Redis介绍
Redis全称REmote DIctionary Server,由Salvatore Sanfilippo写的高性能key-value存储系统,完全开源免费,遵守BSD协议。
Redis是key-value存储系统,其中key类型一般为字符串,value类型则为RedisObject对象。
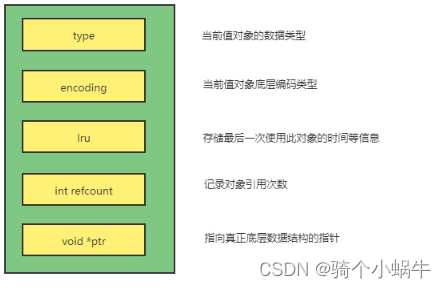
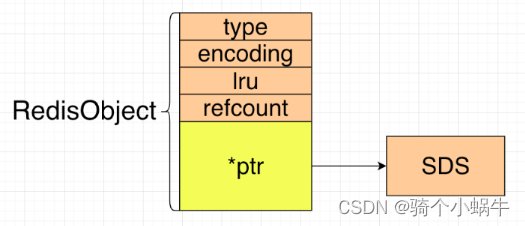
RedisObject的结构
RedisObject定义了5个属性:type、enconding、lru、refcount和*prt
|
属性
|
描述
|
|
type
|
value值的数据类型
|
|
enconding
|
value值的编码方式
|
|
lru
|
记录此对象最后一次访问的时间
|
|
refcount
|
记录对象的引用次数
|
|
*prt
|
数据指针
|
1. type
value值的数据类型。
常见数据类型:
|
类型常量
|
类型描述
|
|
REDIS_STRING
|
字符串对象
|
|
REDIS_LIST
|
列表对象
|
|
REDIS_HASH
|
哈希对象
|
|
REDIS_SET
|
集合对象
|
|
REDIS_ZSET
|
有序集合对象
|
2. enconding
value值的编码方式
常见编码方式:
|
编码常量
|
编码描述
|
|
REDIS_ENCODING_INT
|
long 类型的整数
|
|
REDIS_ENCODING_EMBSTR
|
embstr 编码的简单动态字符串
|
|
REDIS_ENCODING_RAW
|
简单动态字符串
|
|
REDIS_ENCODING_HT
|
字典
|
|
REDIS_ENCODING_LINKEDLIST
|
双端链表
|
|
REDIS_ENCODING_ZIPLIST
|
压缩列表
|
|
REDIS_ENCODING_INTSET
|
整数集合
|
|
REDIS_ENCODING_SKIPLIST
|
跳跃表和字典
|
不同数据类型支持的编码方式
|
数据类型
|
编码方式
|
描述
|
|
REDIS_STRING
|
REDIS_ENCODING_INT
|
使用整数值实现的字符串对象
|
|
REDIS_STRING
|
REDIS_ENCODING_EMBSTR
|
使用 embstr 编码的简单动态字符串实现的字符串对象
|
|
REDIS_STRING
|
REDIS_ENCODING_RAW
|
使用简单动态字符串实现的字符串对象
|
|
REDIS_LIST
|
REDIS_ENCODING_ZIPLIST
|
使用压缩列表实现的列表对象
|
|
REDIS_LIST
|
REDIS_ENCODING_LINKEDLIST
|
使用双端链表实现的列表对象
|
|
REDIS_HASH
|
REDIS_ENCODING_ZIPLIST
|
使用压缩列表实现的哈希对象
|
|
REDIS_HASH
|
REDIS_ENCODING_HT
|
使用字典实现的哈希对象
|
|
REDIS_SET
|
REDIS_ENCODING_INTSET
|
使用整数集合实现的集合对象
|
|
REDIS_SET
|
REDIS_ENCODING_HT
|
使用字典实现的集合对象
|
|
REDIS_ZSET
|
REDIS_ENCODING_ZIPLIST
|
使用压缩列表实现的有序集合对象
|
|
REDIS_ZSET
|
REDIS_ENCODING_SKIPLIST
|
使用跳跃表和字典实现的有序集合对象
|
3. lru
记录此对象最后一次访问的时间。
当redis内存回收算法设置为volatile-lru或者allkeys-lru时候redis会优先释放最久没有被访问的数据。
4. refcount
记录对象的引用次数,类似于jvm的引用计数垃圾回收算法,当refcount为0时,表示没有其它对象引用,可以进行释放此对象。
5. *prt
数据指针,指向底层真正的数据结构。
Redis源码结构
redis源码主要放在src目录里。
主要核心部分分类如下:
1. 基本数据结构
-
动态字符串 :sds.c
-
整数集合 :intset.c
-
压缩列表 :ziplist.c
-
快速链表 :quicklist.c
-
字典 :dict.c
-
Streams :底层实现结构为listpack.c和rax.c
2. Redis数据类型的底层实现
-
redis对象 :object.c
-
字符串 :t_string.c
-
列表 :t_list.c
-
字典 :t_hash.c
-
集合及有序集合 :t_set.c 和 t_zset.c
-
数据流 :t_stream.c
3. Redis数据库的实现
-
数据库的底层实现 :db.c
-
持久化 :rdb.c 和 aof.c
4. Redis服务端和客户端实现
-
事件驱动 :ae.c 和 ae_epoll.c
-
网络连接 :anet.c 和 networking.c
-
服务端程序 :server.c
-
客户端程序 :redis-cli.c
5. 其他
-
主从复制 :replication.c
-
哨兵 :sentinel.c
-
集群 :cluster.c
-
其他数据结构 :hyperloglog.c 、 geo.c 等
-
其他功能 :pub/sub 【发布/订阅】、 Lua脚本等
Redis数据类型
-
一般认为Redis的数据类型有:String、List、Set、Zset、Hash、Stream
-
HyperLogLog、Bitmap、Bloom Filter的底层是String数据类型
-
Geospatial的底层是Zset数据类型
|
数据类型
|
描述
|
使用场景
|
|
String
|
最基本的数据类型,可以存储任意数据,如文本、整数、二进制数据等,最大512M
|
用于缓存、计数器、分布式锁等场景
|
|
List
|
按照插入顺序排序的字符串元素集合,支持头尾插入、弹出等操作
|
用于实现队列、栈、消息队列等场景
|
|
Set
|
无序的字符串元素集合,其中元素不可重复,支持交集、并集、差集等操作
|
用于进行唯一性判定、求多个集合的交集、并集等场景
|
|
Zset
|
带有分数排序的字符串元素集合,支持根据分数范围来获取元素等操作
|
用于需要排序并保持唯一性的场景
|
|
Hash
|
存储多个键值对的字典,支持对单个字段进行增删查改等操作
|
用于表示对象、存储属性等场景
|
|
Stream
|
异步消息传输机制,基于多个消费者以广播模式接收生产者发送的消息
|
用于消息队列、事件驱动等场景
|
|
Bloom Filter
|
底层是String,概率型的数据结构(布隆过滤器),用于快速判断一个元素是否存在于一个集合中
|
用于判重、URL 去重、邮箱黑名单过滤等场景
|
|
Bitmap
|
底层是String,位图,用于存储一系列只有 0 和 1 的值,支持位运算等操作
|
用于标记、统计等场景
|
|
HyperLogLog
|
底层是String,基数统计算法,用于统计一个集合中不重复元素的数量
|
用于进行去重、UV 统计等场景
|
|
Geospatial
|
底层是Zset,地理位置数据类型,支持存储经度、纬度等地理信息,且支持根据地理位置信息进行查询
|
用于 LBS 场景、附近的人、商家等推荐等场景
|
String
String 类型是最简单、最常用的数据类型之一。它可以存储文本、整数或二进制数据。String 类型在 Redis 中被处理为二进制安全的字节序列。
使用场景
-
缓存
:
String 类型常被用作缓存的存储,可以将频繁读取的数据存储在 Redis 中,以提高数据读取效率。例如存储网页内容、用户信息等。
-
计数器
:
String 类型支持对整数进行原子操作,因此可以用作计数器。可用于实现访问量统计、文章点赞数统计等场景。
-
分布式锁
:
由于 Redis 提供原子操作的特性,可以利用 String 类型实现分布式锁。使用 SETNX 命令尝试加锁,利用 SETEX 命令设置过期时间,实现分布式环境下的互斥访问控制。
-
分布式 Session
:
在分布式系统中,可以借助 String 类型实现分布式 Session 的存储和管理。例如将用户登录信息存储在 Redis 的 String 类型中,实现用户状态的共享和管理。
使用示例
-
设置和获取值:
SET key value # 设置字符串键的值
GET key # 获取字符串键的值
-
字符串拼接:
APPEND key value # 将字符串追加到键值的末尾
STRLEN key # 获取指定键值的长度
-
数值操作:
INCR key # 将键值作为整数增加 1
DECR key # 将键值作为整数减少 1
INCRBY key increment # 将键值作为整数增加指定值
DECRBY key decrement # 将键值作为整数减少指定值
-
原子操作和过期:
SETNX key value # 如果键不存在,设置键的值
SETEX key seconds value # 设置键的值和过期时间
总结来说,Redis 的 String 类型是一个灵活而强大的数据类型,适用于缓存、计数器、分布式锁和分布式 Session 等各种常见用例。通过原子操作和丰富的命令集,可以充分发挥 String 类型的优势。
List
List(列表)是一个有序的字符串元素集合,插入顺序按照元素的加入顺序排列。List 可以存储各种类型的元素(如字符串、整数),在 Redis 中被处理为双向链表。List 具备头部插入、尾部插入、头部弹出、尾部弹出等操作,并支持通过索引访问和修改元素。
使用场景
使用示例
-
插入和删除操作:
LPUSH key value1 [value2 ...] # 在列表头部插入一个或多个值
RPUSH key value1 [value2 ...] # 在列表尾部插入一个或多个值
LPOP key # 弹出并返回列表的头部元素
RPOP key # 弹出并返回列表的尾部元素
-
获取列表元素:
LINDEX key index # 获取指定索引处的元素值
LRANGE key start stop # 获取指定范围内的元素值
-
获取列表长度:
LLEN key # 获取列表的长度
-
修改列表元素:
LSET key index value # 设置指定索引处的元素值
总结来说,Redis 的 List 数据类型是一个灵活且功能强大的有序集合,适用于队列、栈和消息队列等各种场景。通过多种插入、弹出和访问元素的命令,可以方便地操作和管理列表数据。
Set
Set(集合)是一个无序的、不重复的元素集合。Set 可以存储各种类型的元素(如字符串、整数),在 Redis 中被处理为哈希表结构。Set 提供了添加、删除、判断元素是否存在等常用操作,还支持交集、并集、差集等集合运算。
使用场景
-
去重
:
Set 的最常见用途是消除重复元素。通过将元素添加到 Set 中,可以自动去重,保留唯一的元素。
-
标签或分类
:
Set 可以用于标签或分类的存储。例如,将文章的标签存储在 Set 中,方便根据标签进行搜索和分类。
-
共同好友
:
Set 可以用于存储共同好友关系。通过将用户的好友列表存储在 Set 中,可以方便地查找两个用户的共同好友。
-
集合运算
:
Set 提供了交集、并集、差集等集合运算,可以对多个 Set 进行操作,求得他们之间的交集、并集或差集。
使用示例
-
添加和删除元素:
SADD key member1 [member2 ...] # 向集合中添加一个或多个元素
SREM key member1 [member2 ...] # 从集合中删除一个或多个元素
-
检查元素是否存在:
SISMEMBER key member # 检查元素是否存在于集合中
-
获取集合中的元素数量:
SCARD key # 获取集合的元素数量
-
获取集合中的所有元素:
SMEMBERS key # 获取集合中的所有元素
-
集合运算:
SINTER key1 [key2 ...] # 返回多个集合的交集
SUNION key1 [key2 ...] # 返回多个集合的并集
SDIFF key1 [key2 ...] # 返回多个集合的差集
总结来说,Redis 的 Set 数据类型提供了一种无序、不重复的集合存储方式,适用于去重、标签或分类、共同好友关系存储以及集合运算等场景。通过多种操作命令,可以方便地对集合进行增删查改以及集合运算。
Zset
Zset(Sorted Set)数据类型(有序集合)是一种基于 Set 的数据类型,其每个元素都会关联一个 double 类型的分数(score)属性。Zset 中的元素是唯一的,但是分数(score)可以重复。Zset 根据元素的分数进行排序,俗称为有序集合。
使用场景
-
排行榜:
Zset 常被用于实现排行榜功能,例如音乐网站的歌曲播放次数排行榜、积分排行榜等,分数可以表示播放次数或者积分,元素即为歌曲或用户。
-
范围查询:
由于有序集合中元素按照分数排序,因此可以方便进行范围查询。例如,可以使用 ZRANGEBYSCORE 命令获取指定分数范围内的元素列表。
-
任务调度:
Zset 可以用于任务调度,分数可以表示任务的执行时间,通过定时将分数符合条件的任务提取出来执行。
-
实时榜单:
Zset 可以用于实时热门数据统计,例如统计最近一段时间内的热门搜索关键词或热门商品。
使用示例
-
添加和删除元素:
ZADD key score1 member1 [score2 member2 ...] # 向有序集合中添加一个或多个元素
ZREM key member1 [member2 ...] # 从有序集合中删除一个或多个元素
-
查看元素排名:
ZRANK key member # 获取指定成员的排名
-
查看元素分数:
ZSCORE key member # 获取指定成员的分数
-
获取集合中的元素数量:
ZCARD key # 获取有序集合的元素数量
-
获取指定分数范围内的元素:
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] # 获取指定分数范围内的元素
总结来说,Redis 的 Zset 数据类型提供了一种根据分数进行排序的有序集合存储方式,适用于排行榜、范围查询、任务调度和实时榜单等场景。通过多种操作命令,可以方便地对有序集合中的元素进行增删查改以及范围查询。
Hash
Hash 是一个键值对集合,类似于关联数组或者对象。在 Redis 中,每个 Hash 可以存储多个键值对,其中键与值都是字符串类型的。Hash 常用于存储对象的属性和值,特别适合用来存储对象的多个属性,比如用户、商品等。
使用场景
-
存储对象属性:
Hash 可以用于存储对象的多个属性和对应的值,比如用户对象的属性(用户名、年龄、性别等)、商品对象的属性(名称、价格、库存等)。
-
缓存存储:
Hash 可以用于存储缓存信息,例如将数据库查询结果缓存为 Hash 类型,字段名作为缓存的唯一标识,字段值存储查询结果。
-
计数器:
Hash 可以用于实现计数器功能,例如网站的文章点赞数、评论数等,可以以文章 ID 为键,以点赞数和评论数为字段值存储在 Hash 中。
-
对象存储:
Hash 适合于存储较为复杂的对象结构,比如存储 JSON 数据时,可以将不同属性存储为 Hash 的不同字段,方便操作和检索。
使用示例
-
添加和修改字段:
HSET key field value # 设置指定字段的值
HMSET key field1 value1 field2 value2 ... # 设置多个字段的值
-
获取字段值:
HGET key field # 获取指定字段的值
HMGET key field1 field2 ... # 获取多个字段的值
-
删除字段:
HDEL key field1 [field2 ...] # 删除一个或多个字段
-
获取所有字段名:
HKEYS key # 获取所有字段名
-
获取所有字段值:
HVALS key # 获取所有字段的值
-
获取字段数量:
HLEN key # 获取字段的数量
总结来说,Redis 的 Hash 数据类型提供了一种存储对象属性的键值对集合存储方式,适用于对象属性存储、缓存存储、计数器和对象存储等场景。通过多种操作命令,可以方便地对 Hash 中的字段进行增删查改操作。
Stream
Stream(流)是一个有序、持久化的消息流数据结构,类似于消息队列。Stream 以时间顺序存储消息,并为每个消息分配一个唯一的、递增的 ID。Stream 中的消息称为条目(entry),每个条目包含一个字段的键值对集合。Stream 提供了多种操作来添加、读取和删除条目,并可以根据条件进行过滤。
使用场景
-
消息队列:
Stream 可以作为轻量级的消息队列使用,用于发布订阅模式、异步任务处理、实时处理等场景。
-
日志收集:
Stream 可以用于实时收集和存储系统日志,方便后续检索和分析。
-
事件溯源:
Stream 可以用于记录和回放事件流,实现事件溯源机制。
-
实时数据处理:
Stream 可以用于实时数据处理,对实时数据进行监控、处理、聚合等操作。
使用示例
-
添加条目:
XADD mystream * field1 value1 field2 value2 # 添加条目,并生成递增的唯一 ID
-
读取条目:
XREAD STREAMS mystream 0 # 从指定位置读取条目,0 表示从最旧的条目开始读取
-
删除条目:
XDEL mystream id1 id2 ... # 删除一个或多个指定的条目
-
获取条目数量:
XLEN mystream # 获取条目的数量
-
根据条件过滤条目:
XREAD STREAMS mystream id0-0 COUNT 10 # 根据 ID 过滤条目,从指定 ID 位置开始读取指定数量的条目
总结来说,Redis 的 Stream 是一种用于处理实时流式数据的日志数据结构。作为高性能的消息队列,Stream 支持添加、读取、消费和管理消息,适用于消息队列、日志处理和流式计算等场景。通过使用 Stream 提供的命令,可以实现高效、可持久化的实时数据处理。
为什么不使用Redis发布订阅 (pub/sub) 来实现消息队列:
Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,支持发布 / 订阅,支持多组生产者、消费者处理消息。但是存在很多问题:
-
消费者下线,数据会丢失。
-
不支持数据持久化,Redis 宕机,数据也会丢失,Pub/Sub 没有基于任何数据类型实现,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,Pub/Sub 的数据也会全部丢失。
-
消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失。
缓冲区的默认配置:client-output-buffer-limit pubsub 32mb 8mb 60。它的参数含义如下:
-
32mb:缓冲区一旦超过 32MB,Redis 直接强制把消费者踢下线。
-
8mb + 60:缓冲区超过 8MB,并且持续 60 秒,Redis 也会把消费者踢下线。
Bloom Filter
Bloom Filter 是一种概率型数据结构,用于快速判断一个元素是否在集合中,具有快速查询和占用空间少的特点。Bloom Filter 使用一系列哈希函数和位数组,通过将元素映射到位数组的多个位置,并将相应位置的值置为 1,来表示元素存在的可能性。
但需注意:Bloom Filter 在存在一定的误判率(false positive)的情况下使用,因此适用于对错误率要求不高的场景。
使用场景
-
缓存穿透:
Bloom Filter 可以用于缓存穿透场景,当请求的数据在缓存中不存在时,可以通过 Bloom Filter 快速判断请求的数据是否一定不存在,从而避免无效的数据库查询操作。
-
去重判断:
Bloom Filter 可以用于去重场景,例如判断一个 URL 是否已经访问过,判断一个用户是否已经参与过某个活动等。
-
数据集合判断:
Bloom Filter 可以用于判断元素是否属于一个大数据集合,避免对庞大的数据集合进行昂贵的查询操作。
使用示例
-
添加元素:
BFADD key item # 向 Bloom Filter 中添加一个元素
-
判断元素是否存在:
BFMEXISTS key item1 item2 ... # 判断一个或多个元素是否存在于 Bloom Filter 中
-
获取 Bloom Filter 的错误率:
BFINFO key # 获取 Bloom Filter 的相关信息,包括错误率、哈希函数数等
总结来说,Redis 的 Bloom Filter 是一种快速判断元素是否存在的概率型数据结构,适用于缓存穿透、去重判断和数据集合判断等场景。通过添加元素和判断元素是否存在的操作,可以实现快速而低成本的元素存在性判断。需要注意的是,Bloom Filter 在存在一定的误判率(false positive)的情况下使用,因此适用于对错误率要求不高的场景。
Bitmap
Bitmap(位图)是一种稀疏压缩的数据结构,用于存储和操作二进制位的集合。每个位可以表示一个索引或标记,BitMap 中的位数由用户指定,一般用于表示布尔值或者计数器。
使用场景
-
布尔值表示:
Bitmap 可以用来表示布尔值(0 或 1),例如标记用户是否在线、是否已读等状态。
-
计数器:
Bitmap 可以用于实现计数器功能,例如统计用户登录次数、点击次数等。
-
位操作:
Bitmap 提供了位操作的功能,例如与、或、非、异或等操作,可以用于集合运算、位运算等应用。
使用示例
-
将指定位置的位设置为 1:
SETBIT key offset value # 将 key 的 offset 位置的位设置为 value (0 或 1)
-
获取指定位置的位的值:
GETBIT key offset # 获取 key 的 offset 位置的位的值 (0 或 1)
-
统计指定范围内值为 1 的位的数量:
BITCOUNT key [start end] # 统计 key 中指定范围内的值为 1 的位的数量
-
对多个 key 进行位操作并将结果保存到新的 key 中:
BITOP operation destkey key1 [key2 ...] # 对多个 key 进行位操作(与、或、非、异或)并将结果保存到 destkey 中
总结来说,Redis 的 Bitmap 是一种稀疏压缩的位集合数据结构,适用于表示布尔值、计数器和位操作等场景。通过设置位、获取位的值、统计位数量和位操作等操作,可以对二进制位进行存储、操作和查询。Bitmap 在实现简单功能时占用的内存较小且性能较高,适合处理大量位操作的需求。
HyperLogLog
HyperLogLog(超级日志日志)是一种基数估计算法,用于统计唯一元素的数量。HyperLogLog 使用非常小的固定空间来估计大型集合的基数,同时引入了一定的误差。
使用场景
使用示例
-
添加元素到 HyperLogLog:
PFADD key element1 element2 ... # 将元素添加到 HyperLogLog 中
-
获取 HyperLogLog 的基数估计:
PFCOUNT key # 获取 HyperLogLog 的基数估计值
-
合并多个 HyperLogLog:
PFMERGE destkey sourcekey1 sourcekey2 ... # 合并多个 HyperLogLog,并将结果保存到 destkey 中
总结来说,Redis 的 HyperLogLog 是一种基数估计算法,用于统计大型集合的基数。通过添加元素到 HyperLogLog,获取基数估计值,以及合并多个 HyperLogLog 等操作,可以实现高效的基数统计。需要注意的是,HyperLogLog 在提供基数估计的同时,会引入一定的误差(通常为 0.81%),因此适用于对精确度要求不高的基数统计场景。
Geospatial
Geospatial(地理空间)功能是通过 Geohash 算法实现的,它允许在 Redis 中存储和查询具有地理位置信息的数据。Geospatial 提供了一系列的命令和数据结构,可以进行地理位置坐标的存储、距离计算、位置查询等操作。
使用场景
-
地理位置存储
:
Geospatial 可以用于存储具有地理位置信息的数据,例如存储地标、商家或用户的地理坐标、地理区域等。
-
位置查询与距离计算
:
Geospatial 提供了查询附近位置、计算两地距离等功能,例如在地理半径范围内查找附近的商家、计算两点之间的距离等。
-
地理位置可视化
:
通过 Geospatial 可以将地理位置信息存储到 Redis 中,然后配合其他工具实现地理信息的可视化,例如在地图上展示商家的分布情况、绘制用户的移动轨迹等。
使用示例
-
添加地理位置坐标:
GEOADD key longitude latitude member # 将指定的经度、纬度和成员添加到指定的 key 中
-
查询指定位置的地理信息:
GEOPOS key member1 [member2 ...] # 获取指定成员的地理位置坐标信息
-
查询指定位置附近的其他成员:
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [COUNT count] [ASC|DESC] # 获取指定半径范围内的成员信息
总结来说,Redis 的 Geospatial 功能通过 Geohash 算法实现对地理位置的存储和查询,适用于地理位置存储、位置查询与距离计算以及地理位置可视化等场景。使用 Geospatial 提供的命令,可以进行地理位置坐标的存储、查询和距离计算等操作,方便实现与地理信息相关的功能。
参考文章:
https://zhuanlan.zhihu.com/p/382296964