en.wikipedia.org/wiki/CUDA
https://developer.nvidia.com/cuda-faq
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)