文章目录
- 报错代码
- 报错信息
- 图片展示
- 解决方法
- 再次运行,成功!!!
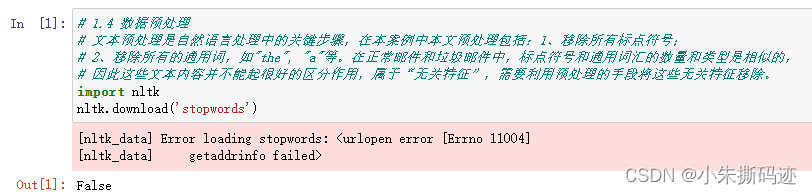
报错代码
import nltk
nltk.download('stopwords')
#or
import nltk
from nltk.corpus import stopwords
stopword = stopwords.words('english')
print(len(stopword))
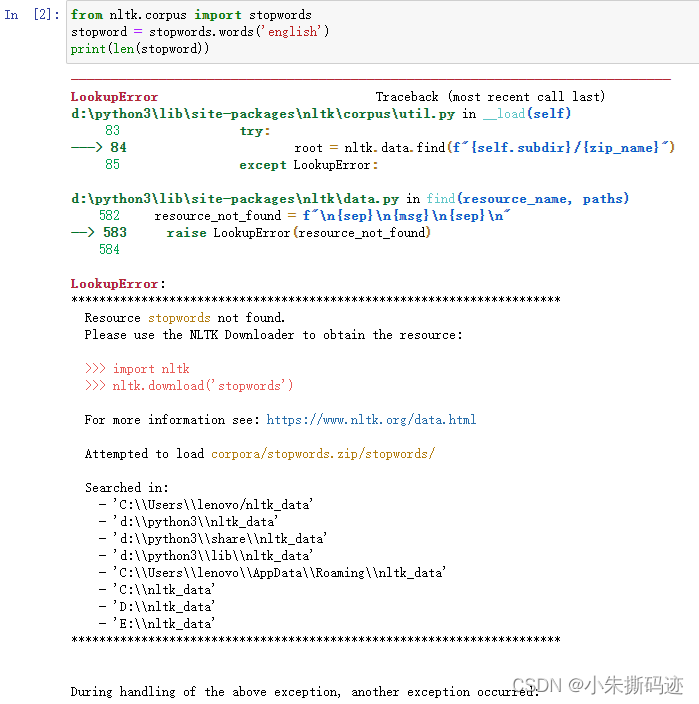
报错信息
[nltk_data] Error loading stopwords: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
False
....
LookupError:
**********************************************************************
Resource stopwords not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('stopwords')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/stopwords
Searched in:
- 'C:\\Users\\lenovo/nltk_data'
- 'd:\\python3\\nltk_data'
- 'd:\\python3\\share\\nltk_data'
- 'd:\\python3\\lib\\nltk_data'
- 'C:\\Users\\lenovo\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
图片展示
解决方法
- 下载料语(根据上述代码我仅需下载stopword文件)
推荐下载地址:点击可到GitHub下载网站
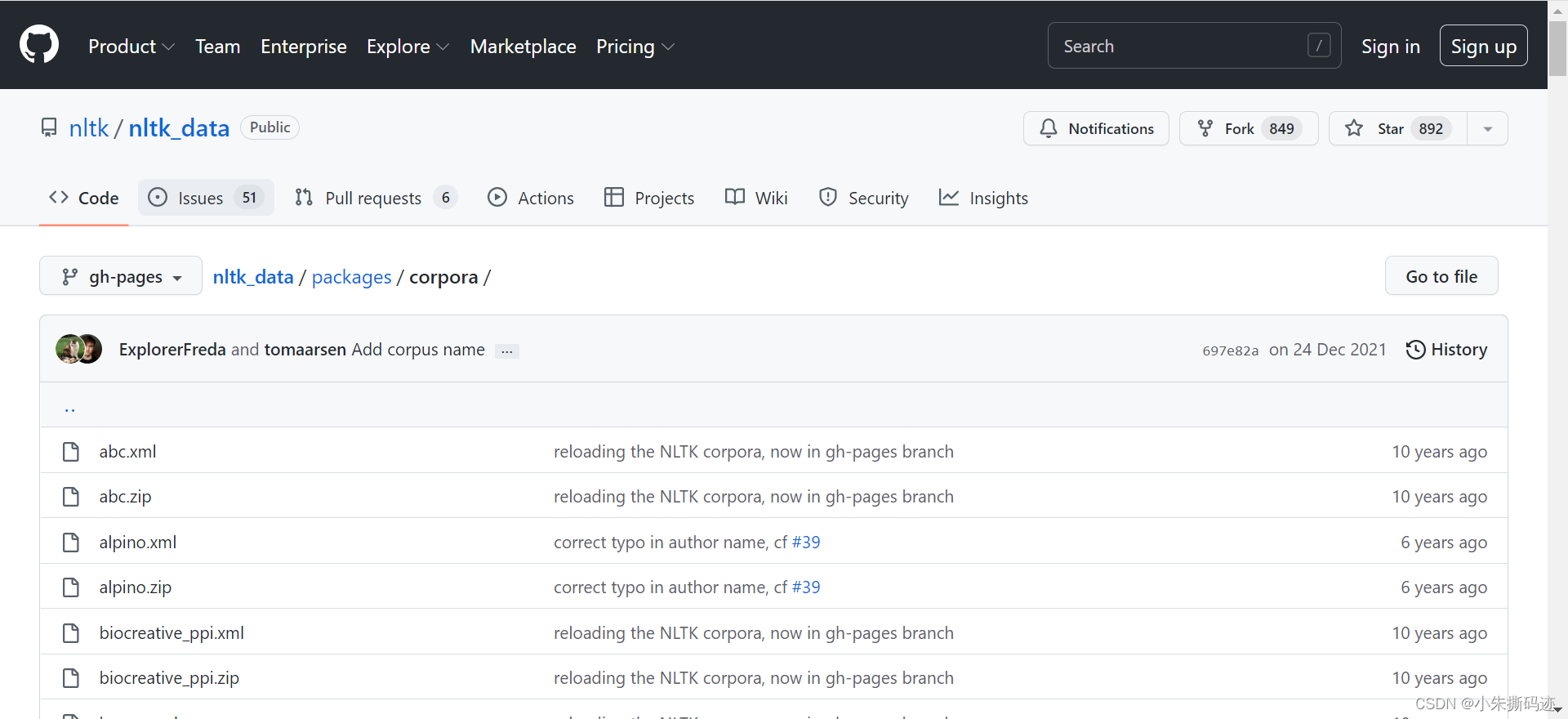
找到自己需要的模块(语料)
我的代码需要stopwords

- 在本地新建文件夹(注意一定要手动新建
corpora目录)
注意是报错信息的任意路径

查看图片路径

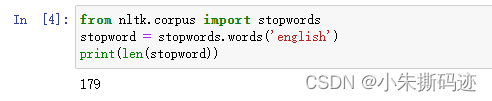
再次运行,成功!!!
import nltk
from nltk.corpus import stopwords
stopword = stopwords.words('english')
print(len(stopword))
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)