磁盘配额(Quota)的应用与实作
Quota 的一般用途:
针对 www server ,例如:每个人的网页空间的容量限制;
针对 mail server,例如:每个人的邮件空间限制。
针对 file server,例如:每个人最大的可用网络硬盘空间。
限制某一群组所能使用的最大磁盘配额(使用群组限制);
限制某一用户的最大磁盘配额(使用用户限制);
限制某一目录(directory, project)的最大磁盘配额;
…
基本上,quota就是在回报管理员磁盘使用率以及让管理员管理磁盘使用情况的一个工具。
Quota 的使用限制:
1.在 EXT 文件系统家族仅能针对整个 filesystem:
EXT 文件系统家族在进行 quota 限制的时候,它仅能针对整个文件系统来进行设计,无法针对某个单一的目录来设计它的磁盘配额;
2.核心必须支持quota :
Linux 核心必须有支持quota这个功能才行;
3.只对一般身份使用者有效:
并不是所有在 Linux上面的账号都可以设定 quota ,例如root 就不能设定quota ,因为整个系统所有的数据几乎都是他的。
4.若启用 SELinux,非所有目录均可设定quota :
新版的 CentOS 预设都有启用SELinux这个核心功能,该功能会加强某些细部的权限控制。由于担心管理员不小心设定错误,因此预设的情况下,quota 似乎仅能针对 /home进行设定而已。
不同的文件系统在quota的处理情况上不太相同
Quota 的规范设定项目:
quota 针对XFS filesystem的限制项目主要分为底下几个部分:
1.分别针对用户、群组或个别目录 (user, group & project):
XFS 文件系统的 quota 限制中,主要是针对群组、个人或单独的目录进行磁盘使用率的限制。
2.容量限制或文件数量限制(block或inode):
文件系统主要规划为存放属性的 inode 与实际文件数据的 block 区块,Quota 管理inode或block这两个管理的功能为:
限制inode用量:可以管理使用者可以建立的【文件数量】;
限制block用量:管理用户磁盘容量的限制,较常见为这种方式。
3.柔性劝导与硬性规定(soft/hard):
hard 限制值要比 soft 要高。
hard:表示使用者的用量绝对不会超过这个限制值,若超过这个值则系统会锁住该用户的磁盘使用权;
soft:表示使用者在低于soft限值时,可以正常使用磁盘,但若超过 soft 且低于 hard的限值,每次用户登入系统时,系统会主动发出磁盘即将爆满的警告讯息,且会给予一个宽限时间(grace time)。不过,若使用者在宽限时间倒数期间就将容量再次降低于soft 限值之下,则宽限时间会停止。
4.会倒数计时的宽限时间(grace time):

不要在根目录底下进行quota设计,因为文件系统会变得太复杂。
基本上,针对 quota 限制的项目主要有三项,如下所示:
uquota/usrquota/quota:针对使用者账号的设定
gquota/ grpquota:针对群组的设定
pquota/prjquota:针对单一目录的设定,但是不可与grpquota同时存在。
将quota 的管理数据列出来
xfs_quota -x -c "指令" [挂载点]
 限制值设定方式:
限制值设定方式:
xfs_quota -x -c "limit [-ug] b[soft|hard]=N i[soft|hard]=N name"
xfs_quota -x -c "timer [-ug] [-bir] Ndays"
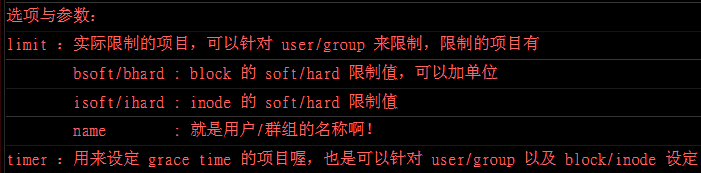
要针对某些目录进行容量的限制:
有了project,不用管在里头建立文件的文件拥有者。
XFS quota 的管理与额外指令对照表
disable:
暂时取消 quota 的限制,但其实系统还是在计算 quota 中,只是没有管制而已。
enable:
就是回复到正常管制的状态中,与 disable 可以互相取消、启用!
off:
完全关闭 quota 的限制,使用了这个状态后,你只有卸除再重新挂载才能够再次的启动 quota。也就是说,用了 off 状态后,无法使用 enable 再次复原 quota 的管制。
remove:
必须要在 off 的状态下才能够执行的指令,这个remove可以【移除】quota 的限制设定,例如要取消project的设定,无须重新设定为 0,只要 remove -p 就可以了。

软件磁盘阵列(Software RAID)
磁盘阵列全名是【Redundant Arrays of lnexpensive Disks, RAID】,英翻中的意思是:容错式廉价磁盘阵列。
RAID可以透过一个技术(软件或硬件),将多个较小的磁盘整合成为一个较大的磁盘装置;而这个较大的磁盘功能可不止是储存而已,他还具有数据保护的功能。
整个 RAID 由于选择的等级(level)不同,而使得整合后的磁盘具有不同的功能,基本常见的 level有这几种:
1.RAID-0(等量模式,stripe):效能最佳
这种模式如果使用相同型号与容量的磁盘来组成时,效果较佳。这种模式的 RAID会将磁盘先切出等量的区块(名为chunk,一般可设定 4K~1M 之间),然后当一个文件要写入 RAID时,该文件会依据 chunk 的大小切割好,之后再依序放到各个磁盘里面去。由于每个磁盘会交错的存放数据,因此当你的数据要写入RAID时,数据会被等量的放置在各个磁盘上面。
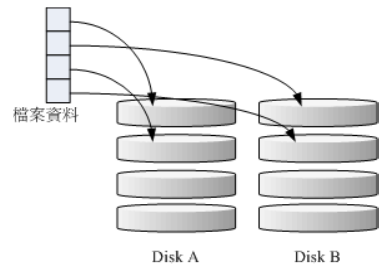
在组成 RAID-0 时,每颗磁盘 (Disk A 与 Disk B) 都会先被区隔成为小区块 (chunk)。当有数据要写入RAID时,资料会先被切割成符合小区块的大小,然后再依序一个一个的放置到不同的磁盘去。由于数据已经先被切割并且依序放置到不同的磁盘上面,因此每颗磁盘所负责的数据量都降低了。
照这样的情况来看,越多颗磁盘组成的 RAID-0 效能会越好,因为每颗负责的资料量就更低了。
这表示资料可以分散让多颗磁盘来储存,当然效能会变的更好。此外,磁盘总容量也变大了,因为每颗磁盘的容量最终会加总成为RAID-O的总容量。
只是使用此等级必须要
自行负担数据损毁
的风险,由上图我们知道文件是被切割成为适合每颗磁盘分区区块的大小,然后再依序放置到各个磁盘中。如果某一颗磁盘损毁了,那么文件数据将缺一块,此时这个文件就损毁了。
由于每个文件都是这样存放的,因此
RAID-0只要有任何一颗磁盘损毁,在 RAID上面的所有数据都会遗失而无法读取。
另外,如果使用不同容量的磁盘来组成RAID-0时,由于数据是一直等量的依序放置到不同磁盘中,当
小容量磁盘的区块被用完了,那么所有的数据都将被写入到最大的那颗磁盘去
,效能会变差,因为最后只剩一颗可以存放数据了。
2.RAID-1(印象模式:mirror):完整备份
这种模式也是需要相同的磁盘容量的,最好是一模一样的磁盘啦。如果是不同容量的磁盘组成
RAID-1 时,那么总容量将以
最小
的那一颗磁盘为主。
这种模式主要是【让同一份数据,完整的保存在两颗磁盘上头】,同步写入两颗磁盘,因此 RAID 的整体容量几乎少了 50%。
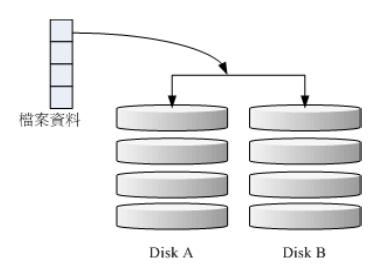
每颗 RAID 1 都是独立的
。由于两颗磁盘内的数据一模一样,所以任何一颗硬盘损毁时,资料还是可以完整的保留下来的。RAID-1 最大的优点大概就在于数据的备份吧!不过由于磁盘容量有一半用在备份,因此总容量会是全部磁盘容量的一半而已。
效能写入不佳,读取还可以
。因为数据有两份在不同的磁盘上面,如果多个 processes 在读取同一笔数据时,RAID 会自行取得最佳的读取平衡。
RAID 1+0,RAID 0+1
所谓的RAID 1+0 就是:(1)先让两颗磁盘组成RAID 1,并且这样的设定共有两组;(2)将这两组RAID 1再组成一组RAID0。反过来说,RAID 0+1就是先组成 RAID-0 再组成 RAID-1 的意思。
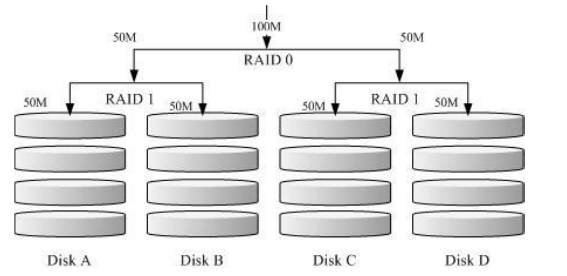
如上图所示,Disk A+ Disk B组成第一组 RAID 1,Disk C + Disk D组成第二组 RAID 1,然后这两组再整合成为一组RAID0。如果我有100MB的数据要写入,则由于 RAID0 的关系,两组 RAID1 都会写入 50 MB,又由于RAID1的关系,因此每颗磁盘就会写入 50MB 而已。如此一来不论哪一组 RAID1 的磁盘损毁,由于是RAID 1的映像数据,因此就不会有任何问题发生了。
RAID 5:效能与数据备份的均衡考虑
RAID-5 至少需要三颗以上的磁盘才能够组成这种类型的磁盘阵列。
这种磁盘阵列的数据写入有点类似 RAID-0 ,不过每个循环的写入过程中(striping),在每颗磁盘还加入一个同位检查数据(Parity) ,这个数据会记录其他磁盘的备份数据,用于当有磁盘损毁时的救援。
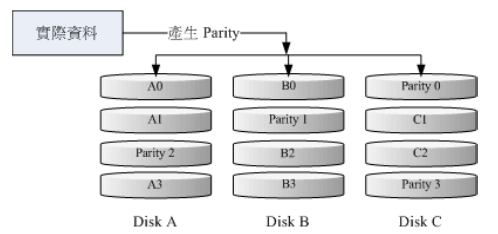
如上图所示,每个循环写入时,都会有部分的同位检查码(parity)被记录起来,并且记录的同位检查码每次都记录在不同的磁盘,因此,任何一个磁盘损毁时都能够由其他磁盘的检查码来重建原本磁盘内的数据。
不过,
由于有同位检查码,因此 RAID 5 的总容量会是整体磁盘数量减一颗
。
因为 RAID 5预设仅能支持一颗磁盘的损毁情况。当损毁的磁盘数量大于等于两颗时,这整组 RAID 5 的资料就损毁了。
RAID 6 则使用两颗磁盘的容量作为 parity 的储存,因此整体的磁盘容量就会少两颗,但是允许出错的磁盘数量就可以达到两颗。
Spare Disk:预备磁盘的功能
当磁盘阵列的磁盘损毁时,就得要将坏掉的磁盘拔除,然后换一颗新的磁盘。换成新磁盘并且顺利启动磁盘阵列后,磁盘阵列就会开始主动的重建(rebuild)原本坏掉的那颗磁盘数据到新的磁盘上,然后你磁盘阵列上面的数据就复原了。这就是磁盘阵列的优点。
为了让系统可以实时的在坏掉硬盘时主动的重建,因此就需要预备磁盘(spare disk)的辅助。
所谓的 spare disk 就是一颗或多颗没有包含在原本磁盘阵列等级中的磁盘,这颗磁盘平时并不会被磁盘阵列所使用,当磁盘阵列有任何磁盘损毁时,则这颗 spare disk 会被主动的拉进磁盘阵列中,并将坏掉的那颗硬盘移出磁盘阵列,然后立即重建数据系统。最后直接将坏掉的那颗磁盘拔除换一颗新的,再将那颗新的设定成为spare disk ,就可以了。
磁盘阵列的优点
1.数据安全与可靠性:当硬件(指磁盘)损毁时,数据是否还能够安全的救援或使用;
2.读写效能:例如 RAID 0可以加强读写效能,让你的系统IO 部分得以改善;
3.容量:可以让多颗磁盘组合起来,故单一文件系统可以有相当大的容量。
假设有 n 颗磁盘组成的RAID 设定:
software, hardware RAID
所谓的
硬件磁盘阵列
(hardware RAID)是透过磁盘阵列卡来达成数组的目的。
磁盘阵列卡上面有一块专门的芯片在处理RAID 的任务,因此在效能方面会比较好。在很多任务(例如 RAID 5 的同位检查码计算)磁盘阵列并不会重复消耗原本系统的 IO 总线,理论上效能会较佳。
此外目前一般的中高阶磁盘阵列卡都支持热拔插,亦即在不关机的情况下抽换损坏的磁盘,对于系统的复原与数据的可靠性方面非常的好用。
由于磁盘阵列有很多优秀的功能,然而硬件磁盘阵列卡价格偏高,因此就有发展出利用软件来仿真磁盘阵列的功能,这就是所谓的软件磁盘阵列(software RAID)。
软件磁盘阵列
主要是透过软件来仿真数组的任务,因此会损耗较多的系统资源,比如说 CPU 的运算与IO 总线的资源等。
CentOS 提供的软件磁盘阵列为 mdadm 这套软件,这套软件会以 partition 或 disk 为磁盘的单位,也就是说,不需要两颗以上的磁盘,只要有两个以上的分区槽 (partition)就能够设计磁盘阵列了。此外,mdadm支持刚刚 RAID0/RAID1/RAID5/spare disk 等,而且提供的管理机制还可以达到类似热拔插的功能,可以在线(文件系统正常使用)进行分区槽的抽换。
硬件磁盘阵列在 Linux 底下看起来就是一颗实际的大磁盘,因此硬件磁盘阵列的装置文件名为 /dev/sd[a-p],因为使用到 SCSI 的模块之故。至于软件磁盘阵列则是系统仿真的,因此使用的装置文件名是系统的装置文件,文件名为/dev/md0, /dev/md1…,两者的装置文件名并不相同。
软件磁盘阵列的设定
mdadm --detail /dev0/md0
mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...

格式化与挂载使用 RAID
mkfx.xfs -f -d su=256,sw=3, -r extsize=768k /dev/md0
mkdir /srv/raid
mount /dev/md0 /srv/raid
df -Th /srv/raid
救援机制
mdadm --manage /dev/md[0-9] [-add 装置] [--remove 装置] [--fail 装置]

开机自启动 RAID 并挂载
新的 distribution 大多会自己搜寻 /dev/md[0-9] 然后在开机的时候给予设定好所需要的功能。
software RAID 也是有配置文件的,这个配置文件在 /etc/mdadm.conf,这个配置文件内容很简单,只要知道/dev/md0 的 UUID 就能够设定这个文件。
关闭软件 RAID
1.先卸除且删除配置文件内与这个 /dev/md0 有关的设定;
umount /srv/raid
vim /etc/fstab
2.覆盖掉 RAID 的 metadata 以及 XFS 的 superlock,才关闭 /dev/md0
dd if=/dev/zero of=/dev/md0 bs=1M count=50
mdadm --stop /dev/md0
dd 的指令是因为 RAID 的相关数据其实也会存一份在磁盘当中,因此,如果你只是将配置文件移除,同时关闭了RAID,但是分区槽并没有重新规划过,那么重新启动过后,系统还是会将这颗磁盘阵列建立起来,只是名称可能会改变,最后搞混。 因此,移除掉Software RAID,上需要 dd.
逻辑滚动条文件系统(LVM)
LVM 的重点在于【可以弹性的调整filesystem 的容量】,而并非在于效能与数据保全上面。
LVM 可以整合多个实体 partition 在一起,让这些 partitions 看起来就像是一个磁盘一样。而且,还可以在未来新增或移除其他的实体 partition 到这个 LVM 管理的磁盘当中。如此一来,整个磁盘空间的使用上具有弹性。
什么是 LVM:PV,PE,VG,LV 的意义
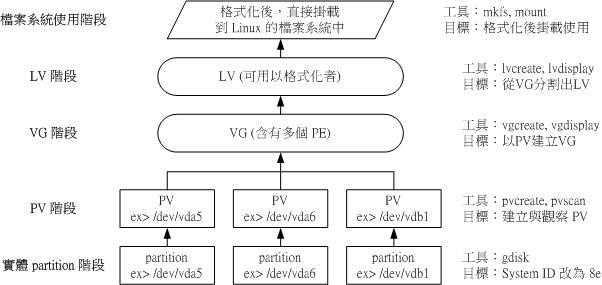
LVM 的全名是 Logical Volume Manager,中文可以翻译作逻辑滚动条管理员。之所以称为【滚动条】可能是因为可以将 filesystem 像滚动条一样伸长或缩短。
LVM 的作法是将几个实体的 partitions(或 disk) 透过软件组合成为一块看起来是独立的大磁盘(VG),然后将这块大磁盘再经过分区成为可使用分区槽(LV),最终就能够挂载使用了。
Physical Volume, PV,实体滚动条
实际的 partition(或 Disk) 需要调整系统标识符(system ID)成为 8e(LVM 的标识符),然后再经过 pvcreate的指令将他转成 LVM 最底层的实体滚动条(PV) ,之后才能够将这些 P V加以利用。
调整system ID 的方是就是透过gdisk。
Volume Group, VG,滚动条群组
所谓的 LVM 大磁盘就是将许多 PV整 合成这个 VG。所以 VG 就是LVM组合起来的大磁盘。
在预设的情况下,使用 32 位的 Linux系统时,基本上 LV 最大仅能支持到65534个 PE而已,若使用预设的 PE为4MB的情况下,最大容量则仅能达到约256GB而已;不过,这个问题在 64 位的 Linux系统上面已经不存在了,LV几乎没有啥容量限制了。
Physical Extent, PE,实体范围区块
LVM 预设使用 4MB 的 PE 区块,而 LVM 的LV在 32位系统上最多仅能含有 65534个 PE(lvm1 的格式),因此预设的LVM 的LV会有4M*65534/(1024M/G)=256G。
PE 是整个LVM最小的储存区块,也就是说,其实我们的文件资料都是由写入PE来处理的。简单的说,这个 PE 就有点像文件系统里面的 block 大小。所以调整PE会影响到LVM 的最大容量。
在 CentOS 6.x 以后,由于直接使用 lvm2 的各项格式功能,以及系统转为64位,因此这个限制已经不存在了。
Logical Volume,LV,逻辑滚动条
最终的 VG 还会被切成 LV,这个 LV 就是最后可以被格式化使用的类似分区槽的东西。
**
LV 不可以随意指定大小
**。既然PE是整个LVM 的最小储存单位,那么 LV 的大小就与在此 LV 内的 PE 总数有关。为了方便用户利用 LVM来管理其系统,因此 LV的装置文件名通常指定为【/dev/vgname/lvname】的样式
LVM可弹性的变更filesystem 的容量是透过【交换PE】来进行数据转换,将原本 LV 内的 PE 移转到其他装置中以降低 LV 容量,或将其他装置的 PE 加到此 LV中以加大容量。
VG、LV 与PE的关系有点像下图:
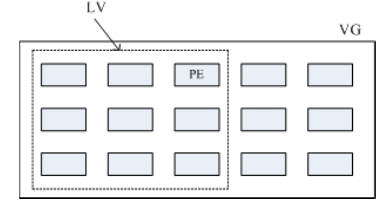
如上图所示,VG 内的 PE 会分给虚线部分的LV,如果未来这个VG要扩充的话,加上其他PV即可。而最重要的 LV 如果要扩充的话,也是透过加入 VG 内没有使用到的PE来扩充的。
实体流程
可以利用LV这个玩意儿来进行系统的挂载。依据写入机制的不同,有两种方式:
1.线性模式(linear):假如将 /dev/vda1, /dev/vdb1 这两个partition 加入到VG当中,并且整个VG 只有
一个LV 时,那么所谓的线性模式就是:当 /dev/vda1 的容量用完之后,/dev/vdb1 的硬盘才会被使用到,这也是所建议的模式。
2.交错模式(triped):将一笔数据拆成两部分,分别写入/dev/vda1与/dev/vdb1 的意思,感觉上有点像RAID0。如此一来,一份数据用两颗硬盘来写入,理论上,读写的效能会比较好。
基本上,LVM 最主要的用处是在实现一个可以弹性调整容量的文件系统上,而不是在建立一个效能为主的磁盘上,所以,应该利用的是 LVM 可以弹性管理整个 partition大小的用途上,而不是着眼在效能上的。因此,LVM 默认的读写模式是线性模式。如果要使用triped 模式,要注意,当任何一个 partition 损坏,所有的数据都会损毁的。所以不是很适合使用这种模式。如果要强调效能与备份,那么就直接使用 RAID 即可,不需要用到LVM。
LVM 实作流程
LVM 必需要核心有支持且需要安装 lvm2这个软件,好佳在的是,CentOS 与其他较新的 distributions 已经预设将 Ivm 的支持与软件都安装妥当了。
1.Disk 阶段(实际的硬盘)
gdisk -l /dev/vda
2.PV 阶段
要建立PV其实很简单,只要直接使用pvcreate即可。
pvcreate:将实体partition建立成为PV;
pvscan:搜寻目前系统里面任何具有PV的磁盘;
pvdisplay:显示出目前系统上面的PV 状态;
pvremove:将PV属性移除,让该 partition不具有PV属性。
3.VG 阶段
vgcreate:就是主要建立 VG的指令;
vgscan:搜寻系统上面是否有VG存在;
vgdisplay:显示目前系统上面的VG状态;
vgextend:在VG内增加额外的 PV;
vgreduce:在VG内移除PV;
vgchange:设定VG是否启动(active);
vgremove:删除一个VG;
vgcreate [-s N[mgt]] VG名称 PV名称
# -s:后面接PE的大小(size),单位可以是m,g,l
4.LV 阶段
创造出 VG 这个大磁盘之后,再来就是要建立分区区。这个分区区就是所谓的LV。
lvcreate:建立LV;
lvscan:查询系统上面的LV;
lvdisplay:显示系统上面的LV状态;
lvextend :在LV里面增加容量;
lvreduce:在LV里面减少容量;
lvremove :删除一个LV;
lvresize:对LV进行容量大小的调整;
lvcreate [-L N[mgt]] [-n LV名称] VG名称
lvcreate [-l N] [-n LV名称] VG名称
 LV的名称必须使用全名。
LV的名称必须使用全名。
放大 LV 容量
LVM弹性调整磁盘容量的流程的:
1.VG 阶段需要有剩余的容量:因为需要放大文件系统,所以需要放大 LV,但是若没有多的 VG 容量,那
么更上层的 LV 与文件系统就无法放大的。因此,要尽各种方法来产生多的 VG 容量才行。
一般来说,如果VG容量不足,最简单的方法就是再加硬盘,然后将该硬盘使用上面讲过的 pvcreate 及 vgextend 增加到该 VG 内即可。
2.LV阶段产生更多的可用容量:如果 VG 的剩余容量足够了,此时就可以利用 Ivresize 这个指令来将剩余
容量加入到所需要增加的LV装置内;
3.文件系统阶段的放大: Linux实际使用的其实不是LV,而是 LV 这个装置内的文件系统。所以一切最终还是要以文件系统为依归。
整个文件系统在最初格式化的时候就建立了inode/block/superblock 等信息,要改变这些信息是很难的。不过因为文件系统格式化的时候建置的是多个 block group ,因此可以透过在文件系统当中增加 block group 的方式来增减文件系统的量。而增减 block group 就是利用 xfs_growfs ,所以最后一步是针对文件系统来处理的,前面几步则是针对 LVM的实际容量大小。
严格说起来,放大文件系统并不是没有进行【格式化】。放大文件系统时,格式化的位置在于该装置后来新增的部份,装置的前面已经存在的文件系统则没有变化。而新增的格式化过的数据,再反馈回原本的supberblock。
使用 LVM thin Volumn 让 LVM 动态自动调制磁盘使用率
LVM thin Volume 的概念是:先建立一个可以实支实付、用多少容量才分配实际写入多少容量的磁盘容量储存池(thin pool),然后再由这个 thin pool 去产生一个【指定要固定容量大小的LV装置】。
在所有由 thin pool 所分配出来的 LV 装置中,总实际使用量绝不能超过 thin pool 的最大实际容量
。
LVM 的 LV 磁盘快照
什么是LV磁盘快照:快照(snapshot)就是将当时的系统信息记录下来,就好像照相记录一样,未来若有任何资料更动了,则原始资料会被搬移到快照区,没有被更动的区域则由快照区与文件系统共享。
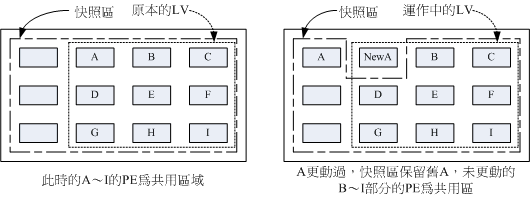
左图为最初建置 LV 磁盘快照区的状况,LVM 会预留一个区域(左图的左侧三个PE区块)作为数据存放处。此时快照区内并没有任何数据,而快照区与系统区共享所有的 PE数据,因此快照区的内容与文件系统是一模一样的。等到系统运作一阵子后,假设 A 区域的数据被更动了(上面右图所示),则更动前系统会将该区域的数据移动到快照区,所以在右图的快照区被占用了一块PE成为A,而其他B到Ⅰ的区块则还是与文件系统共享。
照这样的情况来看,LVM 的磁盘快照只有备份有被更动到的数据,文件系统内没有被变更的数据依旧保持在原本的区块内,但是 LVM 快照功能会知道那些数据放置在哪里,因此【快照】当时的文件系统就得以【备份】下来,且快照所占用的容量又非常小。
那么快照区要如何建立与使用呢?
首先,由于快照区与原本的 LV 共享很多PE区块,因此
快照区与被快照的 LV 必须要在同一个 VG 上头
。
1.先观察 VG 还剩下多少剩余容量;
vgdisplay VG名称
2.利用 lvcreate 建立快照区;
lvcreate -s -l 26 -n 快照区名称 VG具体地址

利用快照区复原系统
要复原的数据量不能够高于快照区所能负载的实际容量。由于原始数据会被搬移到快照区,如果快照区不够大,若原始资料被更动的实际数据量比快照区大,那么快照区当然容纳不了,这时候快照功能会失效。
LVM 相关指令汇总与 LVM 的关闭

文件系统阶段(filesystem的格式化处理)部分,还需要以 xfs_growfs 来修订文件系统实际的大小才行。
虽然LVM可以弹性的管理磁盘容量,但是要注意,如果想要使用 LVM 管理硬盘时,那么在安装的时候就得要做好 LVM 的规划了,否则未来还是需要先以传统的磁盘增加方式来增加后,移动数据后,才能够进行LVM的使用。
关闭移除流程:
1.先卸除系统上面的 LVM 文件系统(包括快照与所有LV);
2.使用 lvremove 移除 LV;
3.使用 vgchange -a n VGname 让 VGname这个VG不具有 Active 的标志;
4.使用 vgremove 移除VG;
5.使用pvremove移除PV;
6.最后,使用 fdisk 修改ID回来;
《鸟哥的Linux私房菜-基础篇》学习笔记