先上一张最终结果的图吧:

感觉AtCoder的ABC还是比较练手的,考验代码速度,网速,D题还会有一些思维难度。
这次ABC由于网络原因,很迟才看到题,但完成得还是不错的。
题解:
A
题意:给你三个都需要被完成的任务的难度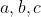 ,均为1至100的正整数。
,均为1至100的正整数。
首先,你可以用0的花费完成任何一个任务。
如果你完成了一个任务,那么你可以完成另一个任务,花费是两个任务的难度的差的绝对值。
题解:利用绝对值的几何意义可以发现,最优解一定是选择难度在中间的那个任务完成,然后再完成另外两个任务。
那么最终的花费一定是难度最大的任务的难度减去难度最小的任务的难度。
代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a,b,c;
cin >> a >> b >> c;
cout << max(max(a,b),c)-min(min(a,b),c) << endl;
}
B
题意:给你字符串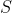 和
和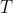 ,每次可以对串进行一种操作:将串的最后一个字符取出,扔到最前面去。
,每次可以对串进行一种操作:将串的最后一个字符取出,扔到最前面去。
问是否能将串变为串。
串和串的长度均小于或等于100且相等。
题解:显然暴力执行操作,暴力判断。
代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
string s,t;
cin >> s >> t;
for(int i=0;i<s.length();++i)
{
char c=s[s.length()-1];
string tmp=s;
s.pop_back();
s.insert(s.begin(),c);
if(s==t)
{
puts("Yes");
return 0;
}
}
puts("No");
}
C
题意:给你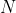 个正整数
个正整数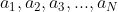 ,我们定义
,我们定义

其中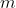 为自然数。
为自然数。
求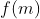 的最大值。
的最大值。
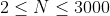 ,
,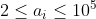
题解:首先这道题求的是最大值(最小值显然为0),容易想到暴力枚举,但显然会超时。
细心的读者也许发现了,我C题的通过时间比B题早将近7分钟,原因竟然是:
当我码着B题,想着C题的时候,隔壁一名大佬(STO yeh)突然说了声最小公倍数。
我一想,取所有数的最小公倍数减一,那么。。。。。
那么C题比B题好码多了,于是码了C,于是C题便比B早提交。。。别问我为什么还过了7分钟才交B
证明:这个不需要证明吧。。。。
代码:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n,x,sum=0;
scanf("%d",&n);
for(int i=1;i<=n;++i)
{
scanf("%d",&x);
sum+=x-1;
}
printf("%d\n",sum);
}
的确比B好码得多啊。。。。
D
没错又是一道有思维难度的题目(大佬除外)。
题意:给你一条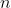 个点的链,点按顺序标号为
个点的链,点按顺序标号为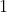 至,然后输入一些点对,让你删边,使得这些点对都不连通,求最少删边数量。
至,然后输入一些点对,让你删边,使得这些点对都不连通,求最少删边数量。
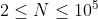 ,
,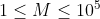 ,
,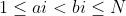
题解:在这道题上卡了很久。
其实不应该卡那么久,因为曾经做过这道题的树上版本,但由于那道题是删点,所以一开始以为不适用,但是后来想了一想,其实可以套用。
方法就是:将所有区间按照右端点的大小排序(从小到大),然后对于一个区间,若它当前未被切断,则切断它最右的一条边。
证明:用类似归纳法的思想,对于右端点最小(最左)的区间,它一定要被切断,为了“惠及”尽可能多的区间,切断它最右的一条边。为什么最优呢,因为这是它已经是右端点最左的区间了,因此只有切断最右的那条边,才能切断最多的区间。
于是我们排除掉已经被切断的区间,再次找到右端点最小的未被切断的区间,由于前面的决策是最优的(已证明),我们可以忽略掉那些区间。此时,切断该区间最右的边一定是最优的,证法同上。
拓展:关于树上的做法(那道题是删点),将所有点对的lca按照深度排序,从深度大的点往深度小的点删,证法类似,不详细展开,有兴趣的读者可以自行查阅资料。
代码:
#include <bits/stdc++.h>
using namespace std;
#define MAXN 100001
struct data{
int a,b;
bool operator<(const data &d)const{
return b<d.b;
}
}a[MAXN];
int n,m;
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;++i)
{
scanf("%d%d",&a[i].a,&a[i].b);
}
sort(a+1,a+m+1);
int now=0,ans=0;
for(int i=1;i<=m;++i)
{
if(now<=a[i].a)
{
now=a[i].b;
++ans;
}
}
printf("%d\n",ans);
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)