- 期刊: Analytical Chemistry
- 中科院最新分区(2022年12月最新版):1区(TOP)
- 影响因子(2021-2022):8.008
- 第一作者:Abigail A. Enders
- 通讯作者:Heather C. Allen
- 原文链接:Functional Group Identification for FTIR Spectra Using Image-Based Machine Learning Models
目录
论文标题
摘要
引言
方法
A. Python Scripts. (Phthon脚本)
B. Spectra Collection. (光谱收集)
C. Data Preprocessing. (数据预处理)
D. Labeling. (标签)
E. Machine Learning. (机器学习)
F. Accuracy and Loss. (准确率和损失)
G. Classification of Validation Data. (验证数据的分类)
RESULTS AND DISCUSSION (结果与讨论)
结论
论文标题
Functional Group Identification for FTIR Spectra Using Image-Based Machine Learning Models
使用基于图像的机器学习模型对FTIR光谱进行功能组识别
摘要
Fourier transform infrared spectroscopy (FTIR) is a ubiquitous spectroscopic technique. Spectral interpretation is a time-consuming process, but it yields important information about functional groups present in compounds and in complex substances. We develop a generalizable model via a machine learning (ML) algorithm using convolutional neural networks (CNNs) to identify the presence of functional groups in gas-phase FTIR spectra. The ML models reduce the amount of time required to analyze functional groups and facilitate interpretation of FTIR spectra. Through web scraping, we acquire intensity-frequency data from 8728 gas-phase organic molecules within the NIST spectral database and transform the data into spectral images. We successfully train models for 15 of the most common organic functional groups, which we then determine via identification from previously untrained spectra. These models serve to expand the application of FTIR measurements for facile analysis of organic samples. Our approach was done such that we have broad functional group models that infer in tandem to provide full interpretation of a spectrum. We present the first implementation of ML using image-based CNNs for predicting functional groups from a spectroscopic method.
傅里叶变换红外光谱(FTIR)是一种普遍存在的光谱技术。光谱解释是一个耗时的过程,但它可以提供化合物和复杂物质中存在的官能团的重要信息。我们通过机器学习(ML)算法,利用卷积神经网络(CNNs)开发了一个可推广的模型,以识别气相FTIR光谱中官能团的存在。ML模型减少了分析官能团所需的时间,并有助于FTIR光谱的解释。通过网络抓取,从NIST光谱数据库中的8728个气相有机分子中获取强度-频率数据,并将其转化为光谱图像。我们成功地训练了15个最常见的有机官能团的模型,然后通过识别以前未训练的光谱来确定。这些模型扩展了FTIR测量在有机样品分析中的应用。我们的方法是这样做的,我们有广泛的官能团模型,串联推断,以提供一个光谱的完整解释。我们提出了ML的第一个实现使用基于图像的cnn从光谱方法预测官能团。
引言
The anthropogenic impact on the climate and environment has prompted the analysis and detection of pollutants or contaminants with Fourier transform infrared spectroscopy (FTIR), such as microplastics in waters1,2 and table salts,3 nitrates from agricultural fertilizers in soil,4−6 and polyaromatic hydrocarbons in the ocean’s surface.7,8 The diversity of the chemical composition of the pollutants and the central fundamental technique of FTIR underscores the importance of a computational method for improved throughput of spectral analysis. The bottleneck is most frequently the assignment of peaks to relevant functional groups.9,10
人类活动对气候和环境的影响促使人们利用傅里叶变换红外光谱(FTIR)分析和检测污染物或污染物,如水中的微塑料和表盐、土壤中的农业肥料硝酸盐、海洋表面的和多芳香烃。污染物化学组成的多样性和FTIR的核心基本技术强调了计算方法对提高光谱分析吞吐量的重要性。瓶颈最常见的是将峰分配给相关的官能团。
Functional groups describe and define the physical and chemical properties of compounds.11,12 Identification of many organic groups is accomplished via FTIR due to the associated unique vibrational frequencies.13,14 Large numbers of spectra are time consuming to analyze and require expert chemist analysis to determine present composition. This limits the application of FTIR spectral techniques as a sampling method for functional group elucidation. There is thus an unexplored, yet applicable field of FTIR spectral interpretation through statistical methods. Progress toward machine learning (ML) methods for environmental pollutant analysis has been explored for specific, targeted applications.9,15−17 Generalizable functional group ML models would increase the utility of FTIR sample screening in environmental and other chemistry applications.18,19
官能团描述和定义化合物的物理和化学性质。许多有机基团的识别是通过FTIR完成的,因为相关的独特的振动频率。大量的光谱需要花费大量的时间来分析,并且需要专家的化学分析来确定现有的成分。这限制了FTIR光谱技术作为官能团解释的采样方法的应用。因此,利用统计方法对FTIR光谱进行解译是一个尚未开发、但仍具有应用价值的领域。用于环境污染物分析的机器学习(ML)方法的进展已经探索了具体的、有针对性的应用。可推广的官能团ML模型将增加FTIR样品筛选在环境和其他化学应用中的效用。
In this study, we investigate the implementation of convolutional neural networks (CNNs)20 to identify functional groups present in FTIR spectra. By limiting spectral preprocessing, we explore a minimalistic approach to allow the network to learn spectral patterns for successful recognition of the 15 most common organic functional groups (Table 1).
在本研究中,我们研究了卷积神经网络(CNNs)的实现,以识别存在于FTIR光谱中的官能团。通过限制光谱预处理,我们探索了一种最小化的方法,允许网络学习光谱模式,以成功识别15个最常见的有机官能团(表1)。

ML serves to address a need for quick identification of spectral components.21 To date, the use of a CNN to broadly classify functional groups has not been reported. CNNs work by having layers of nodes called neurons; these neurons can be trained on data to identify spectral components that were observed in the training data in new spectra. The algorithm works to minimize a loss function; this is done by comparing answers given by the CNN to the true answers from a training data set. The difference between the reported and the true presence of a group constitutes the loss function. The training data set is a randomly segmented subset of spectral images that the CNN uses to learn and adjust neuron weights.
ML用于解决快速识别光谱成分的需要。到目前为止,使用CNN对官能团进行广泛分类的报道还没有。CNN通过称为神经元的节点层工作;这些神经元可以对数据进行训练,以识别在新光谱中观察到的训练数据中的光谱成分。该算法的工作原理是最小化损失函数;这是通过将CNN给出的答案与训练数据集中的真实答案进行比较来完成的。报告的和真实存在的群体之间的差异构成了损失函数。训练数据集是一个随机分割的光谱图像子集,CNN用来学习和调整神经元的权值。
CNNs expand upon artificial neural networks (ANNs) by using mathematical convolutions to provide convolved data to the following neuron. Each neuron has a receptive field for which it convolves the information, similar to how a human brain has regions of neurons designated for processing specific information.22 CNNs significantly reduce the number of neurons per pixel that a traditional feed-forward network requires to capture the complexity of an image. Thus, CNNs are a sophisticated solution to the alternative complex network required to machine learn images by capturing the spatial and temporal uniqueness of images. FTIR spectra offer unique “images” to evaluate using the sophisticated ML advancements.
CNN扩展人工神经网络(ann),使用数学卷积为下一个神经元提供卷积数据。每个神经元都有一个接收区域,用于卷积信息,类似于人类大脑有专门处理特定信息的神经元区域。CNN大大减少了传统前馈网络捕捉图像复杂性所需的每像素神经元数量。因此,cnn是一种复杂网络的复杂解决方案,需要机器学习图像,通过捕捉图像的空间和时间唯一性。FTIR光谱提供了独特的“图像”,以评估使用先进的ML进展。
We probe the effectiveness of image recognition ML as a facile solution to FTIR spectral interpretation. The information contained in a spectrum is most often presented to a chemist as a two-dimensional (2D) image; therefore, it is desirable to develop models that learn via similar spectral visualization.23 Determining functional groups present in spectra requires analysis of both peak location on the frequency axis and shape; training models of spectra as images allows for an elegant approach that utilizes the totality of information obtained from a spectrum. Previous implementations of FTIR ML for functional group identification have limited,24 averaged,25 and segmented24,26 spectral data to reduce information used during training. The computational resources available today make this an unnecessary and limiting feature. We include all available spectral data from 4000 to 600  to reduce any biases in the learning process.
to reduce any biases in the learning process.
我们探讨了图像识别的有效性作为一个简单的解决方案的FTIR光谱解释。光谱中所包含的信息通常以二维(2D)图像的形式呈现给化学家;因此,开发通过类似光谱可视化来学习的模型是很有必要的。确定光谱中存在的官能团需要分析峰在频率轴上的位置和形状;作为图像的光谱训练模型允许一种优雅的方法,利用从光谱获得的全部信息。之前的FTIR ML用于官能团识别的实现对光谱数据进行了限制、平均和分割,以减少训练过程中使用的信息。现在可用的计算资源使这成为一个不必要的和有限的特性。我们收集了4000到600 的所有可用光谱数据,以减少学习过程中的任何偏差。
Current methods for spectral processing and interpretation are limited to library searching software27 and highly specific questions using implementations of ML including support vector machines,9,28 k-nearest neighbors,29,30 and principal component analysis (PCA),9,28,29 or factor analysis.31 Library searching methods require a pre-existing and transferable database for searching spectra. The initial creation of libraries requires an intensive endeavor for collecting a large enough spectral repository. Once implemented, libraries cannot extrapolate beyond the spectra included in the software. The size of libraries is not of significant concern for storage, but it is a cumbersome feature for application compatibility and relative use-to-memory consumption. ML does not require the transfer of training data to the user and can predict beyond the data used for training. The use of ML to resolve challenging implementations of FTIR spectra (e.g., extremely large data sets, continuous analysis) has become of interest as increased processing power makes it possible to train and infer (interpret unknown spectra) with complex algorithms.32−35 However, these highly specific models are only applicable in the setting in which they are developed because the training is completed on a narrow range of examples. To increase the amount of available training spectra or improve further calculations, ML algorithms in tandem with molecular dynamics have been explored.35−37
目前的光谱处理和解释方法仅限于库搜索软件和使用ML实现的高度具体的问题,包括支持向量机、 k-近邻、和主成分分析(PCA)、或因子分析。图书馆检索方法需要一个预先存在的和可转移的数据库来检索光谱。图书馆的最初创建需要集中精力收集足够大的光谱存储库。一旦实现,库在软件不能外推超出光谱包括。库的大小与存储无关,但对于应用程序兼容性和相对使用到内存的消耗来说,它是一个麻烦的特性。ML不需要将训练数据传递给用户,并且可以预测用于训练的数据以外的数据。使用ML来解决具有挑战性的FTIR光谱实现(例如,超大数据集,连续分析)已经变得有趣,因为增加的处理能力使训练和推断(用复杂算法解释未知光谱)成为可能。然而,这些高度特定的模型仅适用于开发它们的环境,因为训练是在一个狭窄范围的例子上完成的。为了增加可用训练谱的数量或改进进一步的计算,ML算法与分子动力学已经被探索。
Previous applications38−40 of ML have employed data preprocessing prior to training with unsupervised ML methods, such as PCA,28 which reduces the information in the training data. Spectral preprocessing is becoming an unnecessary component with the advances in ML. Data dimensionality reduction limits the transferability of the final model to broader applications. Deep learning results in feature extraction within the model before and during learning. ML requires any feature extraction (e.g., selecting peaks of interest) to be completed by a user (manually or automatically) before training the algorithm. Results from recent studies identify little variability in prediction success between preprocessed data (e.g., removing wavenumber regions, derivative spectra, and components resulting from PCA) and raw data pipelined to sophisticated ML methods.41,42 A recent application of ML successfully implemented broader methods for functional group analysis; however, the authors utilize a multilayer perceptron ML method with an autoencoder and train using two sources of data: FTIR and MS spectra.43 Implementing methods such as selecting spectral regions of interest24 can result in learning becoming memorization by the model; rather than making a generalizable algorithm that can be inferred on novel spectra, the model overfits the training data. An overfit model does well on spectra it has seen before but performs poorly on new data. Showing select data based on human evaluation increases the time required by an expert and introduces bias. While there are regions of relative disinterest to the chemist, it is not sufficient to ignore them in training. The absence of a peak is equally as informative as the presence of another.
在之前的ML应用中,使用无监督ML方法进行训练前的数据预处理,如PCA,这减少了训练数据中的信息。随着ML技术的发展,光谱预处理逐渐成为一个不必要的组成部分。数据降维限制了最终模型的可转移性。深度学习的结果是在学习之前和学习过程中在模型内部提取特征。ML要求用户在训练算法之前完成任何特征提取(例如,选择感兴趣的峰值)。最近的研究结果表明,预处理数据(例如,去除波数区域、导数光谱和由PCA得到的成分)与原始数据流水线到复杂的ML方法之间的预测成功差异很小。最近ML的应用成功地实现了更广泛的功能基团分析方法;然而,作者利用带有自动编码器的多层感知器ML方法,并使用两种数据来源:FTIR和MS光谱进行训练。选择感兴趣的光谱区域等实施方法可以使学习变成模型的记忆;该模型对训练数据进行过拟合,而不是制造一个可在新光谱上推断的可推广算法。过拟合模型在光谱上表现良好,但在新数据上表现不佳。显示基于人类评估的精选数据增加了专家所需的时间,并引入了偏见。虽然有些区域对化学家来说是相对不感兴趣的,但在训练中忽略它们是不够的。一个山峰的缺失和另一个山峰的存在同样能提供信息。
In our work, we create separate functional group models that are executed simultaneously resulting in complete analysis of FTIR spectra. We obtain spectra from the NIST Chemistry Webbook; peaks are not labeled in this data set. The use of individual functional group models presents a robust approach to establish a broad but precise computational analysis of spectra. Training a model for each functional group improves the overall accuracy attainable because each model is focused on a binary question: is this functional group present? The training of individual models does not impede the speed of spectrum analysis achieved and results are provided succinctly. By approaching the classification of spectra via the proposed method, we reduce the likelihood that the model learns a connection between functional groups that is not chemically relevant. In other words, one present functional group does not indicate another group’s presence or absence. Individually trained models reduce the potential for this and improve the overall accuracy by posing a simplified question. Here, we develop effective and accurate FTIR ML models that apply to broader questions, limit spectral preprocessing, and provide the entire spectrum to the algorithm.
在我们的工作中,我们创建了独立的官能团模型,这些模型可以同时执行,从而得到FTIR光谱的完整分析。我们从NIST化学网络书获得光谱;峰在这个数据集中没有标记。使用单个官能团模型提出了一个稳健的方法来建立一个广泛但精确的光谱计算分析。为每个官能团训练一个模型可以提高整体的准确性,因为每个模型都聚焦于一个二元问题:这个功能组是否存在?单个模型的训练并不妨碍频谱分析的速度,结果被简洁地提供。通过采用所提出的方法对光谱进行分类,我们降低了模型在化学上不相关的官能团之间学习联系的可能性。换句话说,一个存在的的官能团并不表示另一个官能团的存在或缺失。单独训练的模型减少了这种可能性,并通过提出一个简化的问题来提高总体的准确性。在此,我们开发了适用于更广泛问题的有效、准确的FTIR ML模型,限制了光谱预处理,并为算法提供了整个光谱。
方法
A. Python Scripts. (Phthon脚本)
All Python scripts can be accessed from our repository at this address: https://github.com/Ohio-StateAllen-Lab/FTIRMachineLearning. The FTIR spectra are the property of NIST and can be accessed through their website. The implementation of Inception V344 is modified for our use, and the original source is linked on our repository with the published modified version. The computational procedure is described in detail in the Supporting Information and is documented in each Python script.
所有Python脚本都可以从我们的存储库访问:https://github.com/Ohio-StateAllen-Lab/FTIRMachineLearning。FTIR光谱是NIST的特性,可以通过他们的网站访问。Inception V344的实现已经为我们的使用进行了修改,原始源代码在我们的存储库中与发布的修改版本进行了链接。计算过程在支持信息中详细描述,并在每个Python脚本中文档化。
B. Spectra Collection. (光谱收集)
Data was obtained from the National Institute for Science and Technology Chemistry WebBook via a web scraping implementation in Selenium using the CAS number identifier from the official list of compounds in the WebBook.45 When a compound had an FTIR spectrum, the file, in jcamp-dx format, was retrieved and stored with the CAS number as the filename. A total of 8728 spectra from pure compounds in gas phase were obtained (Figure 1). Each spectrum’s InChI key was saved in a collective text file.
数据来自国家科学技术化学研究所的WebBook,通过Selenium的web抓取实现,使用的是WebBook中化合物的官方列表中的CAS编号标识符。当化合物具有FTIR光谱时,以jcamp-dx格式检索并以CAS号作为文件名存储该文件。从气相纯化合物中共获得8728个光谱(图1)。每个光谱的InChI键保存在一个集体文本文件中。

C. Data Preprocessing. (数据预处理)
Only spectra in absorbance and wavenumbers were used for training models. Each spectrum was evaluated to ensure it was in absorbance and wavenumbers via a Python script. Files in transmission or wavelength were relocated to a distinct directory to preserve all spectra obtained from web scraping. Files in the correct mode were converted from jcamp-dx to csv. Once converted, each spectrum was normalized so that the maximum peak height was 1. Normalized spectra were saved as jpg images.
训练模型只使用吸光度和波数中的光谱。通过Python脚本对每个光谱进行评估,以确保其具有吸光度和波数。传输或波长的文件被重新定位到一个独特的目录,以保存从网络抓取获得的所有光谱。在正确的模式下,文件从jcamp-dx转换为csv。转换后,将每个光谱归一化,使最大峰高为1。归一化的光谱保存为jpg图像。
The convolutional neural network model of the infrared spectral classification of logging gas designed in this work uses the LeNet-5 network architecture, and an improvement is made on this basis. The network model used mainly includes an input layer, convolutional layer, pooling layer, fully connected layer, and output layer. The input layer is the acquired gas infrared spectrum data; the output layer is the gas type and concentration information included in the input data. The network model in this work consists of three convolutional layers, two pooling layers, and one fully connected layer. The size of the convolution kernel of the convolution layer is 7 × 7, and the size of the convolution kernel of the pooling layer is 2 × 2. This work uses TensorFlow to build a convolutional neural network structure. The first, third, and fifth layers are convolution layers, the second and fourth layers are pooling layers, the sixth and seventh layers are fully connected layers, and the last layer is the output layer.
本文设计的测井气体红外光谱分类卷积神经网络模型采用Lenet-5网络结构,并在此基础上进行了改进。 所使用的网络模型主要包括输入层、卷积层、池化层、全连接层和输出层。 输入层为获取的气体红外光谱数据; 输出层是输入数据中包含的气体类型和浓度信息。 本文的网络模型由三个卷积层、两个池层和一个全连通层组成。 卷积层的卷积核大小为7×7,池化层的卷积核大小为2×2。 本工作使用TensorFlow构建卷积神经网络结构。 第一、三、五层为卷积层,第二、四层为池层,第六、七层为全连接层,最后一层为输出层。
Parameters in the neural network are important parts of the classification or regression problem, while in TensorFlow, variables are the parameters used to save and update the neural network. Variables also need to be assigned an initial value, and random numbers are often used to initialize variables in TensorFlow. In this work, the truncated_normal random number generator was used to assign random numbers to the initial value, and the random number generator was used to generate normally distributed random numbers.However, if the random value deviated from the mean value by more than two standard deviations, the random operation would be repeated.
神经网络中的参数是分类或回归问题的重要组成部分,而在TensorFlow中,变量是用来保存和更新神经网络的参数。 变量也需要赋一个初始值,在TensorFlow中经常使用随机数来初始化变量。 本文利用 truncated_normal 随机数生成器对初始值进行随机数赋值,并利用随机数生成器生成正态分布随机数,但如果随机数与均值的偏差超过两个标准差,则会重复随机操作。
D. Labeling. (标签)
Functional groups were identified via the InChI key. Using SMARTS functional group identifiers, each spectrum’s key was parsed to return binary indicators. Present functional groups are labeled as “1” and absent as “0”. Results were saved in one spreadsheet with CAS numbers as spectrum and file identifiers. Spectra were copied into directories based on the presence or absence of a functional group. This method allows one compound with multiple functional groups present to be copied into the directory for each group. Each of the 17 functional groups had two directories: positive and negative cases. Positive cases include the functional group and negative cases do not contain the group. Randomly, 10 photos, 5 from positive and negative, for each functional group were reserved for validation. Then, the directory containing more instances for a given group was reduced randomly until both directories contained the same number of spectra.
通过InChI键确定官能团。使用SMARTS官能团标识符,解析每个频谱的键以返回二进制指标。存在的官能团被标记为“1”,不存在被标记为“0”。结果保存在一个电子表格中,以CAS号作为光谱和文件标识符。光谱被复制到目录的基础上是否存在一个官能团。此方法允许将具有多个官能团的化合物复制到每个组的目录中。17个官能团各有两个目录:正和负例子。正例情况包括官能团,负例情况不包括官能团。随机抽取10张照片,正例和负例各5张照片,各官能团留待验证。然后,随机减少一个给定组中包含更多实例的目录,直到两个目录包含相同数量的光谱。
E. Machine Learning. (机器学习)
A convolutional neural network (CNN) for image recognition was employed. A unique model was trained for each functional group containing two classes. The functional groups and the number of images in the positive cases are presented in the Supporting Information. The architecture, Inception V3, was accessed from the available models on the Google TensorFlow library. Each model was trained for 10 000 epochs at a learning rate of 0.01, using an initialized version of Inception V3 and training the last layer of the model graph (Figure 2).
采用卷积神经网络(CNN)进行图像识别。为包含两个类的每个官能团训练一个独特的模型。在支持信息中给出了正例的官能团和图像数量。这个架构,Inception V3,是从谷歌TensorFlow库中可用的模型中访问的。每个模型以0.01的学习速率训练了10000代,使用初始化的Inception V3版本,并训练模型图的最后一层(图2)。
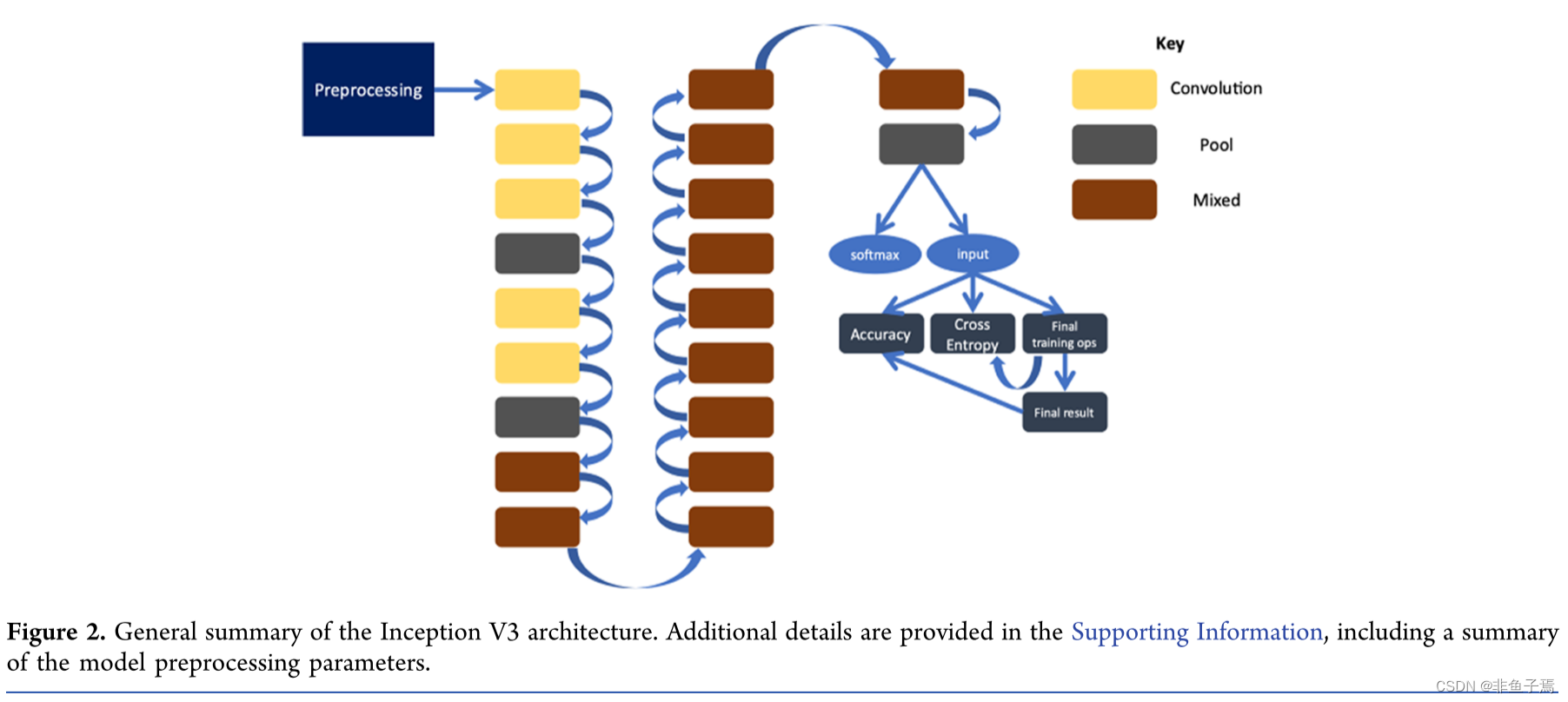
Inception V3 employs several techniques that ultimately lead to an increase in accuracy in the final model results. The model begins with preprocessing the input spectra, which includes decoding and reducing spectra to 299 × 299 × 3 pixels. The RMSProp optimizer results in the greatest accuracy. The specific equations describing the available optimizers are provided. As a postoptimization step, exponential moving average is employed. Batch normalization aids in reducing the time to convergence and occurs after convolutions in Inception V3; specific details, including the equations used, are provided. Additionally, learning rate adaptation is utilized to efficiently train the algorithms. Using gradual learning rate ramp-up, the initial learning rate for the model is 10% of the defined rate; after initializing, the rate is linearly increased until the slope of the decay rate intersects with the theoretically defined exponential decay rate. More specific details are included in the Supporting Information.
Inception V3采用了几种技术,最终导致了最终模型结果准确性的提高。该模型首先对输入光谱进行预处理,包括解码和将光谱缩小到299×299×3像素。RMSProp优化器的结果是最准确的。提供了描述现有优化器的具体方程式。作为一个后优化步骤,采用了指数移动平均法。批量归一化有助于减少收敛的时间,在Inception V3的卷积之后进行;具体细节,包括使用的方程,都已提供。此外,学习率适应被用来有效地训练算法。利用渐进式的学习率提升,模型的初始学习率为定义速率的10%;初始化后,速率线性增加,直到衰减率的斜率与理论上定义的指数衰减率相交。更具体的细节包括在支持信息中。
Models are trained and validated using an 80/20 split. For example, if 100 spectra are provided, 80 are used for training and 20 are used for validation. The preprocessing methods include distortion of the spectra such that after each backpropagation, the 80 spectra are altered and are not identical between iterations. Validation spectra are used to guide backpropagation but do not affect the training directly. The final train and validation accuracies presented are from the described source. After the models converge, the reserved 10 spectra are used to test the models further. These spectra are not used to adjust the model and present a more accurate representation of the model accuracy beyond the current data set.
使用80/20分割来训练和验证模型。例如,如果提供100个光谱,则80个用于训练,20个用于验证。预处理方法包括光谱的变形,这样在每次反向传播后,80个光谱被改变,在迭代之间不完全相同。验证光谱被用来指导反向传播,但不直接影响训练。给出的最终序列和验证精度来自所描述的源。模型收敛后,利用保留的10个光谱对模型进行进一步的检验。这些光谱不是用来调整模型的,而是在当前数据集之外更准确地表示模型的精度。
Parameters are initialized to reduce the time and computational power required to train a custom model. Models converge within the 10000 training steps, and early termination of training is not employed. It took 5 h to train the 15 models. Classification of an unknown spectrum requires 1 min.
初始化参数以减少训练自定义模型所需的时间和计算能力。模型在10000个训练步骤内收敛,不采用提前终止训练。训练这15个模型花了5个小时。对未知光谱进行分类需要1分钟。
F. Accuracy and Loss. (准确率和损失)
Accuracy and cross entropy (loss) for both training and test models were obtained and saved as csv files. The final accuracies and entropies for training and test results from each model are investigated to identify any anomalies.
获得了训练和测试模型的准确度和交叉熵(损失),并保存为csv文件。对每个模型的训练和测试结果的最终准确率和熵进行调查,以确定任何异常情况。
G. Classification of Validation Data. (验证数据的分类)
When spectra were classified, the models were called upon to infer (determine the functional groups present) and a final result was provided. Each functional group model was trained and validated separately, and the predictions were not used in conjunction to attempt ensemble classification. Models were evaluated independently of each other and from the embedded validation methods to further analyze prediction accuracy. The 10 reserved spectra were analyzed via the respective models they were withheld from to examine the learning quality of the algorithm. Confusion matrices were used to represent the true and predicted functional group for the 17 models.
当光谱被分类时,模型被要求进行推断(确定存在的官能团),并提供最终结果。每个功能组的模型都是单独训练和验证的,预测结果并没有被用于尝试集合分类。模型的评估是独立的,并从嵌入的验证方法来进一步分析预测的准确性。10个保留光谱通过它们各自的模型进行分析,以检查算法的学习质量。混淆矩阵被用来表示17个模型的真实和预测的官能团。
RESULTS AND DISCUSSION (结果与讨论)
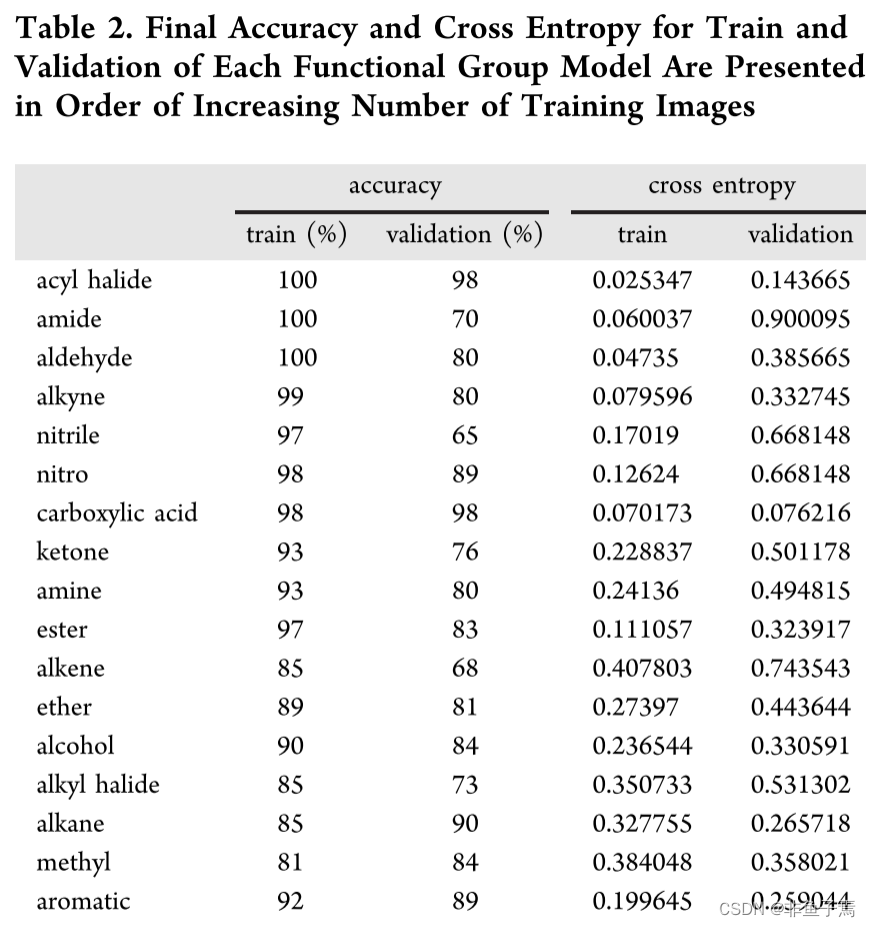
Using ∼9000 gas-phase FTIR spectra, we train 17 functional group models using image-based ML. Our methods result in 15 effectively identified functional groups (Table 2). Each model is trained independently. When a molecule has more than one functional group present, the models for the relevant functional group will identify the presence from the spectrum, resulting in a complete analysis for the 15 trained functional groups. Accuracy and cross entropy results from the last step of training are reported for the train and validation process. The two functional group models that underperform are aldehyde and nitrile based on model prediction of untrained spectra. We define underperforming as misidentifying more than 60% of test cases. The training accuracy is a measure of how well the model classifies the training data, which is used to train the network. A higher training accuracy indicates that the model is learning the training spectra. Validation accuracy expresses the ability of the model to generalize to untrained spectra, which is determined by the number of correctly classified validation spectra. Thus, it is more meaningful to have a higher validation accuracy, albeit not a requirement for a successful inferencing model. Cross entropy is the loss function used to evaluate the final model and is defined as the logarithm of the likelihood of a correct assignment. Smaller cross entropy values indicate that a model is well trained. We observe that cross entropy for training is less than validation. Models are more likely to correctly infer spectra that have been used to train and adjust weights, in comparison to the validation spectra.
我们使用9000个气相傅立叶变换红外光谱,使用基于图像的ML训练17个官能团模型。我们的方法产生了15个有效识别的功官能团(表2)。每个模型都是独立训练的。当一个分子有一个以上的官能团存在时,相关官能团的模型将从光谱中识别出其存在,从而形成对15个训练过的官能团的完整分析。报告了训练和验证过程中最后一步训练的准确度和交叉熵结果。根据对未经训练的光谱的模型预测,表现不佳的两个官能团模型是醛和腈。我们把表现不佳定义为错误识别60%以上的测试案例。训练准确率是衡量模型对训练数据分类的程度,这些数据被用来训练网络。较高的训练精度表明模型正在学习训练谱系。验证准确率表示模型对未训练光谱的归纳能力,它由正确分类的验证光谱的数量决定。因此,尽管不是一个成功的推断模型的要求,但有更高的验证准确率是更有意义的。交叉熵是用于评估最终模型的损失函数,被定义为正确分配的可能性的对数。较小的交叉熵值表明一个模型训练有素。我们观察到,训练的交叉熵比验证的要小。与验证光谱相比,模型更有可能正确推断出已经用于训练和调整权重的光谱。
A confusion matrix for each model was created by using spectra that have been withheld from training and testing data. A confusion matrix compares model assignments to the actual identities of the samples; it shows correct assignments along the trace of a matrix and false assignments off of the trace. Four models have perfect confusion matrices from the classification of 10 withheld images, five containing and not containing functional group spectra examples. The presence or absence of carboxylic acid, aromatic, methyl, and ester functional groups is correctly identified in the withheld spectra (Figure 3).
每个模型的混淆矩阵是通过使用训练和测试数据中被扣留的光谱来创建的。混淆矩阵将模型的分配与样品的实际身份进行比较;它显示了沿着矩阵轨迹的正确分配和离开轨迹的错误分配。四个模型有完美的混淆矩阵,来自10个扣留图像的分类,其中五个包含和不包含官能团光谱例子。羧酸、芳香族、甲基和酯类官能团的存在或不存在在扣留光谱中被正确识别(图3)。

The number of instances of each functional group occurring in the spectra varies significantly, with aromatic-containing spectra occurring most frequently with 3467 images. In contrast, acyl halide has 85 spectra for training and testing the model. We explored the relationship between the number of images and the cross entropy and accuracy for training and testing results (Figure 4). Training accuracy decreases with increasing number of spectra (Table 3). However, the final accuracy, determined by evaluating the unknown spectra for functional group identification, is not correlated to the number of images used for training. Our results indicate that the total number of training spectra does not affect the final performance of the models. The scattered, nonuniformity exhibited in Figure 4a,b depicts the deviation from a linear relationship between the number of spectra and accuracy and cross entropy for validation, confirming that the number of images is not influencing the performance of the models. Training accuracy provides insight into how well the model has learned the training images for a functional group model. Counterintuitively, few spectra being trained for a functional group will result in a higher training accuracy because the model trains on the same spectra more frequently. This model memorizes or overfits functional groups resulting in a model incapable of extrapolating to new spectra.
每个官能团在光谱中出现的实例数量差异很大,其中含芳烃的光谱出现的频率最高,有3467幅。相比之下,酰基卤化物有85张光谱用于训练和测试模型。我们探讨了图像数量与训练和测试结果的交叉熵和准确性之间的关系(图4)。训练精度随着光谱数量的增加而降低(表3)。然而,通过评估未知光谱的官能团识别所确定的最终准确度与用于训练的图像数量没有关系。我们的结果表明,训练光谱的总数并不影响模型的最终性能。图4a,b中表现出的分散的、不均匀的现象描述了光谱数量与验证的准确性和交叉熵之间的线性关系的偏差,证实了图像的数量不影响模型的性能。训练精度提供了对模型学习官能团模型的训练图像的洞察力。反过来说,为一个官能团训练的光谱少会导致更高的训练准确率,因为模型在相同的光谱上训练的频率更高。这种模型会记忆或过度适应官能团,导致模型无法推断到新的光谱上。
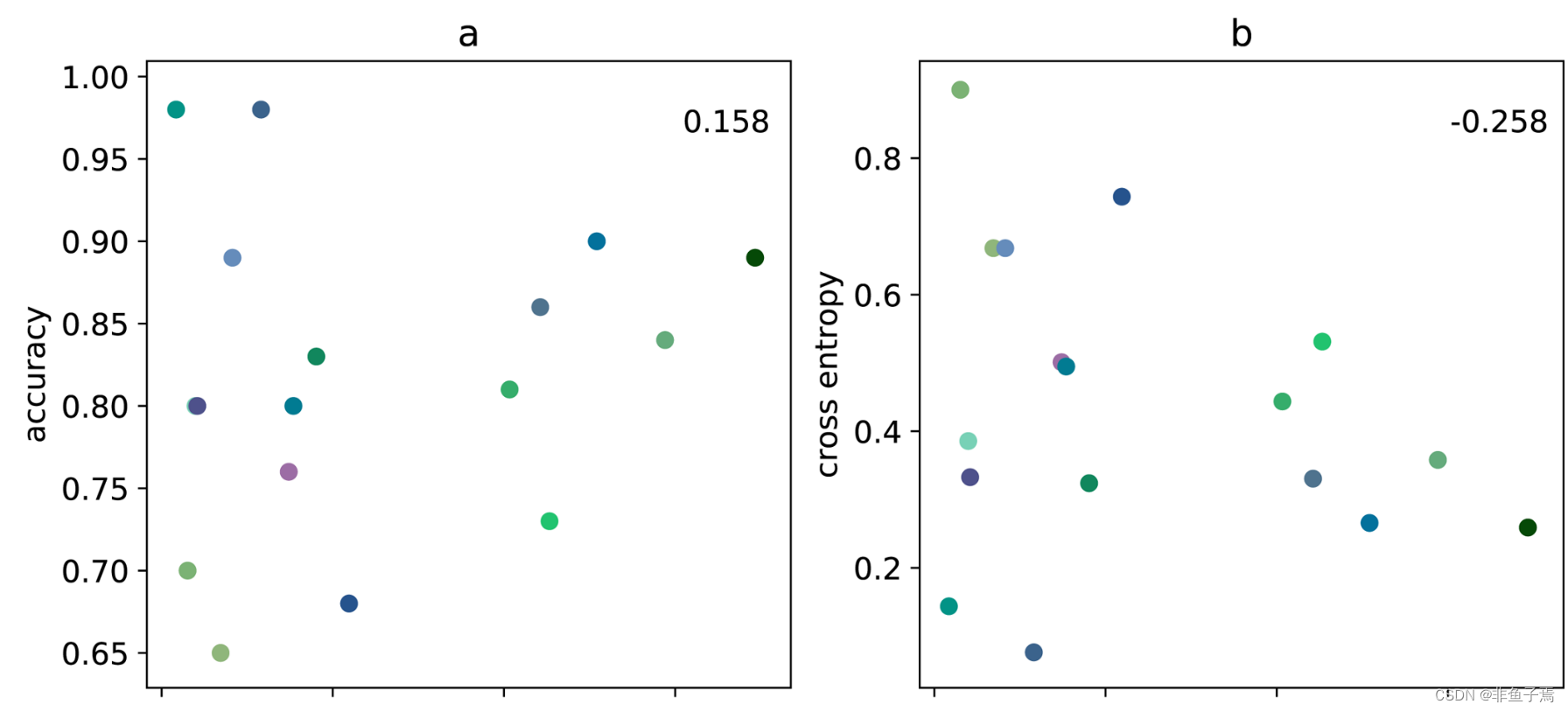

However, from our results, the challenges of limited training spectra do not result in less accurate models. We confirmed this by investigating the relationship of the number of images per class as a function of validation accuracy and cross entropy (Table 2). Models that have more spectra to train on have lower overall training accuracy but still perform well when analyzing unknown spectra. To investigate the linear correlation between the number of spectra used for training and the final accuracy and cross entropy, the Pearson’s correlation coefficient is used (Figure 3). More linearly correlated relationships have a coefficient closer to one, where positive coefficients indicate a positive correlation and negative coefficients indicate a negative correlation. The coefficient for training accuracy and number of training spectra indicates that they are indirectly correlated, whereas the coefficient for training cross entropy and number of training spectra is positive or positively correlated. However, the models with less training spectra show no correlation between the final accuracy and ability to classify unknown spectra. Furthermore, both validation accuracy and cross entropy do not have significant linear correlation. While training results display correlation with the number of images, the validation data indicates that models are successful with a range of number of training spectra.
然而,从我们的结果来看,有限的训练光谱的挑战并没有导致更准确的模型。我们通过调查每类图像的数量与验证准确性和交叉熵的关系来证实这一点(表2)。有更多光谱可供训练的模型,其总体训练精度较低,但在分析未知光谱时仍表现良好。为了研究用于训练的光谱数量与最终准确率和交叉熵之间的线性相关关系,采用了皮尔逊相关系数(图3)。更为线性相关的关系,其系数更接近于1,正系数表示正相关,负系数表示负相关。训练精度和训练光谱数量的系数表明它们是间接相关的,而训练交叉熵和训练光谱数量的系数是正的或正相关的。然而,训练谱系较少的模型显示最终准确度和未知谱系的分类能力之间没有相关性。此外,验证准确率和交叉熵都没有明显的线性相关关系。虽然训练结果显示与图像数量相关,但验证数据表明,模型在一定范围的训练光谱数量下是成功的。
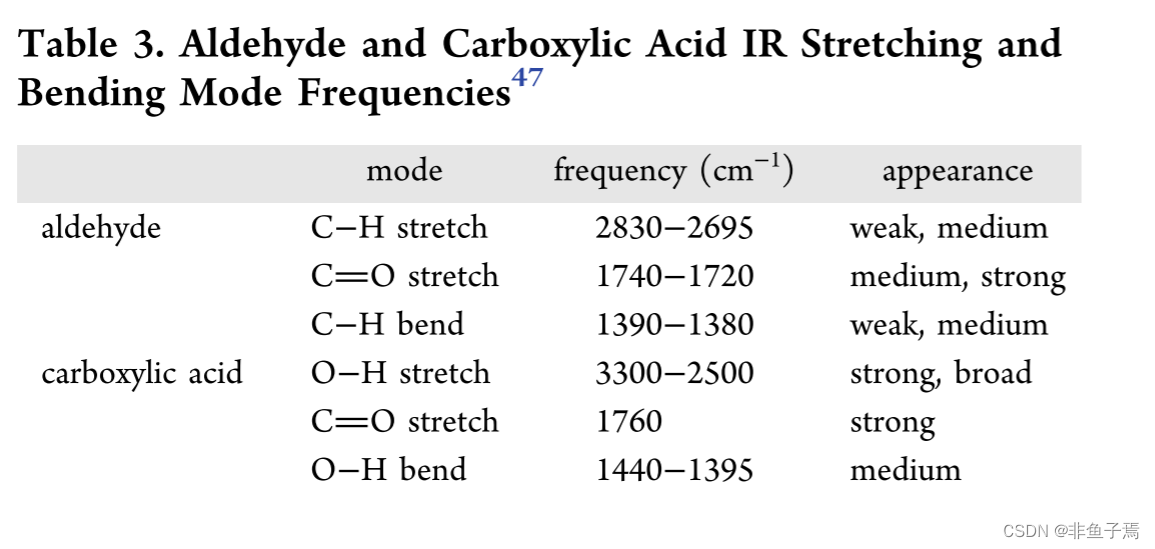
We can determine some of the underlying shortcomings in the model, from both spectroscopic and computational perspectives, by investigating two functional groups: aldehyde and carboxylic acid. The model results for aldehyde are promising for the training data but do not perform as effectively in validation and testing. The confusion matrix for carboxylic acid describes how well the model performs on spectra that have not been used for training or validation. We observe that the IR mode frequencies for the carboxylic acid and aldehyde affect the performance of the model, in addition to the number of spectral examples available for training and validation.
我们可以通过调查两个官能团:醛和羧酸,从光谱和计算的角度来确定模型的一些潜在缺陷。醛的模型结果对训练数据来说是有希望的,但在验证和测试中的表现并不理想。羧酸的混淆矩阵描述了该模型在未用于训练或验证的光谱上的表现如何。我们观察到,除了可用于训练和验证的光谱例子的数量外,羧酸和醛的红外模式频率也会影响模型的性能。
Aldehyde C−H stretching frequency (2830−2695)is commonly overlapping in organic spectra with other C−H bonds because it is a weaker mode (Table 3). The carbonyl stretch is also frequently unresolved in compounds that contain multiple oxygen atoms. The C−H bending mode is often weak, in addition to being in the fingerprint region, which is a challenge to interpret due to the complexity. With these stretching and bending modes considered, it is reasonable to anticipate that an aldehyde functional group is challenging for the model to identify in spectra. In comparison, the carboxylic acid functional groups are always correctly identified in spectra by the model. The model for carboxylic acids is well trained. As observed by the validation accuracy and cross entropy (Table 2), the carboxylic acid model has a more robust transferability to spectra it has never observed. We confirm the effectiveness of the model with a correct assignment of unknown spectra. In totality, there are more carboxylic acid training spectra, and the IR modes are better resolved, especially the strong COO−H stretching, in comparison to aldehydes (Table 3).
醛的C-H拉伸频率(2830-2695 )在有机光谱中通常与其他C-H键重叠,因为它是一个较弱的模式(表3)。在含有多个氧原子的化合物中,羰基伸展也经常无法解析。C-H弯曲模式通常很弱,此外还处于指纹区,由于其复杂性,解释起来是一个挑战。考虑到这些拉伸和弯曲模式,可以合理地预计,醛官能团对于模型在光谱中的识别是具有挑战性的。相比之下,羧酸官能团总是被模型在光谱中正确识别。羧酸的模型是训练有素的。正如验证准确率和交叉熵(表2)所观察到的,羧酸模型对它从未观察过的光谱有更强的转移性。我们通过对未知光谱的正确分配来证实该模型的有效性。总的来说,有更多的羧酸训练光谱,与醛类相比,红外模式得到了更好的解析,特别是强的COO-H拉伸(表3)。
We do not specifically probe the temperature and pressure dependences of model success. However, we hypothesize that the models would perform at high accuracy because pressure effects have been shown to have minimal effect on IR response. In general, the IR transition moment strength for hydrocarbon bonds decreases with increasing temperature and this may affect model accuracy.
我们没有具体探究模型成功与否的温度和压力关系。然而,我们假设这些模型会有很高的精度,因为压力效应已被证明对红外响应的影响很小。一般来说,碳氢化合物键的红外转换矩强度随着温度的升高而降低,这可能会影响模型的精度。
From our results, we observe that the models are more accurate for functional groups when there are more training spectra examples for the functional group and IR peaks are well resolved. Albeit this is an intuitive result for a trained spectroscopist with respect to accuracy correlating to peak resolution, yet there is no precedent using a machine learning approach.
从我们的结果中,我们观察到,当有更多的官能团训练谱例和红外峰得到很好的解决时,模型对官能团的准确性更高。尽管对于一个训练有素的光谱学家来说,这是一个与峰值分辨率相关的准确性的直观结果,但在使用机器学习方法方面还没有先例。
结论
We present a novel method for FTIR spectral interpretation using CNNs and the NIST database. Fifteen functional group models successfully and effectively classify unknown spectra in a facile method for spectral submission to interpretation. We find that the image recognition features inherent in CNNs are transferable to a chemical-identification application. From our observations, we can conclude that CNNs are effective at identifying spectral features for classification and generalizable models are achievable with ample spectral examples. In future work, optimization for functional group identification with less spectral examples should be investigated to improve accuracy. Further investigation of the models could include determining the ability of the model to predict binary and higher-order mixture compositions as well as shifts along the frequency axis.
我们提出了一种使用CNN和NIST数据库进行FTIR光谱解释的新方法。15个官能团模型在一个简单的光谱提交解释方法中成功有效地对未知光谱进行分类。我们发现,CNN固有的图像识别功能可以转移到化学鉴定应用中。从我们的观察中,我们可以得出结论,CNN在识别光谱特征进行分类方面是有效的,并且在有大量光谱实例的情况下可以实现可推广的模型。在未来的工作中,应研究在光谱实例较少的情况下对官能团识别进行优化,以提高准确性。对模型的进一步调查可以包括确定模型预测二元和高阶混合物组成的能力,以及沿频率轴的移动。

声明:上述内容不进行任何商业用途,如有影响,请联系作者。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)