postgresql主从复制是一种高可用解决方案,可以实现读写分离。postgresql主从复制是基于xlog来实现的,主库开启日志功能,从库根据主库xlog来完成数据的同步。
主从复需要注意的地方:
- 启动从库之前,不能执行初始化。
- 启动从库之前,需要通过base_backup从主服务器上同步配置与数据。
- 启动从库之前,需要对同步之后的配置文件进行修改。
- 启动从库之前,需要设置一个恢复的配置文件。
- 从库只能读,不能写。
下面介绍主从复制的实现,这里以两台虚拟机为例,主节点IP是192.168.56.201,从节点IP是192.168.56.202,这里两台机器都是通过源码编译安装的方式安装的postgresql,版本是11.4。编译安装指定的前缀是/usr/local,因此安装完成,可执行程序会在/usr/local/bin目录下。
首先需要在主库上初始化数据库,并启动数据库服务。
启动的时候,不能以root用户来启动。

编译安装不会创建postgres用户,因此我们需要先创建postgres用户和用户组。 我们会将postgresql数据存储路径设置在/home/postgres/data下。
groupadd postgres
useradd -g postgres postgres
切换用户,然后初始化数据库。

初始化成功之后,会有个提示,如何启动数据库,按照提示命令,我们启动数据库。
/usr/local/bin/pg_ctl -D /home/postgres/data -l logfile start

这里启动数据库之后,我们登陆数据库,做两件事情:准备一些数据,将来从节点同步之后,用来做数据验证。创建一个admin/123456的用户,用来做主从复制。

这样在主库上的操作就完成了,接下来就是修改配置文件,然后重启主库。
修改pg_hba.conf,增加刚才创建的用户到文件末尾,method指定为md5,表示密码开启md5验证。

修改postgresql.conf,开启注释,并修改以下配置:
listen_addresses="*"
wal_level=hot_standby
max_wal_senders=2
wal_keep_segments=64
max_connections=100
重启主库,至此,完成主库的所有准备工作:

/\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
下面就是配置和启动从库了,前面注意事项里面提到,不能初始化从库,因为我们需要首先从主库备份数据,备份之后,从库的/home/postgres/data里面的数据和配置信息就和主库一致了。
首先从库也需要postgres/postgres用户组和用户,先创建:
groupadd postgres
useradd -g postgres postgres
之后,切换到postgres用户,进行数据备份和启动操作。
首先是利用base_backup命令进行备份:
/usr/local/bin/pg_basebackup -h 192.168.56.201 -p 5432 -U admin -F p -P -D /home/postgres/data

因为是从库访问,而且是用的admin用户,因此需要输入密码。这里显示备份成功。
因为配置postgresql.conf是从主库同步过来的,这里需要修改一些配置,改为从库的配置:
#wal_level=hot_standby #从库不需要这个配置
#max_wal_senders=2 #同上
#wal_keep_segments=64 #同上
hot_standby=on #开启hot_standby模式
max_standby_streaming_delay=30s #可选,流复制最大延迟
wal_receiver_status_interval=10s #可选,向主库报告状态的最大间隔时间
hot_standby_feedback=on #可选,查询冲突时向主库反馈
max_connections=1000 #最大连接数一般大于主库就行
还需要准备一个恢复配置文件,这个文件在安装postgresql时,会生成到/usr/local/share/postgresql目录下,名字是recovery.conf.sample。我们复制并修改名称为recovery.conf并放置在/home/postgres/data目录下,修改配置:
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=192.168.56.201 port=5432 user=admin password=123456'
这三个配置很直观,recovery_target_timeline='latest'表示恢复最新的数据,standby_mode表示从节点的角色是备选,primay_conninfo表示主库连接信息。
至此,从库的配置工作准备完成,接着就可以启动数据库了。

\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
主从复制到此就配置完成了,接下来就是验证阶段:
1、从主从机器运行的进程验证:
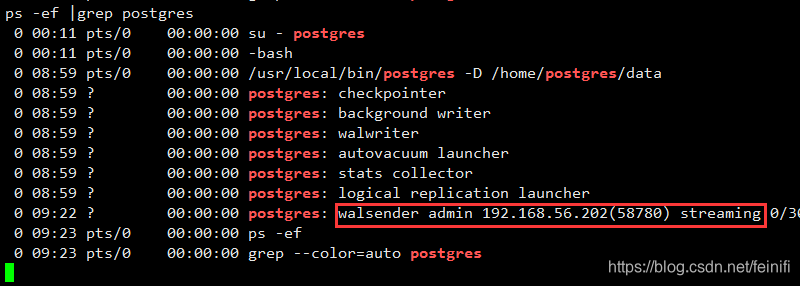
主节点服务器会增加一个walsender进程

从节点服务器增加一个walreceiver进程
2、从数据上验证:

主库在首次启动的时候,没有做主从配置之前,就插入了4条记录在test数据库xx_user表中。如今再次插入一条数据,也显示成功,查询会显示5条记录。

从库在首次启动之后,数据是从主库备份过来的,第一次进入查找就有4条记录。等主库插入一条记录之后,再次查看是5条记录,从库数据均同步成功,表示主从复制配置正确。
最后我们在从库中做插入操作,显示操作失败,因为从库是只读的,不能做增删改的写操作,只能查询。
3、这里可以从/usr/local/bin/pg_controldata /home/postgres/data命令的结果状态中可以验证,主从关系,主库的集群状态是in production,从库是in archive recovery,当我们的主库崩溃,我们可以切换从库为主库。这时候主库状态是shut down,而从库是in production。这里我们模拟停掉主库。
pg_ctl stop -m fast
马上在从库上切换从库为主库:
pg_ctl promote
这里显示了从库的状态由in archive recovery 变为in production的截图:
正常从库的状态:

主库shutdown,从库执行切换主库操作之后:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)