概率分布描述了事件或实验所有可能结果的可能性。这正态分布是最有用的概率分布之一,因为它很好地模拟了许多自然现象。使用 NumPy,您可以根据正态分布创建随机数样本。
这种分布也称为高斯分布或者简单地钟形曲线。后者暗示了绘制分布时的形状:
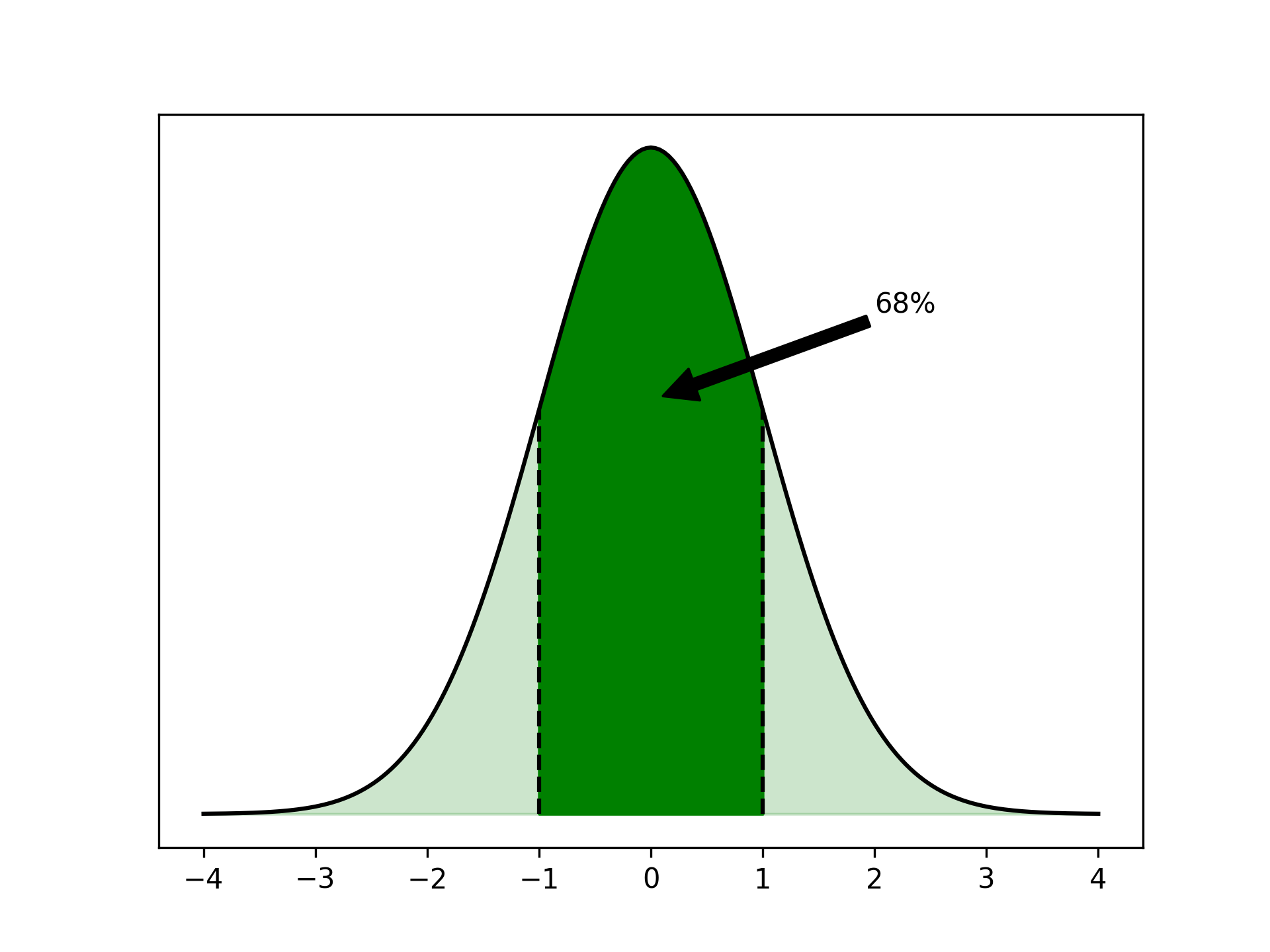
正态分布围绕其峰值对称。由于这种对称性,分布的平均值通常表示为μ,正处于那个峰值。标准差,σ,描述了分布的分散程度。
如果某些样本呈正态分布,则随机样本的值很可能接近平均值。实际上,约 68%所有样本的平均值均在一个标准差之内。
您可以将图中曲线下的面积解释为概率的度量。深色区域代表与平均值小于 1 个标准差的所有样本,占曲线下全部面积的 68%。
在本教程中,您将学习如何使用 Python数值模拟处理正态分布的库,特别是如何创建正态分布的随机数。在此过程中,您将了解 NumPy随机数生成器 (RNG)以及如何确保您可以以可重复的方式处理随机性。
您还将了解如何使用以下方法可视化概率分布Matplotlib和直方图,以及操纵平均值和标准差的效果。这中心极限定理解释了正态分布的重要性。它描述了任何重复实验或测量的平均值如何近似正态分布。
正如您将了解到的,您可以使用正确的 Python 代码进行一些强大的统计分析。要获取本教程的代码,请单击下面的链接:
免费奖金: 单击此处下载免费示例代码您将使用它在 NumPy 中根据正态分布生成随机数。
要继续操作,您需要安装一些软件包。首先,创建并激活虚拟环境。然后运行以下命令pip命令:
$ python -m pip install numpy matplotlib scipy
除了获取 NumPy 之外,您还安装了 Matplotlib 和 SciPy,因此您可以开始使用了。
如何使用 NumPy 生成正态分布的随机数
NumPy 包含一个完整的子包,numpy.随机数,致力于与随机数。由于历史原因,这个包包含了很多功能。但是,您通常应该从实例化默认随机数生成器 (RNG) 开始:
>>>>>> import numpy as np
>>> rng = np.random.default_rng()
>>> rng
Generator(PCG64) at 0x7F00828DD8C0
RNG 可以从许多不同的分布中生成随机数。要从正态分布中采样,您将使用.normal():
>>>>>> rng.normal()
0.7630063999485851
>>> rng.normal()
0.46664545470659285
>>> rng.normal()
0.18800887515990947
虽然这些数字看起来是随机的,不管什么意思,很难确认一个或几个数字是从给定的分布中抽取的。您可以要求 NumPy 一次绘制多个数字:
>>>>>> numbers = rng.normal(size=10_000)
>>> numbers.mean()
0.004567244040854705
>>> numbers.std()
1.0058207076330512
在这里,您生成一万个正态分布数字。如果您不指定任何其他参数,那么 NumPy 将创建所谓的标准正态分布数那些以μ= 0 并且有标准差σ= 1. 您确认您的数字的平均值大约为零。您还使用.std()检查标准差是否接近于 1。
NumPy 可以处理多维数字数组。您可以指定size用一个元组创造N维数组:
>>>>>> rng.normal(size=(2, 4))
array([[ 0.44284801, -0.5197292 , 0.36472606, -0.21618958],
[-0.45235572, 0.04395177, -0.09295108, -0.70332948]])
在本例中,您创建了一个包含两行和四列的正态分布随机数的二维数组。如果您正在对重复实验进行建模,那么在多个维度上组织随机数据可能会很有用。你会看到一个实际的例子之后.
绘制正态分布数字
当您进行建模时,查看单一结果通常并不那么有趣。相反,您想要查看许多样本并尝试了解它们的分布。对于此类概述,通过绘制数字直方图来可视化分布非常有效。
对于第一个示例,请使用您在上面创建的数字:
>>>>>> import numpy as np
>>> rng = np.random.default_rng()
>>> numbers = rng.normal(size=10_000)
您可以在直方图中绘制一万个数字:
>>>>>> import matplotlib.pyplot as plt
>>> plt.hist(numbers)
>>> plt.show()
跑步plt.show()将在单独的窗口中显示直方图。它看起来像这样:
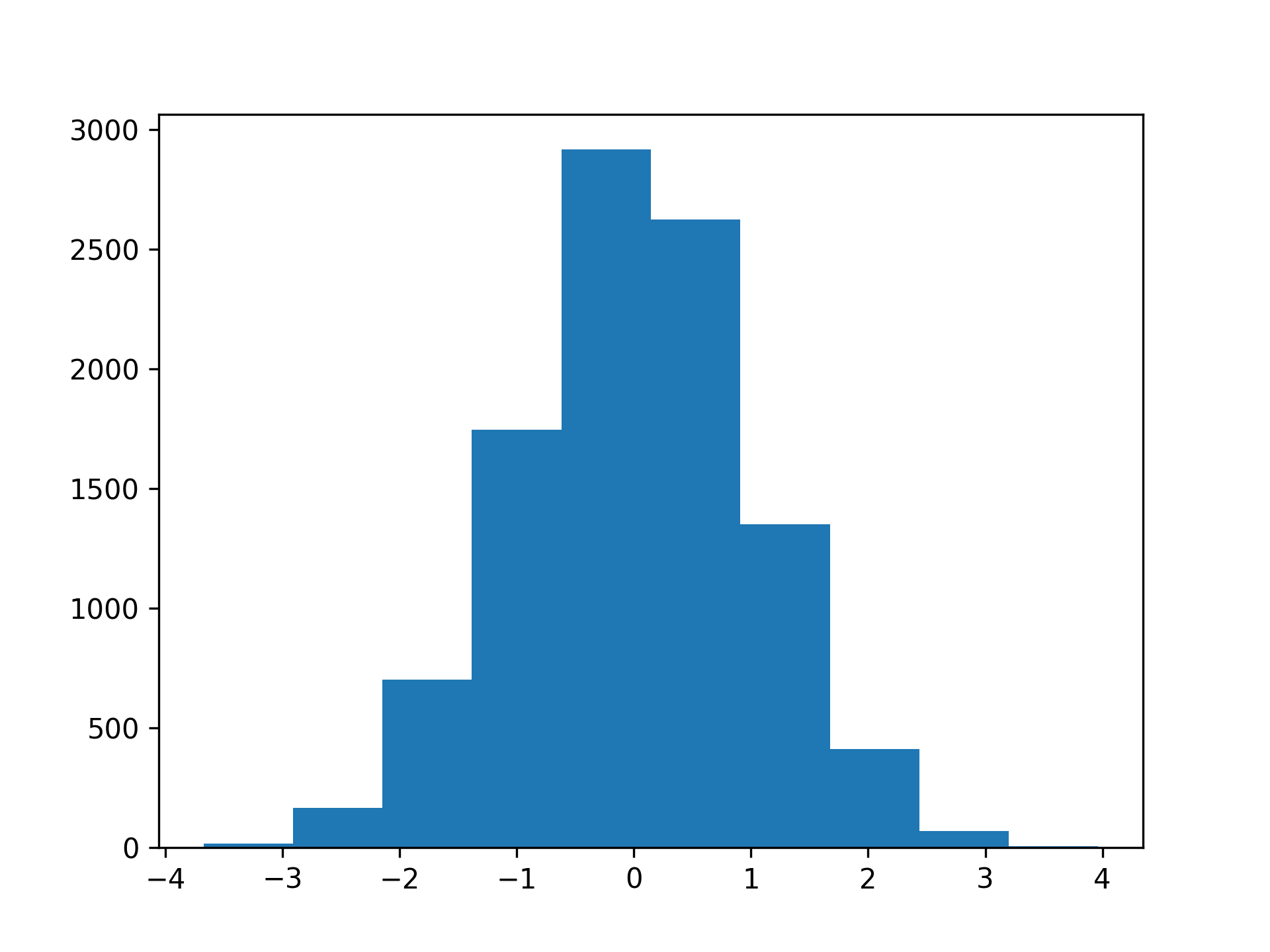
在直方图中,您的值以所谓的方式分组在一起垃圾箱。在上面,您可以数一下蓝色条,看看直方图有 10 个箱。请注意,最外面的条形很小并且很难发现。
直方图的垂直轴显示有多少样本落入每个箱中。直方图的形状显示了与正态分布相关的一些特征。它是对称的,有一个明确定义的峰,并向两侧逐渐变细。
根据数据集中的样本数量,您可能需要增加可视化中的箱数。您可以通过指定来做到这一点bins:
>>>>>> plt.hist(numbers, bins=100)
>>> plt.show()
通过将 bin 数量增加到 100,您将获得更平滑的直方图:
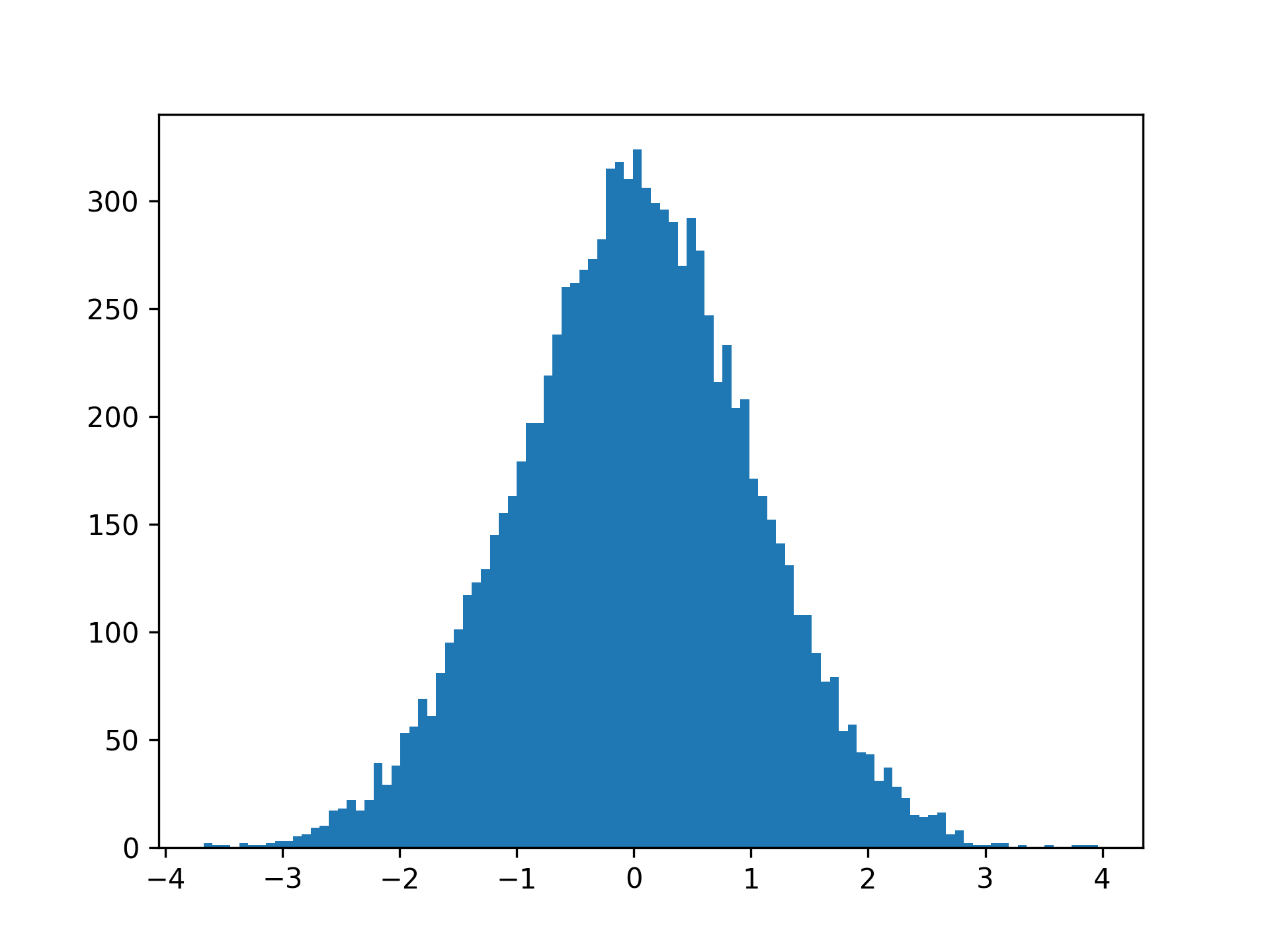
您选择的箱数可能会稍微改变直方图的外观,因此您在探索数据时应该尝试一些不同的选择。
请注意,当您有更多的垃圾箱时,每个垃圾箱中的值就会更少。这意味着您的绝对数字y-axis 很少有趣。它们将根据观察数量和箱数进行扩展。例如,您可以看到第一个图中的计数大约比第二个图中的计数高十倍,而第二个图中您使用的垃圾箱数量是第二个图中的十倍。
您可以通过将观测值数量乘以箱的宽度来计算直方图的面积。单个 bin 的宽度取决于最小值和最大值观察值和箱数。对于包含 100 个 bin 的直方图,您将得到以下结果:
>>>>>> bins = 100
>>> bin_width = (numbers.max() - numbers.min()) / bins
>>> hist_area = len(numbers) * bin_width
>>> hist_area
763.8533882079863
同样,这个值本身通常并不是很有趣。但是,如果您想将直方图与理论正态分布进行比较,它可能会很有用。
这SciPy 库包含几个名为pdf()。这些都是概率密度函数。您可以使用它们来绘制理论概率分布:
>>>>>> import scipy.stats
>>> x = np.linspace(-4, 4, 101)
>>> plt.plot(x, scipy.stats.norm.pdf(x))
>>> plt.show()
在这里,你使用scipy.stats.norm.pdf()计算值的正态分布x介于 -4 和 4 之间。这将创建以下绘图:
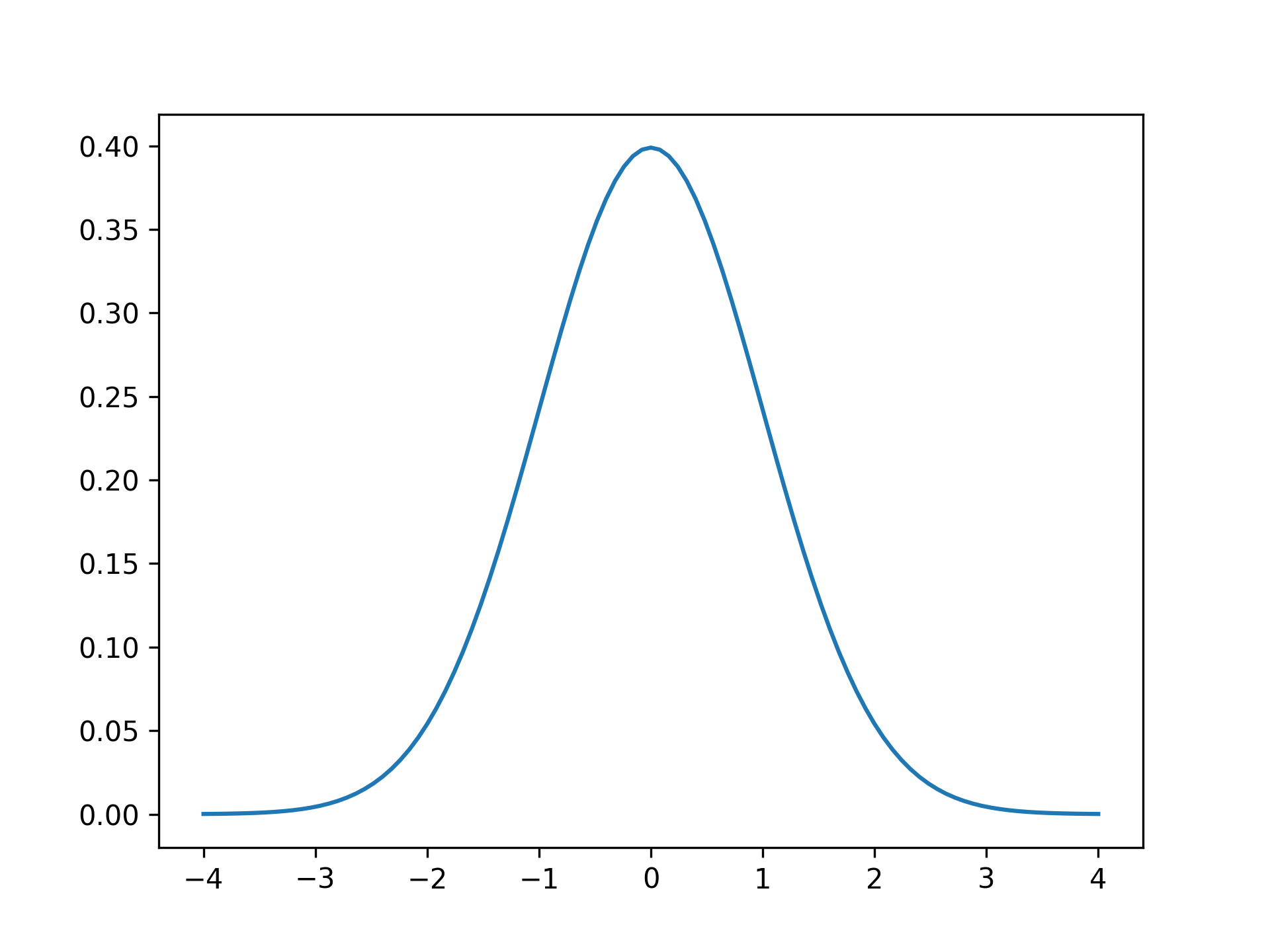
您可以识别具有单个峰值的对称曲线。根据定义,概率密度函数曲线下的面积为一。因此,如果您想将观测值直方图与理论曲线进行比较,那么您需要对后者进行缩放:
>>>>>> x = np.linspace(numbers.min(), numbers.max(), 101)
>>> plt.hist(numbers, bins=100)
>>> plt.plot(x, scipy.stats.norm.pdf(x) * hist_area)
>>> plt.show()
在这里,您可以通过之前计算的直方图面积来缩放概率密度函数。生成的图显示了叠加在直方图顶部的正态分布:
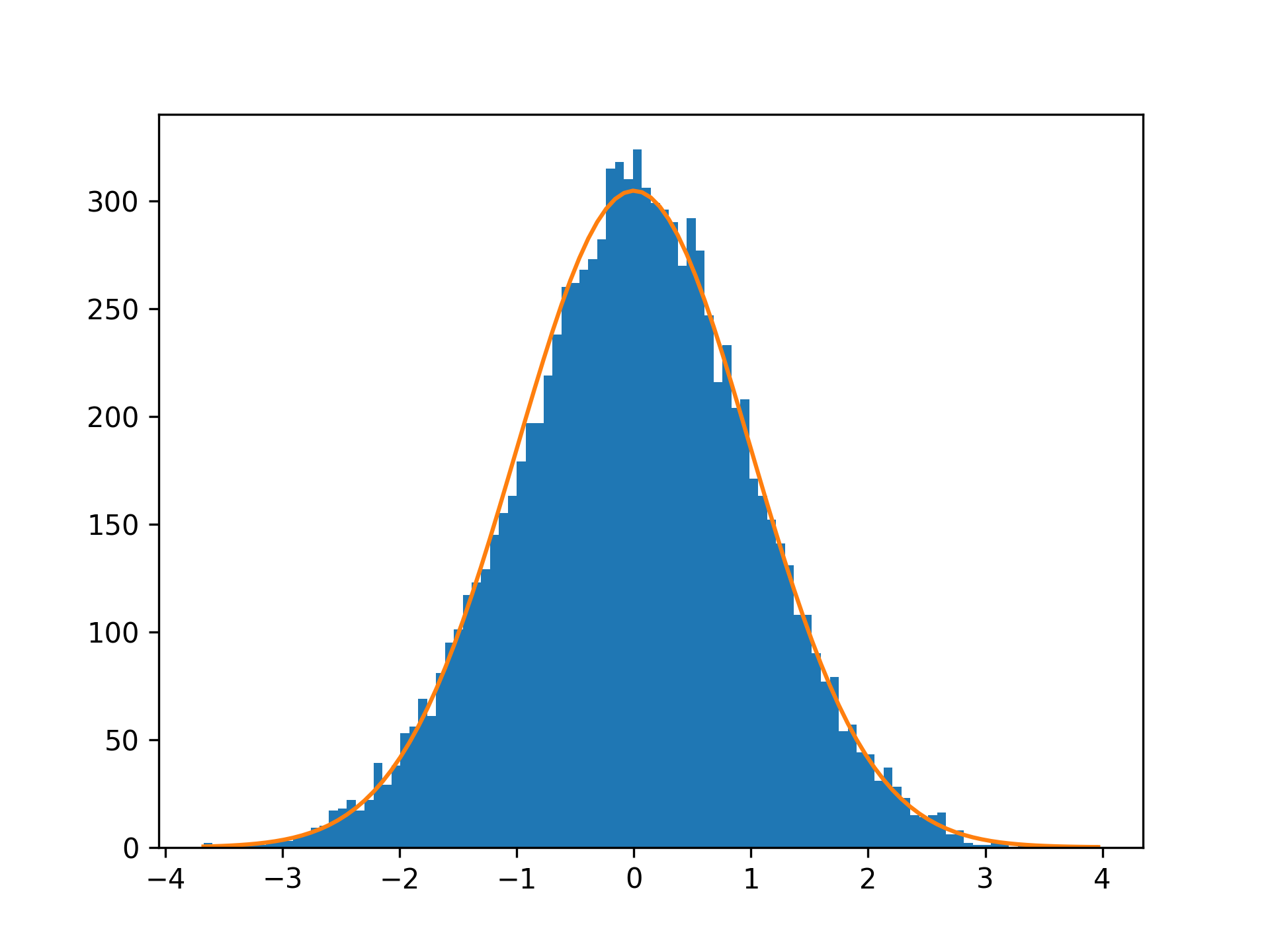
通过目视检查,您可以看到随机数据很好地遵循正态分布。
到目前为止,您已经了解了如何在 NumPy 中使用正态分布。在接下来的部分中,您将详细了解正态分布如何以及为何有用。
指定平均值和标准差
有很多例子自然发生的正态分布数据,包括出生体重、成年身高和鞋码。假设您想要为一台包装小麦袋的机器建模。通过观察和测量,你知道每袋小麦的重量呈正态分布,平均值为μ= 1023 克,标准偏差为σ= 19 克。
之前,您已经看到过以μ= 0。但是,您可以用任何均值定义正态分布,μ,以及任何正标准差,σ。在 NumPy 中,您可以通过指定两个参数来完成此操作:
>>>>>> import numpy as np
>>> rng = np.random.default_rng()
>>> weights = rng.normal(1023, 19, size=5_000)
>>> weights[:3]
array([1037.4971216 , 1031.86626364, 1026.57216863])
与之前相比,现在您的随机值大多略高于 1000。您可以计算观测值的平均值和标准差:
>>>>>> weights.mean()
1023.3071473510166
>>> weights.std()
19.25233332725017
同样,随机数的特征与其理论值接近,但并不完全相等。您可以绘制数据:
>>>>>> import matplotlib.pyplot as plt
>>> plt.hist(weights, bins=50)
>>> plt.show()
这些命令生成如下图:
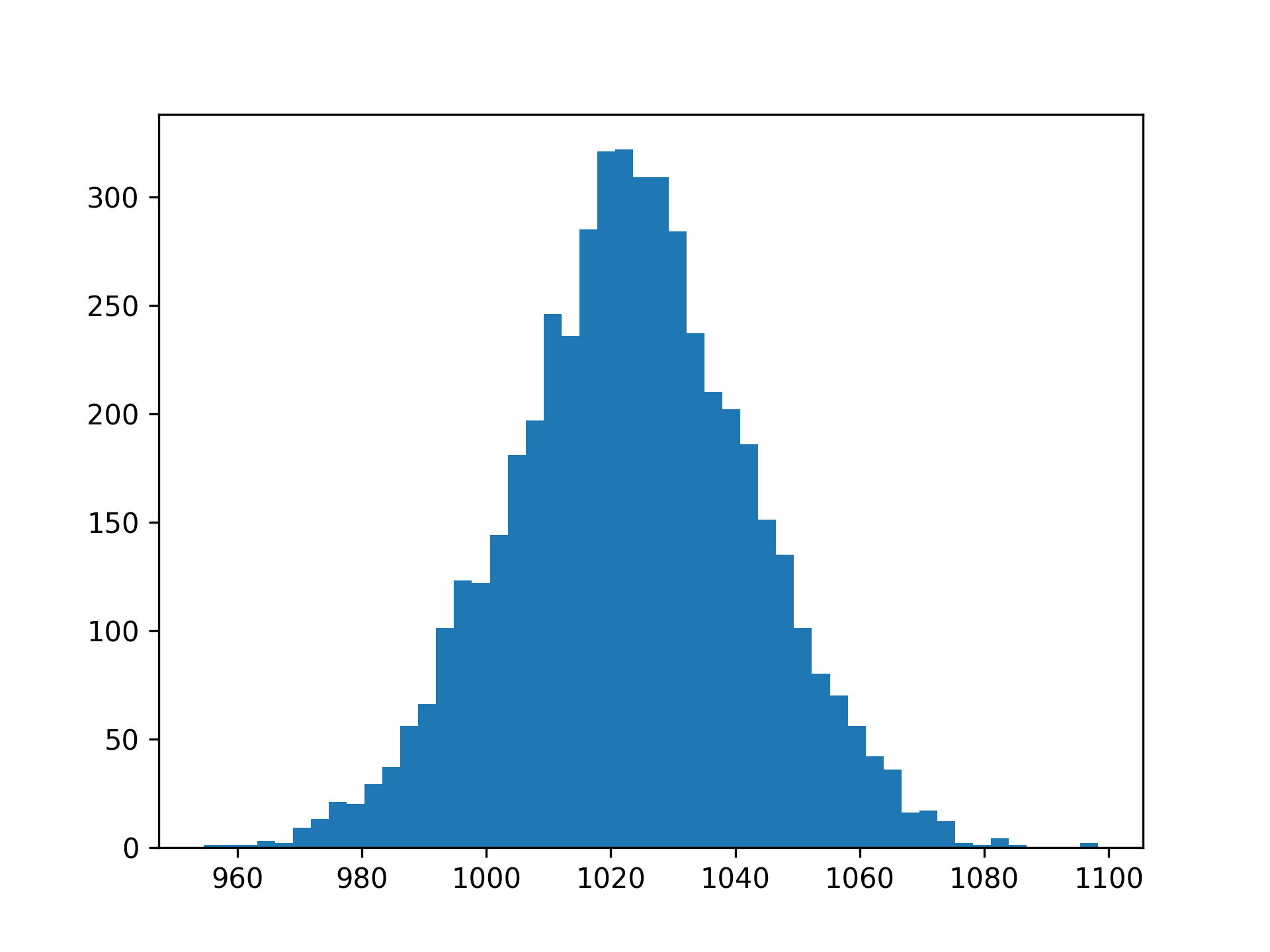
当您认识到直方图的形状时,请注意x- 轴发生移动,以便大多数值都高于 1000。实际上,您可以使用 NumPy 来计算低于 1000 克的观测值的比率:
>>>>>> np.mean(weights < 1000)
0.117
NumPy 计算布尔表达式,例如weights < 1000元素方面。结果是一个数组True和False值取决于每袋小麦的重量。因为True和False可以解释为1和0,分别可以使用mean()计算比率True价值观。
在上面的示例中,您会看到 11.7% 的袋子的测量重量小于 1000 克。您还可以通过查看绘图来估计类似的数字。左边曲线下的面积x=1000代表较轻的麦袋。
您已经看到可以生成具有给定平均值和标准差的正态数字。在下一节中,您将更仔细地了解 NumPy 的随机数生成器。
在 NumPy 中使用随机数
在计算机等确定性系统中创建随机数并非易事。大多数随机数生成器不会产生真正的随机性。相反,它们通过确定性和可再现的过程生成数字,使数字看起来是随机的。
一般来说,随机数生成器(或更准确地说,伪随机数生成器 (PRNG))是一种从已知的种子并从中生成一个伪随机数。这种生成器的优点之一是您可以重现随机数:
>>>>>> import numpy as np
>>> rng = np.random.default_rng(seed=2310)
>>> rng.normal(size=3)
array([0.7630064 , 0.46664545, 0.18800888])
>>> rng = np.random.default_rng(seed=2310)
>>> rng.normal(size=3)
array([0.7630064 , 0.46664545, 0.18800888])
>>> rng = np.random.default_rng(seed=2801)
>>> rng.normal(size=3)
array([-1.90550297, 0.05608914, -0.29362926])
如果您使用特定种子创建随机数生成器,则稍后可以使用相同的种子重新创建相同的随机数。在此示例中,第二次调用.normal()生成与第一个相同的数字。另一方面,如果您使用不同的种子初始化生成器,那么您会得到不同的随机数。
从历史上看,在 NumPy 中处理随机数时,您没有使用显式随机数生成器。相反,您调用了类似的函数np.random.normal()直接地。然而,numpy 1.17引入了显式随机数生成器,我们鼓励您尽可能使用这种处理随机数的新方法。
新机制的优点之一是更加透明。如果您的程序中的不同位置需要随机数,那么您应该传递随机数生成器。您可以了解有关 NumPy 随机数策略的更多信息新经济政策19,NumPy 增强提案之一。
在最后一部分中,您将返回正态分布并了解更多关于它为何如此普遍的信息。
用中心极限定理迭代至正态性
正态分布在统计学和概率论中起着重要作用。它出现在许多实际例子和许多理论结果中。这中心极限定理可以解释一些根本原因。
这结果表示重复实验的平均值将近似正态分布。实现这一点的一个重要标准是实验具有相同的分布,尽管它们不需要呈正态分布。
举个实际的例子,考虑掷骰子。普通骰子有六个面,在掷骰子时,每种结果(1、2、3、4、5 或 6)的可能性均等。因此,这些卷是均匀分布。然而,重复掷骰子的平均值仍接近正态分布。
您可以使用 NumPy 来演示这一点。首先,生成随机骰子:
>>>>>> import numpy as np
>>> rng = np.random.default_rng(seed=2310)
>>> rng.integers(low=1, high=6, endpoint=True, size=1)
array([6])
你用.integers()并指定您想要对 1 到 6 范围内的整数进行采样(包含 1 和 6)。接下来,您可以使用size模拟重复骰子的分布。首先重复掷骰子两次。为了获得代表性分布,您需要执行一万次这样的重复滚动:
>>>>>> rolls = rng.integers(low=1, high=6, endpoint=True, size=(10_000, 2))
您可以使用.mean()计算两次滚动的平均值,然后绘制直方图以查看分布:
>>>>>> import matplotlib.pyplot as plt
>>> plt.hist(rolls.mean(axis=1), bins=21)
>>> plt.show()
这将产生以下情节:
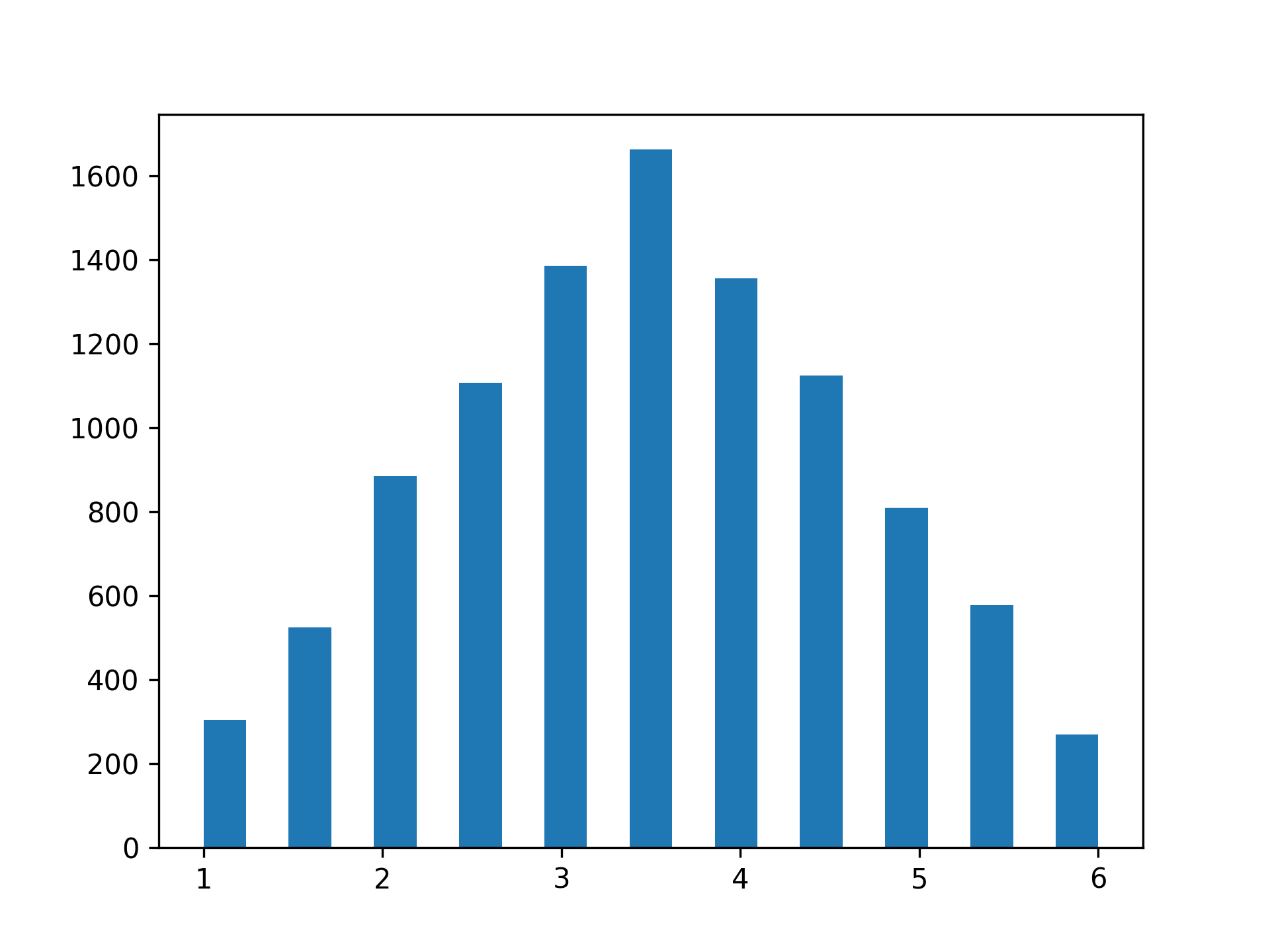
虽然分布接近对称并且具有明显的峰值,但您会注意到形状更像三角形而不是钟形。与此同时,分布不再表现出均匀性,即每种结果的可能性均等。
接下来,尝试用十次重复的骰子进行相同的操作:
>>>>>> rolls = rng.integers(low=1, high=6, endpoint=True, size=(10_000, 10))
>>> plt.hist(rolls.mean(axis=1), bins=41)
>>> plt.show()
现在,分布更加接近熟悉的形状:
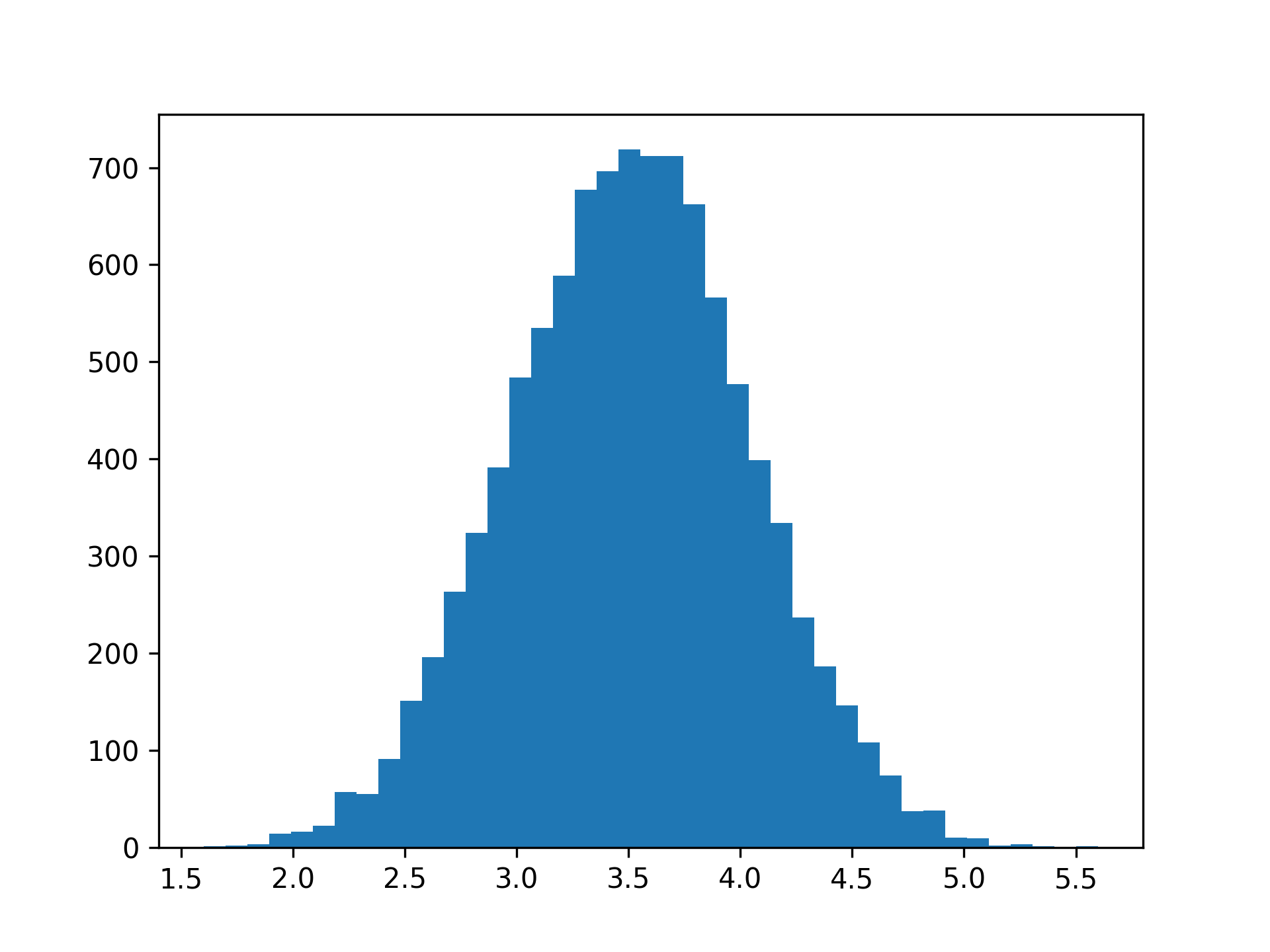
如果增加重复掷骰的次数,您会发现分布将越来越接近正态分布。这说明了中心极限定理:重复实验产生正态性。由于许多自然过程都包含加性效应,因此它们通常很好地遵循正态分布。
结论
在本教程中,您学习了如何在 NumPy 中处理正态分布数据,以及如何在 Matplotlib 中绘制它们。正态分布是最常见的概率分布之一,您已经了解了如何直观地将样本数据的分布与理论正态分布进行比较。
中心极限定理解释了为什么正态分布随处可见的原因之一。重复实验的平均值趋于正态性。
您有正态分布数字的有趣示例吗?在下面的评论中与社区分享。
免费奖金: 单击此处下载免费示例代码您将使用它在 NumPy 中根据正态分布生成随机数。